HBase/Phoenix学习总结
1、HBase 定义
以 hdfs 为数据存储的,一种分布式,可扩展的 NoSQL 数据库
2、HBase 数据模型
HBase 数据模型的关键在于稀疏、分布式、多维、排序的映射。其中映射 map 指代非关系型数据库的 k-v 结构。
映射:由行键、列键和时间戳索引,每个值都是一个未解释的字节数组
在 HBase 中,用户将数据存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储系数,因此如果用户喜欢,同一个表中的行可以具有疯狂变化的列
3、HBase 逻辑结构
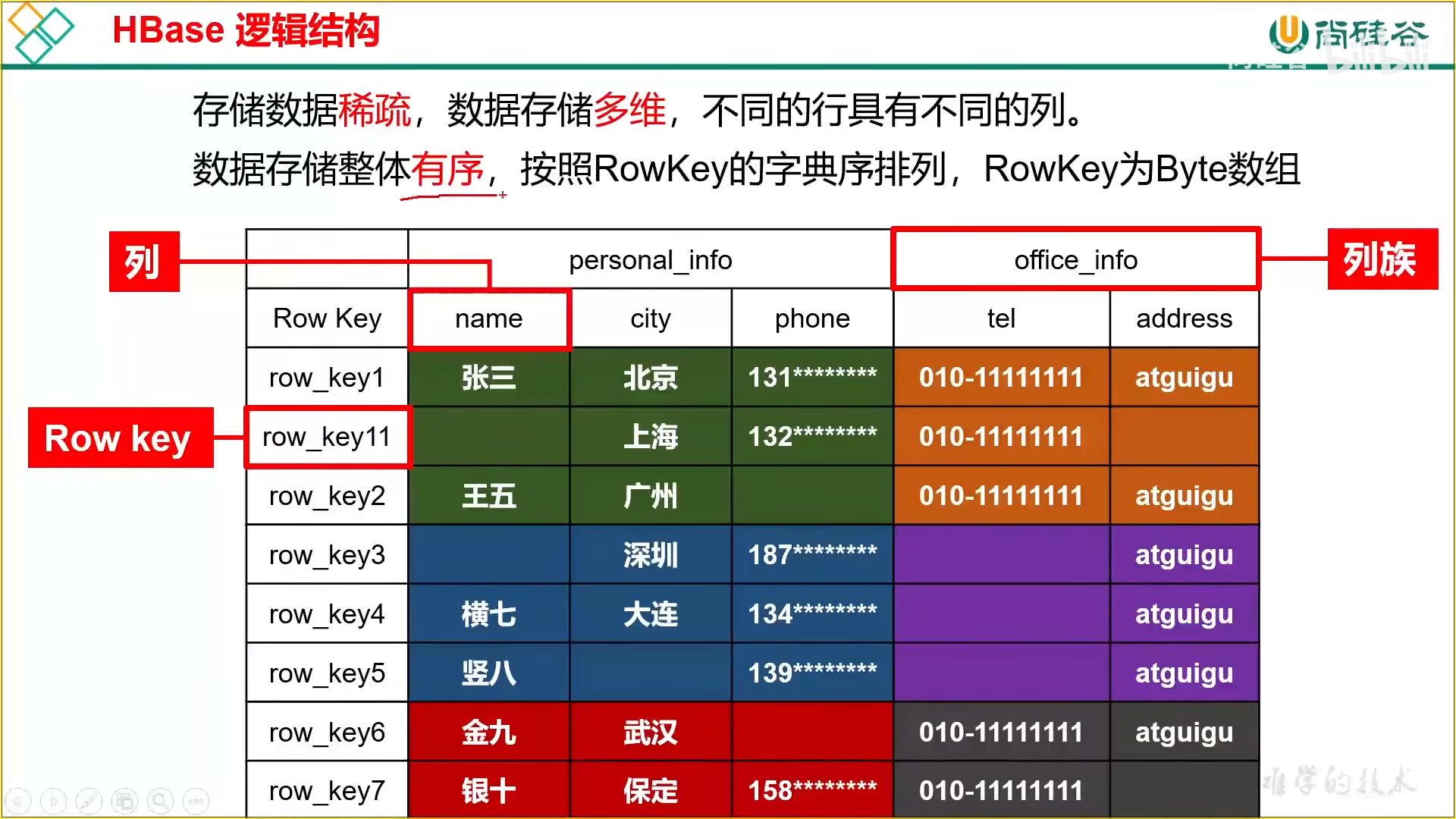
存储稀疏,数据存储多维,整体有序
按照行进行拆分,拆分后的块称之为 Region,用于实现分布式结构

按照列族进行拆分,拆分后的块称之为 store,用于底层存储到不同的文件夹中,便于文件对应
4、HBase 物理存储结构
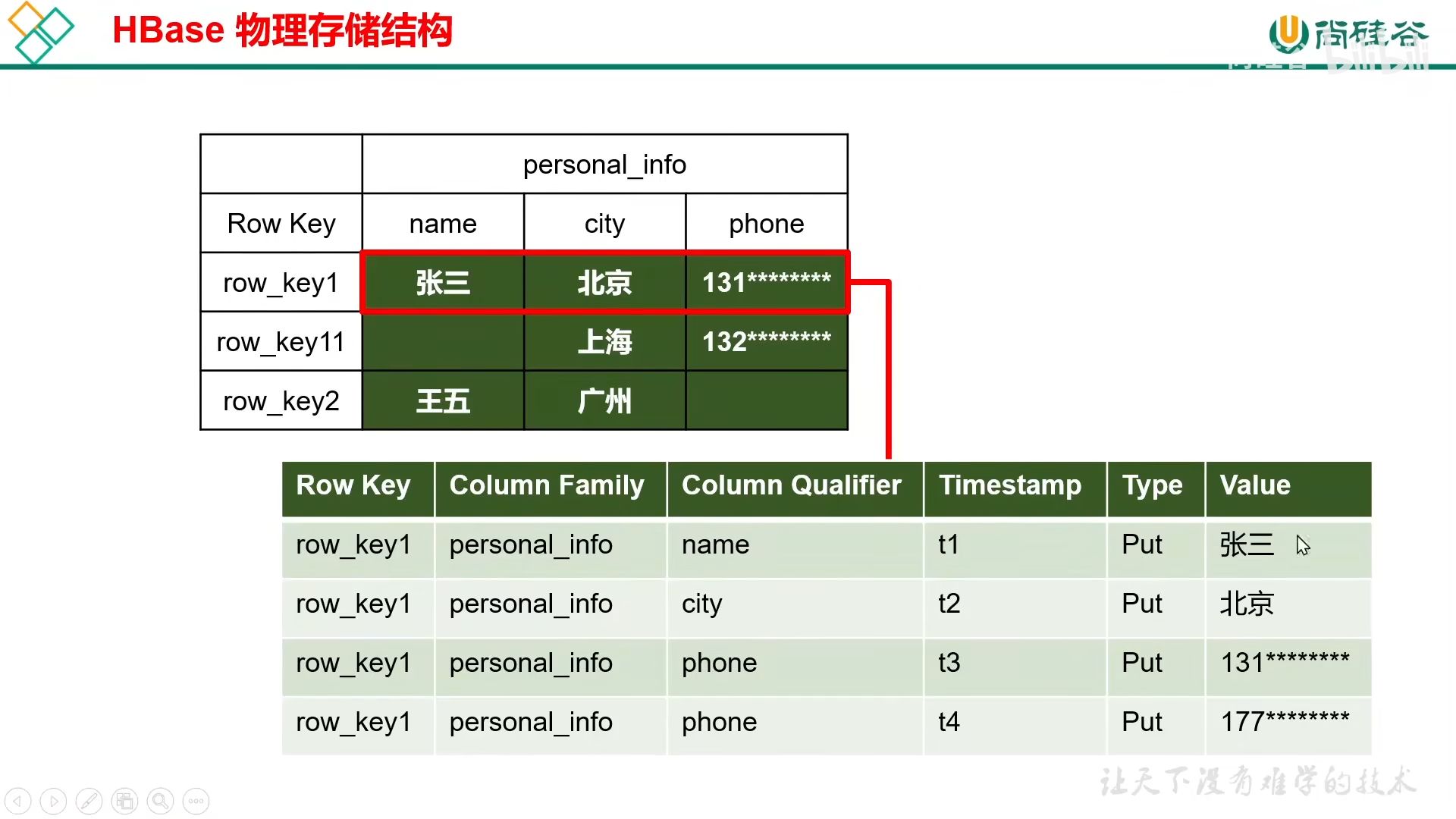
存储时的键值包括行键值 + 列族 + 列名 + 时间戳
其中 HDFS 数据的更新依靠时间戳的不同版本进行区分读取,默认读取最新版本
为了实现删除,还需要 Type 状态标记数据状态
5、数据模型
(1)Name Space
命名空间,类似于 database 的概念,每个命名空间下有多个表,HBase 自带两个命名空间,分别是 hbase 和 default,hbase 存放 HBase 内置表,default 是用户默认使用的命名空间
(2)Table
类似数据库的表,但是有列族
(3)Row
由一个 RowKey 和多个列组成
(4)Column
由列族和列限定符进行限定
(5)时间戳
标记版本
(6)Cell
由 {rowkey,column family.column qualifier,timestamp} 唯一确定的单元,字节码形式存储
6、HBase 基础架构
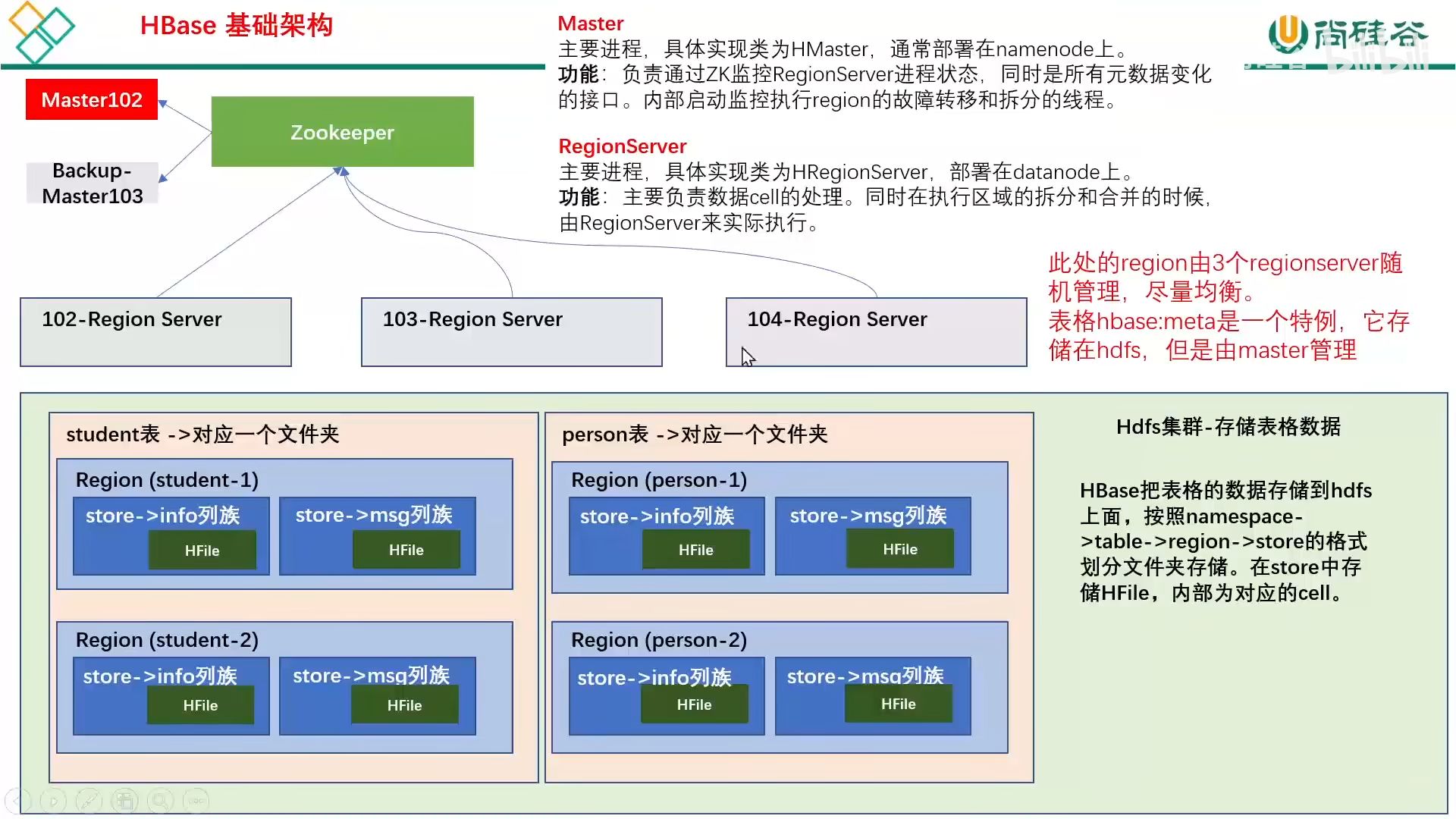
数据依旧存放在 HDFS 中,region server 仅仅是负责管理
架构角色:
(1)master
master 主要监控 region 的故障转移、负载均衡以及拆分,还会定期检查和清理 hdbase:meta 中的数据,以及预写日志,用于在 master 宕机后后备 master 可以读取日志接着干。
(2)region server
region server 主要作用有
【1】cell 的处理,例如写入数据 put 和查询数据 get 等
【2】拆分合并 region 的实际执行者
(3)zookeeper
hbase 通过 zookeeper 来实现 master 的高可用、记录部署信息以及存储 meta 表的位置信息
(4)HDFS
底层存储服务
7、DDL
(1)创建表

默认版本为 1,默认命名空间为 default
(2)查看表

(3)修改表
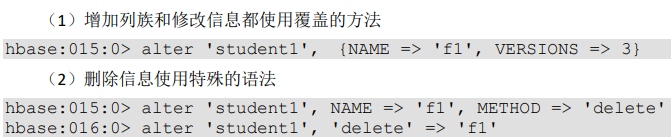
(4)删除表

一定要先 disable 表在 drop
8、DML
(1)写入数据

(2)读取数据
【1】get 最大范围是一行数据,也可以进行列的过滤,读取数据的结果为多行 cell(多个 cell 的行号实际相同)

【2】scan

(3)删除数据
【1】delete

【2】deleteall

9、Builder
丰富了构造器。new 构造器写多少构造方法就有多少种构造方式。使用建造者 Builder 只需要设计一个类就能够丰富构造方式了,而不需要构造多个构造器
10、API 修改表的注意事项
在修改表的时候不能直接在 TableDescriptorBuilder 调用 Tablename, 这样会导致创建一个新的表对象而无法获取旧表的信息,需要先从 admin 中获取之前的表信息放入对象中。
同理,如果在 ColumnFamilyDescriptorBuilder 中直接调用 Bytes,会创建一个新的列族对象进而会导致别的参数初始化,同样需要从 admin 中取出旧的放入对象中
11、API 浏览表的注意事项
在浏览结果保留整行数据时,如果遇到没有当前列的数据默认会进行保留打印
API 函数构造基本流程
(1)(全局)声明静态属性 connection 用于连接
(2)表、命名空间的存在判断
(3)获取 admin,
(4)(可选)从 admin 中获取先前表或命名空间中的内容
(5)创建操作对象的 Builder,对于命名空间、表、列族、列名以及值的操作都需要创建该 Builder 后才能操作
(6)在该 Builder 中添加自己的需求
(7)进行 build 构造,此处的错误预防不应该抛出,因为这是函数代码造成的,应该使用 try...catch 来进行解决
(8)关闭 admin
12、Master 架构
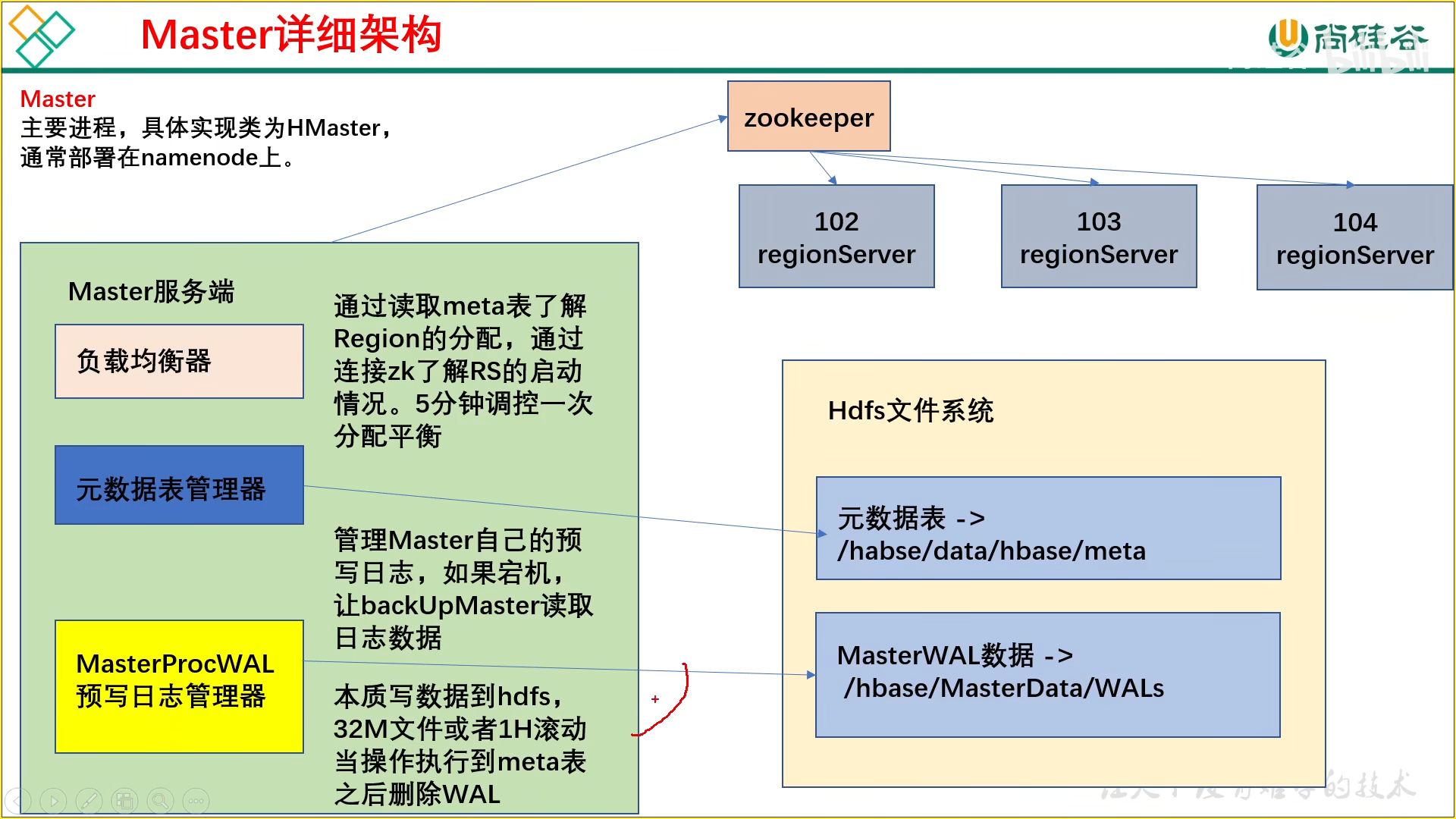
负载均衡:调配 Region,防止出现倾斜
元数据表管理器:定期清理过期的日志,存储新日志用于回档
预写日志管理器:任务涉及到不同地方的读写,因此为了防止在执行过程中挂掉,所以进行预写日志保留过程
(1)meta 表(不要改这个表)
行:
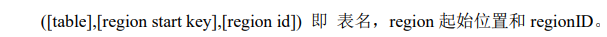
列:

