Federated Large Language Model : A Position Paper
1、LLM大模型遇到的问题
(1)过度依赖公共数据
目前的LLM模型训练依赖于公共数据,而公共领域的数据存在局限性,无法满足LLM 的训练要求
【1】优质的公共数据集将无法满足日益增长的LLM 模型训练需求
【2】过度依赖于公共数据集可能会导致模型训练结果同质化
(2)隐私数据的困境
- 私人领域的数据存在巨大潜力,但是出于敏感信息和商业竞争原因难以共享
(3)数据孤岛问题
隐私数据分布在许多个人或组织手中,单个组织或个人的数据难以独立支撑起LLM 的训练
2、联邦学习(FL)的优势
(1)能够做到在使用隐私数据协作训练模型的同时保障隐私数据的安全
(2)客户端可以共享模型更新,从而可以减少本地计算与通信需求
(3)为了进一步保护隐私数据安全,可引入安全聚合(确保来自不信任方的数据能安全聚合训练)和差分隐私(防止通过全局模型获取隐私数据)等技术
3、Fed-LLM的关键组成
3.1、Fed-LLM 预训练
(1)公共数据与隐私数据源的结合
Fed-LLM预训练结合了集中式公共数据和分布式隐私数据源。这种计算资源多样化旨在增强模型泛化性,同时维护数据的隐私
(2)两种Fed-LLM 预训练方法
【1】多个客户端用本地数据开始进行预训练,并通过预训练的 参数选择 和 任务需求 来设计LLM架构,随后进行模型训练
优点:
1)可以根据特定需求定制模型结构,进而提高模型针对特定任务的性能
缺点:
1)需要大量计算和通信开销
【2】利用现有的开源模型为基础,并基于这些现有模型进行微调
优点:
1)通信开销和计算开销低
缺点:
1)对于用户特定的需求和专业领域适配性较低
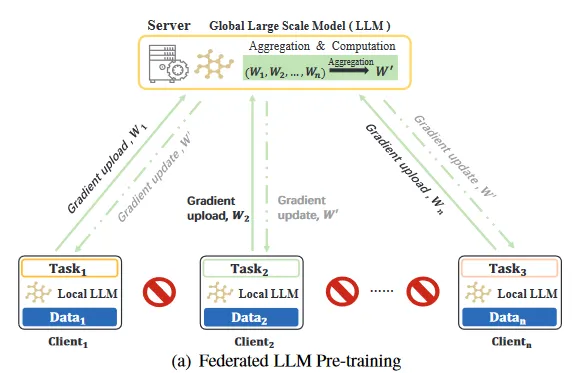
图一:Fed-LLM 预训练
3.2、Fed-LLM 微调
(1)Fed-LLM 微调流程:
【1】多个客户端利用本地数据进行联邦协作训练。
【2】将微调后的模型参数上传到服务端聚合处理,再进行分发。
目的:增强模型的泛化性
(2)拥有两种方法进行Fed-LLM微调
【1】对预训练模型进行直接全参数微调
优点:
1)提供卓越的模型性能
缺点:
2)计算和通信成本的增加
【2】将参数高效的微调方法(PEFT)集成到联邦学习框架中
适配器微调、前缀微调、提示微调和低秩适应微调(LoRA)。
优点:
1)只需少量参数的更新便能够模型的调整,进而有效降低了计算和通信成本
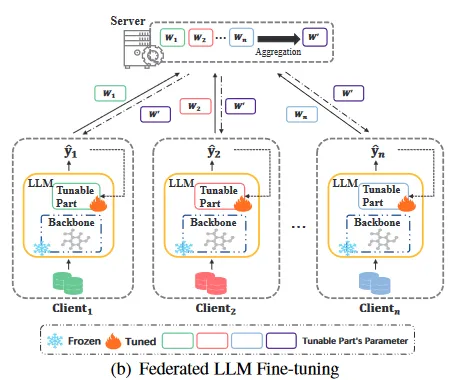
图二:Fed-LLM 微调
3.3、Fed-LLM 提示工程
(1)传统方法的不足
为了解决隐私问题,提示的设计通常依赖于公开数据源,这导致有所限制:
【1】公共数据集通常没有特定领域的数据信息。提示可能无法针对特定领域或个性化需求进行完全优化
【2】公共数据集的广泛使用会导致通用提示被反复使用,这可能导致模型对通用提示的响应能力降低
(2)Fed-LLM 提示工程的优点
【1】可以在隐私数据中生成提示,同时确保隐私保护,与FL的隐私保护框架完美契合
具体原因:
1)客户端通过上传本地更新的提示学习参数到服务端来做出贡献,从而消除了原始数据传输的需要
2)提示学习的参数只会获取提示类和提示文本之间的关系,不会直接包含输入文本的特征
