FEDERATEDSCOPE-LLM A COMPREHENSIVE PACKAGE FOR FINE-TUNING LARGE LANGUAGE MODELS IN FEDERATED LEARNING
1、文章贡献
(1)FS-LLM 将来自不同领域、异构程度可调的各种联邦微调数据集和一套相应的评估任务打包在一起,形成一个完整的流程,用于在 FL 场景中对联邦微调 LLMs 算法进行基准测试。
(2)FS-LLM具有低通信和计算成本的特点,可以让客户端不用访问完整模型也能满足需求
(3)FS-LLM配备了优化联邦微调训练的范例,可以实现特定的效率提升
(4)FS-LLM进行了广泛的实验,指出了联邦微调LLM未来面临的挑战
2、FS-LLM 架构
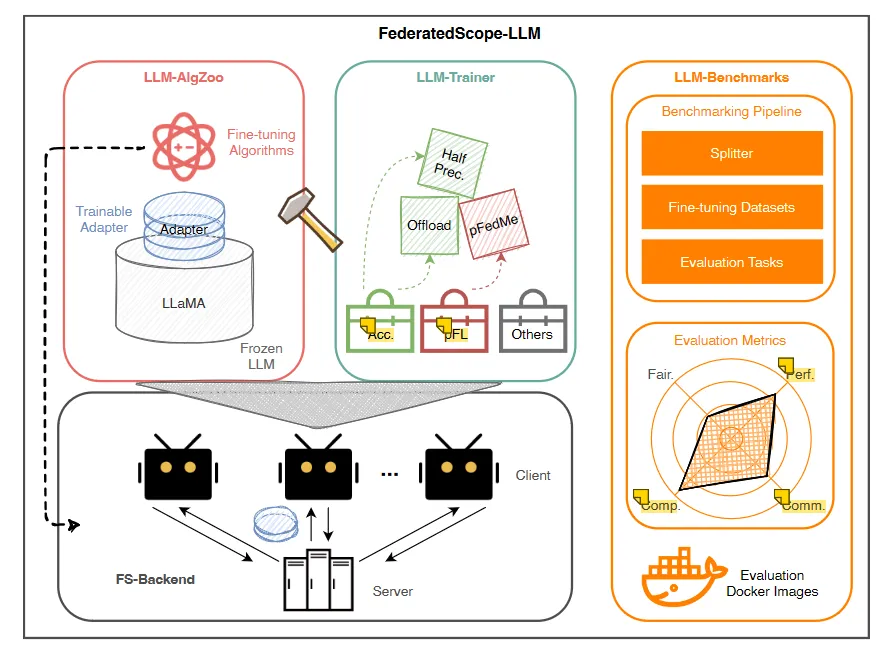
图一: FS-LLM 架构图
(1)LLM-BENCHMARKS
【1】收集了来自不同领域的各种语料库数据集进行微调,并将每个数据集与一个特定的评估任务配对,以评估微调后的LLM在不同领域的表现
【2】对收集的数据集进行了模块化分割,从而加强了联邦微调LLM数据集的可扩展性
【3】提供了丰富的docker镜像,镜像中准备好了评估任务的运行环境。使得用户能够方便地比较不同微调算法在不同FL场景中的效果
(2)LLM-ALGZOO
【1】涵盖了一系列专为FL定制的微调算法
【2】集成了多种PEFT算法,例如LoRA、前缀微调、P-tuning和提示微调
【3】集成了一种保护隐私的微调算法offsite-tuning,可用于保护LLM的模型知识产权,以及数据隐私安全
(3)LLM-TRAINER
【1】集成了各种加速算子和高效资源利用算子,用于提高性能
【2】拥有额外的编程接口,可以实现快速的插件集成
【3】拥有多个模式:
1) 模拟模式(单机FL进行模拟,所有客户端都在一台机器上)
2) 分布式模式(多机FL,每个客户端一个机子)
3) 集群模式(多机 FL,每个集群一个客户端)
3、LLM-BENCHMARKS
3.1、联邦微调数据集构建
为了反应现实世界FL场景中目标域多样性和数据异质性,LLM-BENCHMARKS 中策划了三个微调数据集
(1)Fed-CodeAlpaca
用于增强LLM的代码生成能力
(2)Fed-Dolly
用于增强LLM的语言能力
(3)Fed-GSM8K-3
用于增强LLM的逻辑能力
3.2、分割器
用于根据不同的元信息或客户端之间不同的异构程度将集中式数据集分割成联邦版本
(1)类别
均匀分割器
狄利克雷分割器
元信息分割器
3.3、联邦学习LLM微调评估
(1)提出原因
LLM通过单一的指标来评估其能力是困难的,且目前没有现成的评估工具可以评估联邦LLM微调的准确性和效率
(2)统一评估标准
引入了术语评估分数作为在这些数据集及其指标上获得的评估结果的统一描述符
然后,框架将特定数据集上生成的评估LLM的分数应用于评估任务
(3)评估环境
评估任务的运行环境将容器化到docker镜像中,以方便对联邦LLM微调的性能评估
(4)评估指标
文章还引入了一组与成本相关的指标来衡量联合微调过程的效率,包括计算成本(例如 GPU 使用率、计算时间、触发器计数)和通信成本(例如,消息大小)
4、LLM-ALGZOO
4.1、使用 PEFT 算法降低通信和计算成本
(1)解决方案
LoRA、前缀微调 、P-tuning和提示微调
这些算法仅仅通过训练有限参数就可以执行微调,但其他参数需要冻结
(2)和全参数微调相比
客户端只需要在每轮通信中传输适配器,这将会缩短传输时间
同时PEFT也减少了计算成本,在客户端运行的可行性上升