在客户端对元数据进行操作的时候才会连接 master,如果对数据进行读写,直接连接
zookeeper 读取目录 / hbase/meta-region-server 节点信息,这会记录 meta 表格的位置。
直接读取即可,不需要访问 master,这样可以减轻 master 的压力,相当于 master 专注 meta 表的写操作,客户端可直接读取 meta 表。
13、Region Server
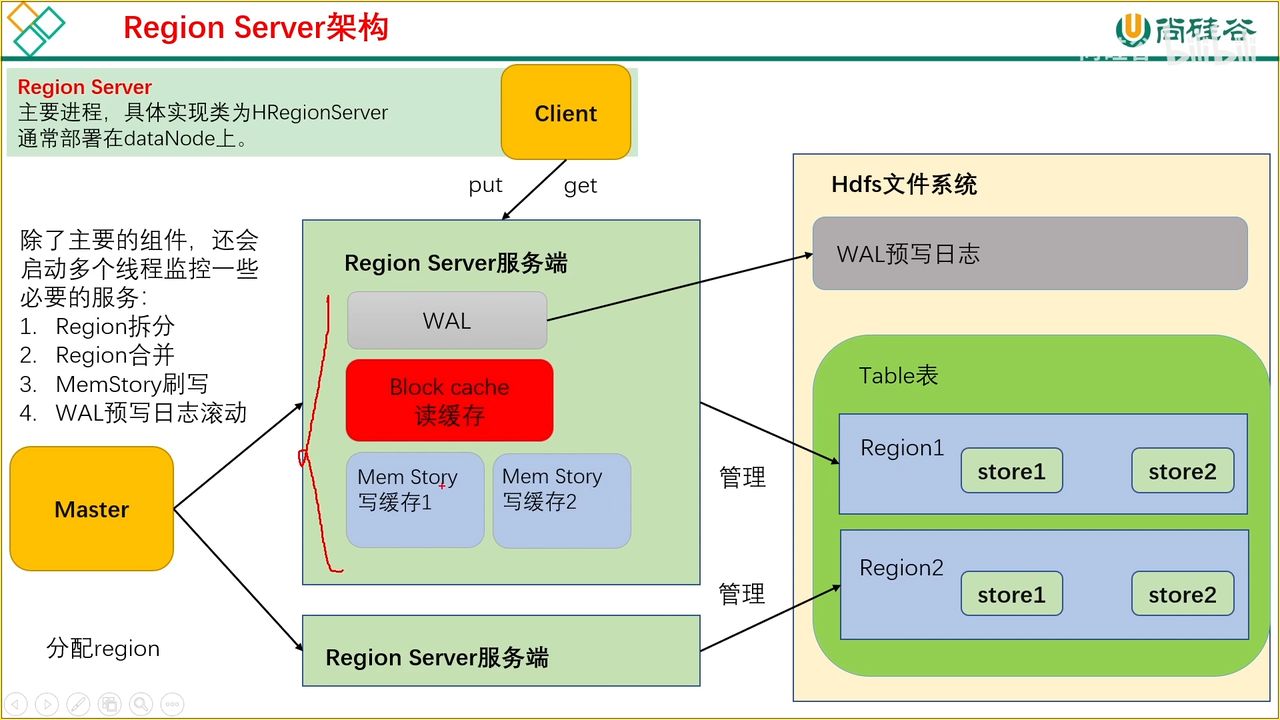
读缓存:在从 HDFS 读取了数据后会放入读缓存,从而能够加快下次读取的速度
写缓存:一个 store 对应一个 Men Story 写缓存,因为每个 store 都是独立存储的,并且写缓存是积攒到一个批次后有序输出的,因此需要排序
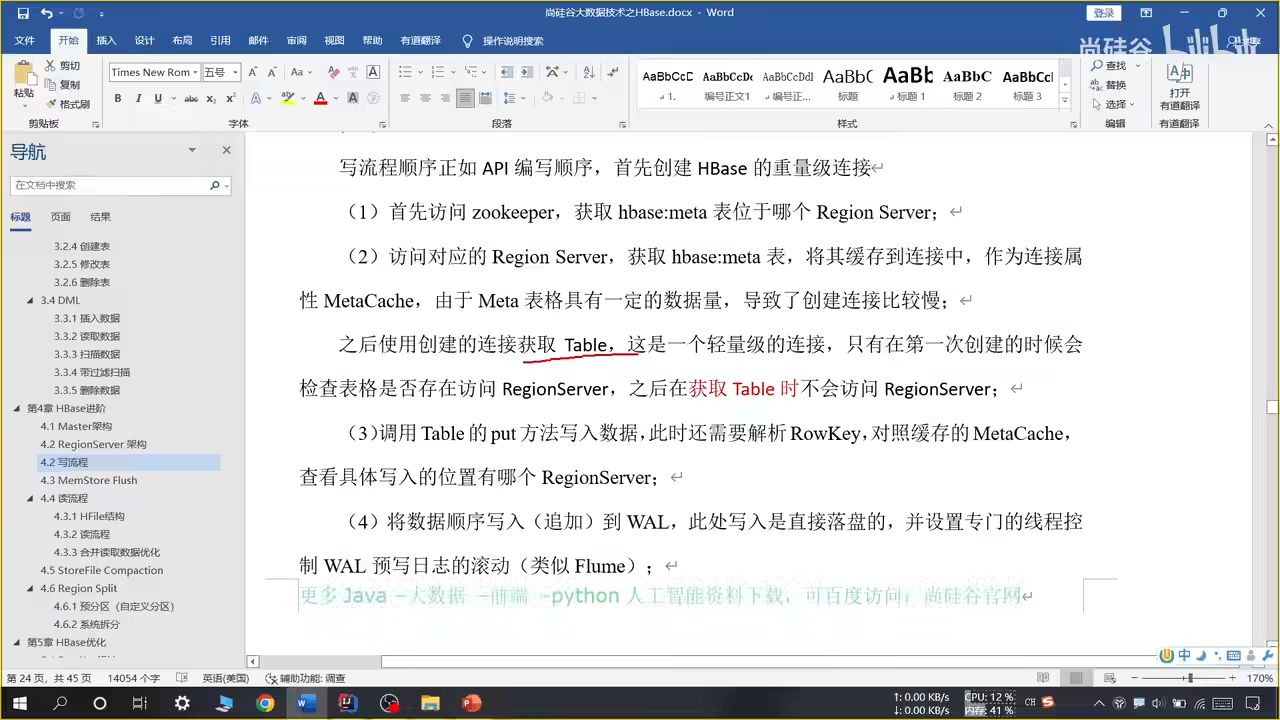
14、HBase 写流程
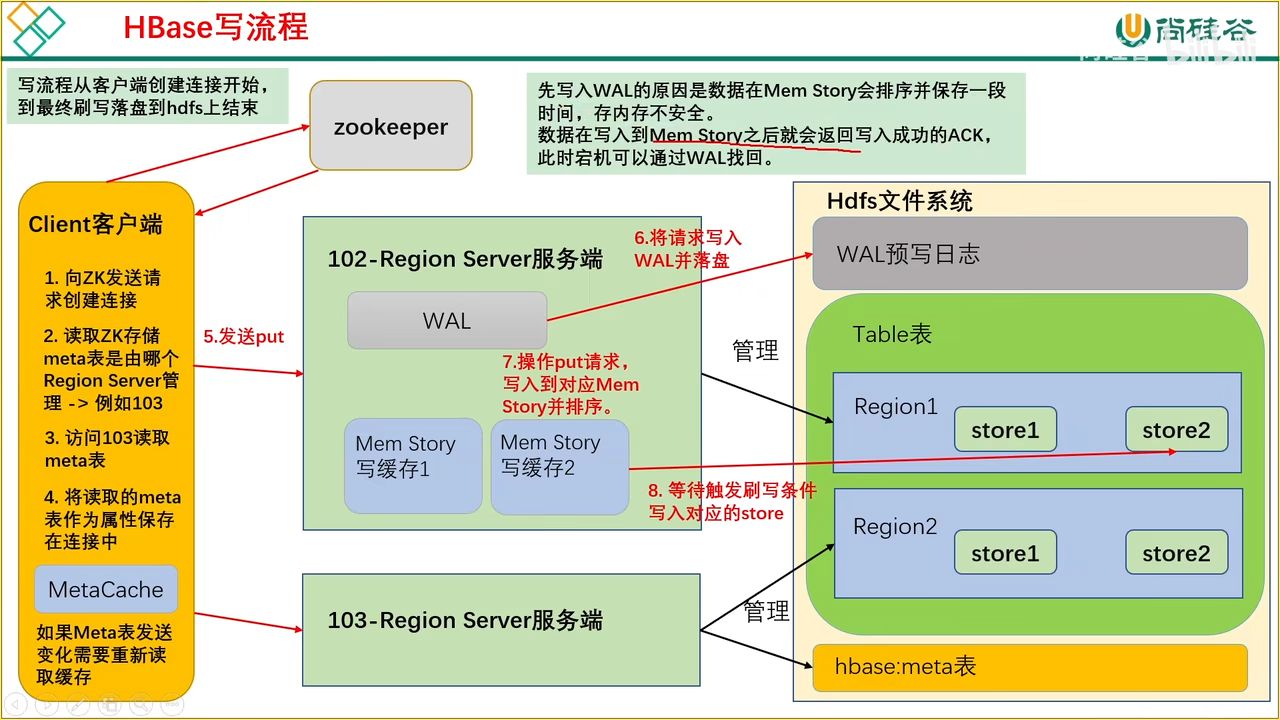
先预写日志到 HDFS 再写入缓存,因为内存不安全,如果丢失可以通过 WAL 找回
具体流程
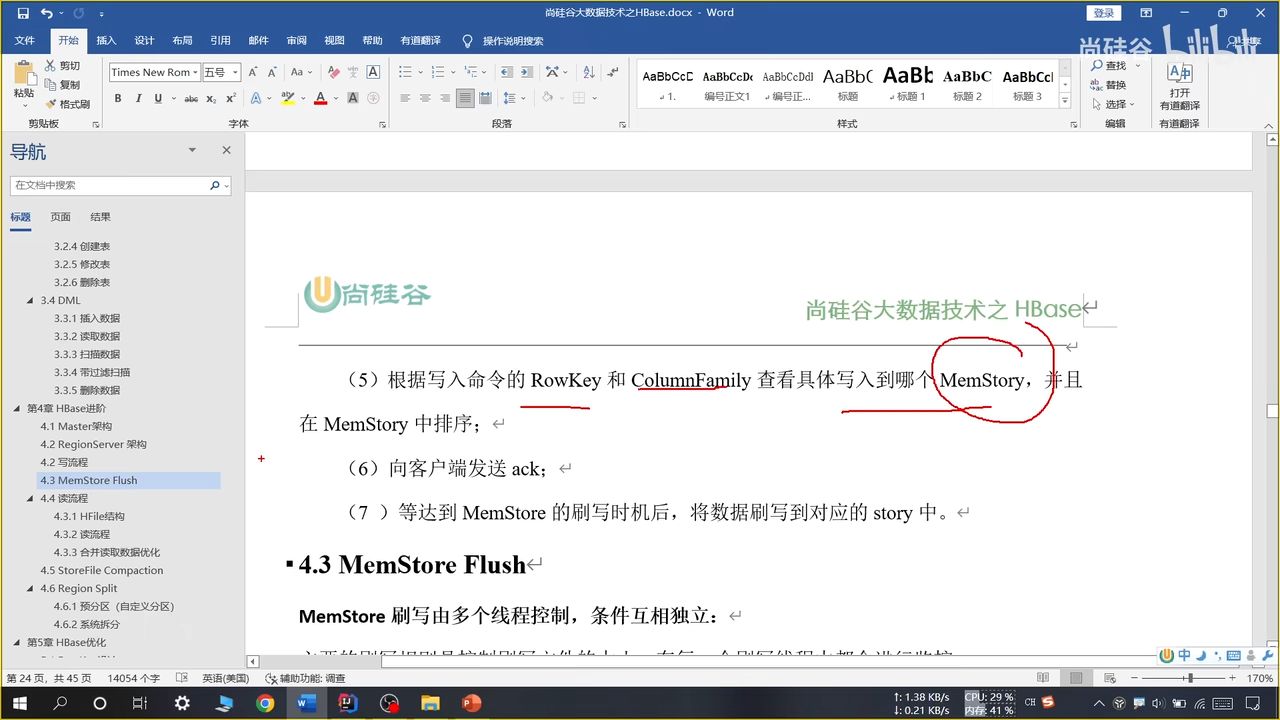
15、MemStore Flush 刷写
(1)按照大小(效率最高)
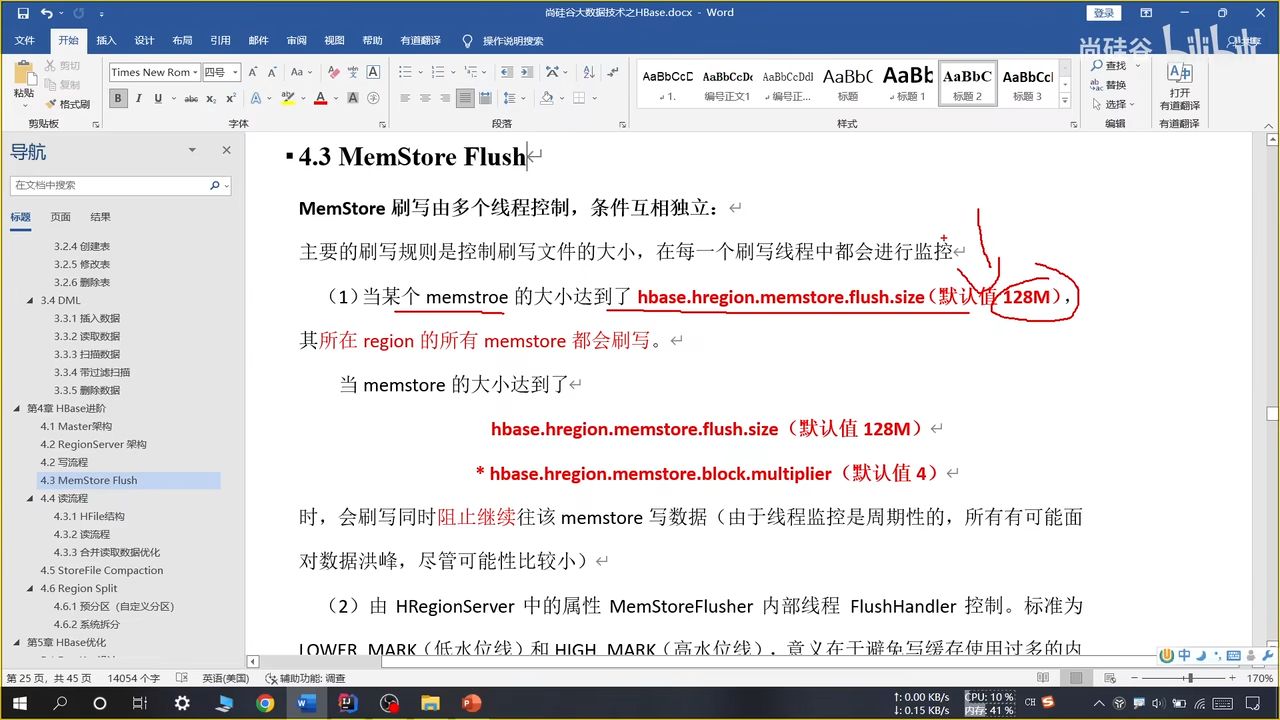
某个 store 达到了写文件大小,整个 region 都会进行刷写,哪怕可能导致小文件不均衡现象
一起刷写,一起保存,能够把一行存储在类似接近的位置(时间范围)
达到一定一定大小(一般是最大值的倍数,称为峰值),就会阻止继续往里面写数据
(2)低水位线(资源不足)

