A Differentiable Language Model Adversarial Attack on Text Classifiers(IEEE Access 2022)
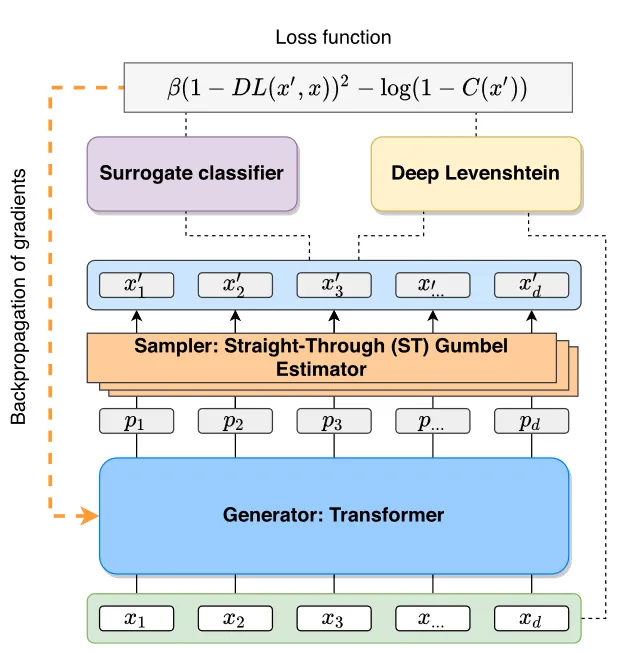
1、Gumbel-Softmax随机采样
优势:
(1)函数可导,能够利用反向传播算法快速计算出梯度
(2)引入Gumbel分布,能够在保证函数可导的情况下进行随机采样
流程:
(1)根据用户输入xi生成类别概率集P∈{π_1,π_2,...,π_k}
(2)根据概率集P和随机变量g抽取样本x'i,其中:
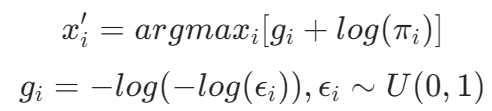
通过添加gi来引入随机性,添加gi后的采样结果依旧服从于原始分布
(3)在正向传播中会采用argmax进行计算,而在反向传播中则使用softmax进行近似计算
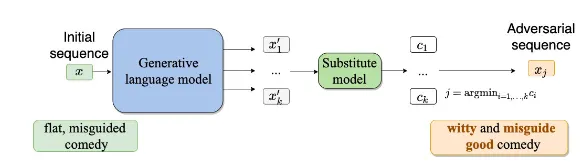
生成模型:四层Transformer模型
替代模型:
【1】白盒场景:RoBerta
【2】黑盒场景:LSTM
2、模型参数更新
优化目标:
最小化正确分类概率的同时最小化原始示例的编辑变化
损失函数:
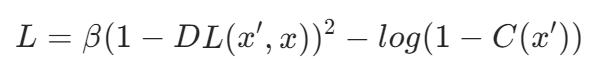
(1)DL(x',x):编辑距离,指x转变为x'所需的最小编辑次数
例子:DL(kitten,sitting)=3
【1】kitten → sitten (k→s)
【2】sitten → sittin (e→i)
【3】sittin → sitting (insert a 'g')
(2)β:编辑距离加权系数,若需要进行多次修改才能从x变成x',则需要对这种情况进行惩罚
(3)C(x'):分类器,输出x'正确标签分类的概率(RoBERTa)
实验比对
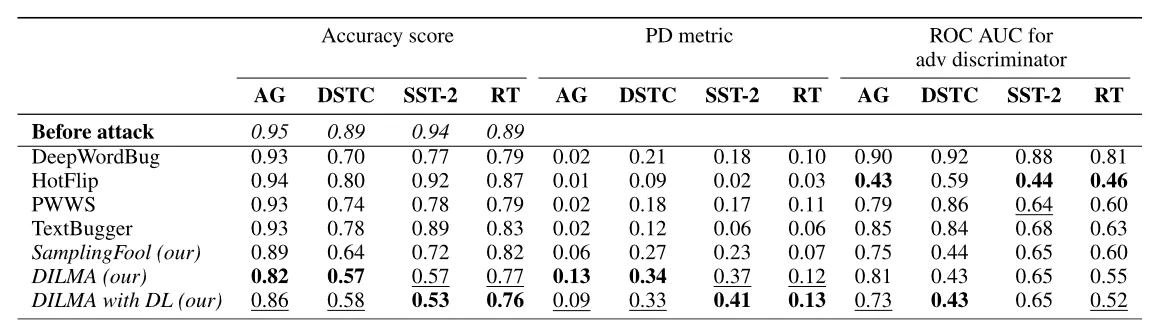
评估指标:
(1)Accuracy score:最终生成文本的准确率
(2)PD:攻击前后模型进行正确分类的概率差异,差异越大攻击效果越好
(3)ROC/AUC:用于评价分类检测结果的好坏,越小攻击效果越好
数据集:
(1)AG:由各种网络新闻文章组成,题材包括世界、体育、商业、科学技术
(2)DSTC:和对话任务相关的特殊数据集,内容为根据对话提取对话意图及解释
(3)SST: 电影评论并带有情感标签
(4)RT:烂番茄影评并带有情感标签

 浙公网安备 33010602011771号
浙公网安备 33010602011771号