“两地三中心”架构学习
why:
任何一个互联网系统,不论是淘宝,还是Google、Facebook,当发展到一定规模时,都会不可避免的触及到单点瓶颈。这里所说的“单点”,在系统的不同发展阶段表现不同。如下图:

在系统发展初期,服务器和应用单点最先成为瓶颈,解决的方法也很简单,加机器、拆应用;紧接着的数据库单点,解决起来就开始不那么容易了,典型的做法是先垂直拆分,再水平拆分,在这过程中要解决多数据源、数据sharding、透明访问等问题。
当应用越来越多、加的机器越来越多、数据库越来越多,单个机房的容量开始捉襟见肘,装不下这么多服务器。我们选择水平扩展的模式,再建一个新机房,形成双机房架构。到这里好像单点问题都解决了,再有容量问题,我们继续建第三个、第四个机房等等。实际上,我们马上碰到了问题:
1. 双机房架构下,两个机房都是连到同一套DB,DB连接不够用了
2. 第三个、第四个机房建在哪里(地域)?如果建在异地,异地的DB访问耗时就不可忽略。如果所有机房都建在一个地域,将无法应对地震等自然灾害影响。
what:
IDC:全称Internet Data Center,即互联网数据中心。
LDC:全称Logical Data Center,即逻辑数据中心。
两地指的是两个城市;
三中心指的是3个IDC;
两地三中心:在同城部署2个IDC, 在另外一个城市再部署1个IDC;
1.同城IDC——数据同步复制(一般通过存储阵列进行同步镜像方式来同步复制)
2.异地IDC——数据异步复制
IDC3只是一个冷备,平常不处理用户请求,因为IDC1到IDC3是异步复制,存在着比较高的时延。如下图:
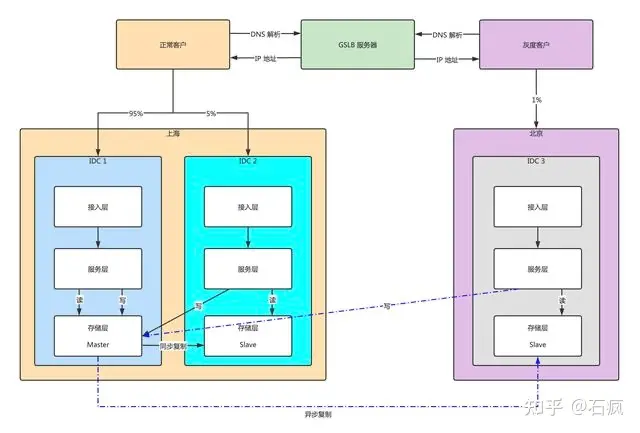
RPO全称recovery point objective,数据恢复的衡量指标,即能够容忍的数据丢失量。RPO=0,指的是已提交的数据都不会被丢失;
同城双中心是指在同城或邻近城市建立两个可独立承担关键系统运行的数据中心,双中心具备基本等同的业务处理能力并通过高速链路实时同步数据,日常情况下可同时分担业务及管理系统的运行,并可切换运行;灾难情况下可在基本不丢失数据的情况下进行灾备应急切换,保持业务连续运行。
与异地灾备模式相比较,同城双中心具有投资成本低、建设速度快、运维管理相对简单、可靠性更高等优点。
异地灾备中心是指在异地的城市建立一个备份的灾备中心,用于双中心的数据备份,当双中心出现自然灾害等原因而发生故障时,异地灾备中心可以用备份数据进行业务的恢复。
how:
两地三中心可提升业务系统的抵御灾难的能力,借用一句话“同城保生产,异地保生存”,如果发生机房或者楼宇级别的灾难,那同城可以保证生产系统在最短时间内恢复业务系统,而异地灾备是保证发生区域性灾难时,生产的关键业务数据不丢失,通过重建生产系统仍然能够保证生产系统恢复到灾难发生之前的业务水平。
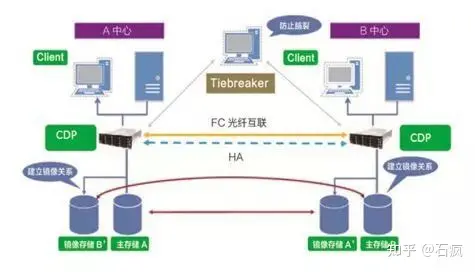
数据备份:
同城双中心的数据采用同步复制,在同城灾备中心建立一个在线更新的数据副本。当有数据下发到生产中心阵列时,阵列间的同步复制都会同时将数据复制一份到同城灾备中心。
同城灾备中心与异地灾备中心之间采用异步复制方式,定期将数据进行复制备份,异步复制支持增量复制方式,可以节省数据备份的带宽占用,缩短数据的备份时间。
灾难检测:
两地三中心的灾难检测通过对资源组状态的监控来判断资源的可用性,包括数据库资源组、网络资源组等。当检测到生产中心有资源组出现fault状态时,同城内生产中心同灾备中心将进行切换,以保证业务的连续性。
容灾切换:
基于应用容灾切换包括一系列的动作:停止灾难节点的部件服务、切断数据复制链路、建立数据容灾基线、启动容灾节点的部件服务、通知前端设备进行业务网络切换。具体动作可以结合实际情况,通过脚本来定制。
恢复回切
回切工作流程和切换流程原理是一样的,只是因为切换的时候是不确定触发的、可能导致业务受部分影响;而回切的时候通过人工确认,选择最小影响的情况下执行操作(比如业务流量非常小的情况下,甚至暂停业务情况下),因此回切推荐采用的是手动切换模式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号