低水位线:还没那么危险,但是已经到了刷写的时机
图中第一行是低水位线,即写缓存占用 JVM 内存的百分比阈值,默认 0.4;
第二行是最大限制阈值,到第二行时必须刷写,即占总体内存的百分比。二者互不影响,且和其他条件(如条件 1)并行

(3)高水位线(资源不足)
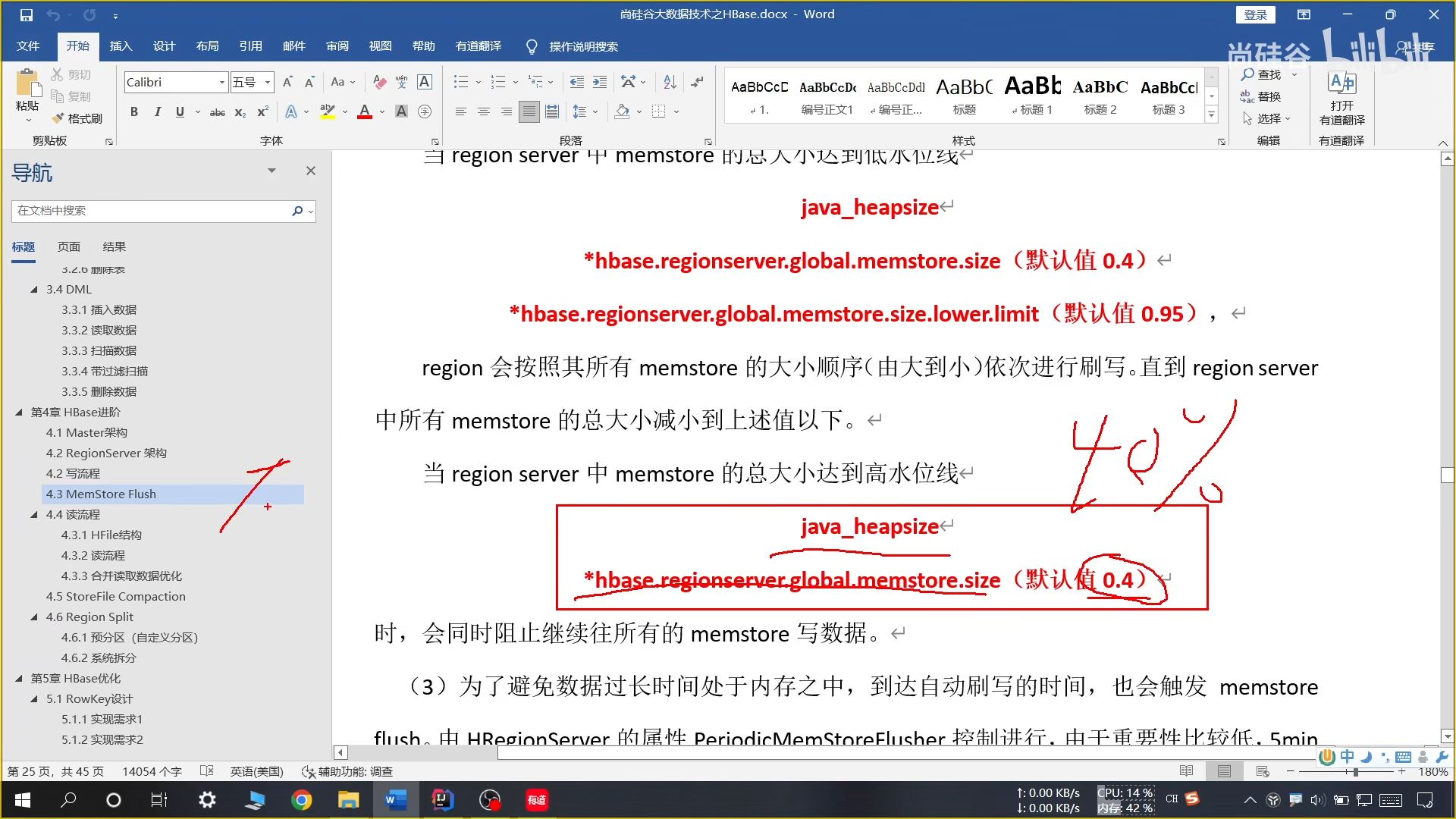
图中是高水位线,高水位线:已经比较危险了,必须马上刷写,并进行写入控制防止溢出,会设置一个睡眠时间防止溢出风险,并设置哟超时限制
(4)按照时间(资源太充足)
周期性刷写,5 分钟一次监控,超过一个小时强制刷写
16、HFile 结构
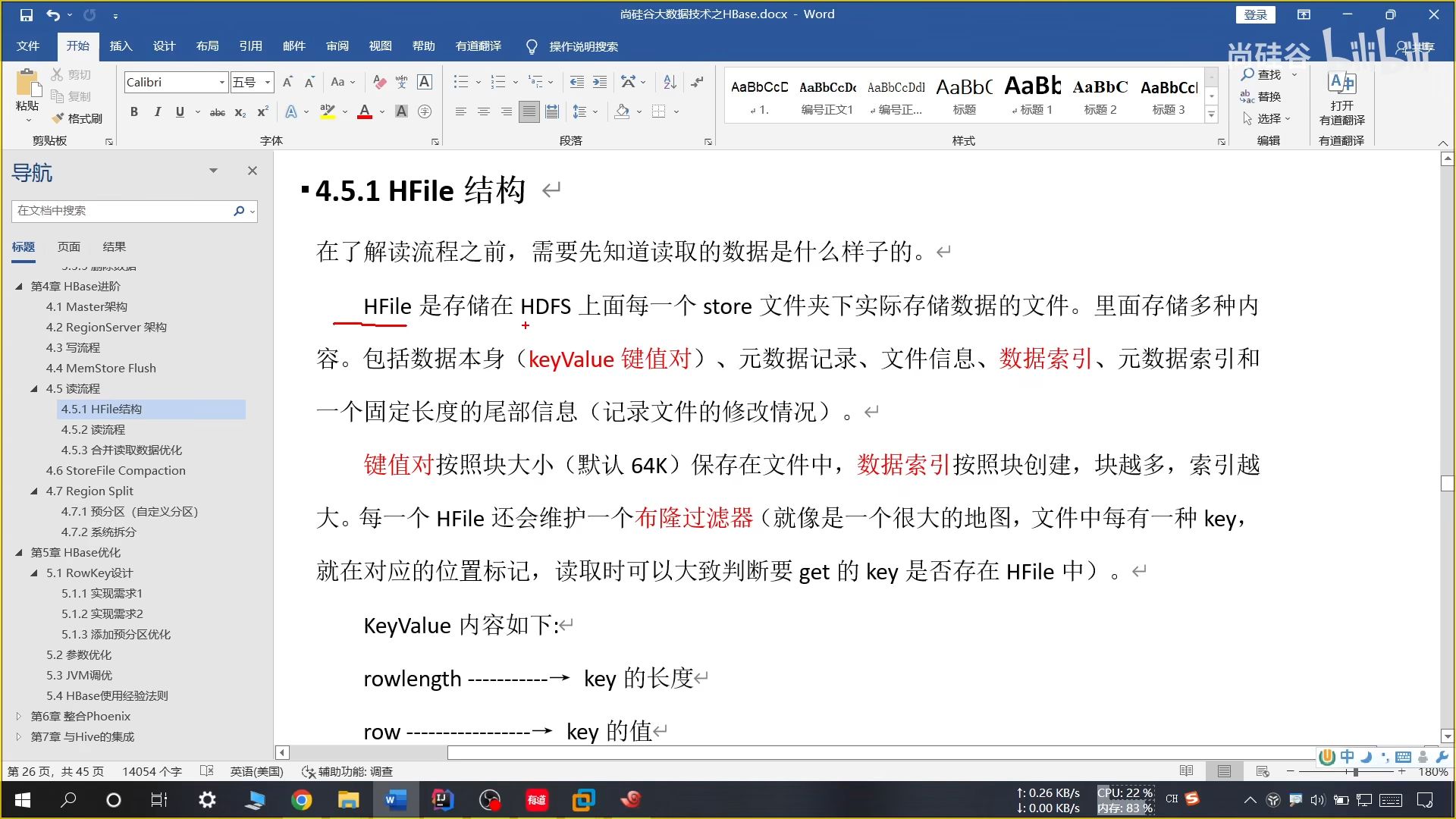
HDFS 中 store 存储的内容:
k-v 键值对、元数据记录、文件信息、数据索引、元数据索引、尾部信息
键值对按照块大小(默认 64k)进行存储,数据索引按照块创建,块越多索引越大。
HFile 中还会维护一个布隆过滤器,文件中每有一种 key,就在对应模余的位置标记,读取时可以大致判断要 get 的 key 是否存在 HFile 中

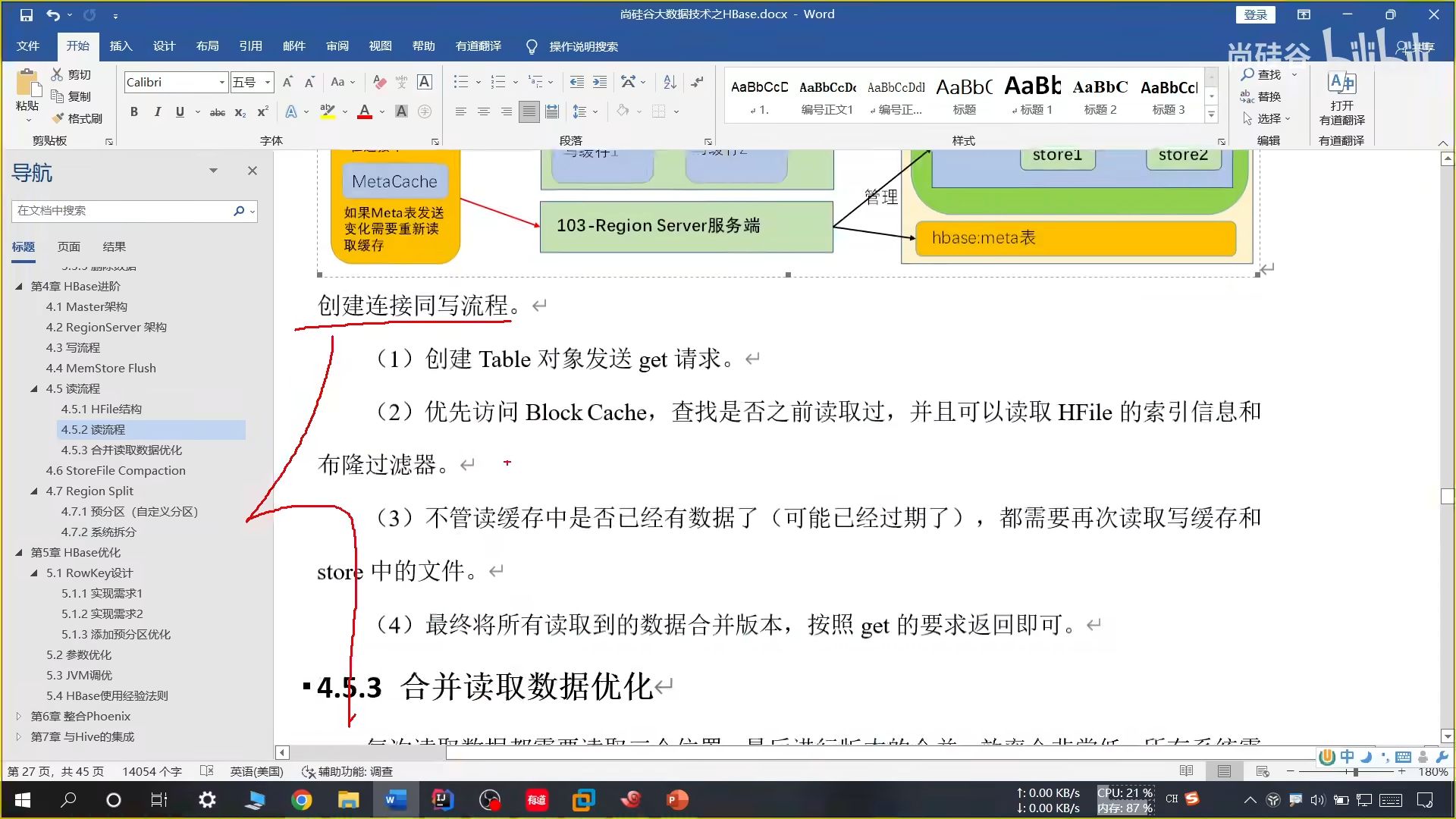
17、读流程
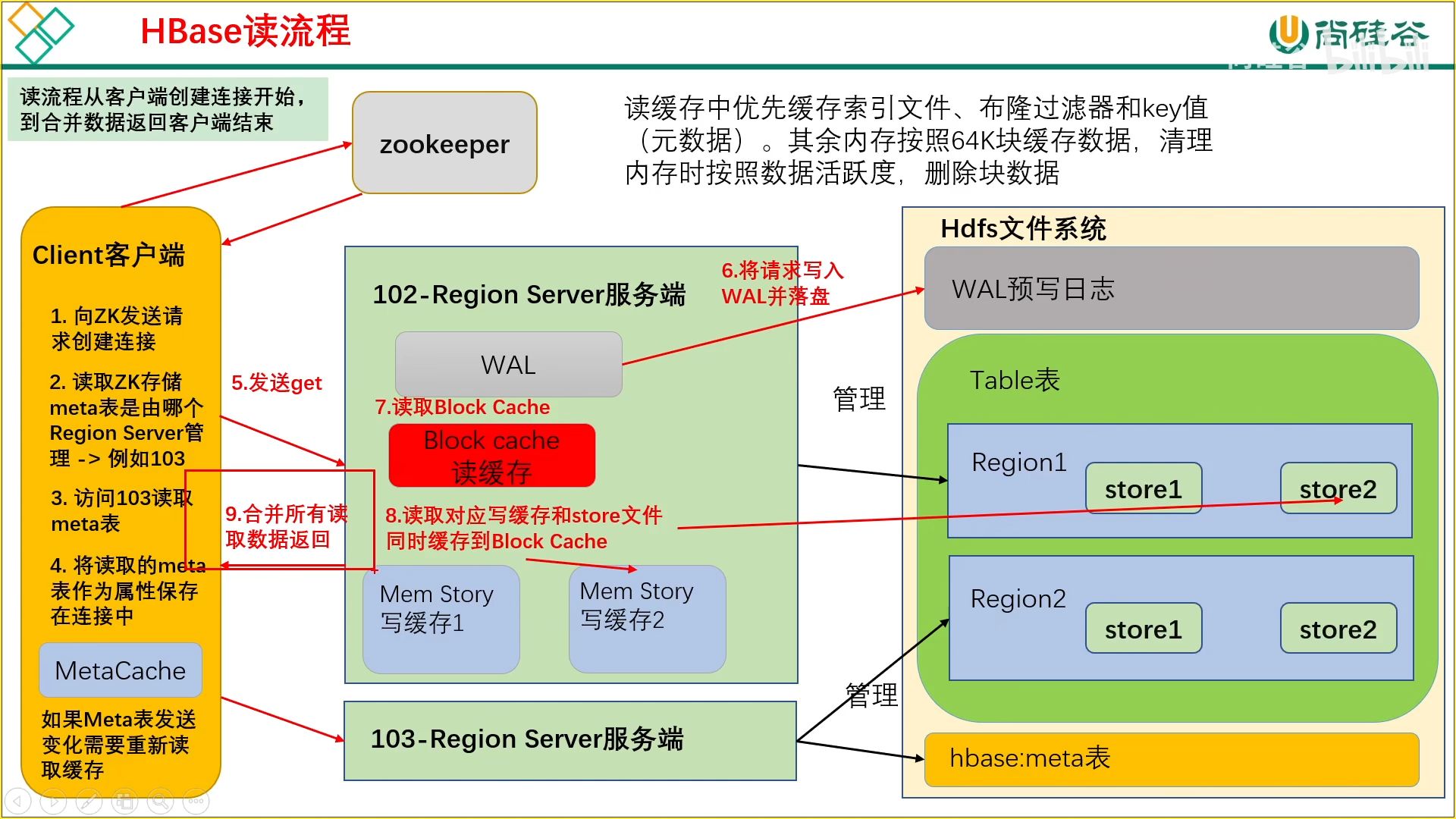
读流程涉及到三个区块:
(1)读缓存
(2)写缓存(刚写进去还没有落盘)
(3)Hdfs 文件系统中落盘的数据
在读取完后进行合并,将高版本的相同数据覆盖低版本的
18、合并读取数据优化