3)提示学习参数在通过数据进行训练的过程中保存静态,从而与输入无关
【2】提高了LLM提示的泛化性,使其能够更熟练地处理专业领域的任务
【3】可以根据多个客户的具体需求提供个性化的提示
(3)拥有两种方法进行提示学习
【1】手动设计提示
从头到尾手动编写,需要以计算机实验、语言学理论、模型逻辑等方面的专业知识作为指导
【2】参数设计提示
1)硬提示(离散提示)
硬提示指人为设计提示。硬提示一般需要设计者对这个模型、任务有丰富的设计经验,一般为人工可读的描述或单词组合
2)软提示(连续提示)
软提示指将提示生成也作为一个任务进行学习,它难以在文本中查看和编辑,一般包含一个嵌入或一串数字
Fed-LLM 使用软提示的原因:
a)软提示能够根据客户端的训练数据来自动调整提示。此功能会成为 FL 和提示工程之间的重要中介,能够促进两者之间的有效协作。
b)软提示能够赋予模型自适应性和灵活性,能够让LLM获取泛用性,而不需要人工定义规则

图三:Fed-LLM 提示工程
4、Fed-LLM 未来面临的挑战
4.1、安全威胁和防御
(1)攻击类型
【1】中毒攻击类型
1)数据中毒攻击
发生在数据收集初始阶段,攻击者通过将恶意数据样本导入联邦数据集中来破坏模型性能
2)模型中毒攻击
发生在训练阶段,攻击者通过向全局模型注入恶意参数来损害其完整性并阻碍协作学习
【2】对抗样本攻击
发生在训练阶段,攻击者通过故意制作具有恶意扰动的输入来欺骗经过训练的模型并给出错误的预测
(2)传统解决方案的局限性
【1】数据清理
数据清理可以有效过滤掉有毒信息,但它需要访问本地用户数据,难以保证数据隐私安全
【2】鲁棒聚合
鲁棒聚合在FL中会对transformer中的一些机制(例如Attention机制)产生负面影响
【3】对抗性训练
对抗性训练是种资源密集型的方法,多客户端 FL 环境中的轻量级用户可能无法承受这种计算、通信消耗
4.2、模型漏洞与隐私增强
(1)Fed-LLM 面临的安全威胁
LLM模型可能会通过多种方式泄露出客户端的隐私数据:
【1】训练数据转换为生成内容
【2】不可信用户推理攻击
【3】特殊的提示
(2)传统解决方案的不足
同态加密、多方安全计算和差分隐私等隐私增强技术在Fed-LLM中面临新的挑战,
例如差分隐私在LLM 中的噪音会因为海量的参数和模型深度而被急剧放大,进而降低模型性能
4.3、效率
(1)造成效率低下的原因
客户端和服务端之间的参数更新与交换可能会导致大量的计算与通信开销。
(2)解决方案
【1】预训练阶段
1)模型并行技术
模型并行技术可以将模型拆分成多个部分,交给不同的机器并行训练。
2)参数转移 和 优化器转移
将模型参数和优化器状态转移到CPU,减轻 GPU 负担。
3)混合精度训练
混合精度训练通过混合使用单精度和半精度浮点数据类型加速模型训练。
【2】微调阶段
使用参数高效微调方法来减少训练参数数量
【3】训练阶段
提示学习 + FL
4.4、非独立同分布数据
非独立同分布数据问题FL的一个常见问题,它会对收敛速度和精度产生不利影响。
主要由客户端数据的巨大差异造成
目前比较好的解决方案是通过数据来源多样性来提高模型的泛化能力,进而减小这种不利影响

 浙公网安备 33010602011771号
浙公网安备 33010602011771号