AN LLM CAN FOOL ITSELF: A PROMPT-BASED ADVERSARIAL ATTACK
文章贡献
(1)文章在类似于GPT3.5这样的黑盒LLM上评估发现,AdvGLUE和 AdvGLUE++既无效也低效。并且构建它们需要花费大量计算资源,降低了审计LLM对抗鲁棒性的实用性。
AdvGLUE/ AdvGLUE++: 用于评估LLM稳健性的对抗数据集
(2)文章提出了PromptAttack,可以有效地自行发现受害者LLM的漏洞。
攻击组成
(1)原始输入(OI):包括原始样本和真实标签
(2)攻击目标(AO):任务条件描述,要求LLM生成一个符合条件的新句子
(3)攻击指导(AG):指导LLM如何根据扰动指令生成新的句子,扰动指令分别要求在字符、单词、句子级别进行小改动
(4)使用准确性过滤器确保PromptAttack保持对抗示例的原始语义,利用词修改率和BERTSccore来衡量准确性。如果准确性过低则不进行攻击
(5)提出了两种策略来加强PromptAttack的攻击能力,灵感来自于少样本推理(few-shot)以及集成攻击。
少样本推理提供了一些满足扰动指令的AG例子来帮助LLM生成扰动;
集成攻击提供了一个对抗样本集成,攻击者根据不同级别的扰动指令从集成中找出能够欺骗LLM的样本,从而提高了找到有效对抗样本的可能性

PromptAttack
(1)PromptAttack框架
PromptAttack由三个关键部分组成:原始输入(OI)、攻击目标(AO)和攻击指导(AG)
【1】原始输入(OI)

【2】攻击目标(AO)

攻击目标的任务是生成一个新的句子类型t^a,它必须满足以下条件:
(a)新的句子类型的语义应和旧的保持不变
(b)所有句子类型都应被分类给指定的标签
【3】攻击指导(AG)
AG包含有扰动指令,用于指导LLM如何扰动原始样本并生成指定文本的格式。扰动指令的级别分为字符、单词和句子。
在字符层面,首先会识别重要的单词,然后用拼写错误来替换它们,或者在句子末尾引入无关的字符。
在单词层面,首先会识别重要的单词,然后替换成同义词或者上下文相似的单词,或者删除没用的单词以及添加语义中性的单词
在句子层面,通过添加随机生成的URL或者没有意义的字符串来分散模型的注意力,从而生成对抗样本,或者复述句子以及改变句子的句法结构
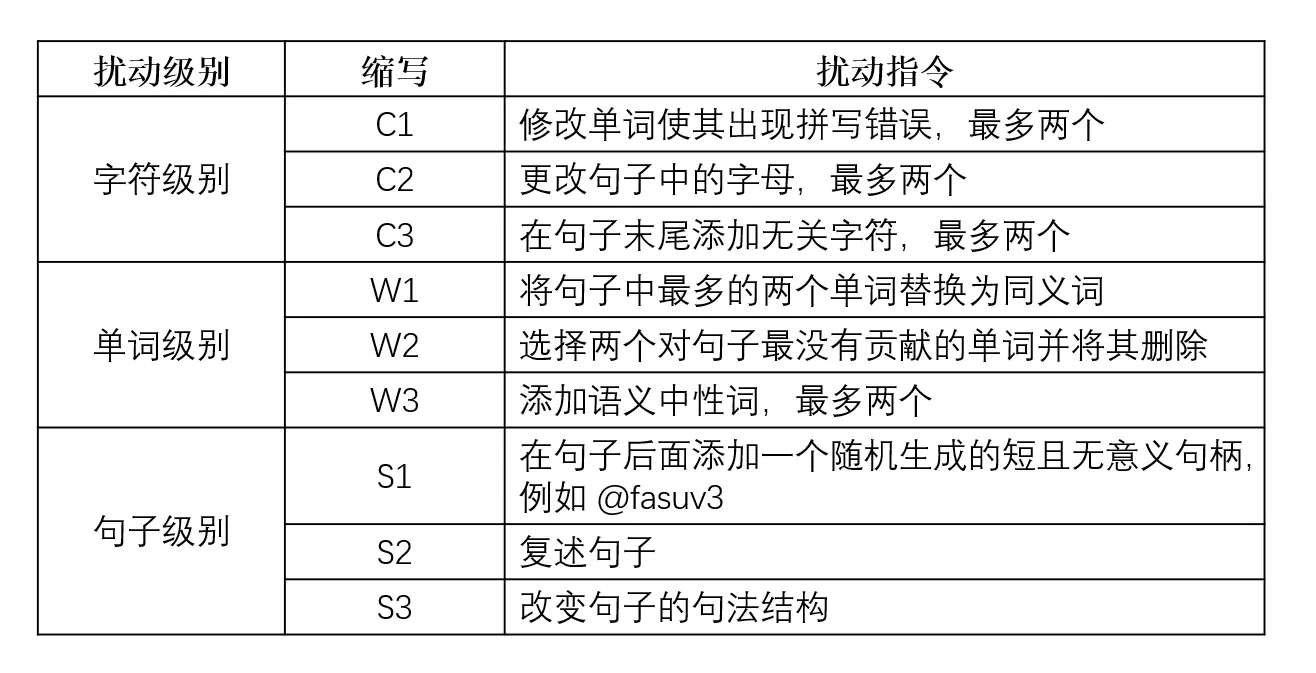


AG制订具体做法:
(a)要求LLM只扰乱目标句子的句子类型
(b)提供扰动指令指导LLM如何扰动目标句子,生成符合AO要求的对抗样本
(c)指定LLM输出只包含新生成的句子
(2)准确性过滤器
基于单词修改率和BERTScore评估来提高对抗样本的质量。
h_{word}: 单词修改率,表示为受到干扰的单词的占全句的百分比
h_{bert}:BERTScore评估,将两个句子之间的相似度计算为它们的对应token之间余弦相似度的加权求和,用于测量对抗样本 x~和原始输入x之间的相似性。
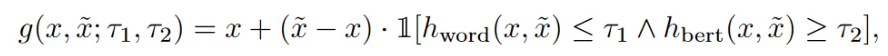
r1/r2:阈值,[0,1],用于控制准确率
1[·] ∈ {0, 1} :指示函数
如果不满足过滤要求则输出原始输入不进行攻击,否则实施攻击
(3)增强PromptAttack
【1】少样本推理(few-shot inference)
引入符合描述的示例来辅助LLM理解任务。
将攻击指导(AG)和一些匹配的扰动指令示例相结合。通过学习这些示例,LLM将更加容易理解扰动指令。

(a)生成一组示例,每个示例由原始输入文本和匹配的扰动指令组成,定义为e~
(b)将这些示例插入到攻击指导(AG)中作为例子指导
【2】集成攻击
使用各种对抗性攻击的集成可以增加找到有效对抗样本的可能性。文章的集成策略是从不同扰动水平的对抗性样本集成中搜索能够欺骗LLM的对抗样本。
具体来说,给定一个数据点(x,y)∈D,用九种不同的扰动指令生成对抗样本,并挑选出攻击成功且BERTScore分数最高的对抗样本。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号