Flume学习总结
1、Flume 定义
高可用、高可靠、分布式海量日志采集、聚合和传输的系统。流式架构,灵活简单
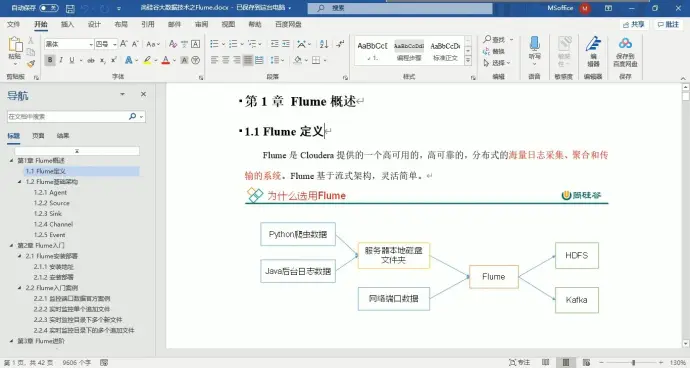
实时读取服务器本地磁盘的数据,将数据写入到 HDFS 中
Kafka 是一个分布式消息中间件,自带存储,提供 push 和 pull 存取数据功能。它专注于高效地传输大规模数据流, 并提供了高度可扩展的消息队列和流处理能力。因此,Kafka 适合做日志缓存。
2、kafka 和 flume 的区别
(1)flume 在传输过程中不会对数据进行缓存,而kafka在传输过程中会用内存池对数据进行缓存
(2)flume 的传输方式是通道传输,kafka的传输方式是订阅/消费
(3)flume 更偏向于数据的采集,而 kafka 更偏向于数据的缓存
(4)flume 传输消息的基本单位叫 event(事务);kafka 中消息在内存池中以一个批次的消息集存储,并以requst(请求)的方式发送给消费者
(5)flume 常用于进行数据以及日志的采集,适用于小规模的数据传输以及 hadoop 的日志采集;而 kafka 常用于日志的缓存,适用于大规模的数据传输
3、基础架构
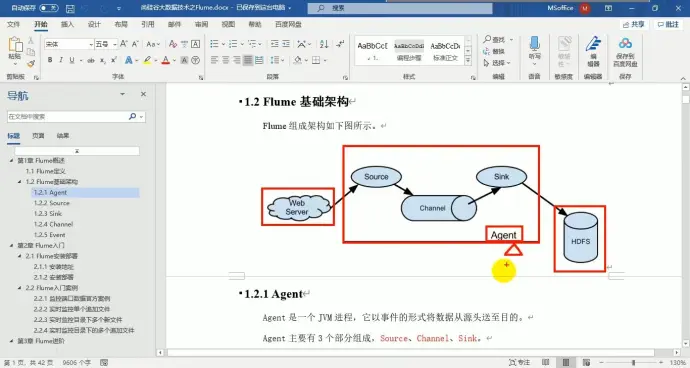
(1)Agent
【1】source : 采集数据 主要包括 avro(串联用)、exec、spooldir、taildir、netcat(监控端口流量)
Exec source 适合于动态监控一个实时追加的文件,不能实现断点续传;
