GCC、objdump、机器表示基础知识
GCC、objdump、机器表示基础知识
前言
最近在看CSAPP(深入理解计算机系统)第三章,打算将自己所学的知识及学习的过程记录下来,以免学了跟没学一样。自从上大学后就一直没有怎么好好学习了,希望自己能够从今天起,每天学习一点点,逐渐改变自己颓废的生活方式。不求一天学多少内容,但求能够细水长流,每天都能在短暂的学习的时间里保持充沛的精力。
如书中所言,人们在学习时常常会这样想
我理解了一般规则,不愿意劳神去学习细节
我们总是觉得理解了一个知识点,可以证明自己的智力,而学习细节则是枯燥而又无聊的。这也是我的思维方式,我总觉得不应该在简单的事情上浪费时间,于是现在薄弱的基础严重制约了我的能力。在每个领域的学习之初,必然有大量重复而又无聊的基础知识,和一些琐屑般的细节,我们往往会忽视它们。当遇到能力的瓶颈的时候,对造成这一切的原因一无所知,也许恰恰就是那些被自己忽视掉的细节。
步入正题,开始对csapp第三章——程序的机器级表示的学习。
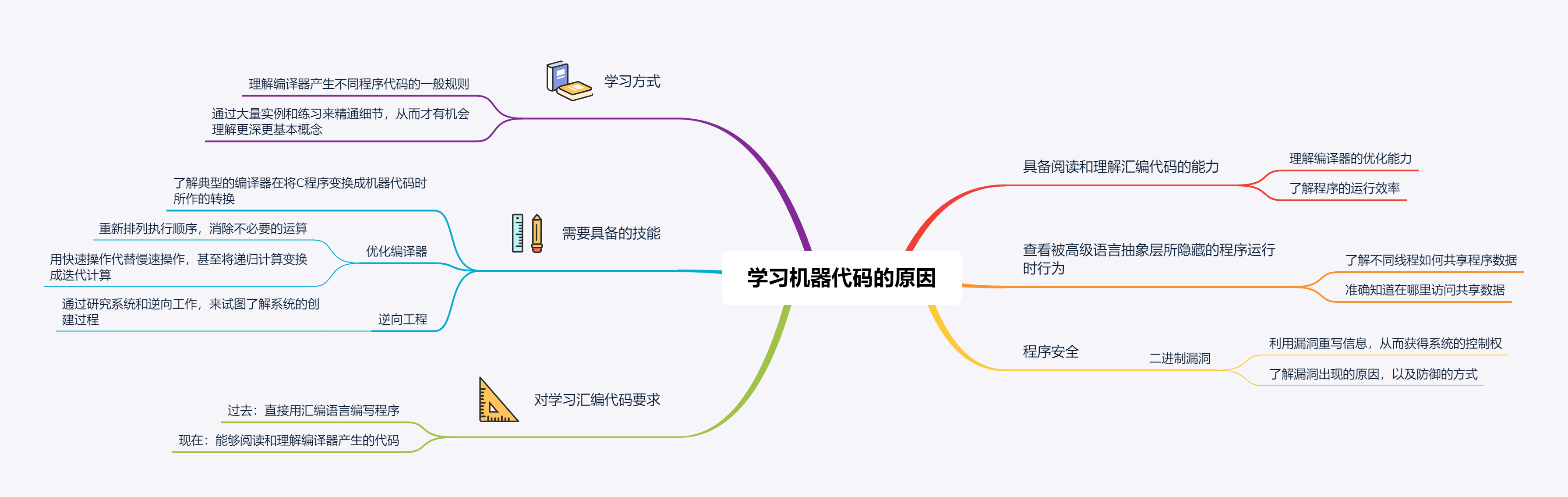
下面是学习机器代码的原因、能力要求及学习方式。
本章使用x86-64 Linux平台,GCC编译器,objdump反汇编器
基础知识
GCC的调用方式
linux> gcc -Og -o p p1.c p2.c
-Og 使用能够生成符合原始C代码整体结构的机器代码的优化等级。(便于学习,如果无法使用,则使用-O1)
-o p 用于将生成的可执行文件命名为p
机器级编程的抽象方式:
- 由指令集体系结构来定义机器级程序的格式和行为,将程序行为描述成每条指令按顺序执行的
- 机器级程序所使用的内存地址是虚拟地址,操作系统负责将虚拟地址翻译成实际处理器内存中的物理地址
汇编程序员可见寄存器
- 程序计数器(“PC”,在x86-64中用%rip表示)给出将要执行下一条指令在内存中的地址。
- 整数寄存器 包含16个命名的为之,存储64位的值,可以存储地址或整数数据,及其他特定功能。
- 条件码寄存器 保存最近执行的算术或者逻辑指令的状态信息。实现例如if或while语句。
- 向量寄存器 存放一个或多个整数或浮点数值。
GCC参数功能(资料来源)
#-c 预处理、编译、汇编
linux> gcc -c a.c #将源文件编译为目标文件a.o(进行编译、汇编,但是不进行链接)
#-o 制定目标名称,并且可以将.c文件或.o文件作为输入
linux> gcc -o app a.c #将a.c生成的可执行文件写入app.out内,若不用-o,则生成a.out
linux> gcc -c func.c main.c #只编译汇编不链接,生成func.o和main.o
linux> gcc func.o main.o -o app.out #将目标文件链接为可执行文件app.out
#-E 生成预处理文件
linux> gcc -E a.c -o a.i #把预处理结果导出a.i文件
linux> gcc -E a.c > a.txt#只激活预处理,不生成文件,重定向到a.txt中
linux> gcc -E a.c |more #在more中显示
#-S 生成汇编文件
linux> gcc -S a.c #编译a.c,将其翻译成汇编语言,存储在circle.s文件中
#-l 手动添加链接库
linux> gcc a.c -o main.out -lm #链接数学库math.h
#通常,GCC会自动在标准库目录中搜索文件,例如/usr/lib
#想链接其他目录中的库,得特别指明
linux> gcc a.c -o main.out /usr/lib/libm.a #将libm.a链接到main.o
linux> gcc a.c -o main.out -L/usr/lib -lm #使用-L选项,为GCC增加另一个搜索链接库目录
objdump参数功能
linux> objdump -d a.o #显示文件
linux> objdump -f a.o #显示文件头信息