(1)有索引文件,读取对应 rowkey 会快一些
(2)有缓存读取的内容和元数据信息,没有变化时不用再次读取
(3)使用布隆过滤器可以快速判断 Rowkey 是否存在
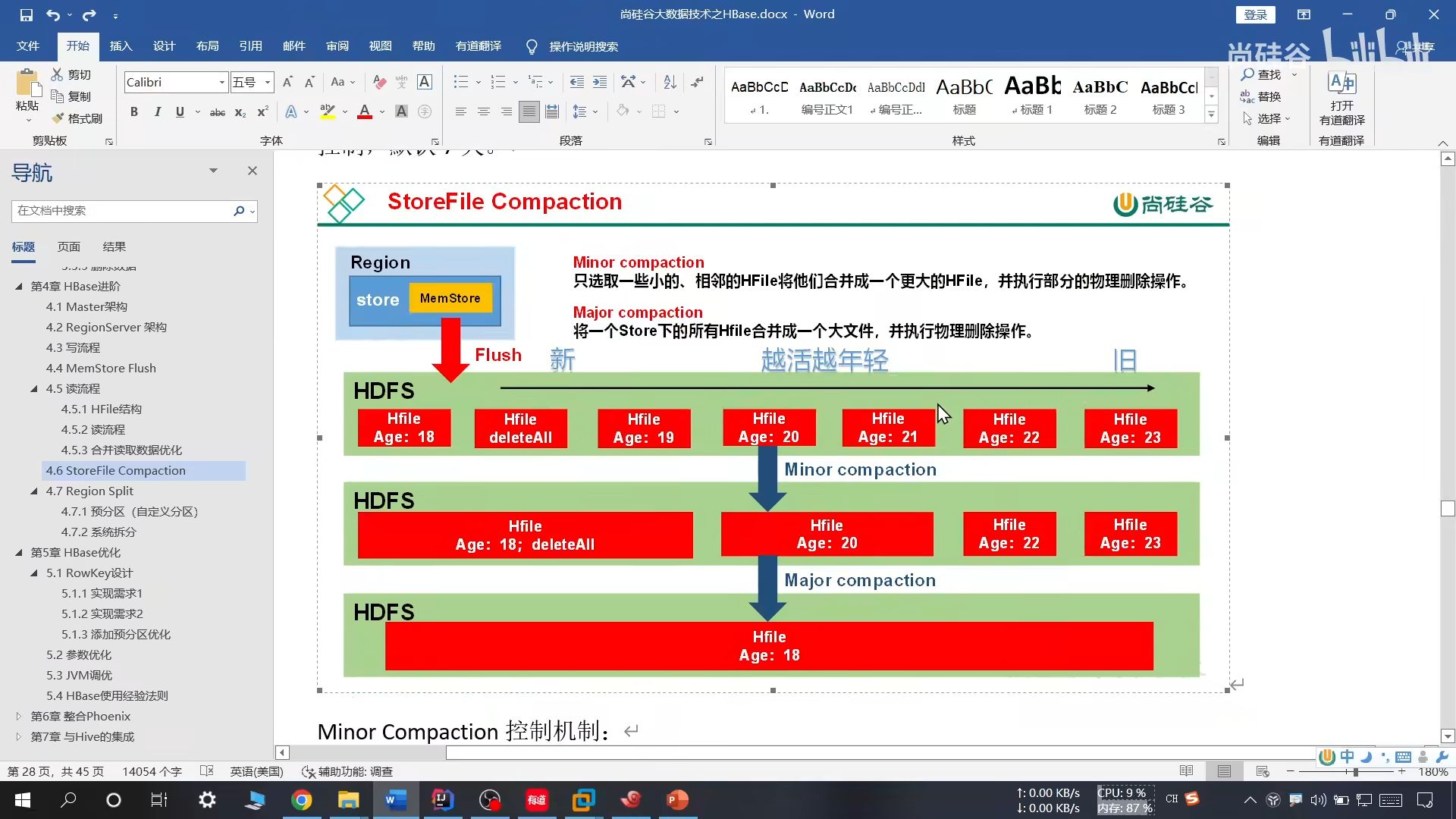
19、文件合并
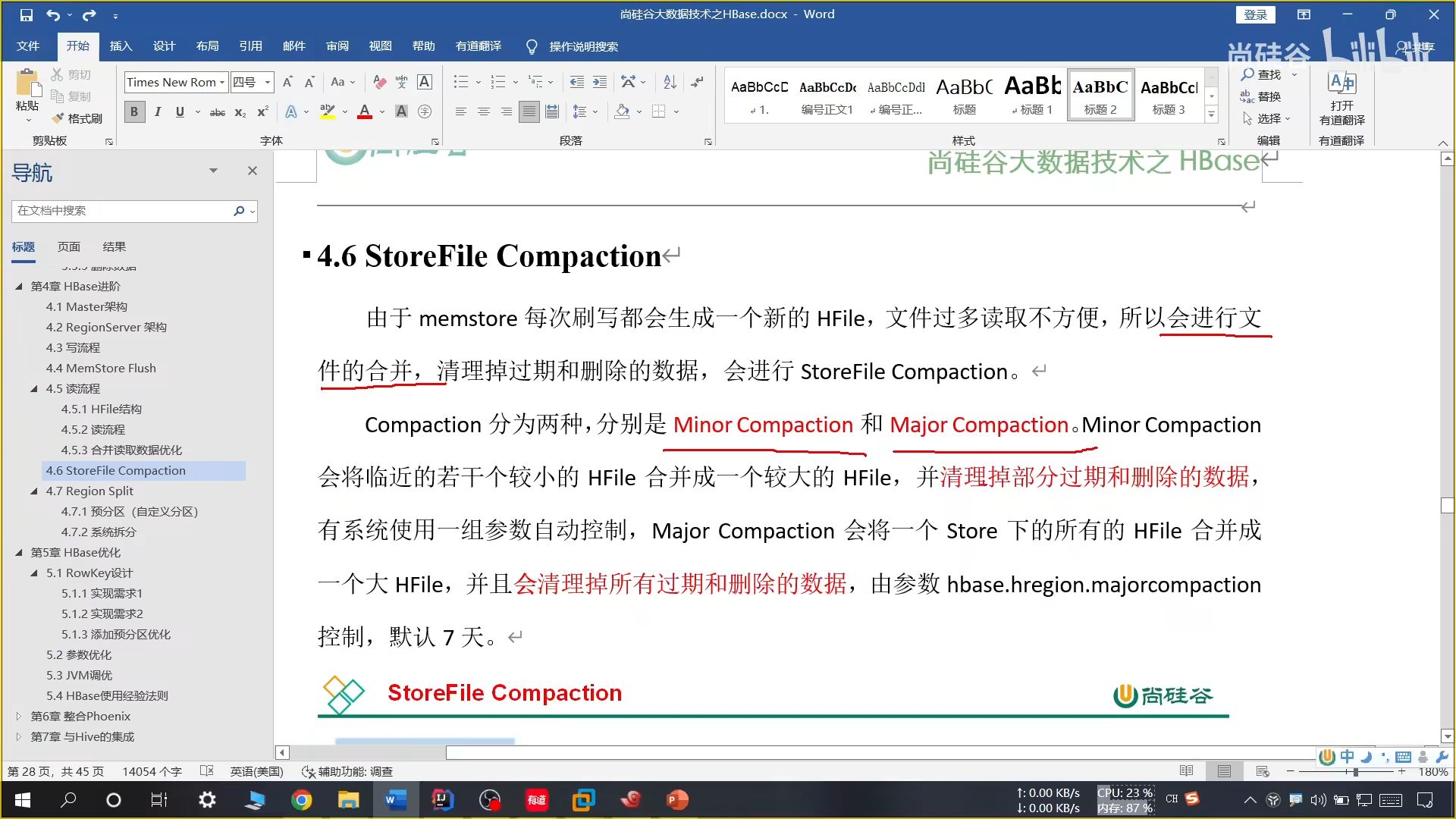
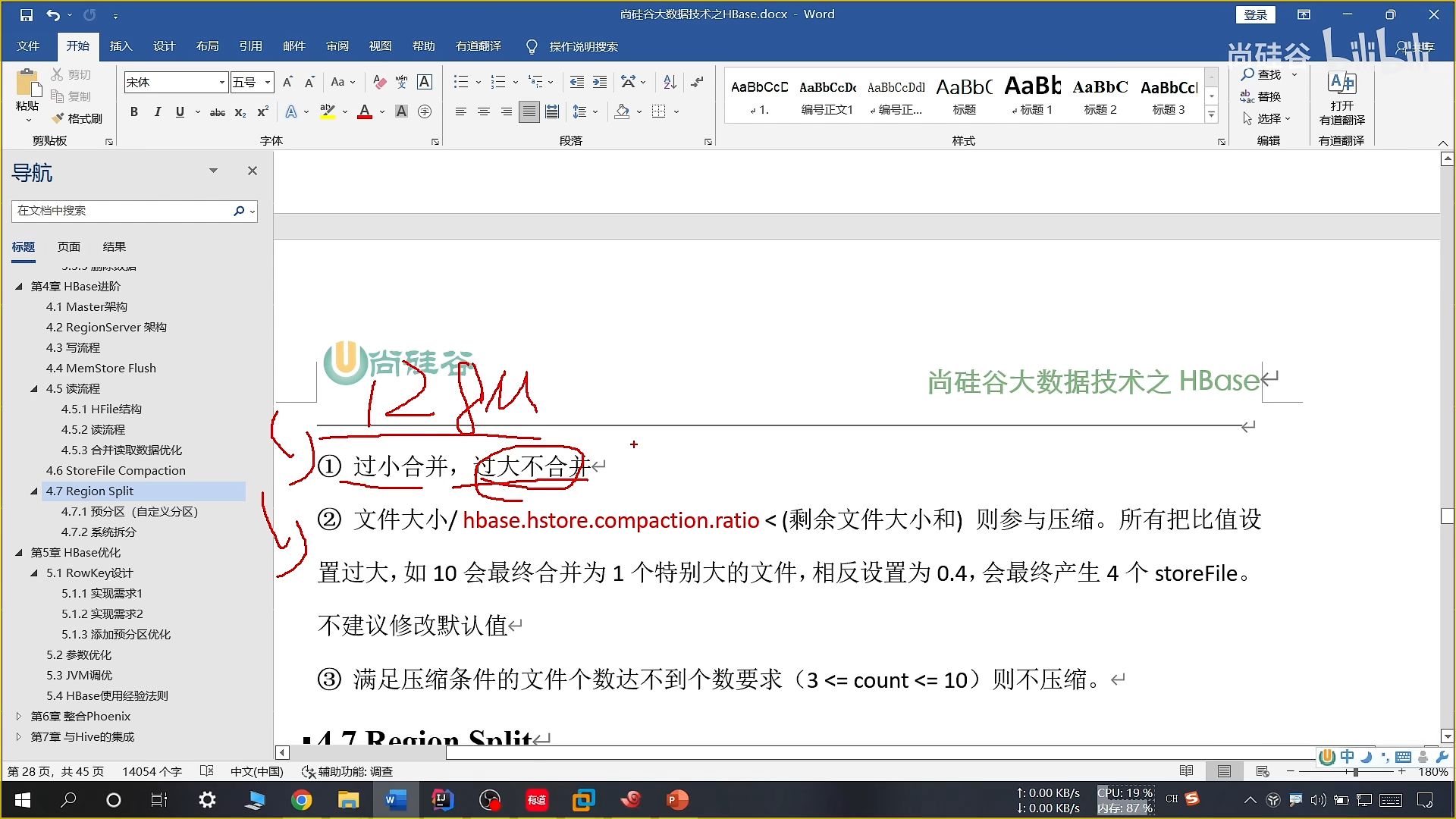
小合并:把临近的 3 个文件合并成一个较大的,并清理部分过期和删除数据