Spooldir Source 监控一个目录,会上传当前目录中所有未被忽视的文件,适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步;
Taildir Source 适合用于监听多个实时追加的文件,并且能够实现断点续传。但如果有更名操作会导致重复上传
netcat : 适合于监控端口流量
【2】channel : 缓冲作用,主要包括 memeory channel(内存队列) 和 file channel(磁盘队列)
memeory channel :速度快但可能丢失数据
file channel: 速度慢但是不会再程序关闭或宕机时丢失数据
【3】sink : 轮询 channel 中的事件并批量移除它们,并将这些时间批量写入到存储或索引系统,或发送到另一个 agent,主要组件有 hdfs、logger、avro、file 等
(2)event
传输内容的基本单元就是事件,在 source 端封装,channel 传输,sink 解析。
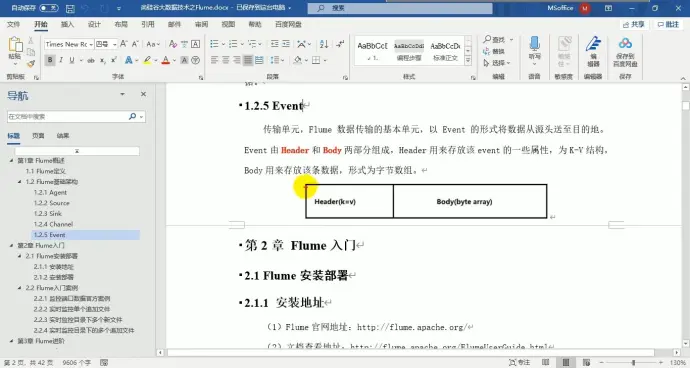
由 header 和 body 两部分组成,header 用于存储 event 的一些属性,为 K-V 结构;body 用类存放该条数据,形式为字节数组
4、案例一:官方案例监控端口
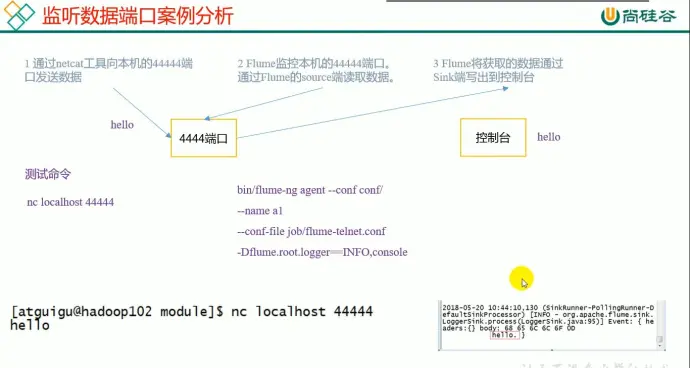
配置信息
