Adversarial Demonstration Attacks on Large Language Models
(1)文章提出了一种名为advICL的攻击方法,仅操作情景示例来误导模型。情景示例为测试示例提供了演示。作为提示的一部分,可以帮助LLM来获得更好的效果以及推理性能 。随着对抗情景示例的增加,情景学习的稳健性会下降。
(2)考虑到上下文学习提示的长度较长,对抗性文本和原始文本之间的标准全局相似约束效率会很低文章引入了一种特定于情景示例的相似性方法,该方法对每个单独的情景示例进行约束,确保了对抗性示例的质量
(3)情景示例的一个固有属性是可以和不同的输入一起使用,因此攻击者可以在不知道输入示例的情况下攻击它。文章提出了advICL的可移植版本Transferable-advICL,
【1】从情景示例集中随机选择一组文本示例,构建小攻击示例集;
【2】随机打乱小攻击示例集中的示例,防止出现局部最小的情况
【3】使用advICL初始化示例并训练出新的扰动情景示例
相关工作
(1)情景示例
情景示例的性能主要受到示例选择、示例排序、示例标签选择的影响。目前关于情景示例的鲁棒性研究主要集中在不稳定性上,而没有关注于扰动。
(2)对抗样本
文章仅仅关注于字符级别和单词级别的扰动
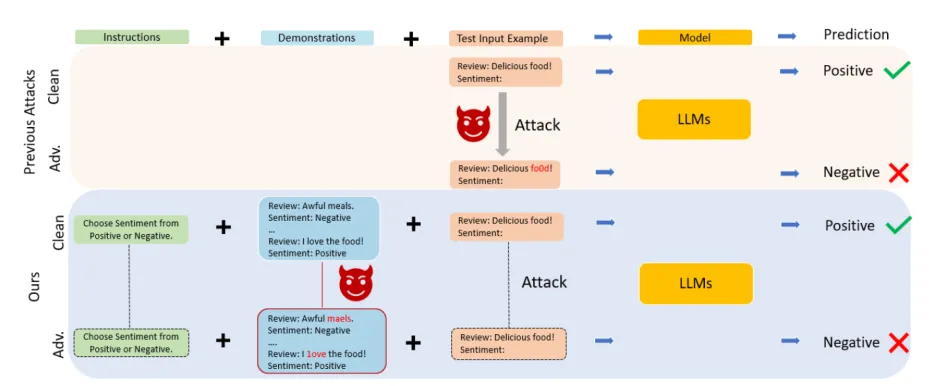
方法
(1)背景-上下文学习
条件文本生成问题:给定一个语言模型f,目标是根据输入测试示例x和情景示例集C生成输出y_test。其中C包含具有特定模板s的N个串联数据标签对(x_i,y_i),i∈N。它们的关系如下:
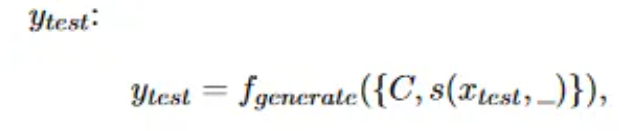
其中s(x_test,...)表示情景示例相同但是标签为空的数据对,y_test来自于候选分类标签集Y={c1,...,ck}。分类 ck与特定 token 的映射函数定义为 V(cki)
最后,上下文学习的预测结果就是以情景示例集C和测试示例xtest为输入,预测为标签ytest的最大概率值。

(2)advICL
【1】攻击目标:输入测试示例xtest和有扰动的情景示例Cδ,让模型输入对应真实标签ytest的概率最小化。
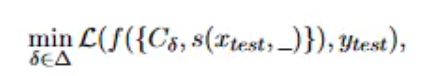
其中s(·)表示为情景示例的特定模板,模板中标签为空。δ代表扰动,L代表logits函数。

【2】攻击方法:通过对情景示例中的一个token实施修改来操纵预测结果,并对情景示例 C中的每个数据标签对 (xi,yi)都单独设置一个扰动界限Δi,扰动界限的测定通过余弦相似度实现。
具体做法:
(a) 从情景示例集C中的xi里选择单词,并根据重要性形成一个WordList。
(b) 对WordList中的每一个单词进行扰动,扰动方式包括字符插入、字符删除、字符交换以及单词交换,最终筛选出最好的修改方法
(c) 带入情景提示集C,使用函数L计算出ytest的概率。使ytest的概率尽可能小且余弦相似度约束保持在扰动界限Δi内。
(d) 不断迭代WordList,直到攻击成功为止
(3)WordList
(a) 初始化WordList 为空集
(b) 遍历句子中的每一个词wj,计算分数Dwj。第一项表示完整情景示例的预测概率,第二项表示缺少单词wj的情景示例的预测概率。
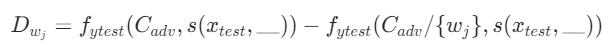
(c) 对所有词的分数Dwj进行降序排序,输出结果
(4) 修改方法筛选
(a) 将单词wj的所有修改组合(字符插入、字符删除、字符交换、单词交换)组成集合bugs
(b) 遍历集合bugs,每次进行单词替换后计算分数Dwj
(c) 挑选出分数最高的修改方法并输出结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号