CAP详解
what:
分布式架构的演变:
阶段1:单体应用架构:也就是我们在开始使用的一个Tomcat一个服务器做了所有的事情
阶段2:应用服务器和数据库服务器分离
阶段3:应用服务器集群
阶段4:应用服务器负载用户
阶段5:数据库读写分离
阶段6:添加搜索引擎减少读库压力
阶段7:添加缓存机制缓解数据库压力
阶段8:数据库水平/垂直拆分
阶段9:应用拆分
阶段10:服务化/微服务
分布式系统面临的问题:
通信异常:
网络本身的不可靠性,因此每次网络通信都会伴随着网络不可用的风险(光纤、路由、DNS等硬件设备或系统的不可用),都会导致最终分布式系统无法顺利进行一次网络通信,另外,即使分布式系统各节点之间的网络通信能够正常执行,其延时也会大于单机操作,存在巨大的延时差别,也会影响消息的收发过程,因此消息丢失和消息延迟变的非常普遍。
网络分区
网络之间出现了网络不连通,但各个子网络的内部网络是正常的,从而导致整个系统的网络环境被切分成了若干个孤立的区域,分布式系统就会出现局部小集群,在极端情况下,这些小集群会独立完成原本需要整个分布式系统才能完成的功能,包括数据的事务处理,这就对分布式一致性提出非常大的挑战。
节点故障
节点故障是分布式系统下另一个比较常见的问题,指的是组成分布式系统的服务器节点出现的宕机或"僵死"现象,根据经验来说,每个节点都有可能出现故障,并且经常发生。
三态
分布式系统每一次请求与响应存在特有的“三态”概念,即成功、失败和超时。 分布式系统中,由于网络是不可靠的,虽然绝大部分情况下,网络通信能够接收到成功或失败的响应,但当网络出现异常的情况下,就会出现超时现象,通常有以下两种情况:
由于网络原因,该请求并没有被成功的发送到接收方,而是在发送过程就发生了丢失现象。
该请求成功的被接收方接收后,并进行了处理,但在响应反馈给发送方过程中,发生了消息丢失现象。
分布式一致性:
分布式数据一致性,指的是数据在多份副本中存储时,各副本的数据是一致的。
副本一致性:
分布式系统当中,数据往往存在多个副本。如果是一台数据库处理所有的数据请求。那么通过ACID原则,基本是可以保证数据的一致性。而多个副本就涉及到了数据的copy,这就带来了数据的同步问题。因为我们没有办法保证可是同时更新所有机器当中的包括备份的所有数据。网络延迟,即使我在同一时间给所有机器发送了更新数据的请求,也不能保证这些请求被响应的时间保持一致,依然会存在时间差,那么就会存在某些机器数据不一致的情况。
总的来说,我们无法找到一种能满足分布式系统所有系统属性的分布式一致性解决方案。因此如何既保证数据的一致性,又保证系统的运行性能,是每个分布式系统都需要权衡和考虑的。也正如此,才诞生了数据一致性级别。