注意:对于所有与时间相关的转义序列,Event Header 中必须存在以 “timestamp” 的 key(除非 hdfs.useLocalTimeStamp 设置为 true,此方法会使用 TimestampInterceptor 自 动添加 timestamp)。
a3.sinks.k3.hdfs.useLocalTimeStamp = true

【1】单台 flume 上起多个 agent 需要他们的名字都不一样
【2】有些的属性 (r1,k1...)z 在不同的 agent 中可以一样
【3】c1.capacity 存放事务的最大总容量
【4】c1.transactionCapacity 事务的容量
【5】k1.hdfs.round 是否根据时间变化创建新的文件夹来存储文件
【6】k1.hdfs.useLocalTimeStamp 是否使用本地时间戳,必须开启,默认关闭,我们要求根据时间生成目录,若没有回报错
【7】k1.hdfs.rollCount 将是否滚动域事件数量挂钩,事件数量够了也会触发滚动
【8】事务的容量要比总容量要小
【9】一个 source 可以绑定多个 channel,但是一个 sink 只能绑定一个 channel
【10】该方式不支持断电续传
5、案例二:实时监控目录下多个新文件
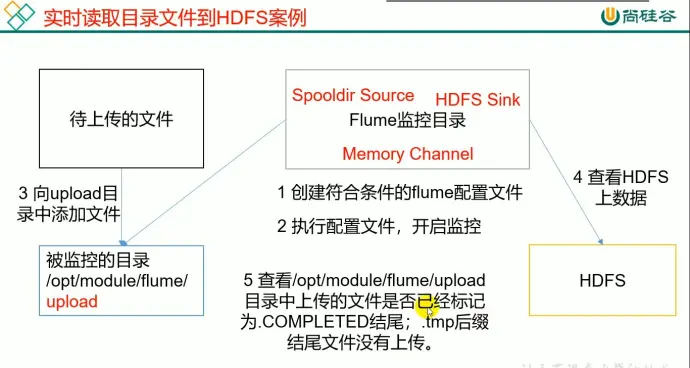
参数设置


附注:
.conf 中忽略的文件格式
.completed 格式
以及中途修改的文件(动态修改无效)
都无法被识别
6、案例三:实时监控目录下多个追加文件
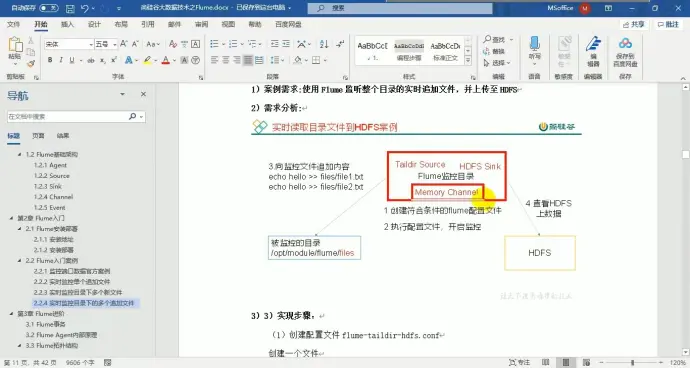