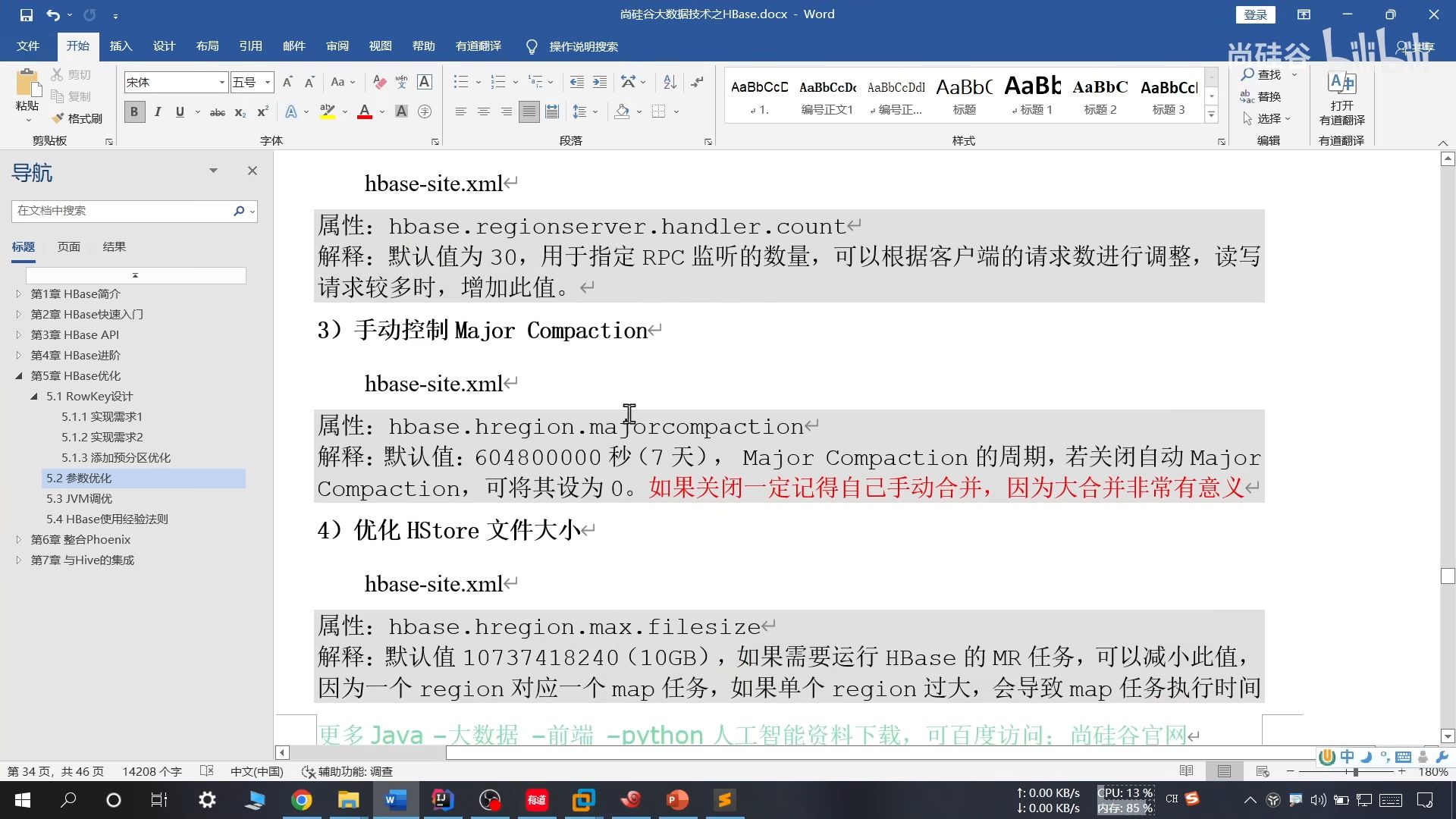
大合并:把一个 store 下的所有 HFile 合并成一个大的,并清理所有过期和删除的数据,默认 7 天一次
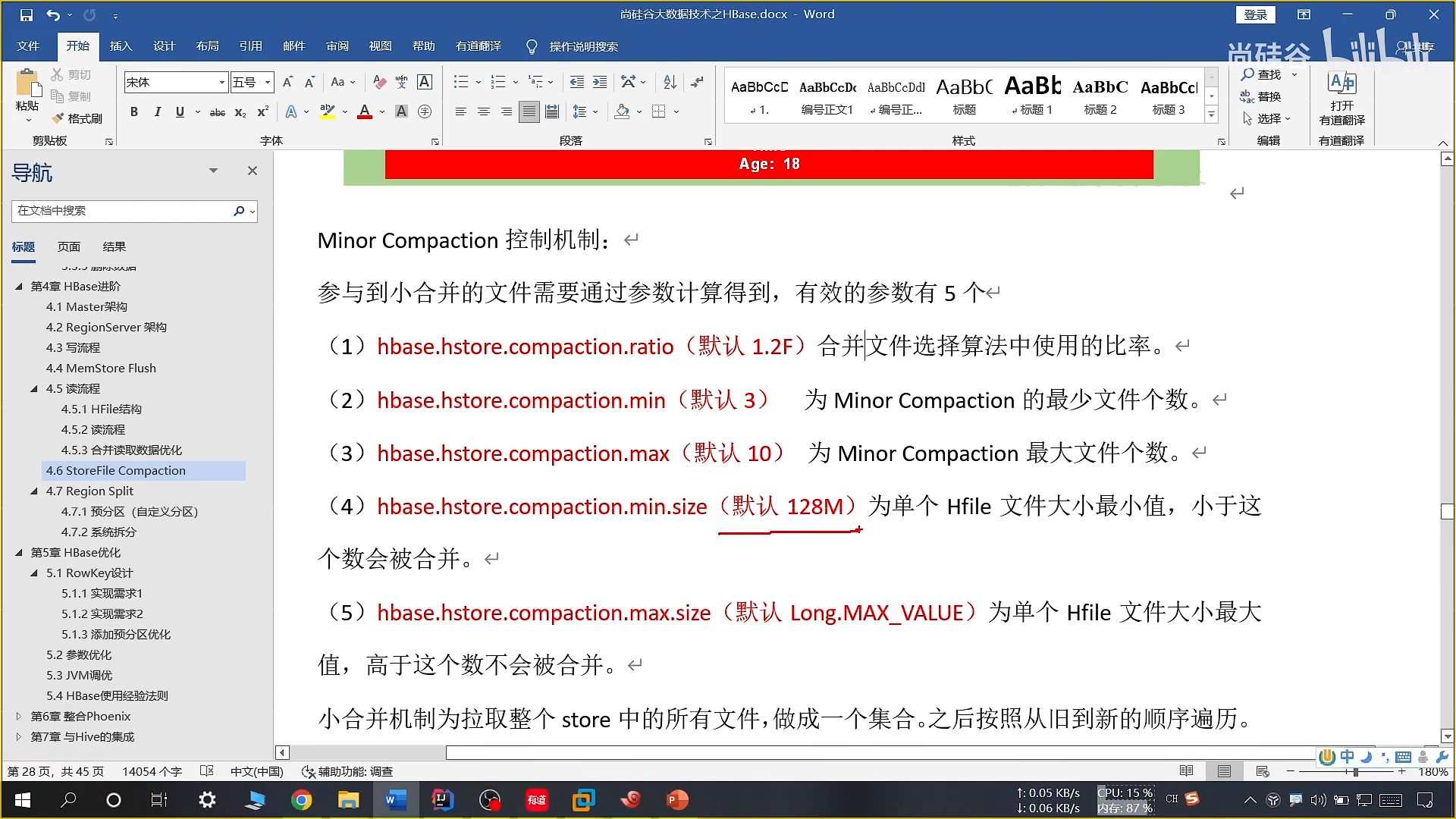
20、小合并合并机制
21、预分区(自定义分区)
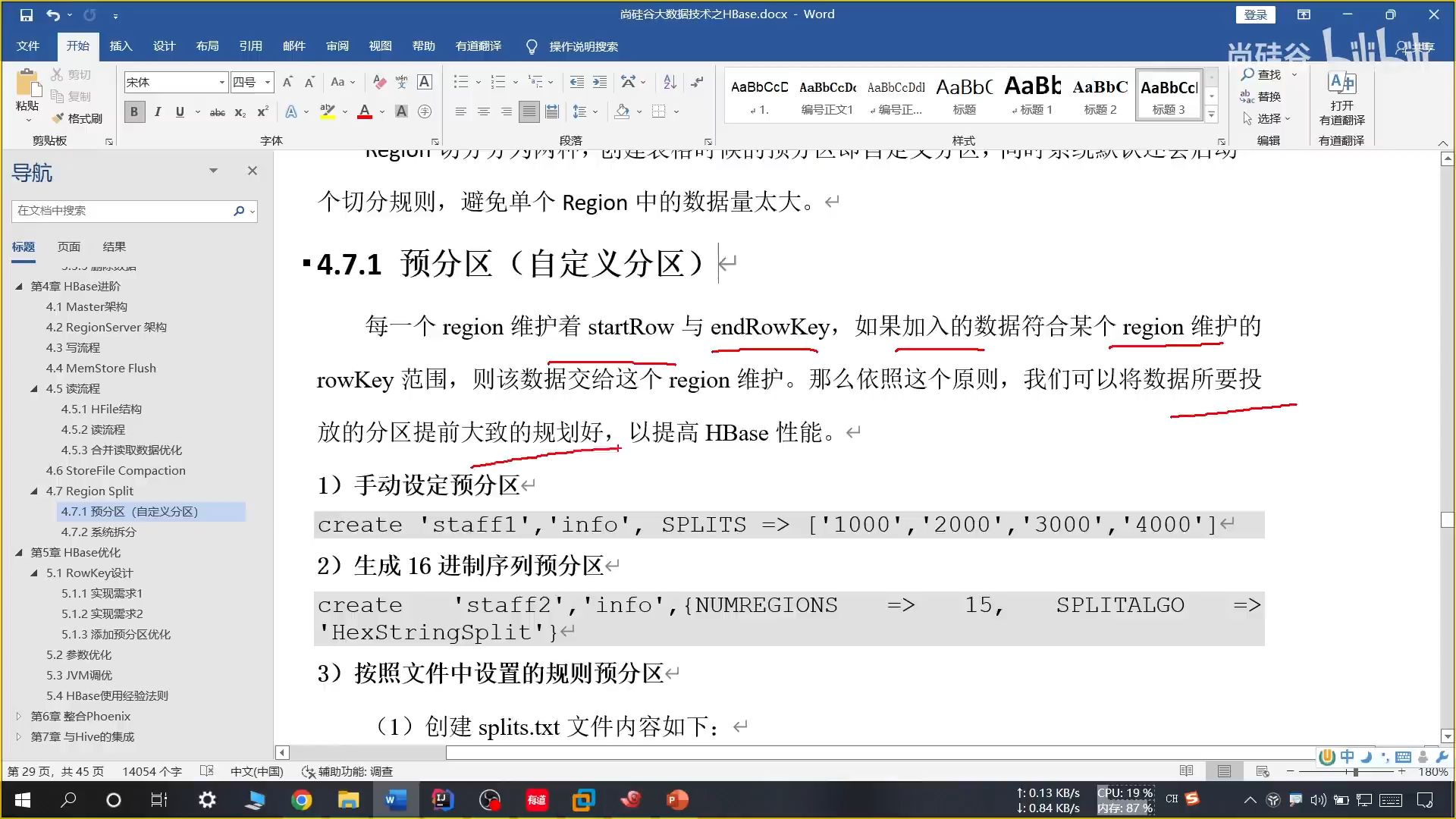
(1)手动设定预分区
推荐使用,切 N 刀就有 N+1 个分区
(2)生成 16 进制分区
不推荐使用,需要将 ROWKEY 转换 16 进制分区太麻烦
(3)文件规则
效果和(1)相似
(4)API 创建预分区
比较少用
22、系统拆分
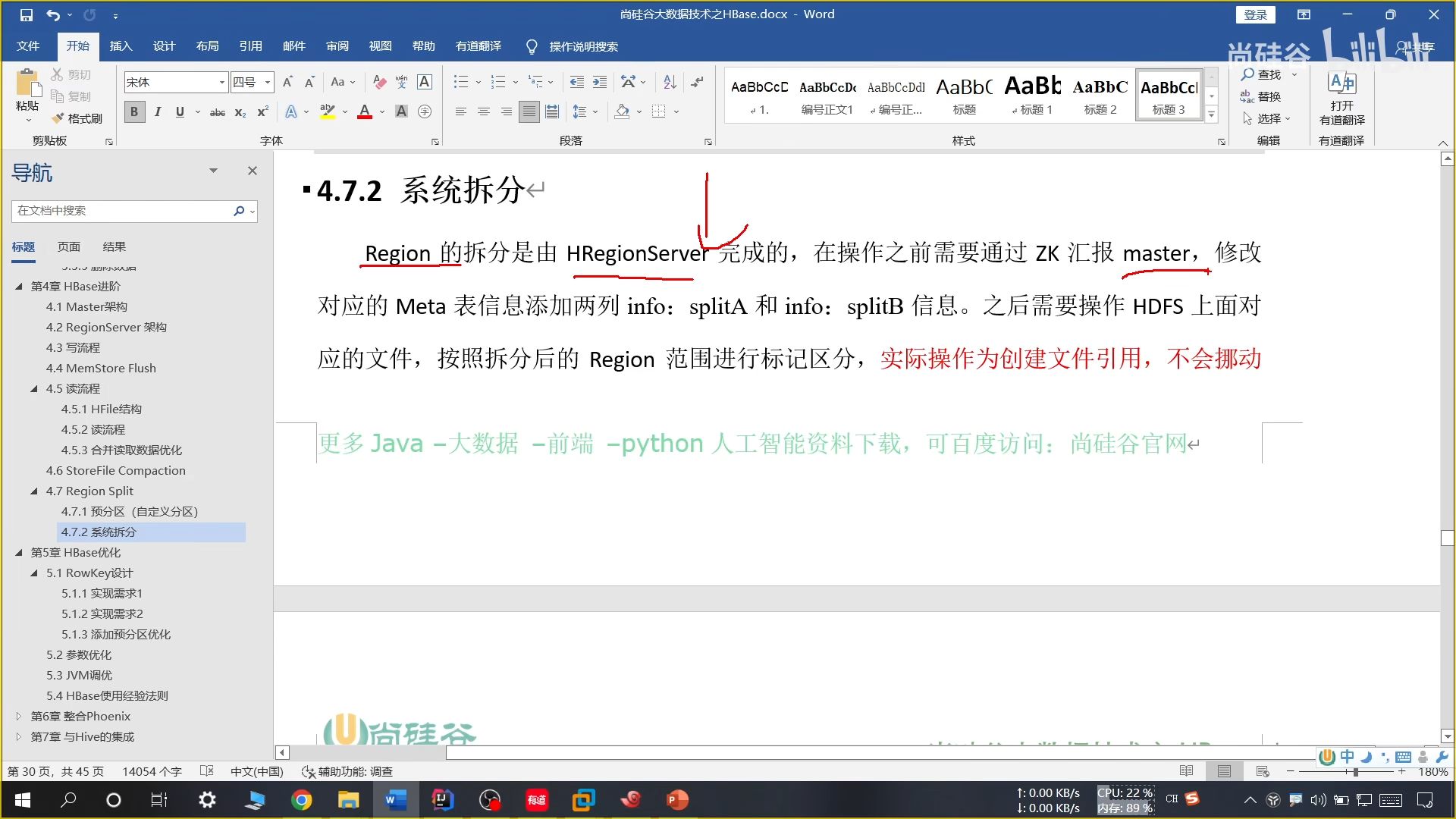
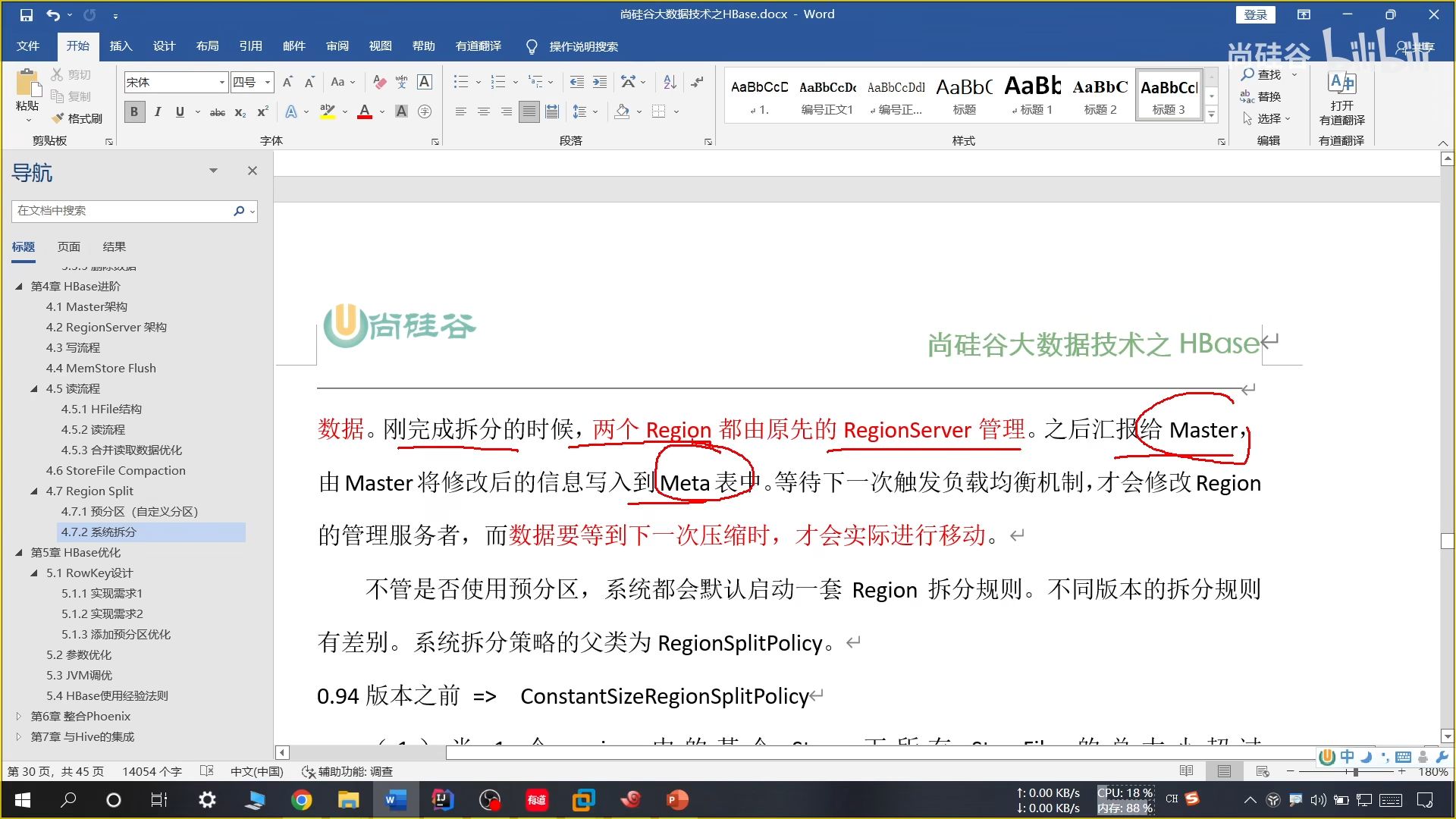
目前采用的方法:
只有一个 Region 的时候,当大小为 2 * 刷写大小(256M)进行拆分,后续达到 10G 进行一次拆分
23、RowKey 设计
(1)按照 MYSQL 表格设计
不推荐,效率不高
(2)TSDB 时间戳数据库
把时间写到 Rowkey 里,可以记录一个值的变化情况
具体方案
(1)生成随机数、hash、散列值
(2)时间戳反转
(3)字符串拼接
常规实现:
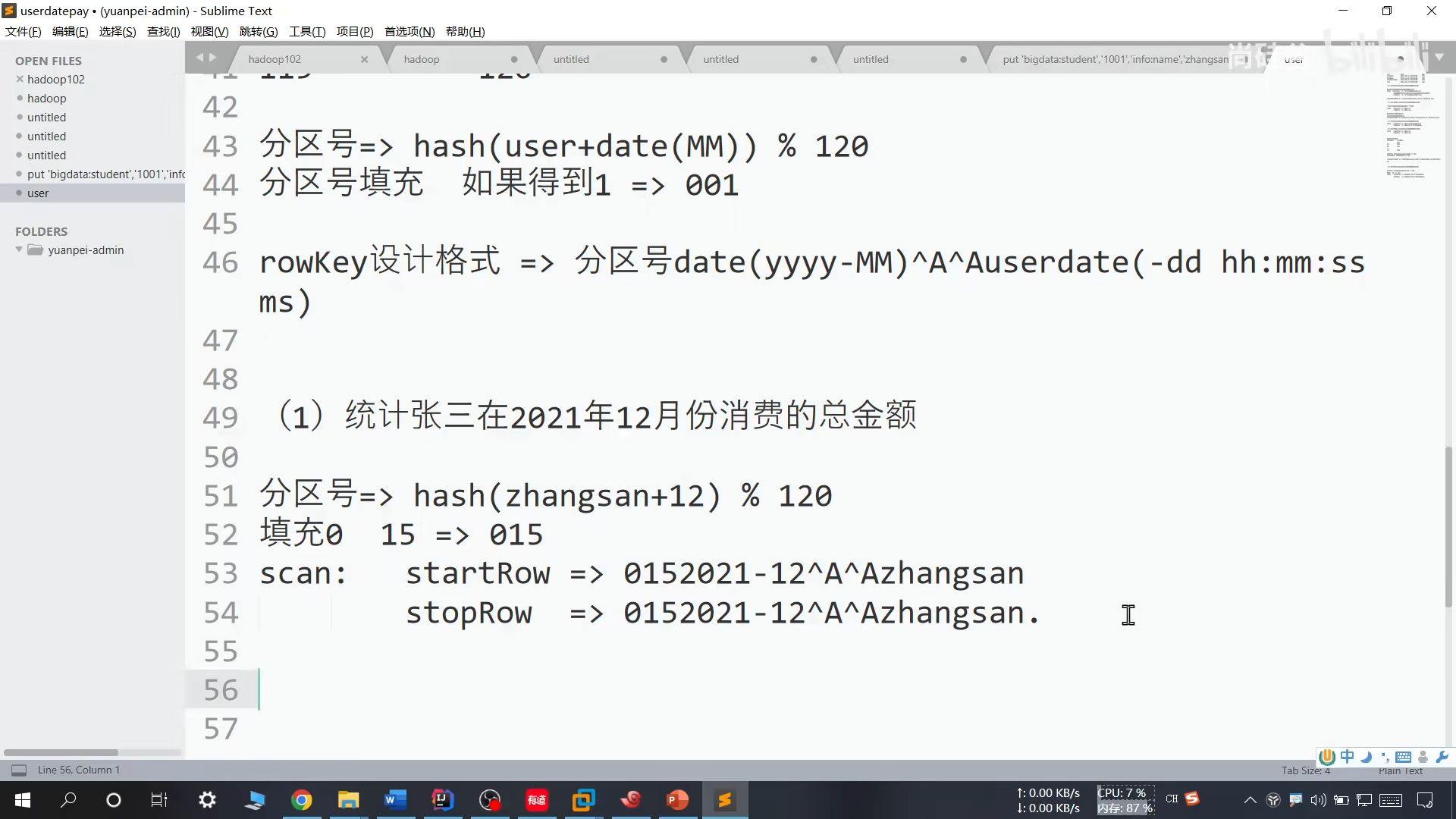
(1)为了防止 scan 过程中取出不相关的键值,使用 AA 进行占位。
(2)结尾需要写和设计的 rowKey 对应位置的值大的字符
(3)设计格式:AAuserdate(yyyy-MM-dd hh:mm:ss ms)
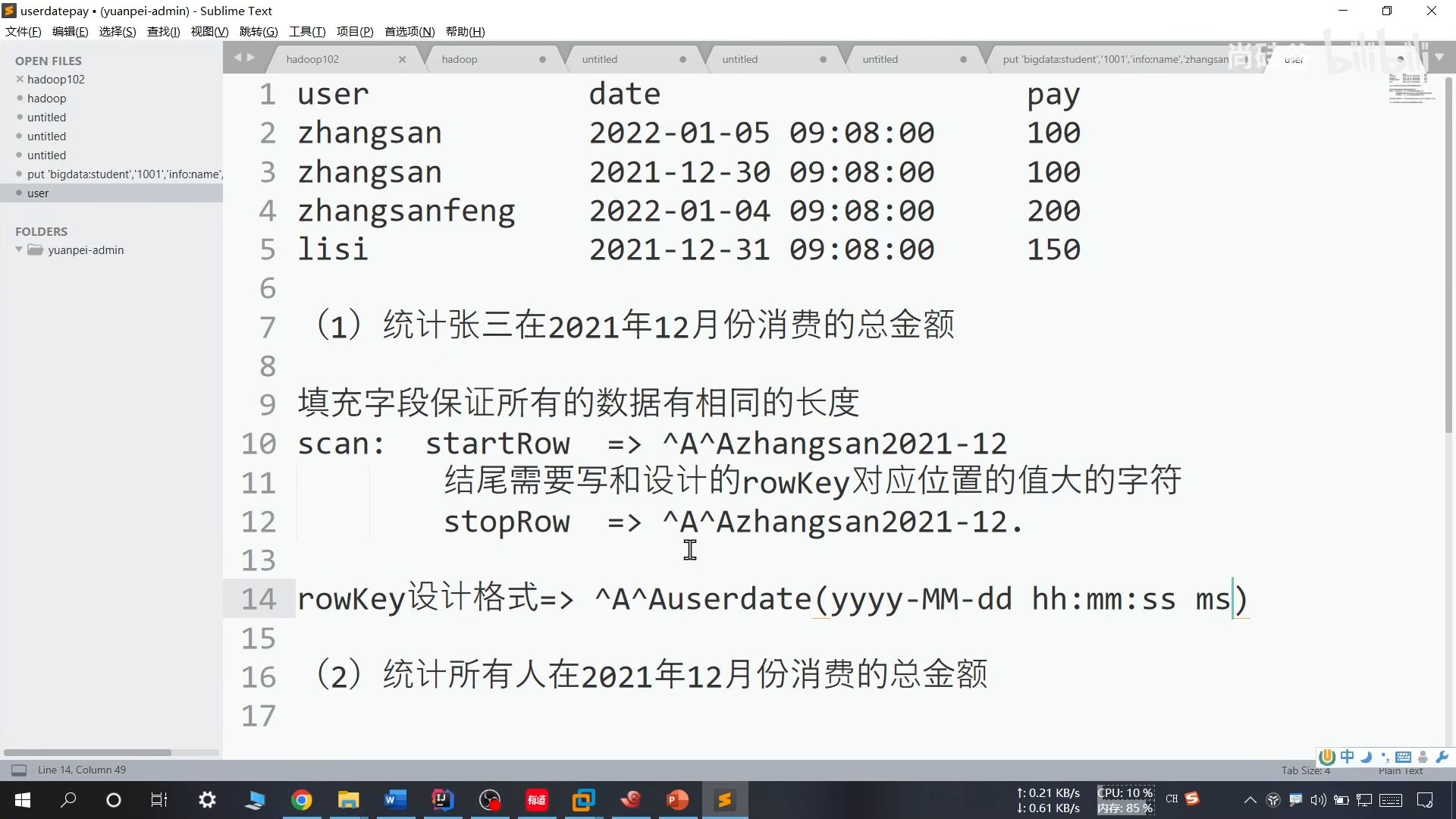
(4)上述方法仅仅适用于单一问题的方案解决,如果需要对多个问题进行解决,那么键值需要重新设计,关键在于把可以穷举的条件写在前面即可
