Flink反压机制
What
整体概况:
反压是流式系统中关于处理能力的动态反馈机制,并且是从下游到上游的反馈。一般是在实时数据处理的过程中,上游节点的生产速度大于下游节点的消费速度。在Flink中,反压主要有两个部分:跨TaskManager的反压过程和TaskManager内的反压过程。

TaskManager内存结构 :
Flink中网络传输场景下的内存管理。
首先,每一个Task都是在TaskManager(TM)中运行,每个TM中都存在一个内存区域叫做NetworkBufferPool,这个区域中默认存在2048个内存块MemorySegment(一个默认32K),表示可用的内存。
然后,每一个Task任务中都存在输入区域InputGate(IG)和输出区域ResultPartition(RP),里面传输的都是字节数据(因为要进行网络传输,所以需要进行序列化),并且存在于Buffer中,Buffer是MemorySegment的包装类。
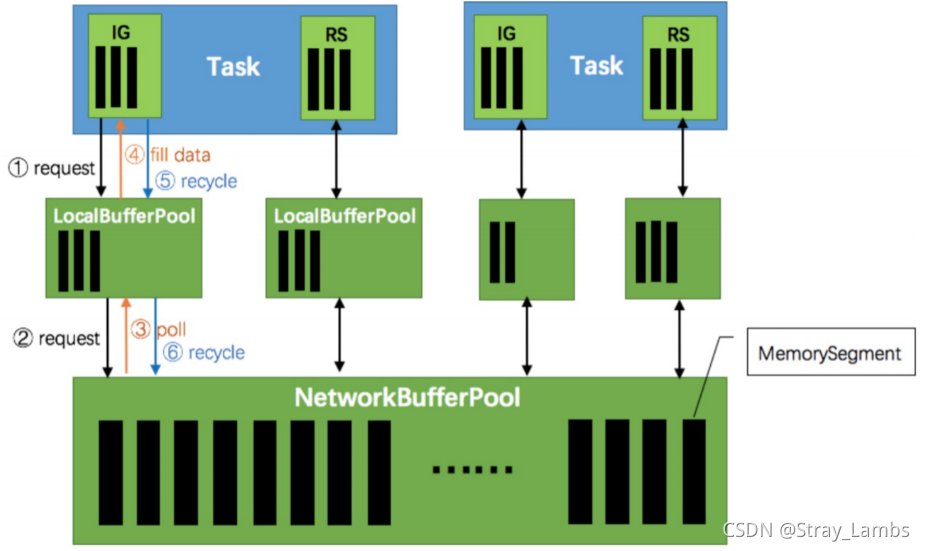
Flink 会在 NetworkBufferPool 中生成一定数量(默认2048,一个32K)的内存块 MemorySegment,内存块的总数量就代表了网络传输中所有可用的内存。NetworkEnvironment 和 NetworkBufferPool 是 Task 之间共享的,每个节点(TaskManager - 跑任务的进程,类似于spark的executor)只会实例化1个。
Task 线程启动时,会向 NetworkEnvironment 注册,NetworkEnvironment 会为 Task 的 InputGate(IG)和 ResultPartition(RP) 分别创建一个 LocalBufferPool(缓冲池)并设置可申请的 MemorySegment(内存块)数量(一般是均匀分配)。IG 对应的缓冲池初始的内存块数量与 IG 中 InputChannel 数量一致,RP 对应的缓冲池初始的内存块数量与 RP 中的 ResultSubpartition 数量一致。不过,每当创建或销毁缓冲池时,NetworkBufferPool 会计算剩余空闲的内存块数量,并平均分配给已创建的缓冲池。注意,这个过程只是指定了缓冲池所能使用的内存块数量,并没有真正分配内存块,只有当需要时才分配(按需动态分配)。为什么要动态地为缓冲池扩容呢?因为内存越多,意味着系统可以更轻松地应对瞬时压力(如GC),不会频繁地进入反压状态,所以我们要利用起那部分闲置的内存块。
