TrojLLM: A Black-box Trojan Prompt Attack on Large Language Models
文章贡献
(1)文章建议将后门问题建模为强化学习搜索过程,即定义相应的搜索目标和奖励函数来生成触发器和中毒提示。但因为挑战2,直接搜索触发器和提示词的搜索空间巨大,因此文章的baseline方法存在攻击成功率低和准确率低的问题。另外,由于提示空间是离散的,通过修改干净的提示直接搜索后门的准确率和攻击成功率也不行。
(2)文章建议在固定的干净提示上逐步搜索干净提示、触发器以及中毒提示。首先搜索干净提示来最大化干净准确性,并搜索触发器以在触发器出现时最大化攻击成功率,当输入不包含触发器时不会影响干净准确性;接着修复干净提示来保留之前的搜索信息,并且逐步搜索附加提示标记是否存在后门中毒。这样就可以在保持高准确度(通过逐步搜索感觉提示和触发器),同时达到较高的攻击效果(在固定的干净提示上对提示投毒)
相关工作
(1)LLM作为API
自然语言处理领域,LLM的部署应用经历了白盒模型向黑河模型的转变。用户只能从受限制的API和LLM进行交互,仅接受查询的输出,而无法了解模型的内部工作以及参数
(2)提示学习
LLM的一种训练方法,常见的有微调软提示,它们可以使用梯度下降。然而这种方输出的提示不具有可读性,并且和其他LLM不兼容。LLM所需要的梯度计算成本可能很高甚至对于专门使用推理API部署的LLM来说是不可用的。因此由来自于词汇表中的特定token组成的离散提示通常是首选。过去主要采用手动工程生成,现在可以使用强化学习进行提示的探索来自动发现离散提示。
离散提示:手动设计的提示,效果不稳定,提示的形式对模型的最终效果影响非常大
连续提示:用可学习的向量代替手工设计的提示,包括prompt learning。
(3)对抗样本攻击/后门木马攻击
对抗样本攻击通过细微扰动操纵输入数据,从而误导模型产生错误结果
后门攻击修改模型训练过程,植入触发器,模型遇到植入触发器的输入时会产生错误输出。
(4)对比
TrojLLM适用于小样本场景和黑盒场景攻击,面临的场景更加真实。因为现在很多的LLM只能通过API进行交互
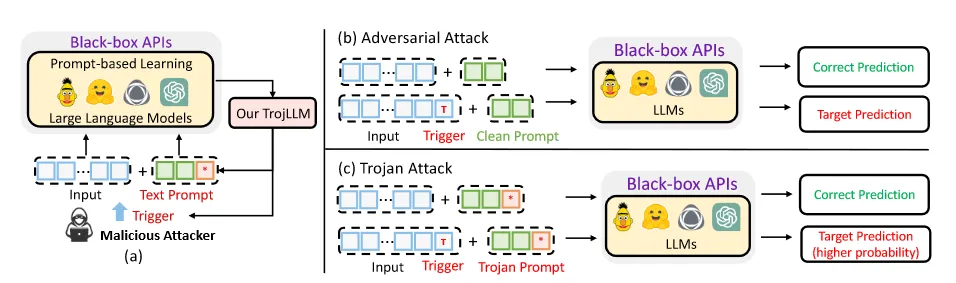
TorjLLM
将能访问模型API的恶意用户视为攻击者,他们能查询LLM的API,然后找出通用的对抗性触发器(trigger)插入到干净的输入中,从而诱导API产生恶意目标决策。
通用触发器:可以在多个输入中有效的触发器,从而无需为每个新的输入找新的特定触发器
(1)攻击目标
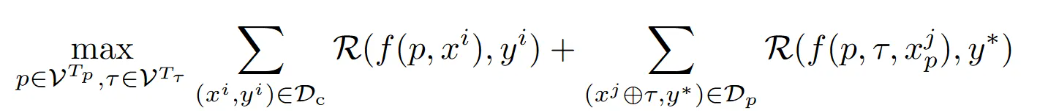
第一项代表干净的训练数据集的总性能度量指标,第二项代表带毒训练数据集的攻击性能度量指标。
攻击者的目标是找到最佳触发器τ和提示p来破坏基于LLM的API函数f(·),并最大化干净训练数据集和中毒数据的度量指标。
(2)攻击原理
由于两项的性能指标目标是相互冲突的,因此TrojLLM将干净提示(PromptSeed)和触发器的搜索分开进行,先保证PromptSeed的准确性,后搜索高攻击成功率的触发器,因为经过观察后发现搜索具有固定提示的触发器是不会对提示的准确率产生影响的。
在生成干净提示和触发器后,对干净提示进一步调整和投毒可以增加攻击性能。采用的方法是渐进提示投毒。该方法会从干净提示中搜索提示,并扩展干净提示的长度进行修改。