linux> objdump -D a.o #反汇编所有section
linux> objdump -h a.o #显示目标文件各个section的头部摘要信息
linux> objdump -x a.o #显示所有可用的头信息,包括符号表、重定位入口
linux> objdump -i a.o #显示可用架构和目标格式列表
linux> objdump -r a.o #显示文件的重定位入口
linux> objdump -R a.o #显示文件的动态重定位入口,仅仅对于动态目标文件有意义
linux> objdump -S a.o #尽可能反汇编出源代码,与-d类似
linux> objdump -t a.o #显示文件的符号表入口
ATT与intel汇编代码格式的区别
//mstore.c
long mult2(long ,long );
void multstore(long x,long y,long *dest){
long t = mult2(x,y);
*dest = t;
}
使用gcc生成intel格式的汇编代码
linux> gcc -Og -S -masm=intel mstore.c
linux> vim mstore.s
结果如下:
.file "mstore.c"
.intel_syntax noprefix
.text
.globl multstore
.type multstore, @function
multstore:
.LFB0:
.cfi_startproc
push rbx
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
mov rbx, rdx
call mult2@PLT
mov QWORD PTR [rbx], rax
pop rbx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE0:
.size multstore, .-multstore
.ident "GCC: (Debian 8.3.0-6) 8.3.0"
.section .note.GNU-stack,"",@progbits
而GCC默认生成的汇编代码是ATT格式的
linux> gcc -Og -S mstore.c
linux> vim mstore.s
结果如下:
.file "mstore.c"
.text
.globl multstore
.type multstore, @function
multstore:
.LFB0:
.cfi_startproc
pushq %rbx # push rbx (in intel)指令后缀、寄存器名字
.cfi_def_cfa_offset 16
.cfi_offset 3, -16
movq %rdx, %rbx # mov rbx, rdx (in intel) 操作数相反
call mult2@PLT
movq %rax, (%rbx) # mov QWORD PTR [rbx], rax (in intel)不同表示方式
popq %rbx
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE0:
.size multstore, .-multstore
.ident "GCC: (Debian 8.3.0-6) 8.3.0"
.section .note.GNU-stack,"",@progbits
从中我们能发现如下区别:
- Intel代码省略了指令的大小的后缀。是push和mov,而不是pushq和movq。
- Intel代码省略了寄存器名字前面的'%'符号
- Intel代码用不同的方式来描述内存中的位置。'QWORD PTR [rbx]',而不是'(%rbx)'。
- 在带有多个操作数时,列出操作数的顺序相反。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号