差分隐私(三):谷歌RAPPOR算法
动机
1、运营商需要分析用户数据
(1)用于维护平台性能与分析报错(2)为用户服务提供安全保障
2、收集用户数据会带来的困境
(1)收集用户数据会损害用户隐私(2)不收集会难以改进服务
3、当时拥有的方法不尽人意
(1)降低收集的数据信息粒度(2)一定时间后强制删除收集数据
提供的隐私保护程度有限
实现细节
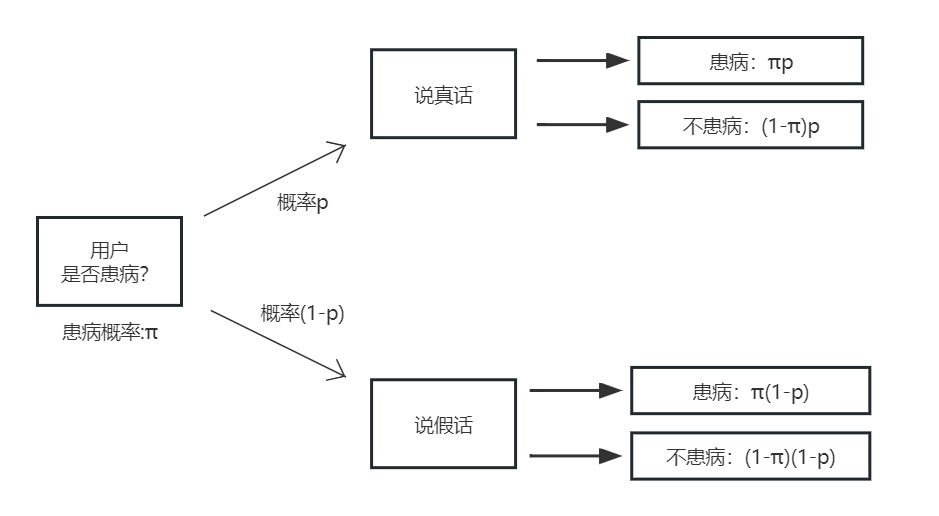
1、随机响应技术
随机响应技术是一种满足差分隐私要求的频数估计算法,它的关键在于提供了一个合理的否认机制,通过该否认机制,可以模糊用户对问题的结果响应,从而实现在保护用户隐私的情况下进行频数统计的目的。
2、RAPPOR算法客户端流程
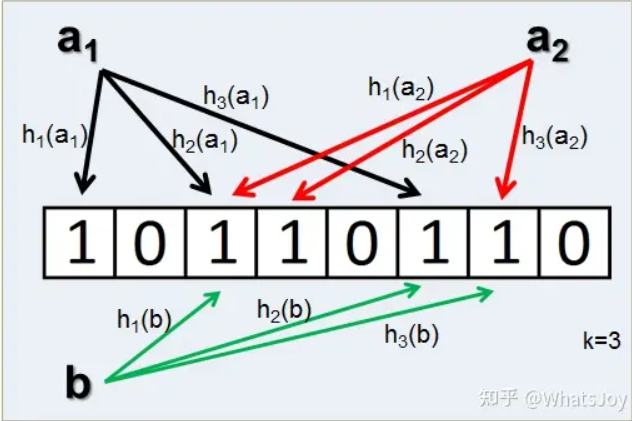
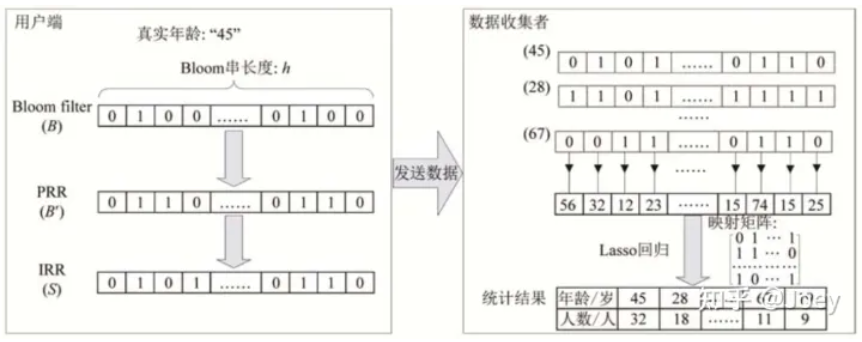
(1)使用布隆过滤器将输入(真值) v 映射成一个长度为k(例:256)的二值向量B
【1】散列函数hash(a):一种映射函数,可以将任意长度的明文信息映射到定长向量或数组中。
【2】布隆过滤器:一种高效查询信息的数据结构