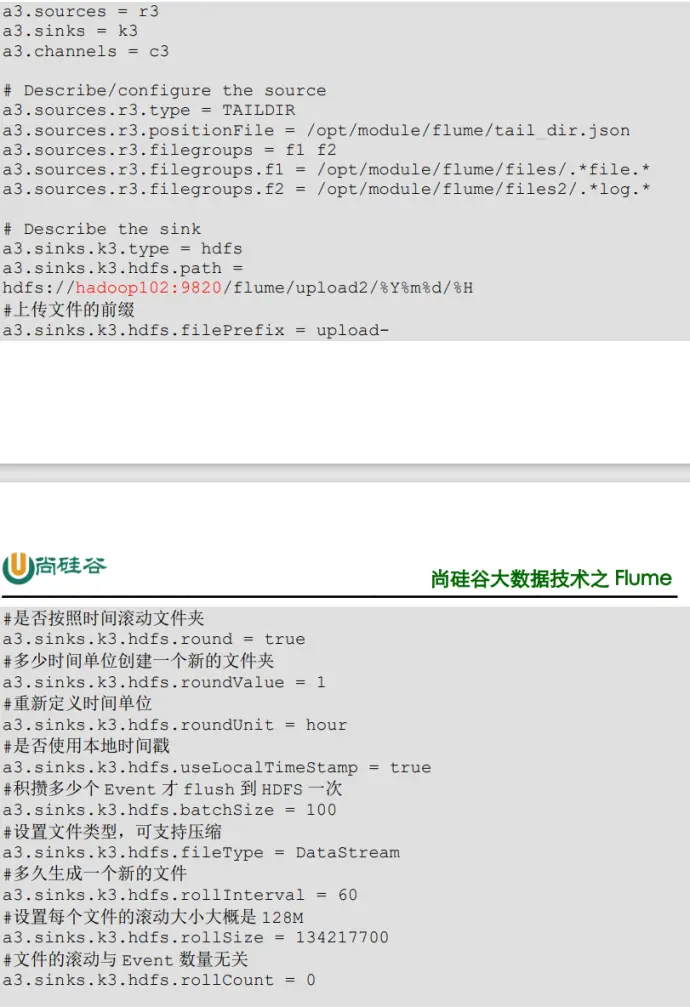


原理:
Taildir Source 维护了一个 json 格式的 position File,其会定期的往 position File
中更新每个文件读取到的最新的位置,因此能够实现断点续传。
附注:
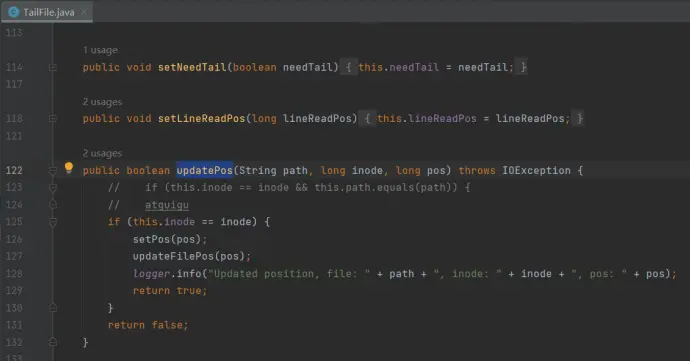
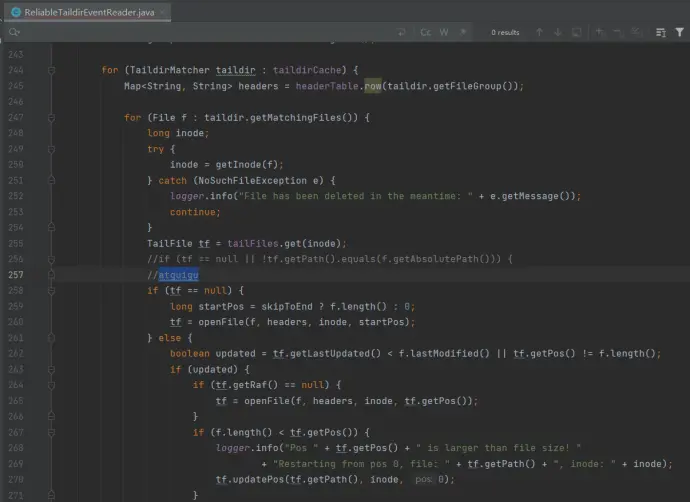
(1)Linux 中储存文件元数据的区域就叫做 inode,每个 inode 都有一个号码,操作系统 用 inode 号码来识别不同的文件,它是一个唯一标识符,Unix/Linux 系统内部不使用文件名,而使用 inode 号码来 识别文件。
(2)在 json 中是根据 inode 和绝对路径共同确认 pos 的,修改它们任意一个都会让文件重新上传
问题:
如果采用 Taildir Source 方式记录 log4j 日志,在日期更迭的时候由于会修改文件名导致文件绝对路径变更进而重复上传,因此需要做出一定的改进:
(1)使用绝对路径写死,不能有更名操作。这种方法若出现任务挂掉第二天才看到,那么这段时间的数据会丢失
(2)找后台要求他们不要按照天为单位更改后缀的方式进行更名,例如 logback,当天生成文件时就自带日期后缀
(3)修改源码,只按照 inode 值进行上传判断
7、flume 事务
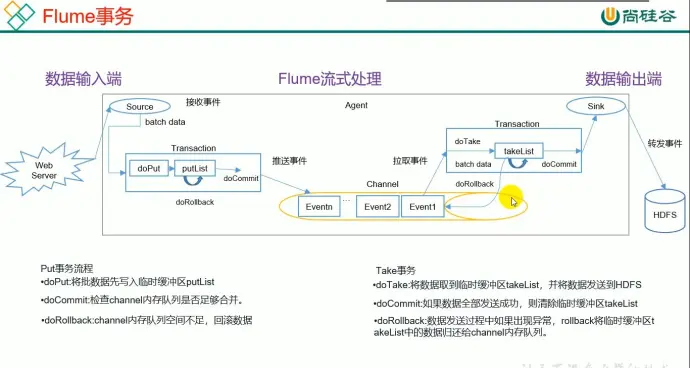
source 推事务到 channel
sink 从 channel 拉取事务
