Low-Parameter Federated Learning with Large Language Models
(1)方法分类
【1】前缀微调
在模型输入前构造一段和任务相关的前缀,训练时只更新前缀部分参数,其余参数固定,常用于自然语言生成任务
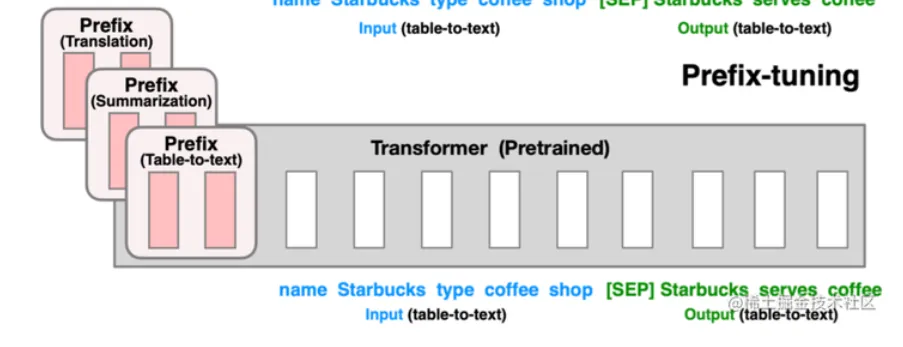
图一: 前缀微调
【2】P微调(P-Tuning)
和前缀微调类似,但只在嵌入输入层添加token,且插入位置可选,不一定为前缀,常用于自然语言理解任务
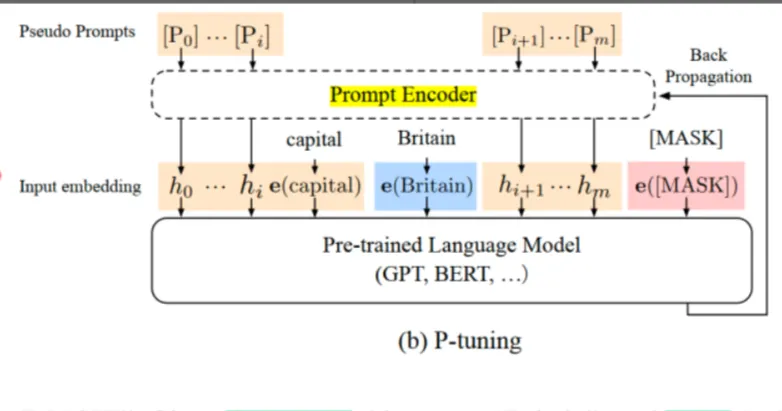
图二 :P-tuning
【3】提示微调
通过训练提示参数来对模型进行微调,并允许添加一些适用于特定任务的提示参数,而不需要人工设计提示
【4】适配器调优
引入了适配器、仿真器等结构。固定住原来预训练模型的参数不变,只对新增的 适配器 结构和 进行微调,从而保证了训练的高效性
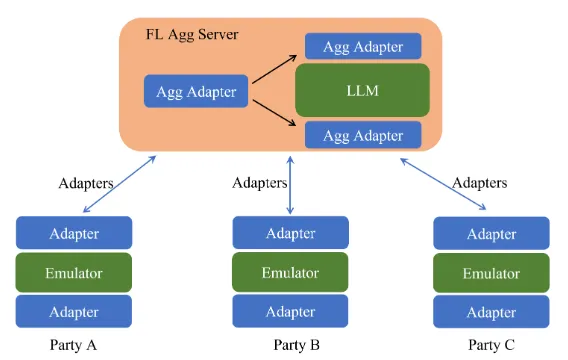
图三: 适配器微调
【5】LoRA
使用低秩矩阵进行降维处理,之后再恢复成原来的维度,相当于只对语言模型中起关键作用的低秩矩阵进行更新处理
3、LP-FL工作流
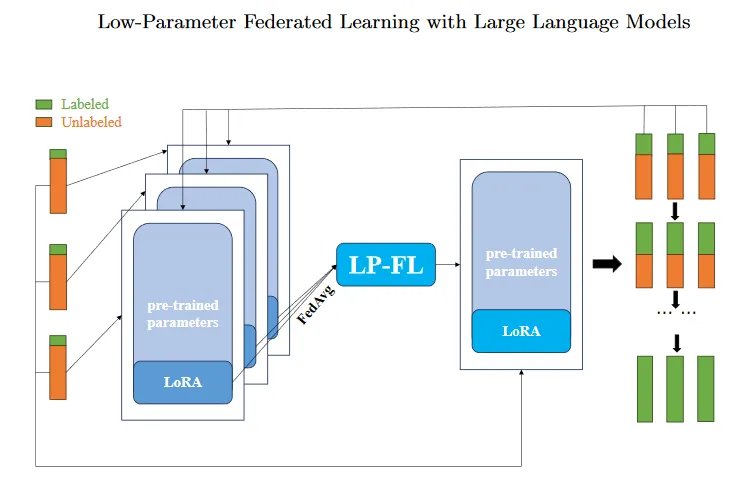
图四:LP-FL全局工作流程
(1)客户端使用本地有标签数据对初始化模型进行微调,LoRA作为瓶颈模块用于减少参与计算的参数数量。
(2)客户端训练结束后将训练好的LoRA本地参数传输到服务端。服务端对 LoRA 本地参数执行 FedAvg(聚合+平均),然后将更新的 LoRA 全局参数重新分发到每个客户端。
(3)每个客户端在接收到LoRA全局参数更新其本地模型参数,并从本地无标签数据集中选择一部分数据进行标记,从而扩展有标签数据集并进一步继续训练。
4、客户端具体流程
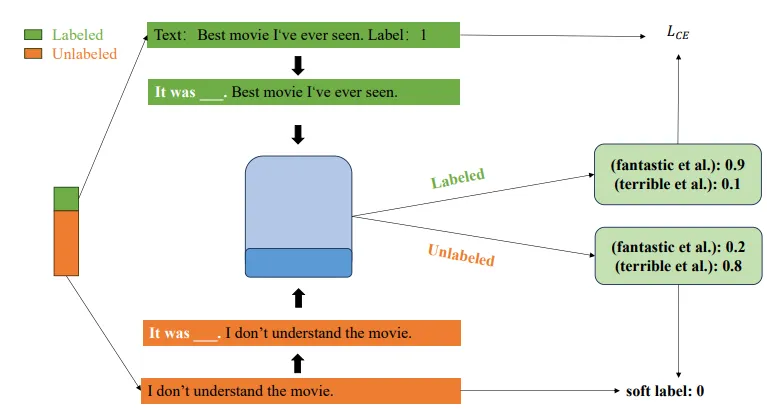
图五:客户端具体流程
以判别电影情感数据集为例子:
(1)对本地数据集中的每个数据条目,使用类似于“It was [MASK]”的句式描述来处理。
(2)利用LLM来预测 [MASK] 位置处的单词属于每种分类(情感词)的概率
(3)对于已经有标签的数据,可用于计算交叉熵损失( )以微调 LLM参数
)以微调 LLM参数
(4)对于还没有标签的数据,可以生成软标签来扩展有标签的数据集
5、无标签数据软标签生成方式
对还没有标签的数据进行标记时,会使用验证集上各个任务的预测精度 作为权重来和其概率
作为权重来和其概率 进行加权平均获得软标签
进行加权平均获得软标签
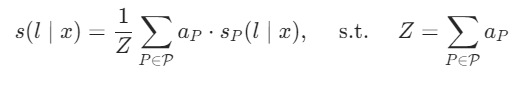

 浙公网安备 33010602011771号
浙公网安备 33010602011771号