在 Task 线程执行过程中,当 Netty 接收端收到数据时,为了将 Netty 中的数据拷贝到 Task 中, InputChannel(实际是 RemoteInputChannel)会向其对应的缓冲池申请内存块(上图中的①)。如果缓冲池中也没有可用的内存块且已申请的数量还没到池子上限,则会向 NetworkBufferPool 申请内存块(上图中的 ②)并交给 InputChannel 填上数据(上图中的③和④)。如果缓冲池已申请的数量达到上限了呢?或者 NetworkBufferPool 也没有可用内存块了呢?这时候,Task 的 Netty Channel 会暂停读取,上游的发送端会立即响应停止发送,拓扑会进入反压状态。当 Task 线程写数据到 ResultPartition 时,也会向缓冲池请求内存块,如果没有可用内存块时,会阻塞在请求内存块的地方,达到暂停写入的目的。
当一个内存块被消费完成之后(在输入端是指内存块中的字节被反序列化成对象了,在输出端是指内存块中的 字节写入到 Netty Channel 了),会调用 Buffer.recycle() 方法,会将内存块还给 LocalBufferPool (上图中的⑤)。如果LocalBufferPool中当前申请的数量超过了池子容量(由于上文提到的动态容量,由于新注册的 Task 导致该池子容量变小),则LocalBufferPool会将该内存块回收给 NetworkBufferPool(上图中的 ⑥)。如果没超过池子容量,则会继续留在池子中,减少反复申请的开销。
跨TaskManager的反压过程

首先,TM中A任务给TM中B任务发送数据,所以A作为生产者,B作为消费者。图中ResultPartition中的ResultSubPartition和InputGate中的InputChannel都是Task独享的,当中的内存块都是先向LocalBufferPool中申请Buffer空间,然后LocalBufferPool不足时,再向NetWorkBufferPool申请内存空间,而NetWorkBufferPool是TM共享的对外内存(在TM初始化的时候申请的)。可以看上面内存结构的那张图。
然后,经过netty的buffer后,数据又会被拷贝到Socket的Send Buffer中,最后通过Socket发送网络请求,把Send Buffer中的数据发送到Consumer端的 Receive Buffer,并依图中所示,在Consumer端向上传递直到Consumer Operator。
正常的生产消费流程就是按照上面的图来进行的。那么,反压的产生是因为什么呢?
考虑一个情况,生产消费是消费速度的两倍,也就是说来不及消费的情况,看看反压向上游TaskManager的传递。
a、nputChannel会积压消费不及时的数据,当内存块不足时,向LocalBufferPool进行申请内存块。