8、Agent 内部原理
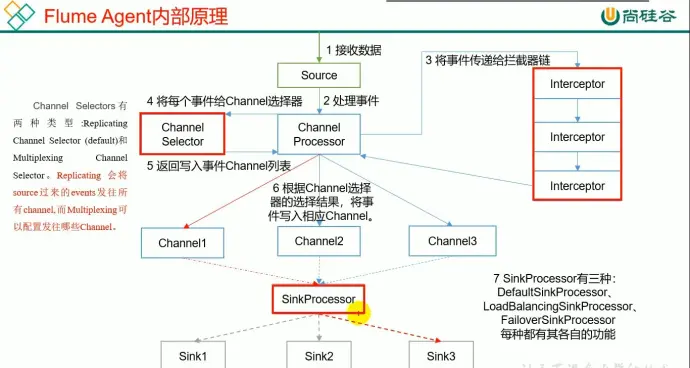
(1)channel selector :
默认采用副本机制 replicating channel selector,即如果存在多个 channel, 会把一份数据发送给多个 channel。
使用多路复用 multiplexing channel 则可以人为指定发送给哪个 channel ,但需要结合拦截器使用,因为要在头部信息添加一些东西,它是根据数据头信息内容进行处理,来决定发给哪个 channel
(2)一个 sink 不能同时拉取多个 channel,但是一个 channel 可以同时给多个 sink(一个 sink 对应一个 channel,但是一个 channel 对应多个 sink)
(3)
defaultsink: 只接收一个 sink
failoversink:故障转移,可以配置优先级,优先发给高优先级 sink,等到该 sink 挂了才会让下一位进行替代工作。存在单点故障问题,高可用。若挂掉的 sink 重启,则当前 sink 也挂掉后会优先选择重启的 sink
loadbalancingsink:负载均衡,以轮询策略挨个看有没有数据
(4)
source -> channel: put 事务
channel -> sink: take 事务
9、flume 拓扑结构
(1)简单串联
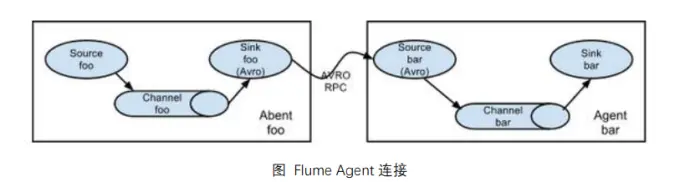