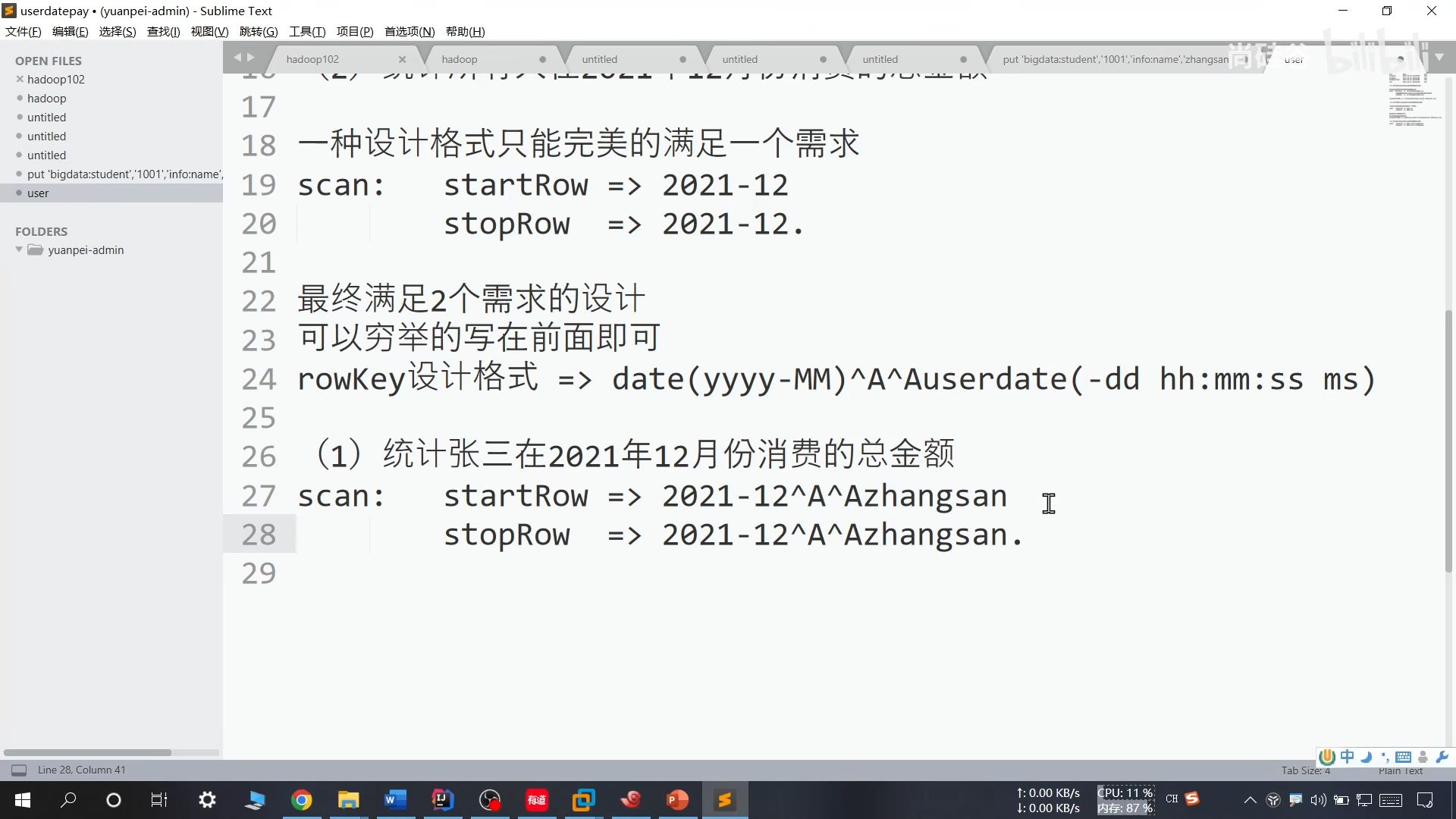
24、添加预分区
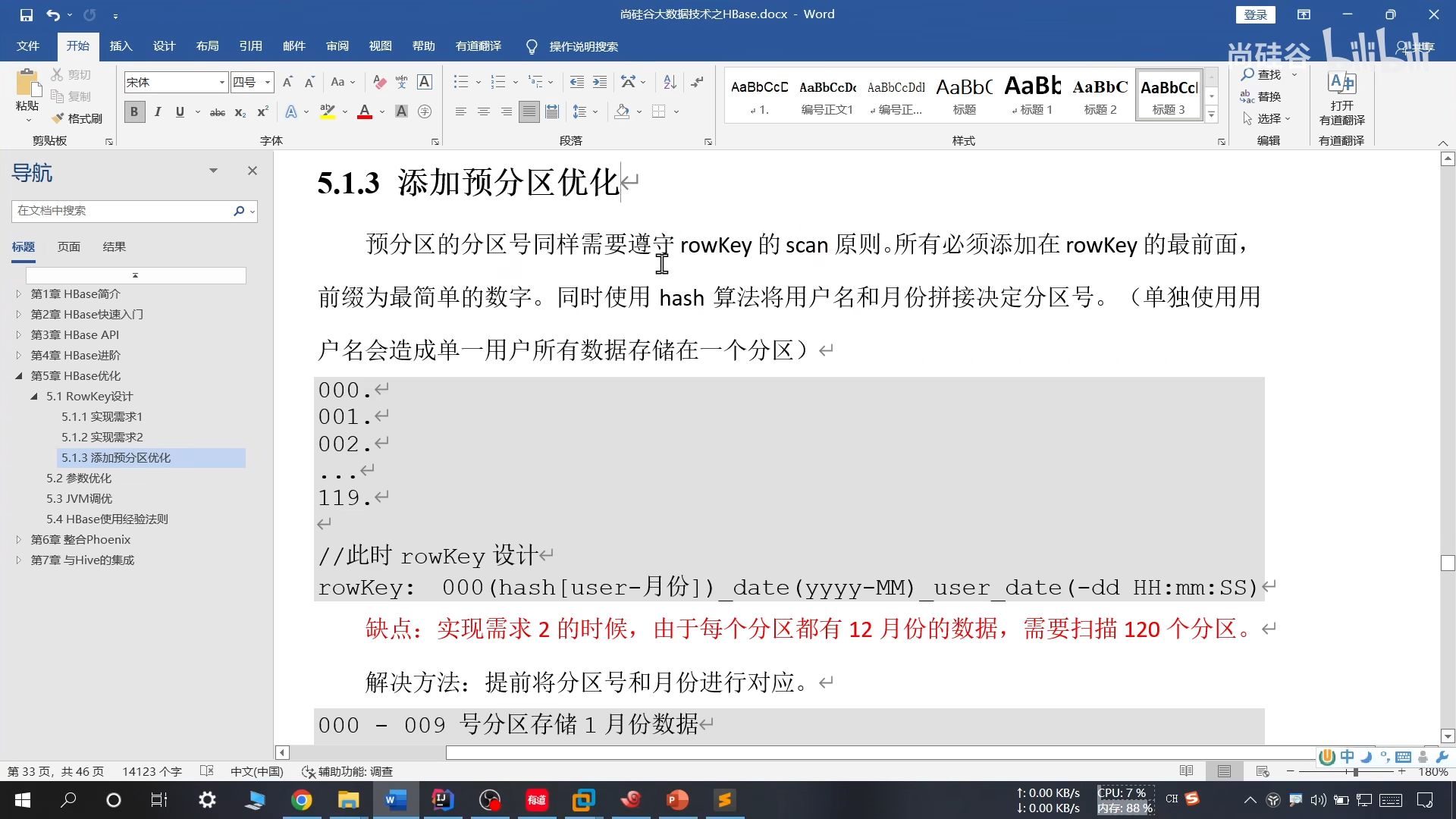
具体做法:
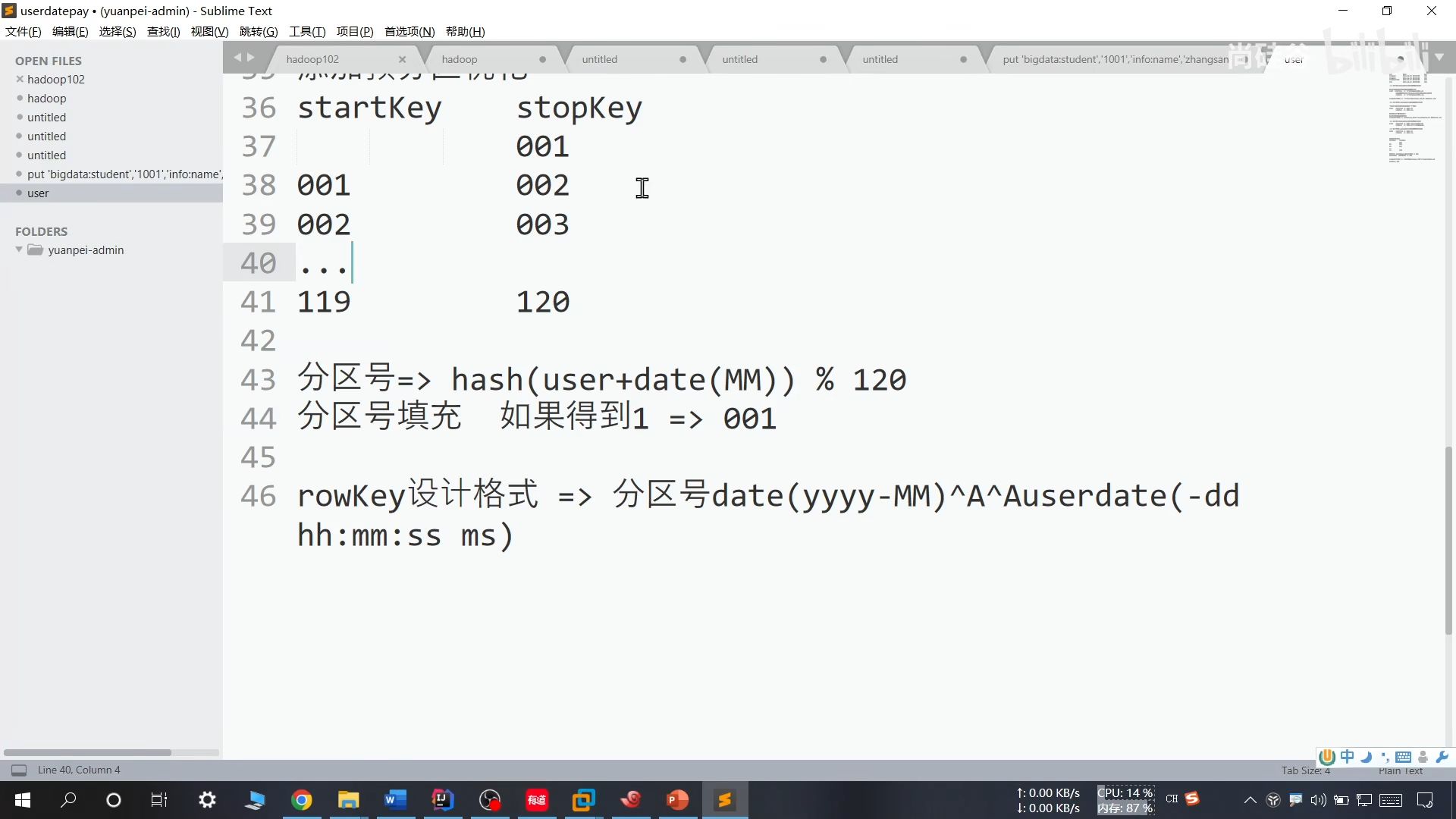
25、预分区优化
存在问题:
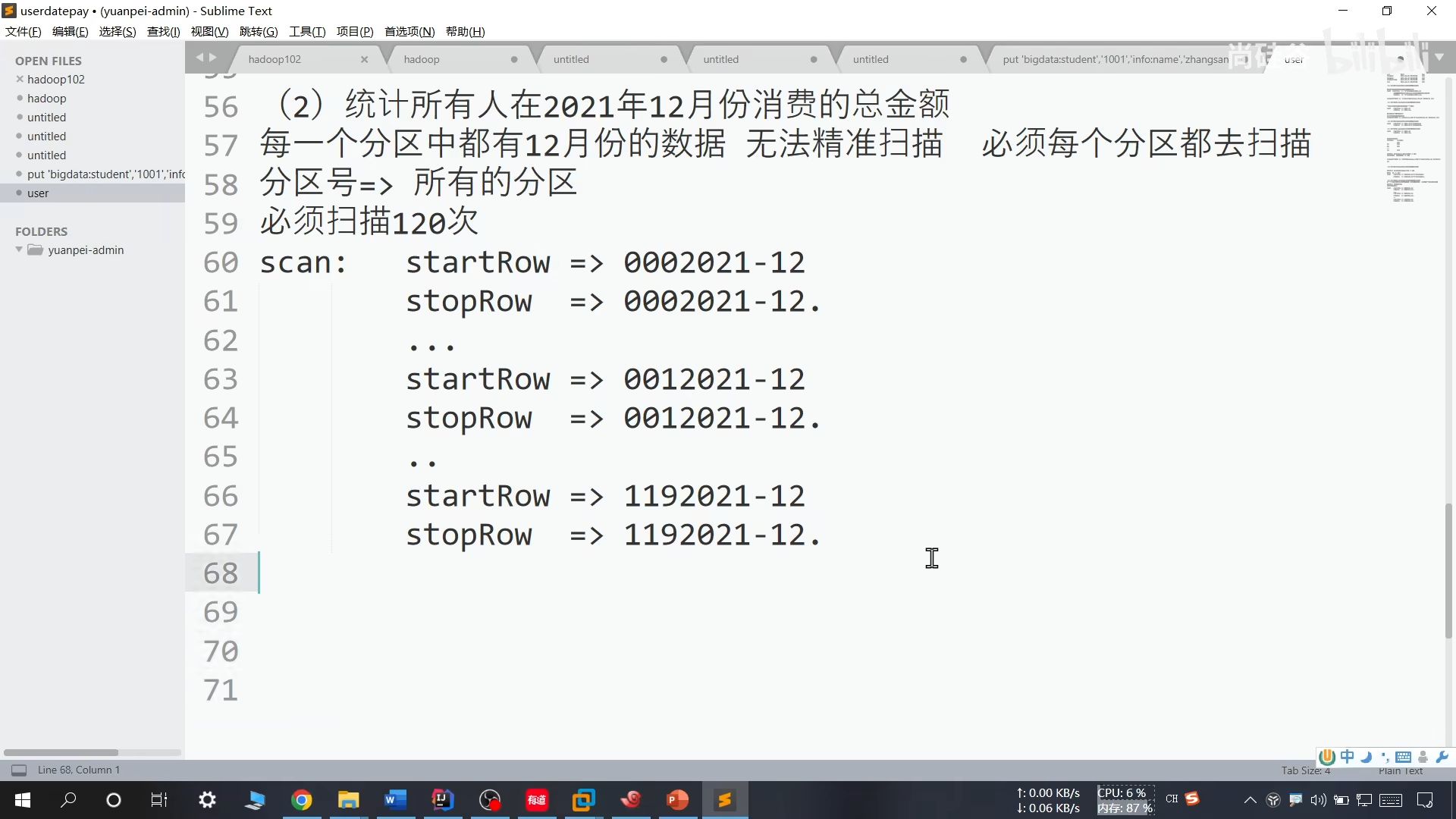
解决方法:
提前将月份和分区号对应一下
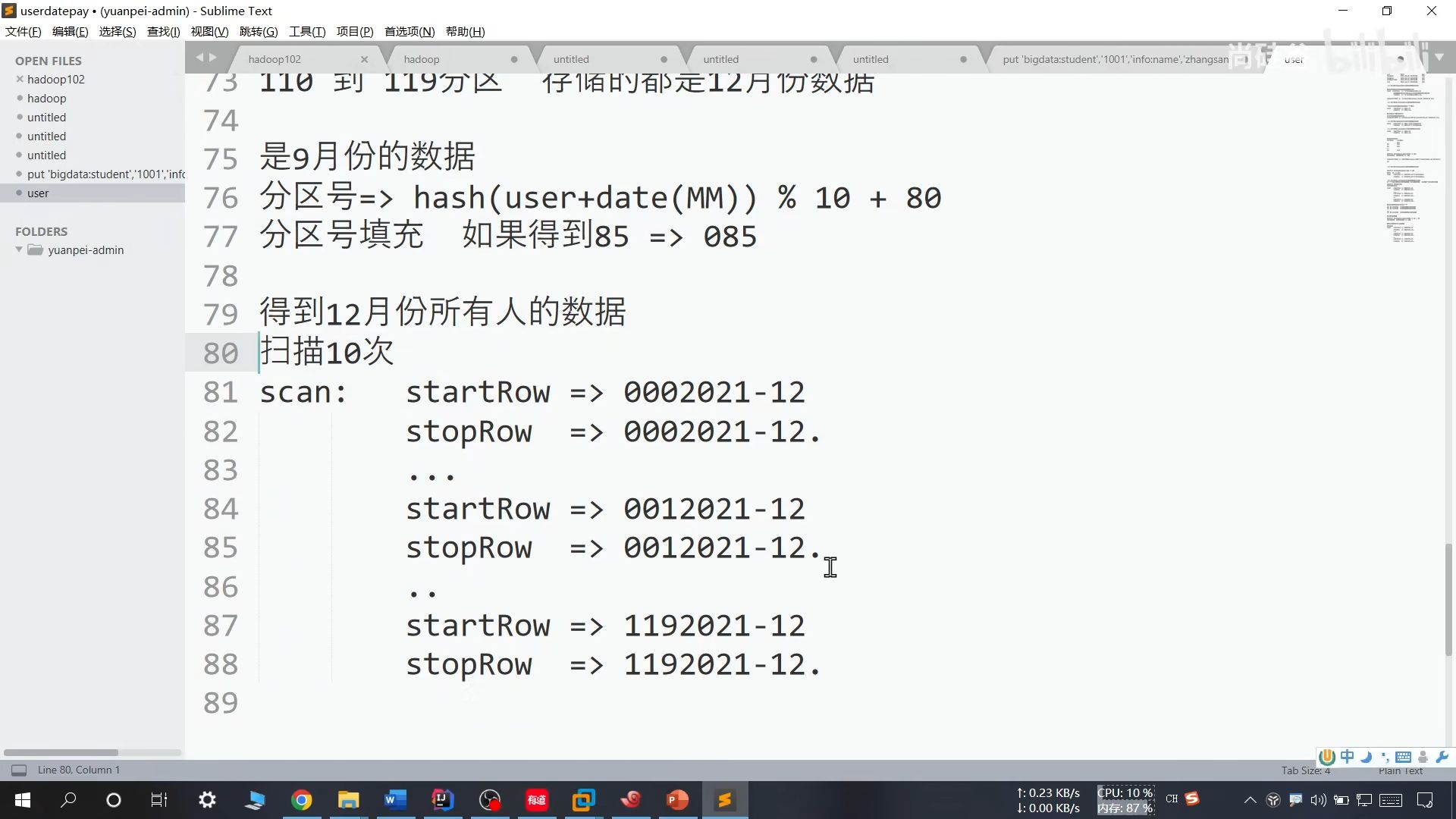
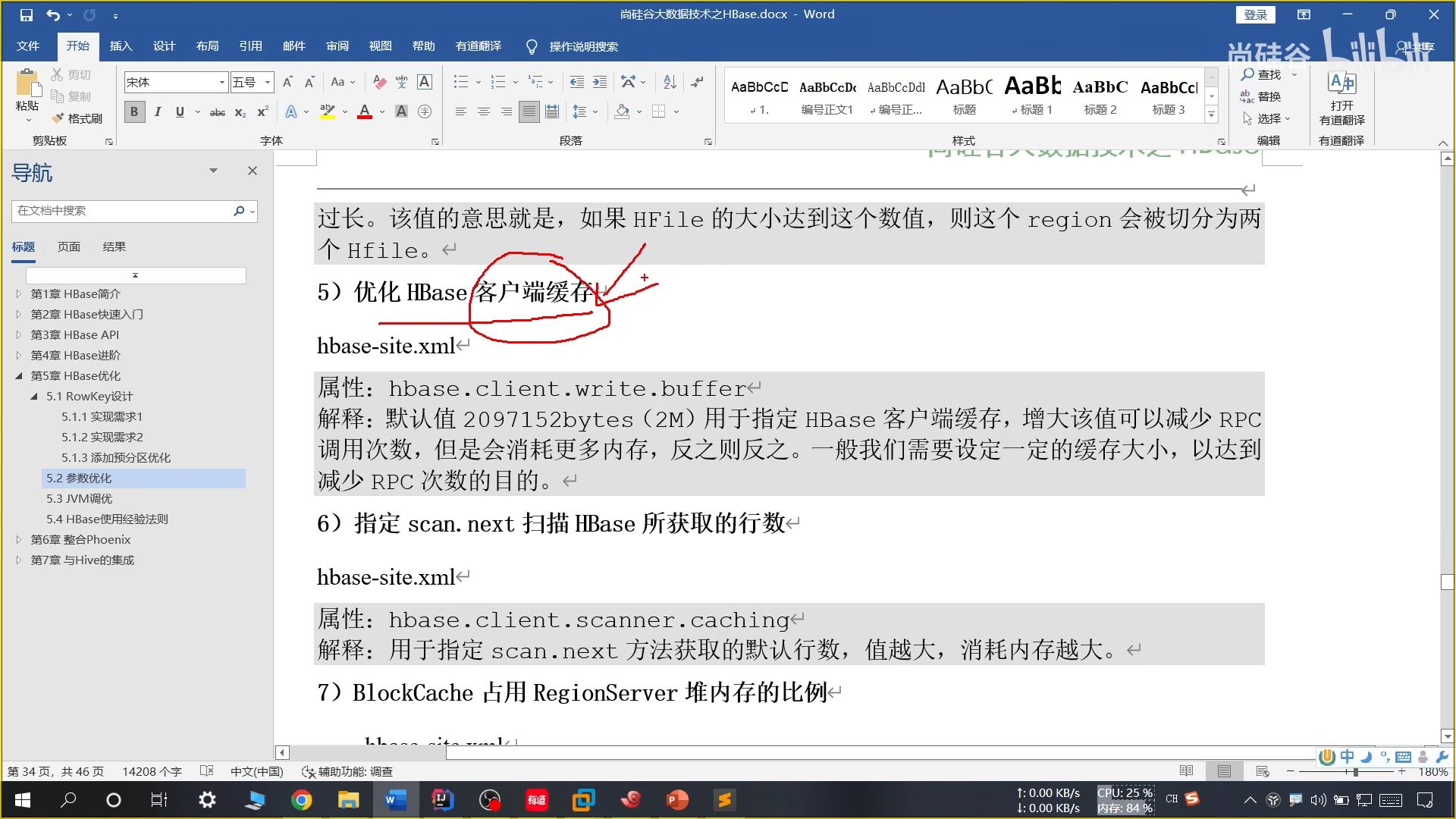
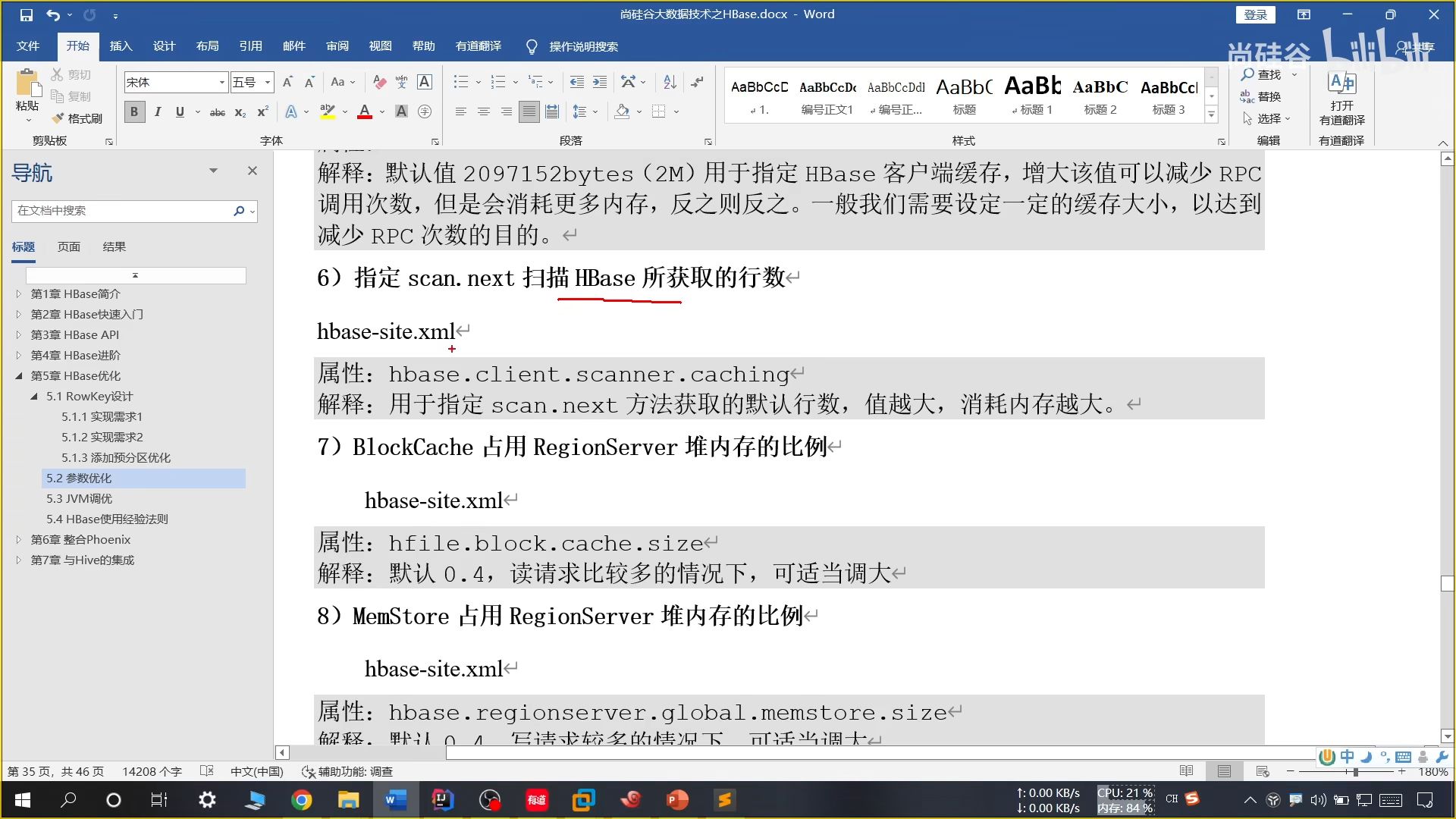
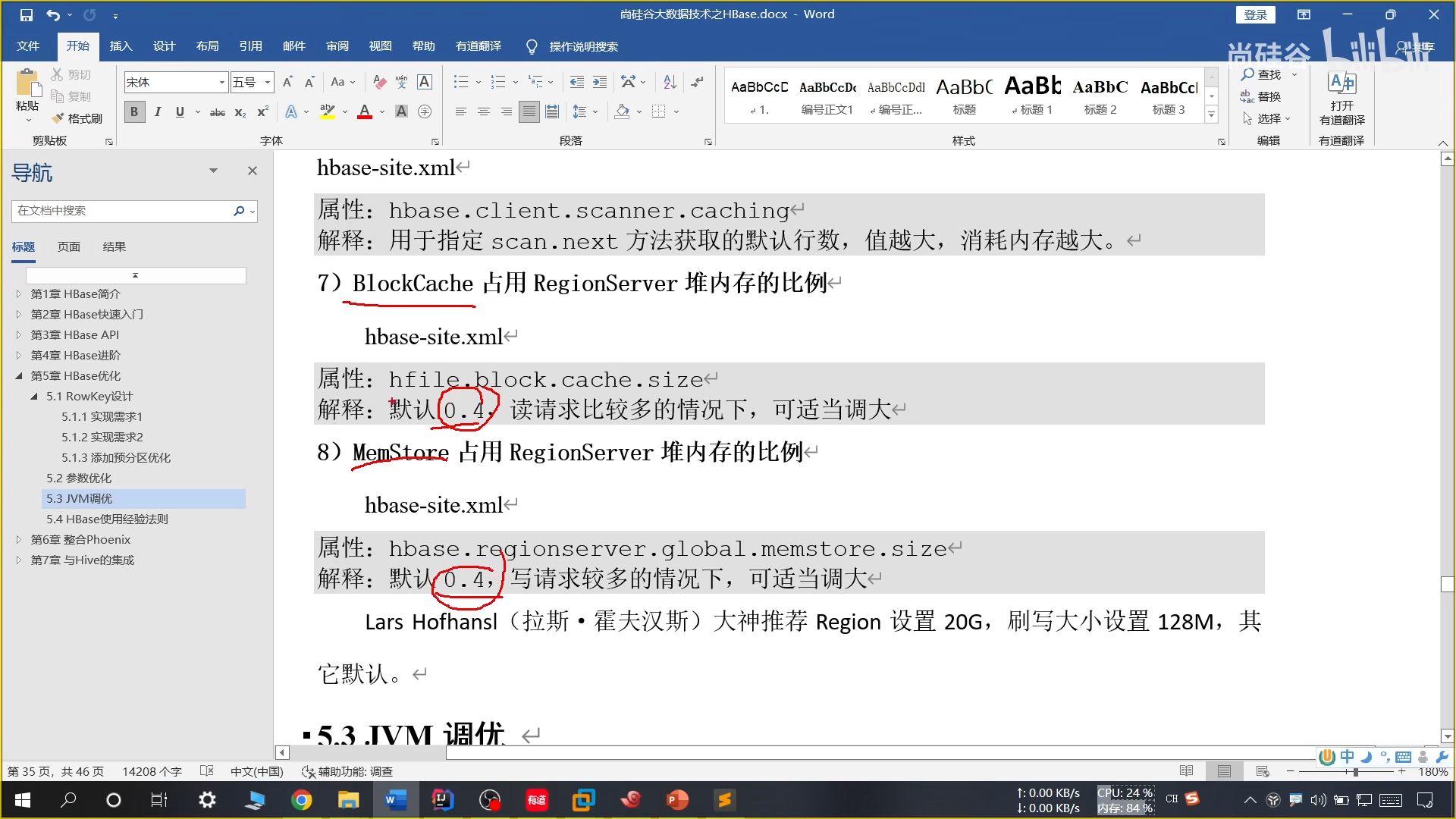
26、参数优化

