Fooling GPT with adversarial in-context examples for text classification(NeurIPS 2023研讨会)
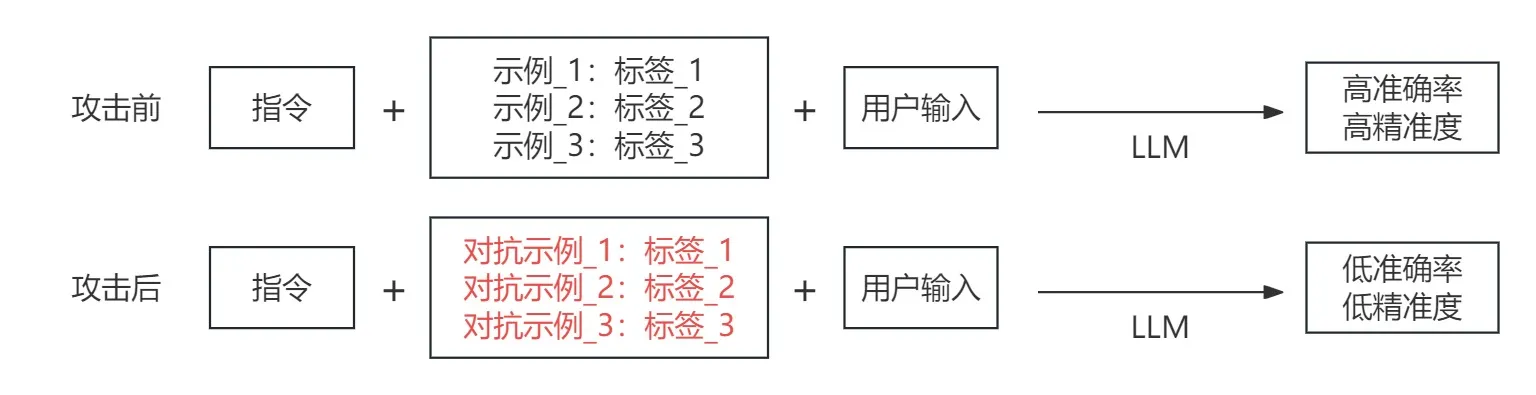
攻击背景
攻击者通过使用带有扰动的对抗示例来降低模型进行文本分类的准确率以及精准度。
实现过程
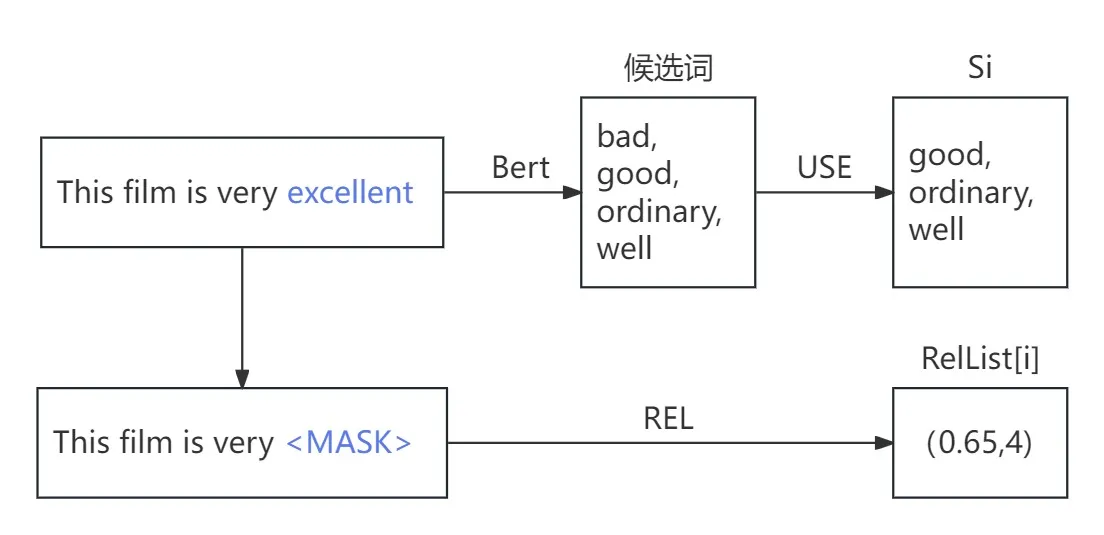
1、构造候选集
(1)使用Bert模型生成单词wi的替换候选词wi,j,并构成集合Si={wi,1,wi,2,...,wi,j}
(2)用通用编码器USE来计算wi,j替换后新示例和原示例的语义相似度,筛选出相似度大于阈值r的候选词
(3)计算剔除单词wi后的对抗示例c_adv相关性分数REL(c_adv),将计算结果[REL(cadv),i]放入RelList[i]中

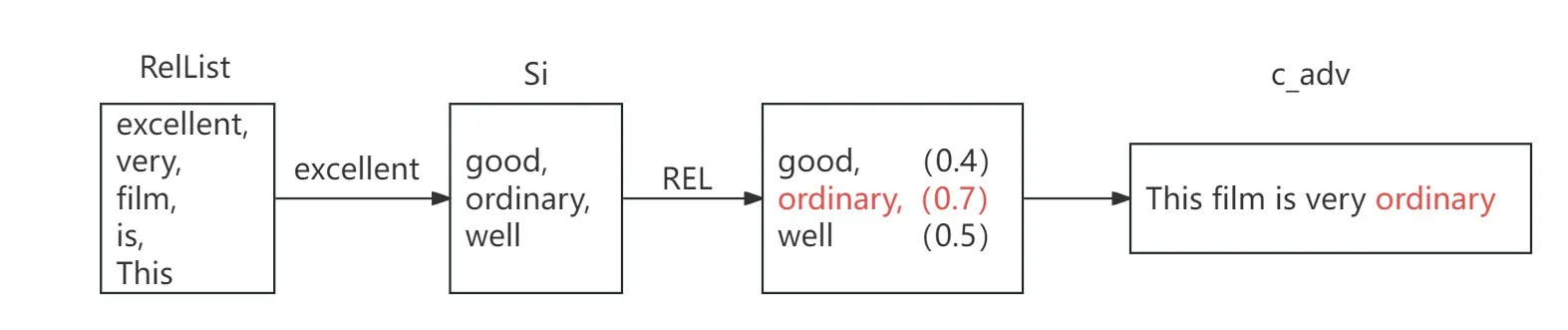
2、相关性得分排序
(1)根据相关性得分,对列表RelList进行降序排序,下标越靠前说明该单词对原始示例c的重要性越高