当一个输入值输入布隆布隆器时,会通过K个散列函数将这个输入数据映射成向量中的K个点,并把它们置为1。检索时,只要查看这些点是不是都是1就有很大概率知道集合中是否存在该元素。
(2)以一定概率f更改二值向量B中每个位的值,得到 B’ , f 为用户可控的参数,代表隐私保护程度,该过程被称为永久随机响应,B‘ 会永久存储于客户端中

(3)初始化全为0的,长度为k的二值向量S,按以下概率赋值,该过程被称为临时随机响应,得到的结果被称作报告S上传给服务器,另外还需上传向量长度 k ,参数 f ,以及概率 p 和 q 。
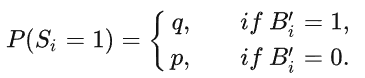
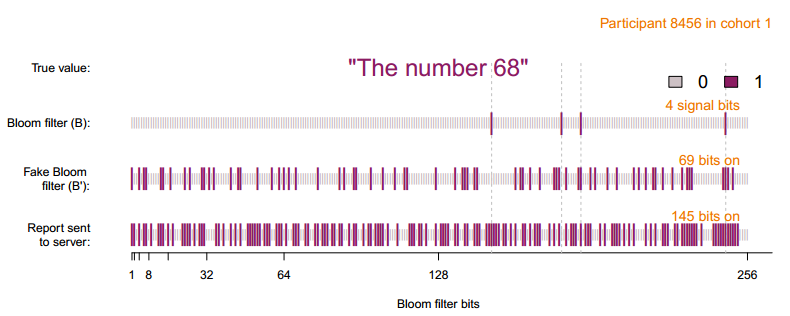
3、RAPPOR算法服务端流程
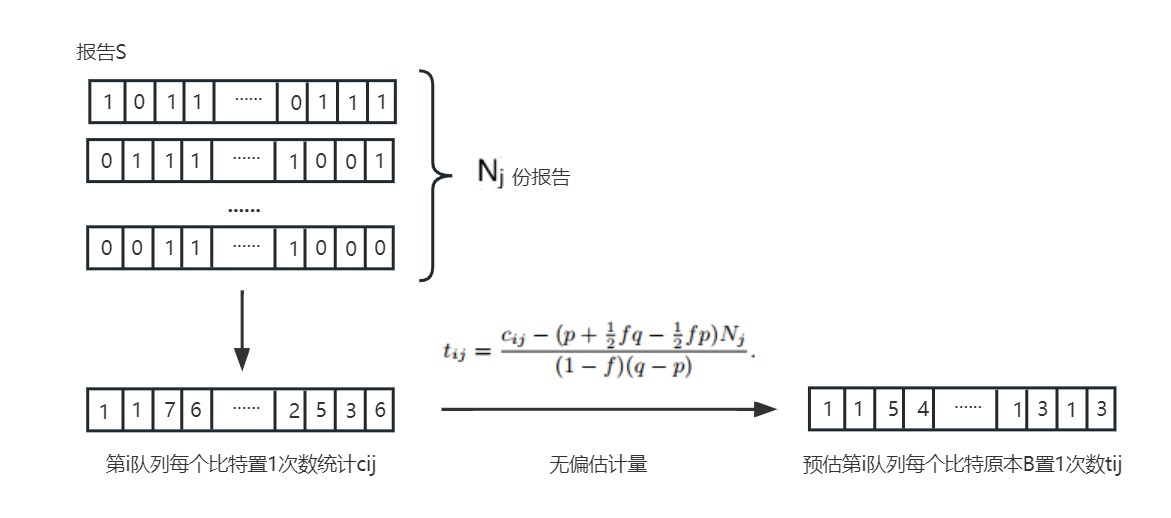
(1)统计该i队列中每个比特的置1次数,记作 cij
(2)根据统计出的次数cij预估原本向量B中实际的置1次数tij,记作向量 y(k维向量)
(3)构造一个大小为 m*k 的映射矩阵 x ,其中m代表该队列中真值v的数量。该矩阵是真值v的布隆映射值按行拼接后得到的矩阵。
(4)使用Lasso回归拟合y = ωx + b,系数ω就是每个真值v在该队列中出现的次数。
4、Lasso回归