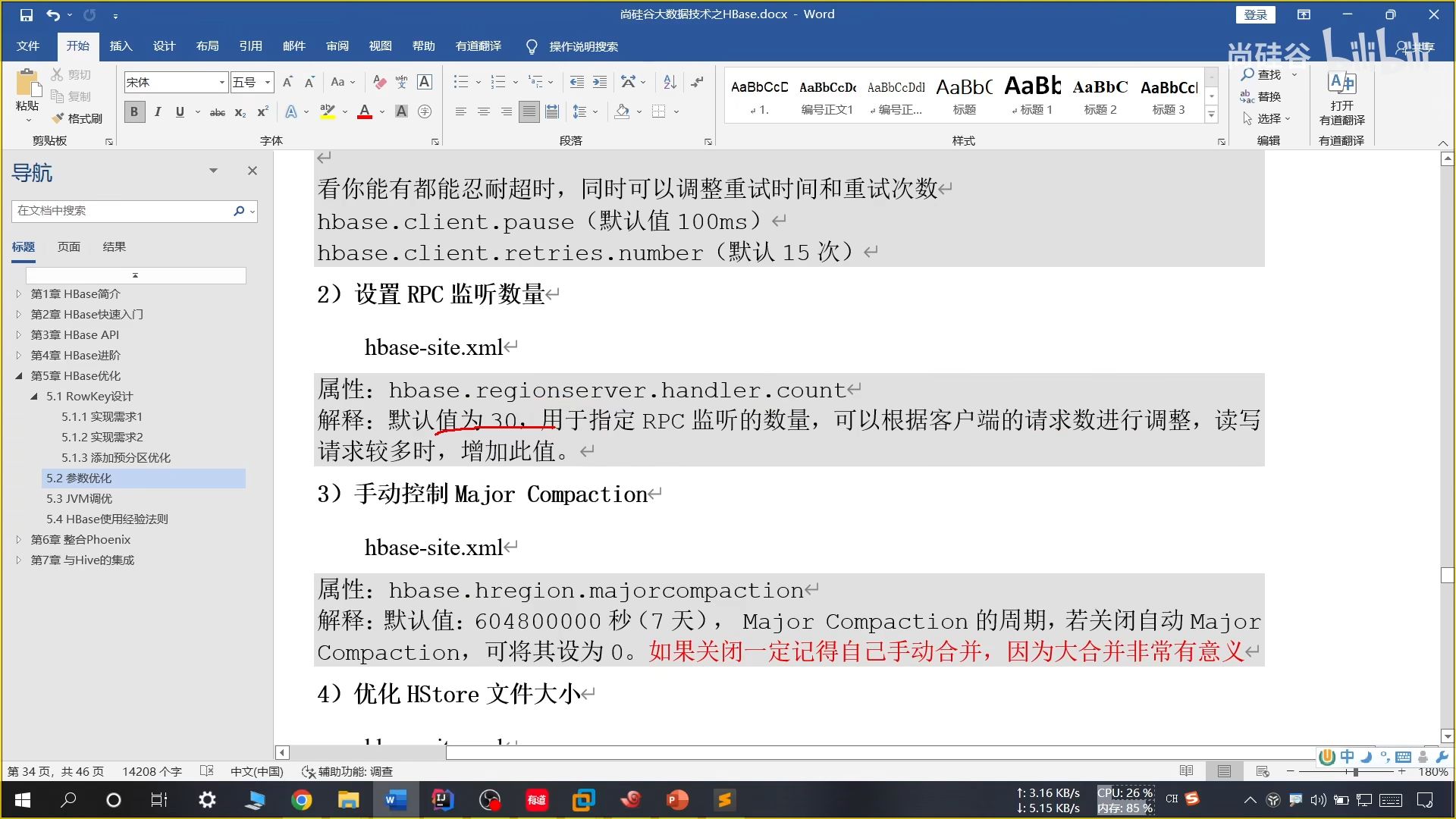
27、HBase 使用经验法则

由于在 HBase 中采用 KV 键值对的方式存储数据,因此需要将列族名称写的尽可能简便一些方便调用
28、Phoenix
(1)基础命令
【1】显示所有表

【2】创建表
直接指定单个列做 RowKey

在 phoenix 中,表名等会自动转换为大写,若要小写,使用双引号,如 "us_population"。
指定多个列为 RowKey

Phoenix 中建表,会在 HBase 中创建一张对应的表。为了减少数据对磁盘空间的占
用,Phoenix 默认会对 HBase 中的列名做编码处理,若不想对列名编码,可在建表语句末尾加上 COLUMN_ENCODED_BYTES = 0;
【3】插入数据

【4】查询记录

【5】删除记录

【6】删除表

【7】退出命令行
29、表的映射
(1)视图映射
该视图是只读的,只能用来做查询,无法对数据进行修改等操作

(2)表映射
表映射会映射 HBase 中已经存在的表,可以修改删除 HBase 中已经存在的数据,删除 Phoenix 中的表,HBase 中被映射的表也会被删除

30、数字类型说明
在 HBase 中添加纯数字值后,在 Phoenix 中视图读取会发生错误,这是由于 HBase 中的数字进行了 16 进制转码,而在 Phoenix 中出现了转换错误


解决方法:
(1)Phoenix 种提供了 unsigned_int,unsigned_long 等无符号类型,其对数字的编码解码方式和 HBase 是相同的,如果无需考虑负数,那在 Phoenix 中建表时采用无符号类型是最合适的选择。


(2)使用 Phoenix 自定义函数,将数字类型的最高位符号位反转。不太会用
31、Phoenix 二级索引
(1)全局索引
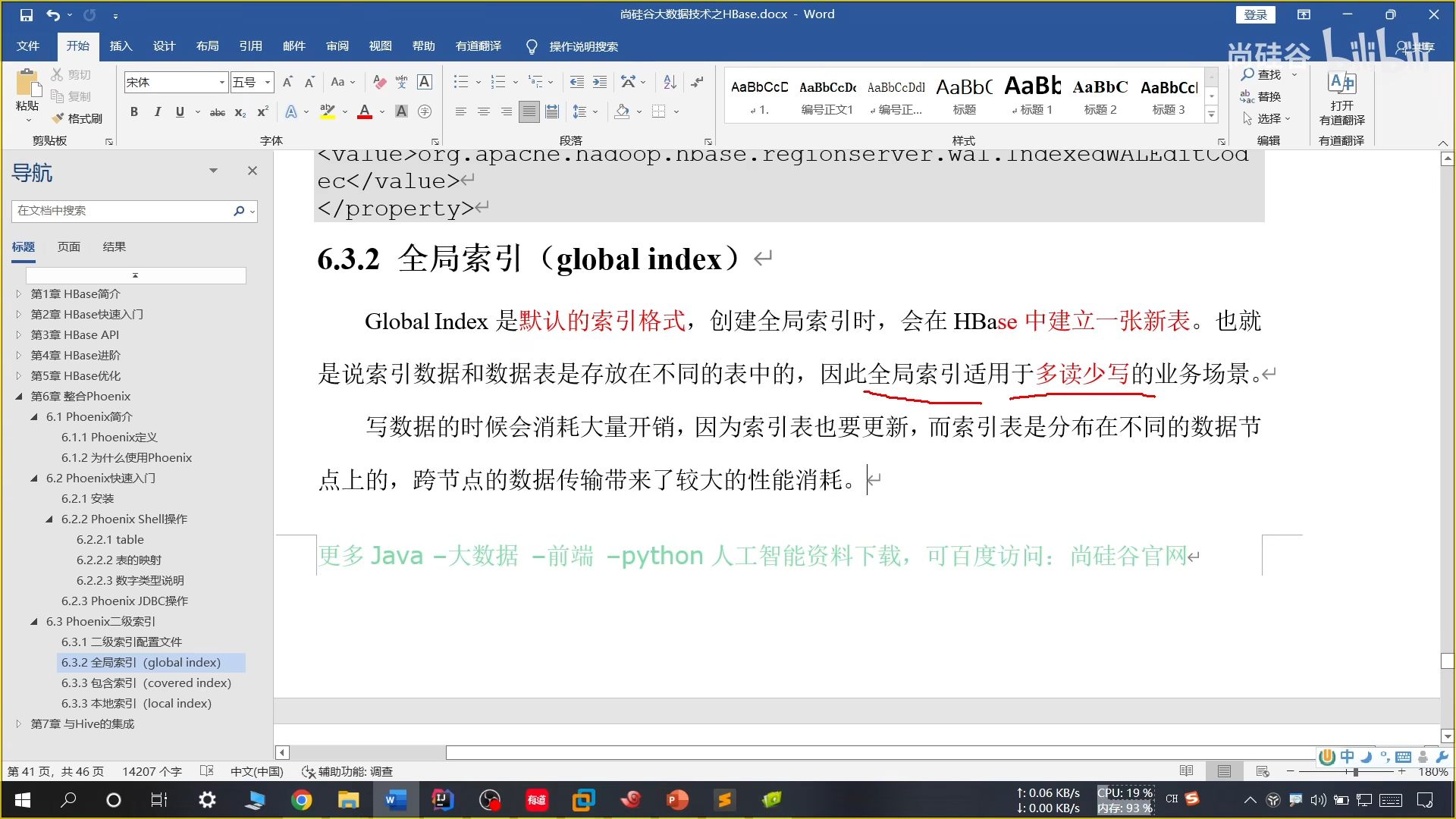

如果想查询的字段不是索引字段,索引表就不会被引用,进而不会带来查询速度的提升。进而需要使用后续两种方法解决
(2)包含索引(全局补充)
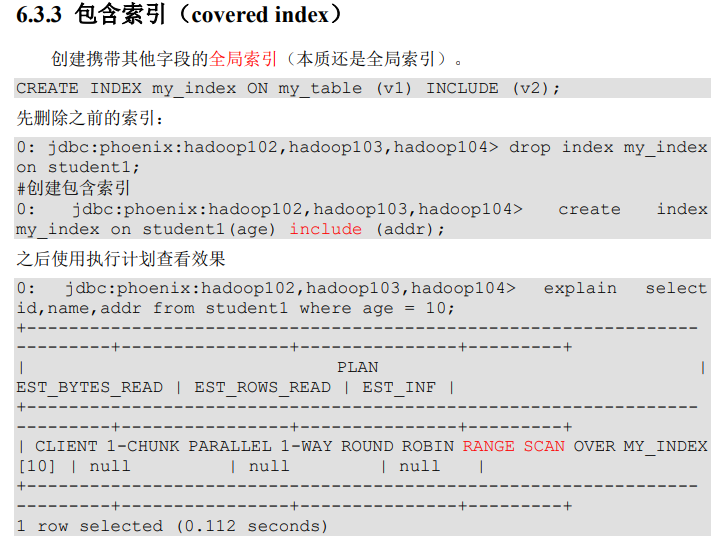
(3)本地索引
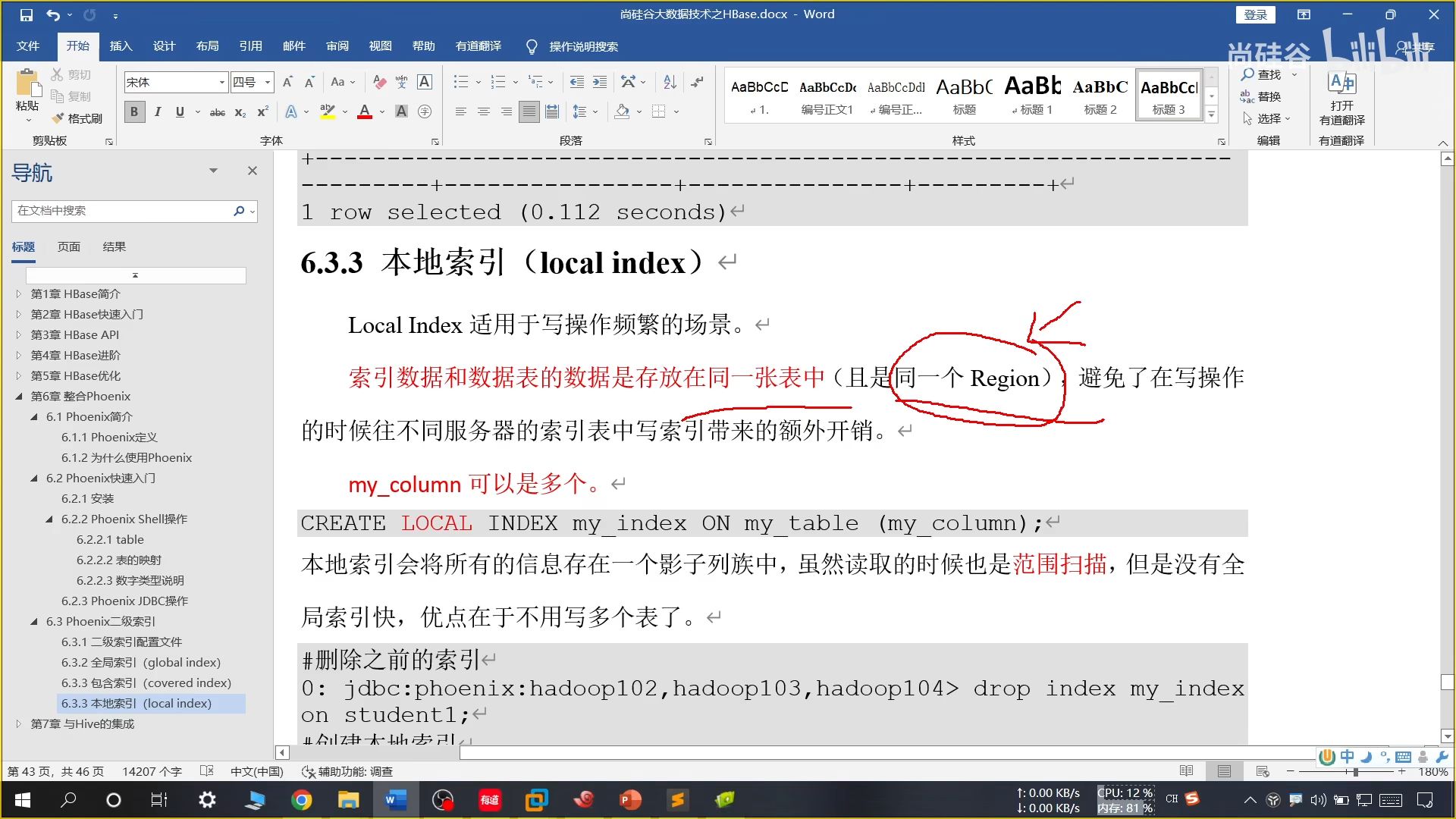
本地索引的索引在原来的表内部,Phoenix 可以看到单 HBase 不可以
32、Hive 集成
在导入数据的时候,由于 load data 无法直接往复杂的表格结构中插入数据,只是单纯把文件上传到表格的路径目录下面,文件格式不会对应。
走 MR 程序的 insert into 可以。因此需要先将数据上传到表中,再使用 insert into 导入
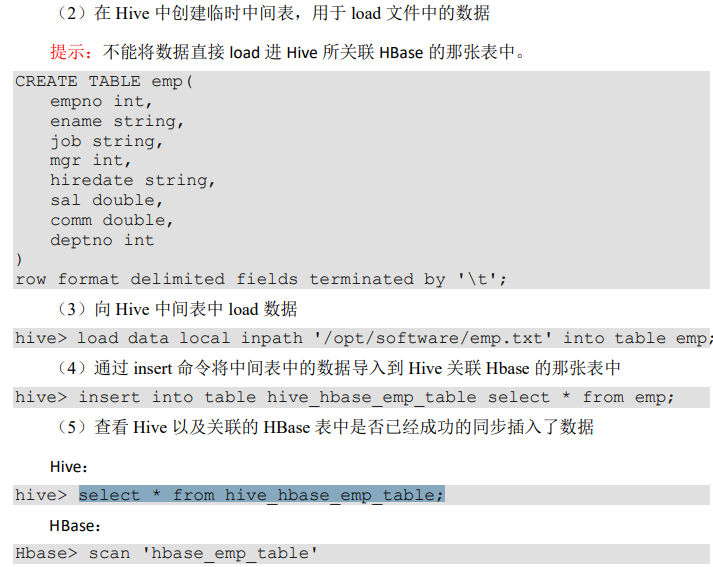
33、实际开发中遇到的情况
在 HBase 中存储了一张表,用 Hive 创建一个外部表来关联 HBase 的这张表来借助 Hive 分析 HBase 这张表中的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号