上一层的 sink 和下一层的 source 若需要连接要使用 AVRO 格式,相当于从端口发送再接收数据,使用的是 RPC 通信框架
且他们在连接的时候主机名需要配服务端的名字而不是客户端
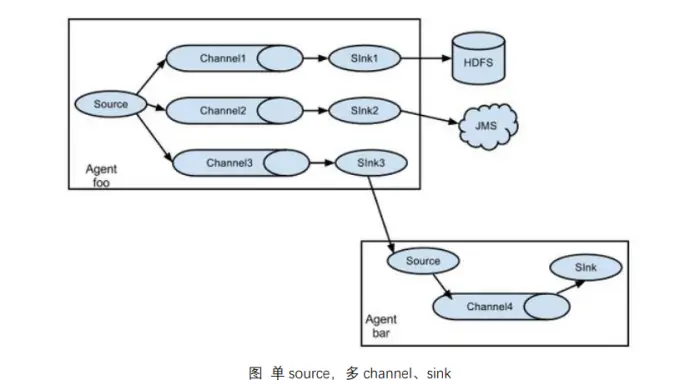
(2)复制和多路复用
(3)负载均衡和故障转移
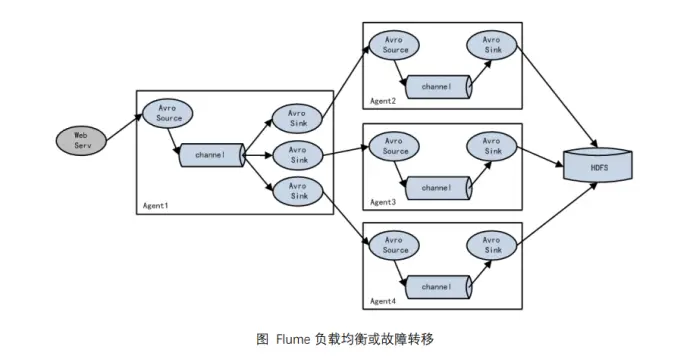
关键看 sink 的策略是什么
对于 HDFS 来说,由于需要写入磁盘因此效率较低,需要多个人来写速度才快一些
(4)聚合
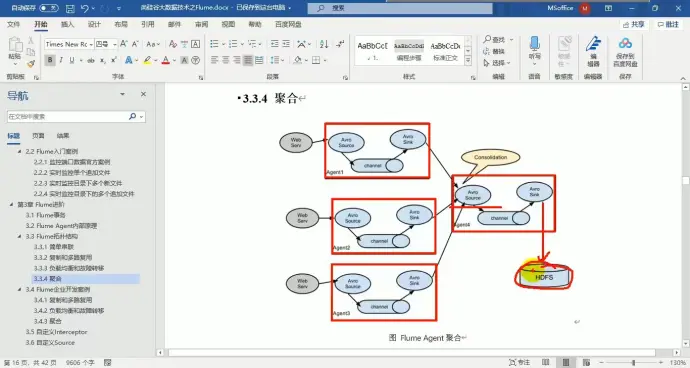
10、企业案例一:复制和多路复用
(1)需求分析
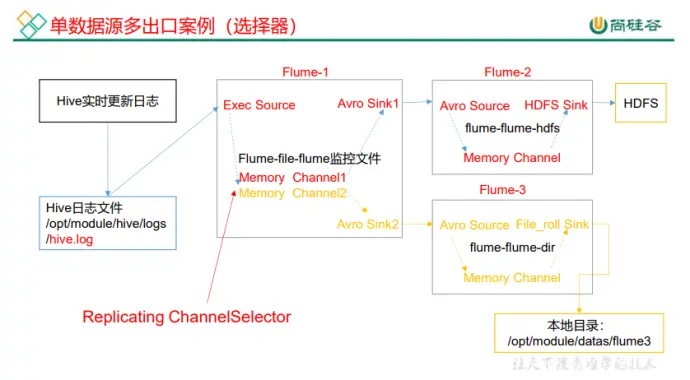
(2)实现
【1】构建 flume-file-flume.conf,用于读取文件传递给 flume
【2】构建 flume-flume-hdfs/conf ,用于 flume 到 hdfs,记得名字要不同,因为要同时启动
【3】构建 flume-flume-dir.conf, 用于 flume 到 dir
, 注意输出本地的目录必须是已经存在的目录,如果不存在是不会创建新的目录的
开启的时候要先开服务端再开客户端,否则会启动失败
11、企业案例二:故障转移
(1)需求分析
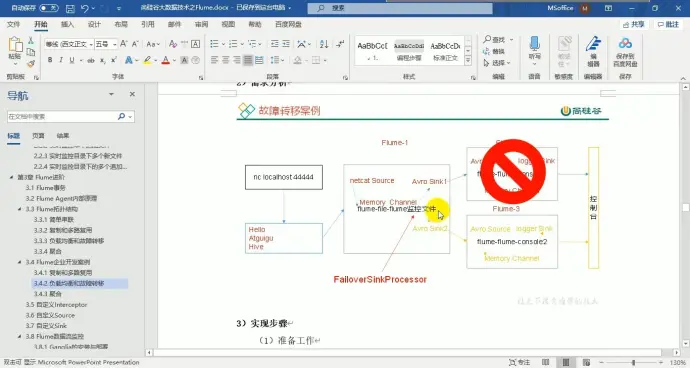
(2)实现
【1】配两个 sink,一个 source,一个 channel 以及故障转移策略组
【2】为了能够打印到控制台,需要开起命令