一致性分类:
强一致性:这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验好,但实现起来往往是对系统的性能影响大。强一致性很难实现。
弱一致性:这种一致性级别约束了系统在写入成功后,不承诺立即可以读取到写入的数据,也不承诺多久后可以达到数据的一致,但是会尽可能的保证某个时间级别(比如秒级别)后数据可以达到最终一致。
读写一致性:用户读取自己写入结果的一致性,保证用户永远能够第一时间看到自己更新的内容。 比如我们发一条朋友圈,朋友圈的内容是不是第一时间被朋友看见不重要,但是一定要显示在自己的列表上。
单调读一致性: 本次读到的数据不能比上次读到的旧。 由于主从节点更新数据的时间不一致,导致用户在不停地刷新的时候,有时候能刷出来,再次刷新之后会发现数据不见 了,再刷新又可能再刷出来,就好像遇见灵异事件一样
因果一致性:指的是:如果节点 A 在更新完某个数据后通知了节点 B,那么节点 B 之后对该数据的访问和修改都是基于 A 更新后的值。于此同时,和节点 A 无因果关系的节点 C 的数据访问则没有这样的限制。
最终一致性:最终一致性是所有分布式一致性模型当中最弱的。可以认为是没有任何优化的“最”弱一致性,它的意思是说,我不考虑所有的中间状态的影响,只保证当没有新的更新之后,经过一段时间之后,最终系统内所有副本的数据是正确的。 它最大程度上保证了系统的并发能力,也因此,在高并发的场景下,它也是使用最广的一致性模型。
CAP:
2000 年,Eric Brewer教授提出了CAP猜想。2年后,Seth Gilbert和Nancy Lynch从理论上证明了猜想的可能性,从此CAP 理论成为了:分布式计算领域的公认理论。
CAP 理论告诉我们:在一个分布式系统中,不可能同时满足一致性(Consistency),可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足其中的2个。
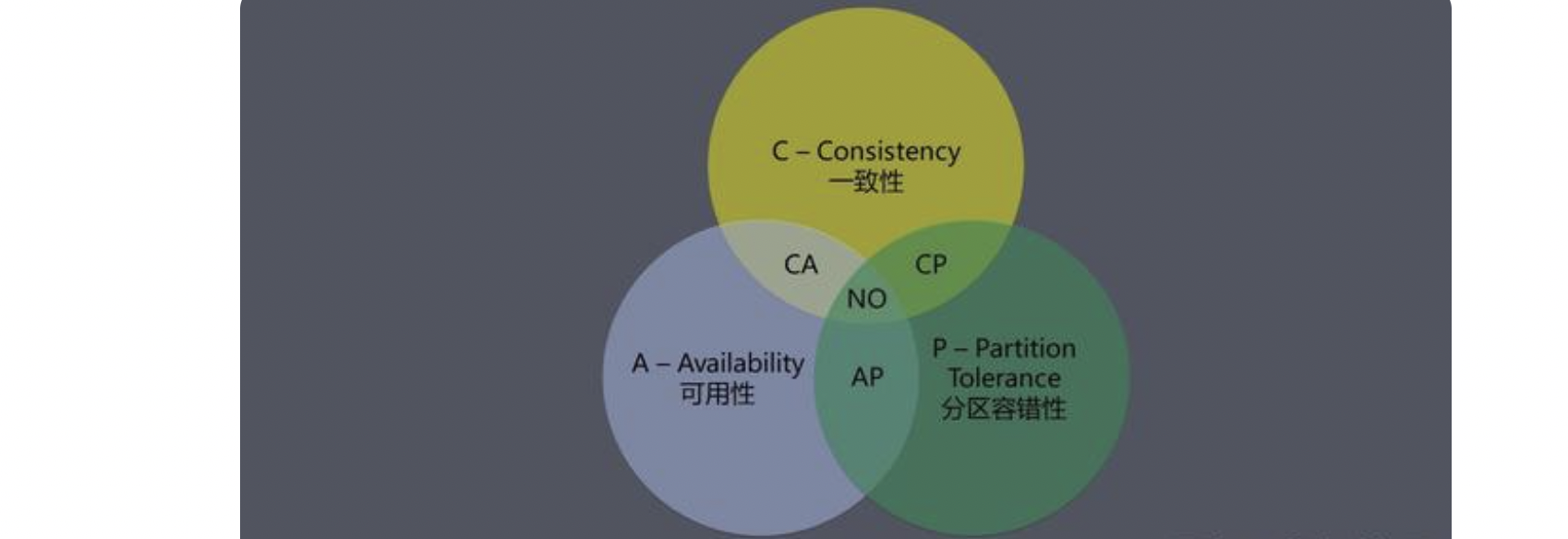
一致性(Consistency):在一个一致性的系统中,客户端向任何服务器发起一个写请求,将一个值写入服务器并得到响应,那么之后向任何服务器发起读请求,都必须读取到这个值(或者更加新的值),即数据在多个副本之间能够保持一致的特性(强一致性)。而像Redis的主从结构,Zookeeper的Master/Slave结构,主从之间的数据保持一致,这些都是最终一致性。
可用性(Availability):系统一直处于可用状态,能正常响应数据,但是不保证响应数据为最新数据。
