Flink的状态类型及关系
what:
状态类型:Managed State和Raw State
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。从名称中也能读出两者的区别:Managed State是由Flink管理的,Flink帮忙存储、恢复和优化;Raw State是开发者自己管理的,需要自己序列化。

具体区别有:
状态管理的方式:Managed State由Flink Runtime托管,状态是自动存储、自动恢复的,Flink在存储管理和持久化上做了一些优化。当我们横向伸缩,或者说我们修改Flink应用的并行度时,状态也能自动重新分布到多个并行实例上。Raw State是用户自定义的状态。
状态的数据结构:Managed State支持了一系列常见的数据结构,如ValueState、ListState、MapState等。Raw State只支持字节,任何上层数据结构需要序列化为字节数组。使用时,需要用户自己序列化,以非常底层的字节数组形式存储,Flink并不知道存储的是什么样的数据结构。
使用场景:绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State。Raw State是在已有算子和Managed State不够用时,用户自定义算子时使用。
Managed State:Keyed State和Operator State
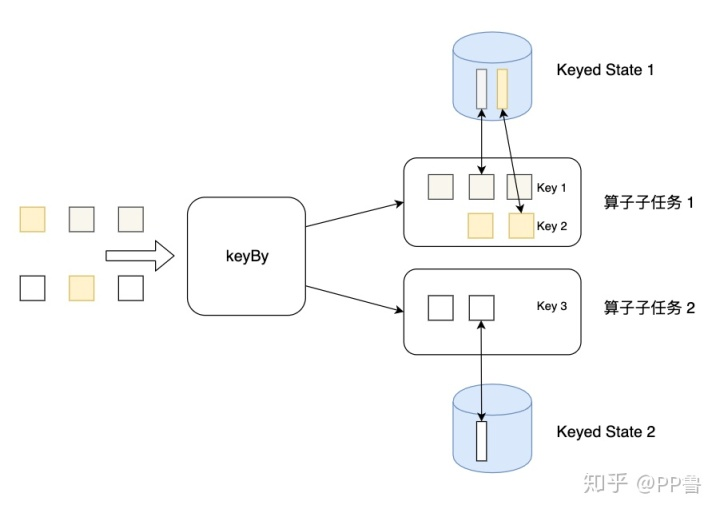
Keyed State是KeyedStream上的状态。假如输入流按照id为Key进行了keyBy分组,形成一个KeyedStream,数据流中所有key相同(如:id为1)的数据共享一个状态,可以访问和更新这个状态,以此类推,每个Key对应一个自己的状态。下图展示了Keyed State,因为一个算子子任务可以处理一到多个Key,算子子任务1处理了两种Key,两种Key分别对应自己的状态。
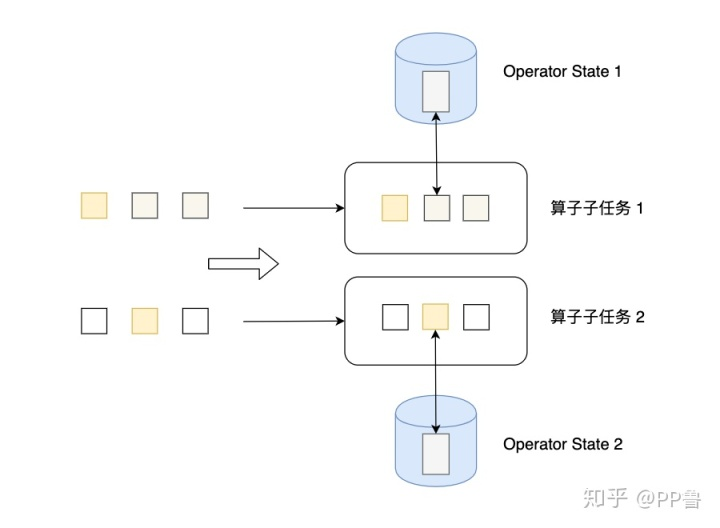
Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。下图展示了Operator State,算子子任务1上的所有数据可以共享第一个Operator State,以此类推,每个算子子任务上的数据共享自己的状态。
状态State之间的关系:
无论是Keyed State还是Operator State,Flink的状态都是基于本地的,即每个算子子任务(或者说每个算子实例)维护着这个算子子任务对应的状态存储,算子子任务之间的状态不能相互访问。

横向扩展:
状态的横向扩展问题主要是指修改Flink应用的并行度变化,确切的说,每个算子的并行实例数或算子子任务数发生了变化,应用需要关停或启动一些算子子任务,某份在原来某个算子子任务上的状态数据需要平滑更新到新的算子子任务上。其实,Flink的Checkpoint就是一个非常好的在各算子间迁移状态数据的机制。算子的本地状态将数据生成快照(snapshot),保存到分布式存储(如HDFS)上。横向伸缩后,算子子任务个数变化,子任务重启,相应的状态从分布式存储上重建(restore)。
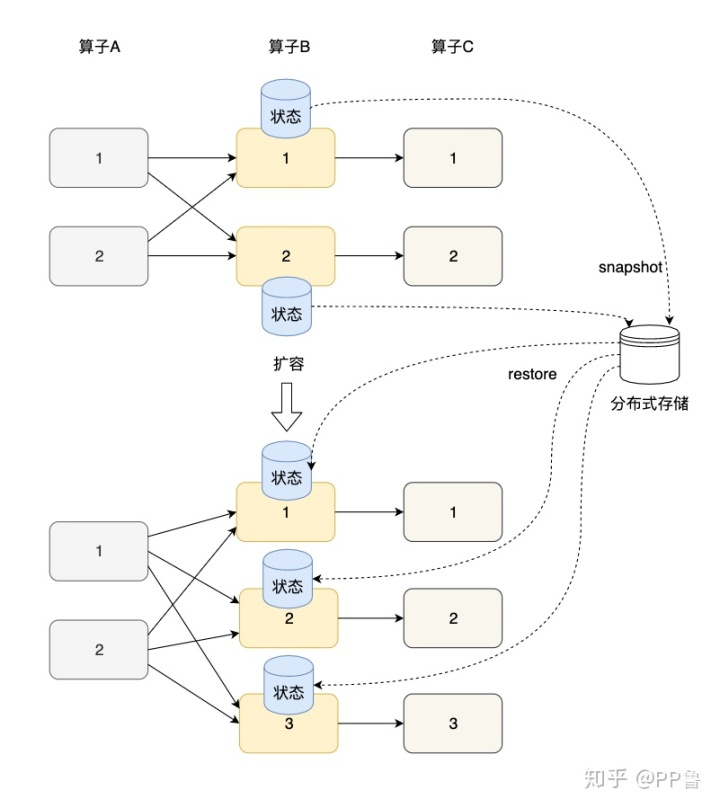
对于Keyed State和Operator State,横向伸缩机制不太相同。由于每个Keyed State总是与某个Key相对应,当横向伸缩时,Key总会被自动分配到某个算子子任务上,因此Keyed State会自动在多个并行子任务之间迁移。
对于一个非KeyedStream,流入算子子任务的数据可能会随着并行度的改变而改变。如上图所示,假如一个应用的并行度原来为2,当并行度改为3时,数据流被拆成3支,或者并行度改为1,数据流合并为1支。Operator State有两种状态分配方式:一种是均匀分配,另一种是将所有状态合并,再分发给每个实例上。
Keyed State的使用方法:
对于Keyed State,Flink提供了几种现成的数据结构供我们使用:
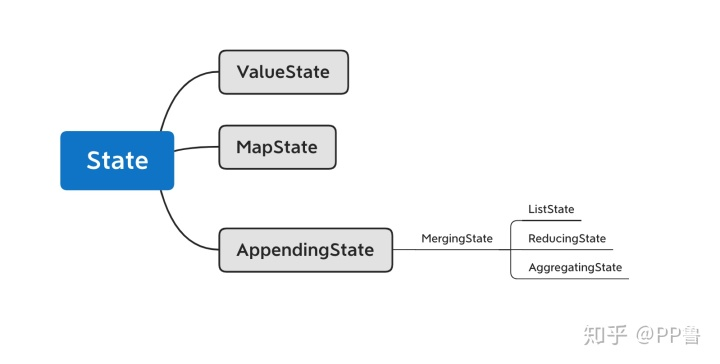
ValueState[T]是单一变量的状态,T是某种具体的数据类型,比如Double、String,或我们自己定义的复杂数据结构。我们可以使用value()方法获取状态,使用update(value: T)更新状态。
MapState[K, V]存储一个Key-Value map,其功能与Java的Map几乎相同。get(key: K)可以获取某个key下的value,等。
ListState[T]存储了一个由T类型数据组成的列表。我们可以使用add(value: T),等。
Operator List State的使用方法:
状态从本质上来说,是Flink算子子任务的一种本地数据,为了保证数据可恢复性,使用Checkpoint机制来将状态数据持久化输出到存储空间上。状态相关的主要逻辑有两项:一、将算子子任务本地内存数据在Checkpoint时snapshot写入存储;二、初始化或重启应用时,以一定的逻辑从存储中读出并变为算子子任务的本地内存数据。Keyed State对这两项内容做了更完善的封装,开发者可以开箱即用。对于Operator State来说,每个算子子任务管理自己的Operator State,或者说每个算子子任务上的数据流共享同一个状态,可以访问和修改该状态。Flink的算子子任务上的数据在程序重启、横向伸缩等场景下不能保证百分百的一致性。换句话说,重启Flink应用后,某个数据流元素不一定会和上次一样,还能流入该算子子任务上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号