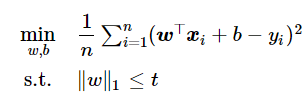
作用:
用于预测特征矩阵X和目标向量y之间的系数ω
组成:
(1)均方误差项:用于计算函数理论值和实际值之间最小误差的函数
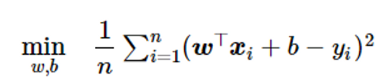
(2)L1正则项:用于防止结果过拟合,提升泛用性

附注:
(1)L2正则项:当使用L2正则项防止过拟合时,该回归被称作岭回归
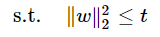
(2)选择Lasso的理由:
平方误差项等值线和L1正则项等值线的交点为系数解
L1正则项等值线在坐标轴上存在不可微的角点,这些角点更容易和平方误差等值线相交
角点在坐标轴上的系数更容易为0(例:(0,b)),因此通过这种方式能够更好进行系数特征的筛选
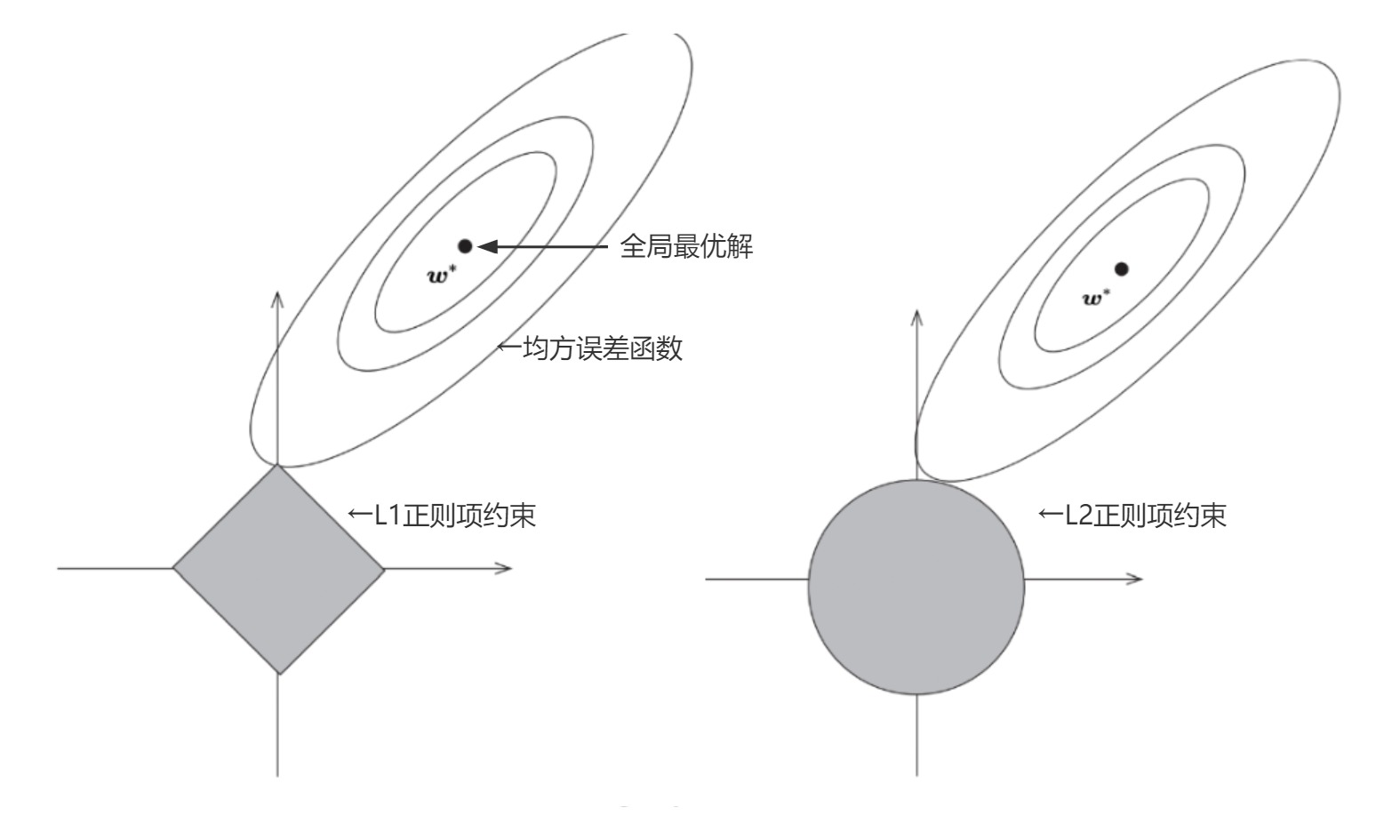
如图所示:
【1】椭圆等高线表示函数,中间的ω*代表函数的全局最优解
【2】灰色的图形代表正则项约束,左边正方形取值区域是LASSO回归约束,右边圆形取值区域是岭回归约束
【3】在没有正则项约束的情况下,ω*是可以被取到的,但添加约束后,ω的取值就只能在灰色图形的区域上了