分区容错性(Partition tolerance):分布式系统在遇到网络故障,产生网络分区时,仍然能够对外提供正常的服务,除非整个网络环境都发生了故障。
证明——CAP只能3选2:
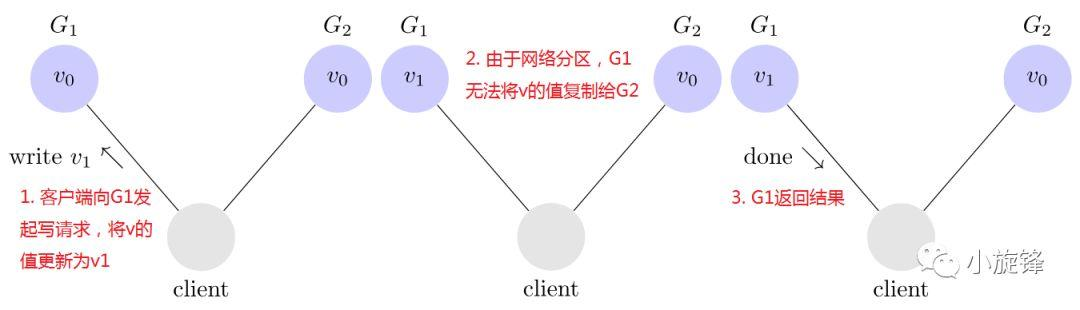
假设存在一个同时满足这三个属性的系统,我们第一件要做的就是让系统发生网络分区。客户端向G1发起写请求,将v的值更新为v1,因为系统是可用的,所以G1必须响应客户端的请求,但是由于网络是分区的,G1无法将其数据复制到G2,由于网络分区导致不一致:
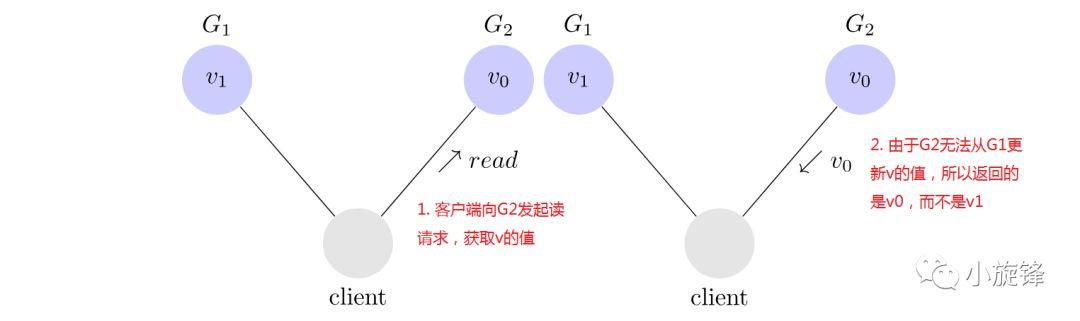
接着,客户端向G2发起读v的请求,再一次因为系统是可用的,所以G2必须响应客户端的请求,又由于网络是分区的,G2无法从G1更新v的值,所以G2返回给客户端的是旧的值v0。由于网络分区导致数据不一致,即这违背了一致性。
demo:
- 数据库的主从结构不需要强一致性,实现最终一致性也可以解决问题。
- Zookeeper的脑裂问题即使出现了分区也只能投出一个Leader,只有一个集群提供服务,当网络连通后,再同步数据。
BASE理论:
全称:Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写,来自 ebay 的架构师提出。
BASE是对CAP中一致性和可用性权衡的结果,BASE理论的核心思想是:**即使无法做到强一致性,但是每个应用可以根据自身业务特点,采用适当的方式来使系统达到最终一致性**
Basically Available:基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但请注意,这绝不等价于系统不可用。
1. 响应时间损失:例如系统正常状态下0.3s将数据返回,出现问题后需要1-2s将数据进行返回
2. 功能上损失(降级):例如淘宝网站在双11进行大促,或者活动秒杀,当你点击某个功能的时候出现"被挤爆了稍后再试.."等等..都是功能上损失
Soft state:软状态
相对于一致性“硬状态”而言的(要求多个节点的数据副本都是一致的,这是一种 “硬状态”)。
软状态指的是:允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本之间进行数据同步的过程中存在延迟。
Eventually consistent:最终一致性
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号