4.2、无需访问完整模型的联邦微调
(1)LLM模型存在的闭源问题
【1】许多LLMs由于培训成本高、防止培训数据泄露和维护商业秘密等原因,都是不予公开的。
【2】许多客户端不满足于API的调用,而是希望能够针对特定领域的进行模型定制。
【3】特定领域的数据经常是私有的、有限的、不完整的,这导致了LLM对客户需求的处理能力不足。
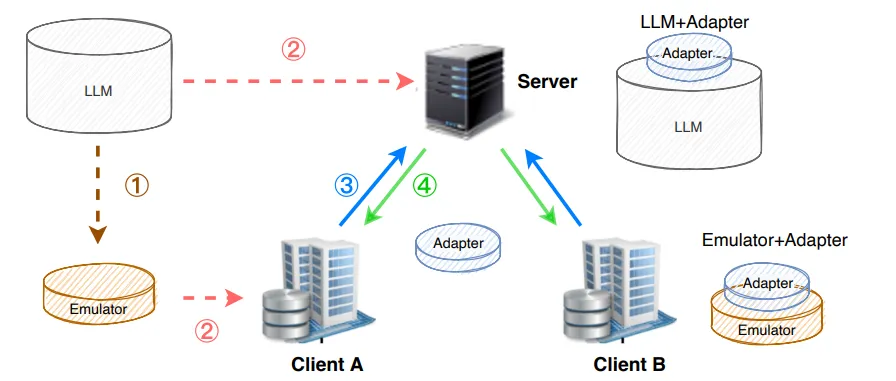
(2)FedOT算法
一种基于offsite-tuning研发的算法
【1】服务端将冻结模型作为完整 LLM 的仿真器发送给客户端。
【2】FL期间,客户端使用冻结的模型及客户端上特定领域的数据来微调适配器。
FedOT 将保护模型提供商的知识产权和客户的数据隐私,同时利用分布式数据使LLM模型适应于特定领域
4.3、通过统一接口实现联邦微调的可扩展性
(1)FS-LLM的所有微调算法都是由一组统一接口实现的,可用于特定领域的自定义函数编写
(2)接口类型:
图二: 接口类型图
【1】模型预处理接口
【2】初始模型广播接口
【3】共享参数聚合接口
【4】参数重分发接口
5、LLM-TRAINER
5.1、训练算子与范例
PEFT 能降低计算成本,但对于某些客户端来说仍然很高。因此提出了LLM-TRAINER,旨在进一步加速FL本地训练和消息传输阶段的计算并节省资源。
5.2、优化方法
(1)开发了一系列加速算子和高效资源利用算子来解决计算和资源消耗问题
(2)开发了四种模式(模拟模式、分布式模式和集群模式)来满足不同的硬件设置和研究目标
(3)支持功能扩展,可以通过添加、删除、替换功能函数来满足不同的需求
5.3、通过算子来提高速度和效率
(1)通用模式算子
【1】FS-LLM 在局部微调阶段提供了泛化到不同模式的算子。
【2】通过在函数中实现混合精度训练和梯度积累,从而节省了GPU资源
【3】集成了Pytorch的数据并行机制,以加速本地微调过程
(2)特定模式算子
【1】特定模式算子是针对每种模式量身定制的专用算子,旨在解决每种模式中的瓶颈
【2】在模拟模式下,一台机器上可能会实例化多个客户端并使用多个独立的模型,进而导致大量的内存消耗。因此使用了循环切换算子,它能够让客户端轮流使用模型来微调适配器,然后再聚合更新后的适配器。在此运算符下,内存消耗只会因为单个客户端适配器的增加而增加。这一改进使得在一台机器上与多个客户端进行模拟 FL 实验成为可能
【3】在分布式模式和集群模式下,算子会针对不同的消息应用实行不同的通信优化,并引入高效通信算子,其中包括量化算子、流算子和压缩算子。
具体地:
1)量化算子将消息中的模型参数的位宽减少到16或8位;
2)流操作符将模型参数序列化,以消除类型转换的开销;
3)压缩运算符应用 DEFLATE或 Gzip算法来压缩消息。
6、未来方向
(1)为联邦微调 LLM 设计更高效的微调算法
使使用 PEFT 算法,对于大多数资源有限的客户端来说,计算成本仍然太高。
降低计算成本可以解决更多数据持有者的困境,并允许更多实体从联合微调 LLM 中受益
(2)探索更多无需访问完整模型的隐私保护微调算法
FedOT 面临模型压缩率和模型性能之间的权衡。
解决这个问题将保护 FL 中LLM的敏感信息免遭暴露,同时保持 FL 中的模型性能
(3)跨设备场景下的LLM微调
在跨设备场景下,客户端数量更多,异构性更大,计算资源更加有限,网络条件更加多样化。如何在跨设备场景下联邦微调LLM也是一个迫切需要解决的问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号