Flink原理与实现:Flink中的状态管理,keygroup,namespace
资源来源:https://blog.csdn.net/u013939918/article/details/107068531/
namespace
维护每个subtask的状态
上面Flink原理与实现的文章中,有引用word count的例子,但是都没有包含状态管理。也就是说,如果一个task在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需要重新计算。从容错和消息处理的语义上(at least once, exactly once),Flink引入了state和checkpoint。
首先区分一下两个概念,state一般指一个具体的task/operator的状态。而checkpoint则表示了一个Flink Job,在一个特定时刻的一份全局状态快照,即包含了所有task/operator的状态。
Flink通过定期地做checkpoint来实现容错和恢复。
State
在Flink中,状态始终与特定算子相关联。总的来说,有两种类型的状态:
- 算子状态(operator state)
- 键控状态(keyed state)
算子状态 (operator state)
算子状态的作用范围限定为算子任务(任务概念:https://www.cnblogs.com/sfzlstudy/p/15683780.html)。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问。
Flink为算子状态提供三种基本数据结构:
(1)列表状态(List state)
将状态表示为一组数据的列表。
(2)联合列表状态(Union list state)
也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
(3)广播状态(Broadcast state)
如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
Keyed State
顾名思义,就是基于KeyedStream上的状态。这个状态是跟特定的key绑定的,对KeyedStream流上的每一个key,可能都对应一个state。
Operator State与Keyed State不同.
Operator State跟一个特定operator的一个并发实例绑定,整个operator只对应一个state。相比较而言,在一个operator上,可能会有很多个key,从而对应多个keyed state。
举例来说,Flink中的Kafka Connector,就使用了operator state。它会在每个connector实例中,保存该实例中消费topic的所有(partition, offset)映射。
原始状态和Flink托管状态 (Raw and Managed State)
Keyed State和Operator State,可以以两种形式存在:原始状态和托管状态。
托管状态是由Flink框架管理的状态,如ValueState, ListState, MapState等。
下面是Flink整个状态框架的类图,还是比较复杂的,可以先扫一眼,看到后面再回过来看: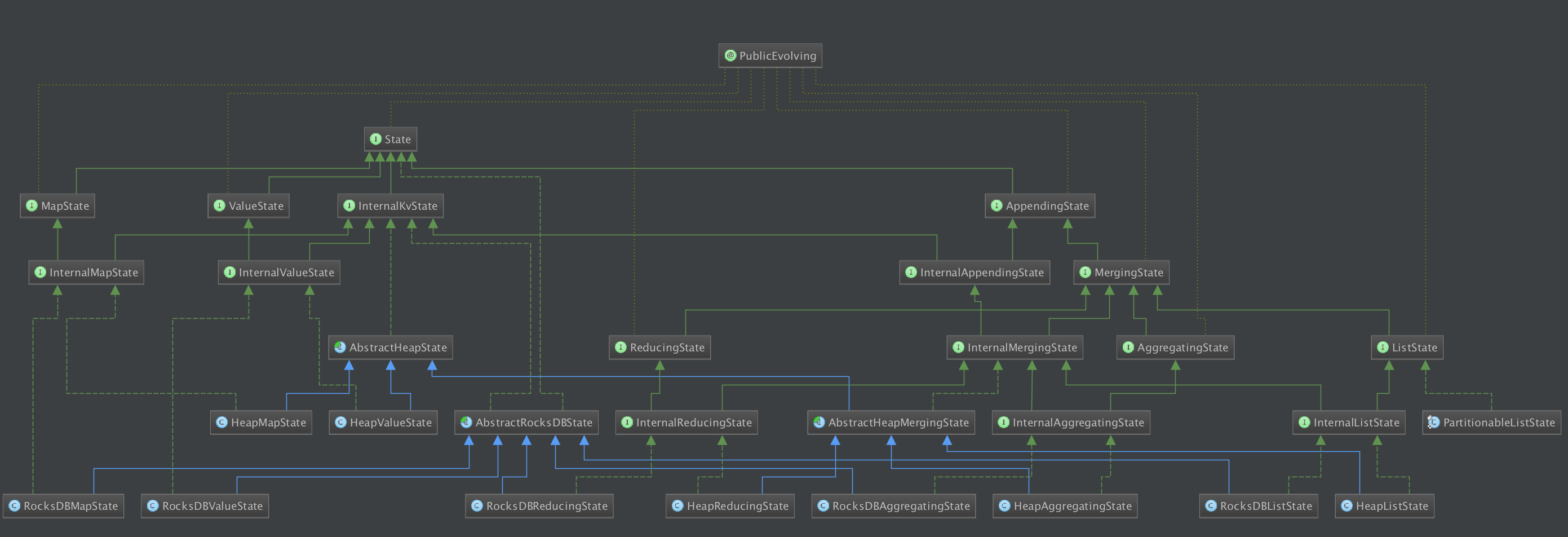
通过框架提供的接口,我们来更新和管理状态的值。
而raw state即原始状态,由用户自行管理状态具体的数据结构,框架在做checkpoint的时候,使用byte[]来读写状态内容,对其内部数据结构一无所知。
通常在DataStream上的状态推荐使用托管的状态,当实现一个用户自定义的operator时,会使用到原始状态。
下文中所提到的状态,如果没有特殊说明,均为托管状态。
使用Keyed State
