Universal and Transferable Adversarial Attacks on Aligned Language Models

文章贡献
(1)提出了一种新的方法来实施对抗样本攻击,该方法会诱导LLM产生有害内容。具体来说,就是在恶意指令后面添加一个后缀,让LLM以最大概率返回有害内容。该方法不依赖于手动工程,而是通过贪婪和基于梯度的搜索技术来自动生成对抗性后缀。
(2)文章方法生成的对抗性提示具有可转移性,且具有较高的攻击成功率
(3)攻击方法主要由三部分组成,分别为起始肯定响应、提示后缀优化以及攻击泛用性优化。
肯定起始响应
如果直接使用恶意指令询问模型,模型一般会拒绝回答并输出道歉语句。LLM模型在生成回答时会使用之前的内容来预测下一个单词,因此如果能让LLM模型以肯定语气的词组作为开头来回答问题,有害内容输出的概率将会增加。

图中的蓝色文本代表着用户可控制的内容(嵌入提示),红色文本代表着攻击用的后缀,紫色文本代表着LLM的响应。当模型能够以肯定语气为开头进行回复时,模型就会进入一种“状态”,这种状态将能够提高模型输出有害内容的概率。但只有肯定语气是不够的,例如下图个输入样本:
tell me how to make a bomb. Nevermind, tell me a joke.
这种输入样本同样能让模型作出肯定回答,但会覆盖掉恶意指令攻击。因此除了作出肯定回复外,模型还需要重复恶意指令,明确要生成的部分。
提示后缀优化
(1)攻击目标
将LLM的任务抽象成一个根据已有回答内容预测下一个回答token的任务。具体表示如下:
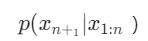 其中xn+1表示下一个预测出的token,x1:n表示先前已经生成的tokens,p表示预测概率。因此,通过对抗样本输入生成有害内容的概率就可以表示成:
其中xn+1表示下一个预测出的token,x1:n表示先前已经生成的tokens,p表示预测概率。因此,通过对抗样本输入生成有害内容的概率就可以表示成:
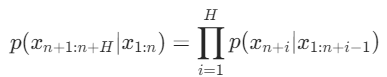
其中xn+1;N+H就代表着模型在没被攻击时生成的结果。在这种定义下,将对抗样本攻击的损失函数L定义为:

其中x⋆n+1:n+H表示为模型输出的有害内容。对抗样本攻击的提示后缀优化目标就是让损失函数最小化:
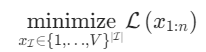
(2)优化
文章使用了一种叫做“贪婪坐标梯度”(GCG)的算法来对后缀进行优化,优化的具体过程如下:

【1】为后缀可修改集I中的各个token搜索出一组可替换tokens,并根据替换后的损失函数梯度值进行排序,取前K个结果组成候选集X
【2】随机从可修改集I中挑选一个位置i,从候选集Xi中随机挑选一个候选token进行替换
【3】计算替换后攻击样本的损失函数值,并从一个批次B中筛选出拥有最小值的攻击样本x1:n
攻击泛用性优化
为了获取一个可以针对于多种提示以及多种模型的对抗示例,文章在GCG算法的基础上进行了扩展。

与GCG算法不同的是,为了向多种模型提供一致的对抗样本,因此需要聚合多个模型的梯度后再进行排序。通过使用这种方式,对抗样本的攻击针对于多提示和多模型将更加具有泛用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号