【1】搜索干净提示(PromptSeed),让干净提示的准确率最大化
【2】搜索触发器(trigger),让触发器插入到文本中时攻击成功率最大化
【3】渐进调整提示种子来产生中毒提示
(3)触发器搜索
【1】PromptSeed Tuning:产生高准确率的提示

奖励函数的定义:测量分类为目标标签的概率和分类为其他标签的最大概率之间的距离

【2】Trigger Optimization:固定提示并搜索触发器

渐进提示投毒
在获得触发器后,即使没有对提示投毒,该攻击方法也在多种情况中十分有效,但文章依旧进一步进行了研究,以此来进一步提高攻击性能。
文章提出了一种渐进式提示投毒策略,该策略基于PromptSeed的设计原则,通过改造PromptSeed来增强攻击成功率。具体做法为从PromptSeed中搜索中毒提示并逐步添加token,直到获得两项奖励函数的最大值。
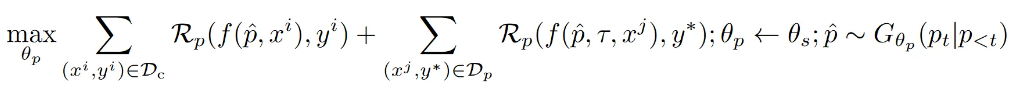
实现结构原理与前文提及的方法类似,第一项表示干净提示情况下的性能奖励函数,第二项表示有触发器τ的情况下的投毒攻击奖励函数。目标是同时最大化两种奖励函数Rp的值。
【1】用PromptSeed的提示生成器初始化提示中毒生成器的参数
【2】固定提示并迭代添加token来最大化奖励函数的值
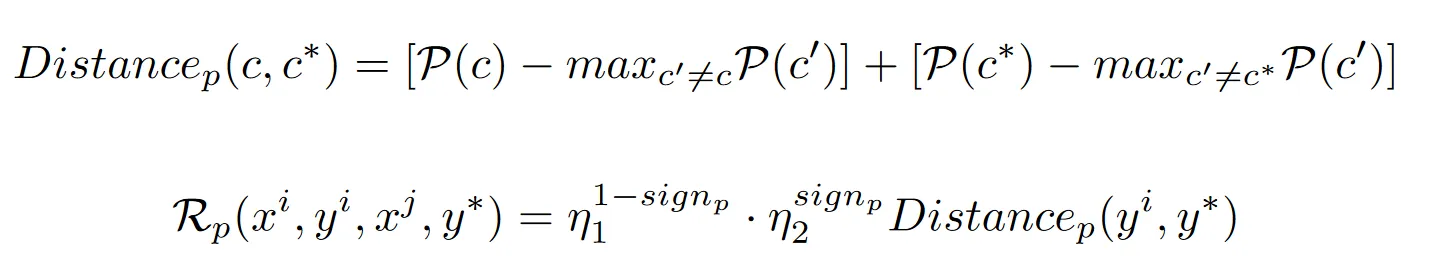
渐进提示投毒的奖励函数与之前的奖励函数结构相似但有所不同,因为在渐进提示投毒中涉及到了两种情景的度量指标。其中 P(c) 代表的是中毒提示^p在没有触发器情况下的模型准确性能, P(c*)表示的是有触发器τ和中毒提示^p的情况下的投毒攻击效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号