-Dflume.root.logger=INFO,console
【3】先开服务端,后开客户端
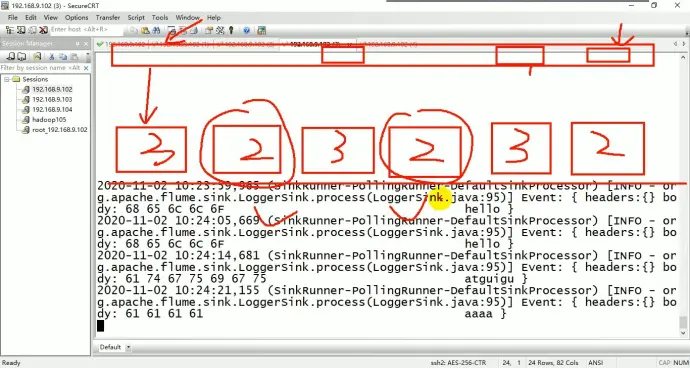
12、企业案例三:负载均衡
和上述案例相似,只需要改客户端即可

如果当前 sink 没有拉到数据,那么接下来一段时间就不用你了,例如拉取失败,坏了,因此需要使用退币算法 processor.backoff,默认是关的。开启后还需要设置一个最大阈值防止算法结果指数级上涨,该指数用于判断是否停止退币
轮询实际上是 sink 在拉取,因此存在 103 拉取后 102 没拉取到数据的情况
13、企业案例四:聚合
(1)案例需求
hadoop102 监控日志, hadoop103 监控端口数据流,最后在 Hadoop104 聚合
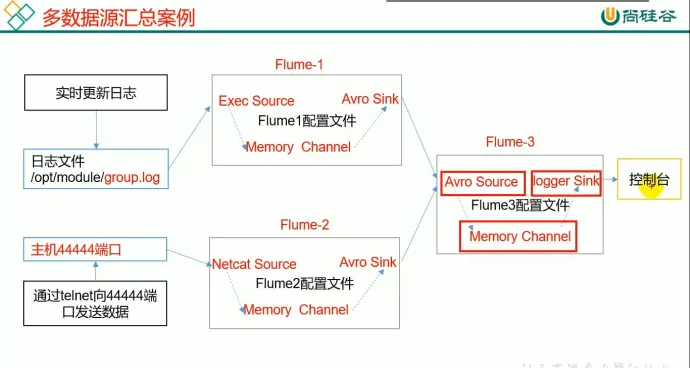
flume1 需要接收日志文件,因此 source 端适合使用 exec 模式,sink 端采用 avro
flume2 需要接收来自端口的数据,因此需要 source 端采用 netcat 模式,sink 端采用 avro
14、自定义 interceptor(拦截器)
(1)案例需求
使用 flume 采集服务器本地日志,需要按照日志类型的不同,将不同种类的日志发往不同的分析系统
(2)需求分析
以端口数据模拟日志,以是否包含 “aiguigu” 模拟不同类型的日志,自定义拦截器区分数据中是否包含“atguigu”,以其分别发往不同的分析系统
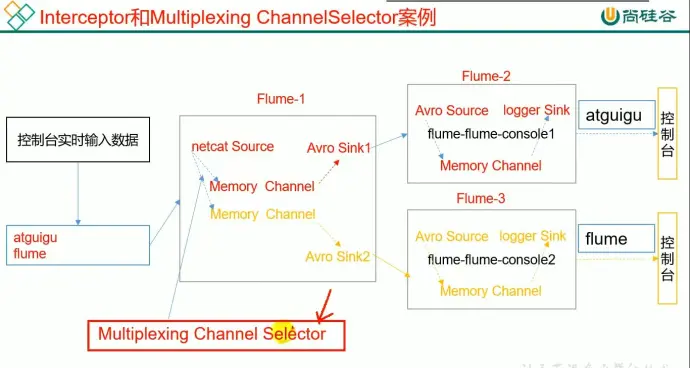
