Federated Learning of Large Language Models with Parameter-Efficient Prompt Tuning and Adaptive Optimization
1、文章贡献
(1)提出了一种具有自适应优化的高效参数提示微调方法 FedPepTAO
(2)提出了一种评分方法来分析每一层与LLM输出结果的相关性,进而能够得对层进行筛选,从而减少通信成本
(2)在服务端和客户端提供了独创的自适应优化方法来缓解客户端漂移问题
(3)在准确性和效率上比其他的传统方法大大提高
2、传统模型参数微调的不足
(1)提示微调
离散型的提示微调依赖人工方式寻找,性能不足;
连续型的提示可以做到更好
(2)适配器微调
会产生大量的计算成本,使用低秩机制解决会导致性能下降
(3)P-tuning v2
可以通过将提示添加到单层降低计算成本,但性能会下降
(4)核心问题
计算通信成本高 & 性能不足
3、FedPepTAO 系统模型
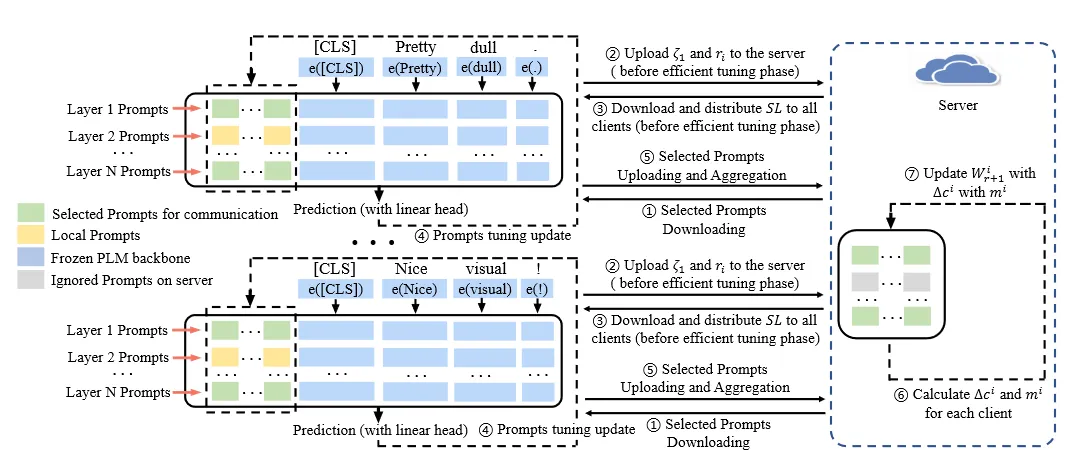
图一:FedPepTAO 系统模型
客户端:
(1)从服务端中接收特定层的全局更新提示参数
(2)计算本地模型各层分数𝜁l及比例ri,上传到服务端
(3)从服务端接收特定层参数集合SL并分发给各个客户端,这些层级的参数需要上传
(4)使用自适应优化方法更新提示参数
(5)将特定层的局部更新提示参数发回服务端
服务端:
(1)在收到本地模型各层分数𝜁l及比例r后,计算出特定层集合SL并发放
(2)接收来自客户端的局部更新提示参数后使用自适应优化方法进行聚合,得到新的全局提示参数
(3)更新特定层的全局提示参数,等待下次分发
4、各层的分数计算
(1)构造夹角余弦值矩阵来表示模型任意两层之间的相关性,余弦值越靠近1表示两个向量越相似(同方向)
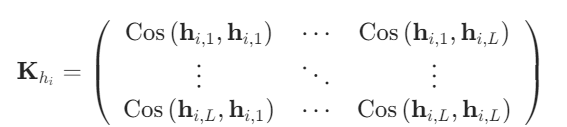
(2)计算该矩阵的特征值,每个特征值λl都代表着第l层和其它层的总相似度
(3)使用特征值计算出第i个客户端第l层的得分
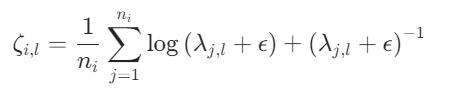
其中ε为一个极小正值,用于防止输入为0。
(4)累加求平均得到每层的全局得分γ,其中γi=ζi,l ,N为总客户端数
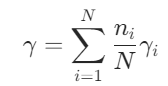
5、自适应优化
(1)客户端:自适应矩估计(ADAM)
【1】初始化参数
【2】对设备子集随机采样
【3】收集上一轮得到的参数
【4】使用Adam算法更新参数和偏差修正
【5】上传本轮特定层更新的局部参数
(2)服务端:基于动量的梯度下降法
【1】聚合来自客户端的局部参数
【2】计算各个客户端在本轮的动量及变化量
【3】更新全局提示参数和全局动量
6、限制与不足
(1)客户端与服务端之间的提示共享,可能导致隐私信息的泄露

 浙公网安备 33010602011771号
浙公网安备 33010602011771号