首先看一下Keyed State下,我们可以用哪些原子状态:
- ValueState:即类型为T的单值状态。这个状态与对应的key绑定,是最简单的状态了。它可以通过update方法更新状态值,通过value()方法获取状态值。
- ListState:即key上的状态值为一个列表。可以通过add方法往列表中附加值;也可以通过get()方法返回一个Iterable<T>来遍历状态值。
- ReducingState:这种状态通过用户传入的reduceFunction,每次调用add方法添加值的时候,会调用reduceFunction,最后合并到一个单一的状态值。
- FoldingState:跟ReducingState有点类似,不过它的状态值类型可以与add方法中传入的元素类型不同(这种状态将会在Flink未来版本中被删除)。
- MapState:即状态值为一个map。用户通过put或putAll方法添加元素。
以上所有的状态类型,都有一个clear方法,可以清除当前key对应的状态。
需要注意的是,以上所述的State对象,仅仅用于与状态进行交互(更新、删除、清空等),而真正的状态值,有可能是存在内存、磁盘、或者其他分布式存储系统中。相当于我们只是持有了这个状态的句柄(state handle)。
接下来看下,我们如何得到这个状态句柄。Flink通过StateDescriptor来定义一个状态。这是一个抽象类,内部定义了状态名称、类型、序列化器等基础信息。与上面的状态对应,从StateDescriptor派生了ValueStateDescriptor, ListStateDescriptor等descriptor。
具体如下:
ValueState getState(ValueStateDescriptor)
ReducingState getReducingState(ReducingStateDescriptor)
ListState getListState(ListStateDescriptor)
FoldingState getFoldingState(FoldingStateDescriptor)
MapState getMapState(MapStateDescriptor)
接下来我们看一下创建和使用ValueState的例子:
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/**
* ValueState状态句柄. 第一个值为count,第二个值为sum。
*/
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// 获取当前状态值
Tuple2<Long, Long> currentSum = sum.value();
// 更新
currentSum.f0 += 1;
currentSum.f1 += input.f1;
// 更新状态值
sum.update(currentSum);
// 如果count >=2 清空状态值,重新计算
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // 状态名称
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), // 状态类型
Tuple2.of(0L, 0L)); // 状态默认值
sum = getRuntimeContext().getState(descriptor);
}
}
// ...
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)
由于状态需要从RuntimeContext中创建和获取,因此如果要使用状态,必须使用RichFunction。普通的Function是无状态的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号