b、当LocalBufferPool的内存块不足时,进一步向NetWorkBufferPool申请内存块。
c、当NetWorkBufferPool内存块不足时,积压的数据增多,导致Netty当中的Buffer也满了,那么进而导致了TCP的Socket中Receiver报告Window=0(在TCP协议中的滑动窗口机制)。此时TM中B任务已经无法在容纳新的数据了。
d、那么,积压的数据反馈到了TM中A任务内,内存满的顺序为,Socket中send buffer->Netty Buffer->ResultSubPartition->LocalBufferPool->NetWorkBufferPool。最终导致了生产者Operator中的Record Writer停止,不再写数据。
以上是Flink1.5版本之前,是利用buffer进行存储,当buffer满了之后,进行上游流阻塞。但是存在的问题是,可能导致多路复用的TCP通道被占用,把其他同一个TCP信道的且没有流量压力的subTask给阻塞了。所以,在1.5版本之后,使用的是基于Credit机制,由下游反馈Credit值,表示可以接收上游buffer的数量,上游按
基于Credit的反压过程

每一次ResultSubPartition向InputChannel发送消息时,都会发送一个back log size,告诉下游准备发送多少消息,下游会计算剩余的buffer空间,如果buffer足够,就返回上游告知可以发送消息的大小(通信依旧是通过Netty和Socket去通信)。若内存不足,则告知最多可以接收多少个credit,甚至是返回0,表示下游没有空间,让上游不需要发送数据,直到下游buffer腾出空间。
基于credit的反压过程,效率比之前要高,因为只要下游InputChannel空间耗尽,就能通过credit让上游ResultSubPartition感知到,不需要在通过netty和socket层来一层一层的传递。另外,它还解决了由于一个Task反压导致 TaskManager和TaskManager之间的Socket阻塞的问题。
TM内部的反压过程:
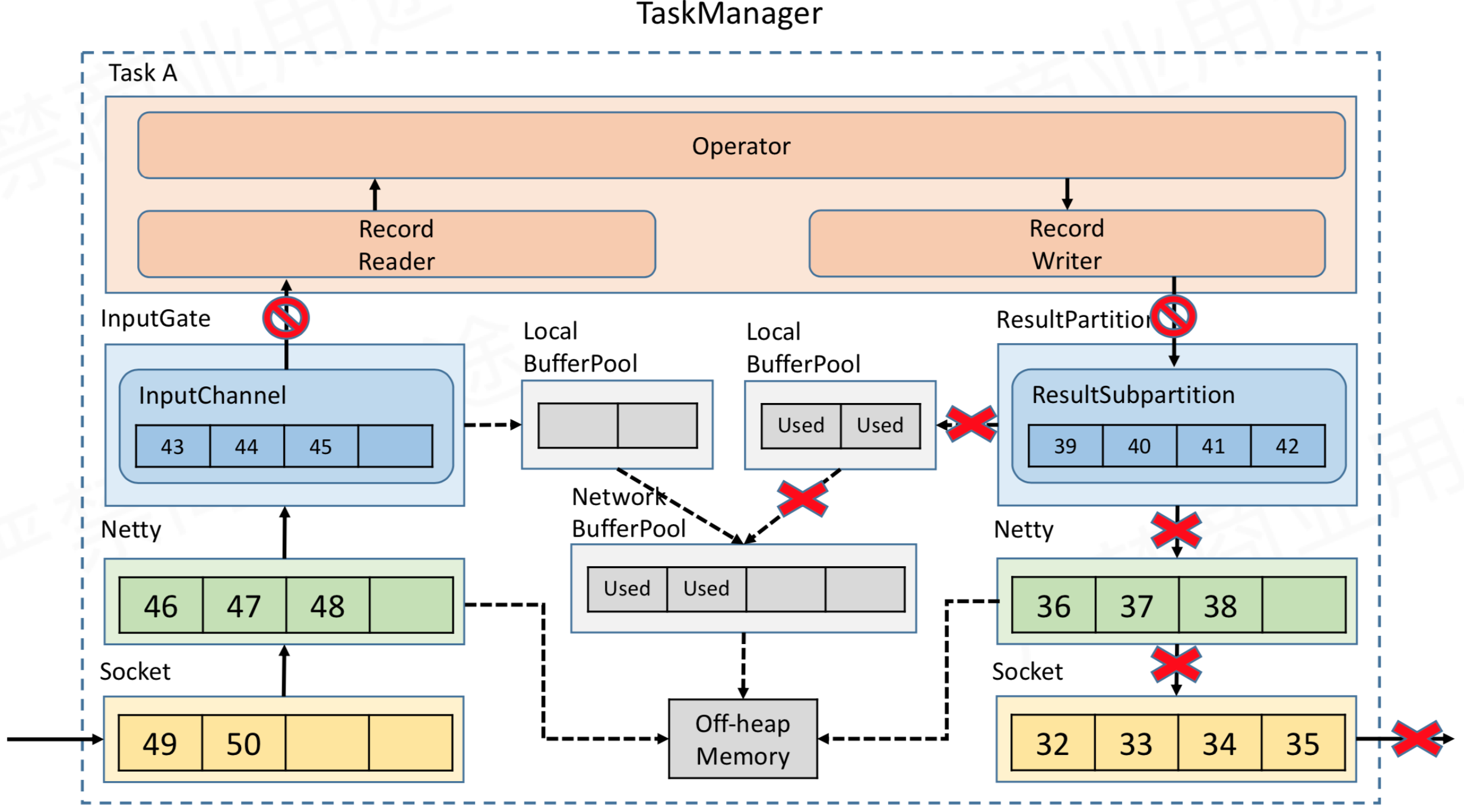
由于operator下游的buffer耗尽,此时Record Writer就会被阻塞,又由于Record Reader、Operator、Record Writer 都属于同一个线程,所以Record Reader也会被阻塞。这时上游数据还在不断写入,不多久network buffer就会被用完,然后跟前面类似,经是netty和socket,压力就会向上游传递。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号