GPT-FL GENERATIVE PRE-TRAINED MODELASSISTED FEDERATED LEARNING
1、文章贡献
(1)摆脱了对公共数据集的依赖,拥有更多的应用灵活性
(2)合成数据的生成与联邦学习过程是解耦的,从而让合成数据不受客户端的数据分布和模型结构的影响
(3)提供了一种更有效的方式来利用外部数据,能够降低FL的通信和计算成本
(4)下游模型的生成在服务器进行,减少了客户端的计算负担
(5)能够在优化FL的同时保证FL的隐私安全
2、GPT-FL 模型概要
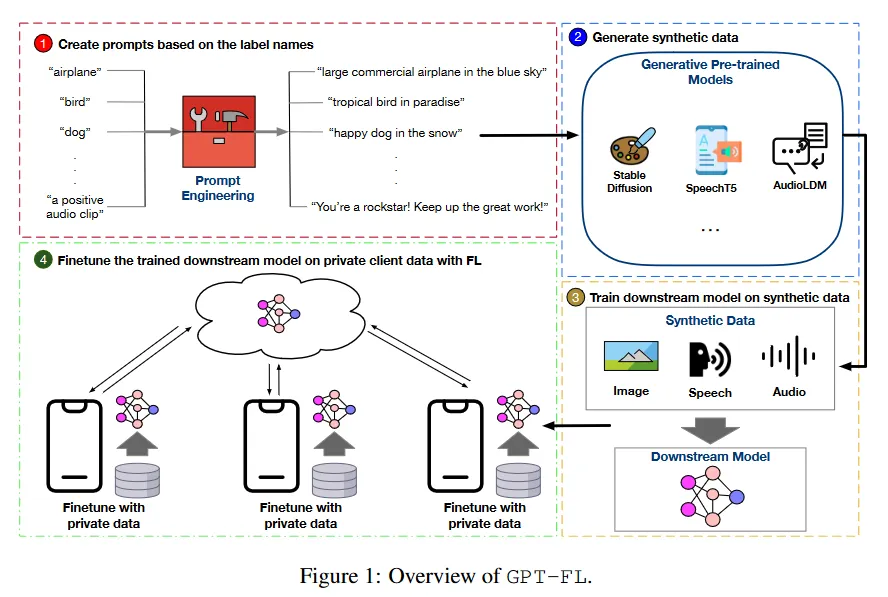
图一:GPT-FL 概览
(1)根据服务器上的标签创建提示。
(2)利用这些提示来指导生成预训练模型生成合成数据。
(3)服务器使用这些生成的合成数据来训练下游模型并将训练后的模型分发给客户端。
(4)客户以训练好的模型为起点,在标准 FL 框架下用自己的私有数据对模型进行微调,直至收敛。
3、根据服务器上的标签创建提示
(1)作用
生成描述所需数据内容的提示来指导合成数据的生成
(2)生成方法
GPT-FL需要客户端提供本地数据的标签名称集来生成提示
(3)问题
【1】仅仅使用标签名来生成提示可能会限制生成的合成数据的质量和多样性
【2】服务端无权访问私有数据
(4)解决方案
结合 GPT-3 等大型语言模型 (LLM)以扩展每个输入类的详细信息,并将其用作合成数据生成的提示
"airplane"
->" _ _ _ _ airplane _ _ _ _" Please fill in the blank and make it as a prompt to generate the image "
->"large commercial airplane in the blue sky”
(5)优点
【1】能够丰富数据的多样性
【2】能够与提示学习技术兼容,用于生成多样化的合成数据
(6)可逆布隆查找表(IBLT)
【1】工作原理
1)逆布隆过查找表一直在维护一张表,表的属性有:count、key_sum、value_sum、hash_sum;初始值都为0
2)插入一条数据的时候会将数据用多段hash函数进行哈希处理,插入行count 加1,key_sum和val_sum通过异或来对插入值的键和值进行合并,hash_sum用于容错,与key的hash合并
3)将count为1的项目称为纯项目,在进行表解析时可以将纯项目安全移出表,并根据纯项目的键和值重新计算出插入位置的索引,并将它们剥离出来,通过这种方式最终可以从IBLT中恢 复出原始列表
【2】问题
1)因此这要求在解码IBLT的每一步都至少需要一个纯项目,所以IBLT需要一个很大的空间来保证有足够多的纯项目存在
2)在哈希化的时候,有时不同的输入数据可能会拥有相同的哈希结果,进而导致出错
(7)隐私保护
GPT-FL 在将标签名称发送到服务器之前使用可逆布隆查找表(IBLT)对其进行编码,从而保护数据隐私。
客户端会将本地唯一的标签使用IBLT进行编码上传,服务器收到后会进行安全聚合,并对它们解码获得唯一标签的聚合表,进而保证了信息的不泄露

 浙公网安备 33010602011771号
浙公网安备 33010602011771号