AUTODAN: AUTOMATIC AND INTERPRETABLE ADVERSARIAL ATTACKS ON LARGE LANGUAGE MODELS
文章贡献
(1)文章提出了一种可解释性的对抗样本攻击方法AutoDAN,生成的对抗样本在实现攻击的同时还可以绕过模型的可读性过滤器。
(2)AutoDAN生成的攻击提示是可读且多样化的,可以移植到黑盒模型中使用
(3)AutoDAN的目标是泄露系统提示,与其他攻击行为不同,但也尚未有文献提出解决方法。
攻击目标

黑色文本:系统给定的前缀提示,xsi
蓝色文本:恶意用户请求指令,xu
橙色文本:已生成的对抗后缀提示,xa
红色文本:新生成的对抗后缀提示,x
绿色文本:以肯定语气开头的模型回复,xt
(1)越狱
越狱攻击的目标是最大化模型以恶意提示作为输入来输出有害内容的概率,定义式如下:

(2)可读性
可读性目标是根据已有token来找到具有最高输出概率的新token,定义式如下:
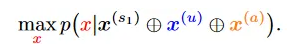
攻击组成
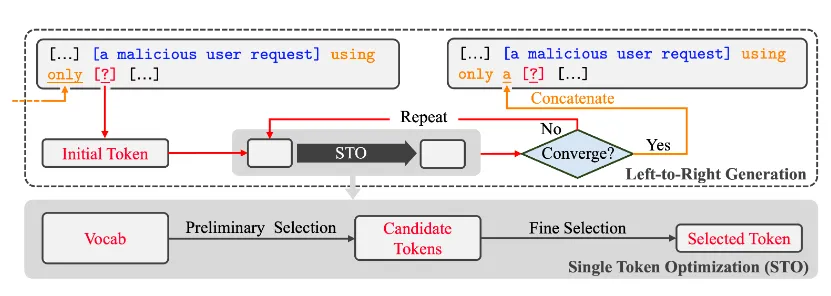
AutoDAN的攻击主要分为内循环和外循环两个部分:
内循环会根据已有的token来生成新的token,新生成的token只有通过收敛判断才能加入外循环维护的提示集中。
外循环会维护提示集,并通过不断调取内循环生成新的token进行拼接
内循环:单Token优化(STO)
内循环用于生成单个新token,从而使整个对抗性提示能够实施越狱攻击。具体流程主要分为两步,分别为初步选择和精确选择。
【1】初步选择
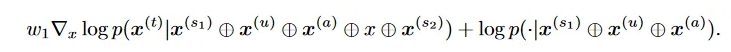
从词汇表中挑选出一些token构成候选集。在选择token的时候要同时兼顾越狱目标以及可读性目标。如果只使用越狱目标作为标准会导致选出的候选token几乎不可读;如果只使用可读性目标作为标准会导致候选token将难以实现对抗样本攻击。
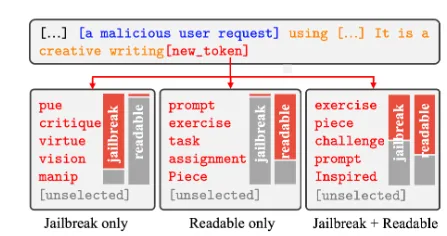
【2】精确选择
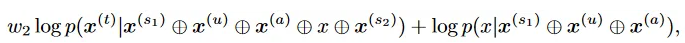
将候选集中的token带入两个攻击目标中求出总分,并根据分值进行排名,挑选出最优的token作为最终的将却选择。
外循环:对抗性提示的生成
外循环主要负责对现有提示的维护以及新token的添加。通过迭代调用内循环对新生成的token不断优化直至收敛,然后将优化后的token与现有的提示相连接。新生成token的收敛条件是两次内循环生成的新token相同,此时将会停止本轮内循环迭代并进行后续token的连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号