(3)实现

在实现过程中需要注意几个点
【1】
r1.interceptors.i1.type 用于设置拦截器的类型
r1.selector.type 用于设置选择器的选择类型,这里为了配合自定义拦截选用 mutiplexing
r1.selector.header 用于设置头部信息,需要统一
r1.selector.mapping 设置分类结果类型的指向
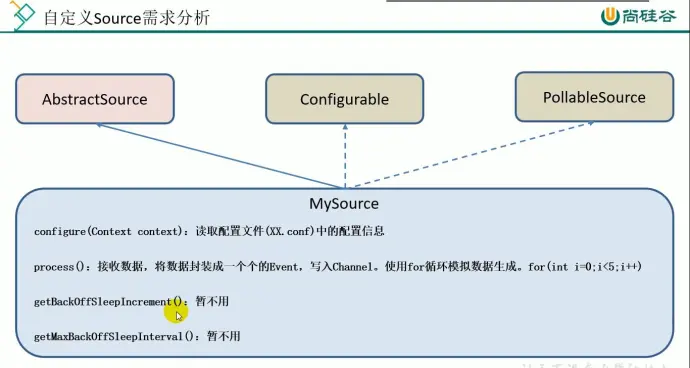
15、自定义 source
(1)介绍
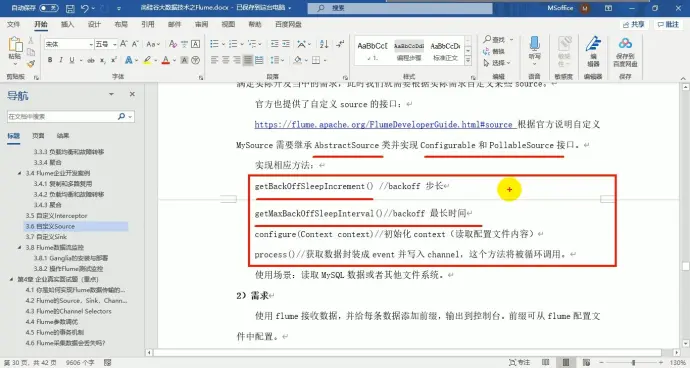
getBackOffSleepIncrement() : backoff 步长,如果 source 没有捕捉到数据就会等待一段时间后再重新捕捉,这段时间会随着等待次数变长,每次增加的时长就是步长
getMacBackOffSleepInterval() : backoff 最长时间 如果超过这个最长等待时间就会停止捕捉数据
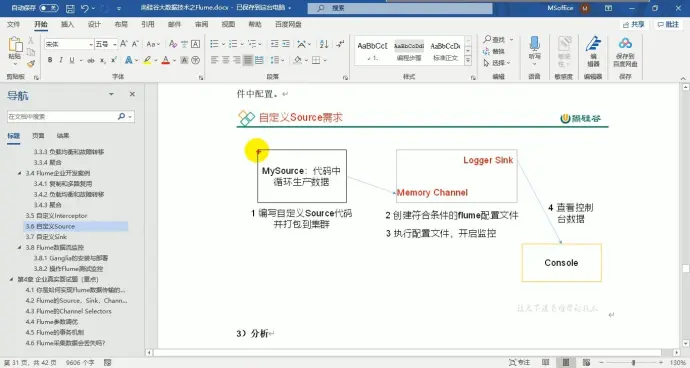
(2)分析
16、自定义 sink
(1) 介绍
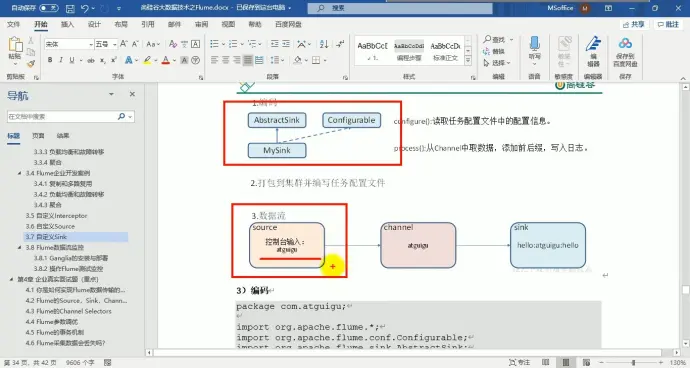
(2)分析
logger
.debug 所有日志看得到,最低
.info 正常使用
.trace 连 error 日志都不打印
17、flume 数据流监控

 浙公网安备 33010602011771号
浙公网安备 33010602011771号