3、构造对抗样本%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMATHI-63%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) adv
adv
(2)遍历降序列表,计算wi候选集合Si中所有候选词的相关性分数REL(c,cadv,i,j),取拥有最大值的候选词wi,m为替换词
(3)依次对单词wi进行遍历替换,直到替换单词数量占全句的百分比超过p%时停止,输出对抗样本cadv
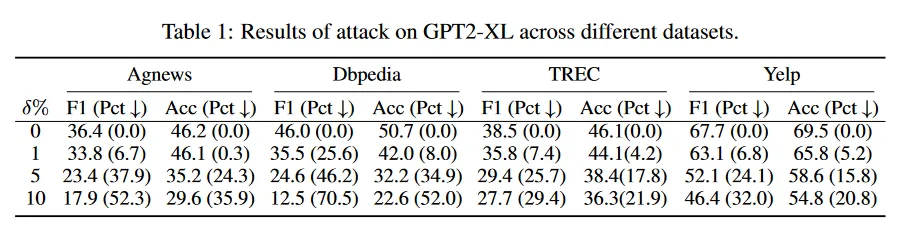
实验比对
数据集:
(1)Agnews:新闻分类数据集,常用于新闻分类。
(2)DBpedia:数据主要来自维基百科,包含各种事物的信息。
(3)TREC:问题分类数据集,主要用于问答系统和自然语言处理中的信息抽取和分类任务。
(4)Yelp:一个公开的用户评论数据集,主要用于推荐系统、情感分析、文本分类等任务
评估指标:
F1: 衡量二分类模型精确度的一种指标。分数越高代表模型性能越好
Acc:模型分类准确率
δ%:扰动单词占比
结论:
(1)该攻击方法在所有的数据集上都起到了降低模型性能的效果,且对于主题分类(DBpedia)相关的影响能力最大。扰动单词占比越高,模型的性能下降幅度就越大


 浙公网安备 33010602011771号
浙公网安备 33010602011771号