【4】等高线与约束区域的切点即为ω的取值。在Lasso中,由于正方形的取值区域在坐标轴上有棱角,这就导致等高线的切点更容易在这些棱角上,即在Lasso中ω更容易出现在坐标轴上,进而导致部分权重取零的概率增大【例:(0,b)】,从而更加容易对特征值进行筛选
5、未知字符串应对方法
(1)EM算法(期望最大化)
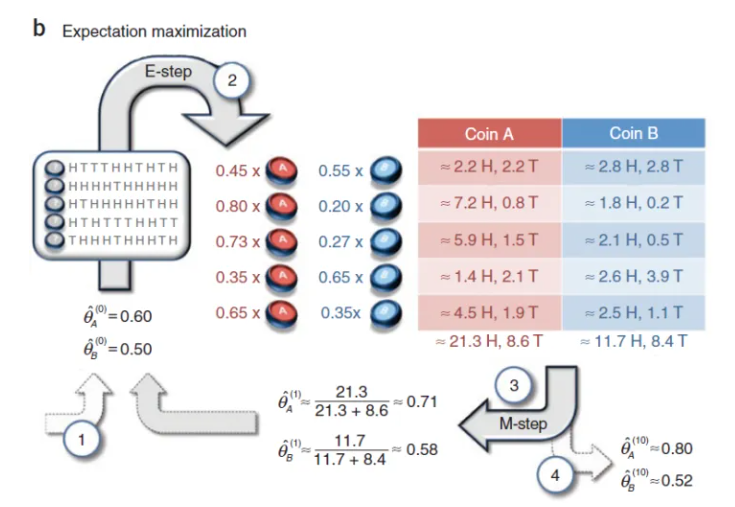
例子:使用两枚硬币A、B进行抛硬币实验,正面朝上的概率不同(θA,θB),H代表正面,每次实验不知使用哪个硬币,求θA和θB
【1】初始化假设分布参数θ(例:θA=0.6)
【2】Expectation 步:使用步骤一中的参数,利用贝叶斯公式计算联合分布的条件概率期望(例:使用A硬币的概率是0.45)
【3】Maximization步:根据【2】中的得到的分布选择概率进行极大似然估计,得到新的分布参数θA’,θB‘(例:θA’=0.71)。其中极大似然估计是一种参数估计的方法
【4】判断分布参数的变化值是否小于一个常数ε,若是则认为收敛,输出分布参数。(例:θA=0.8)
(2)RAPPOR中的应用
在RAPPOR算法中,会通过使用EM算法构造出可能的字符串并放入候选集C中作为一个新的“字典”进行更加严格的训练估计,从而筛选统计出新的字典中没有的词条
具体流程如下:
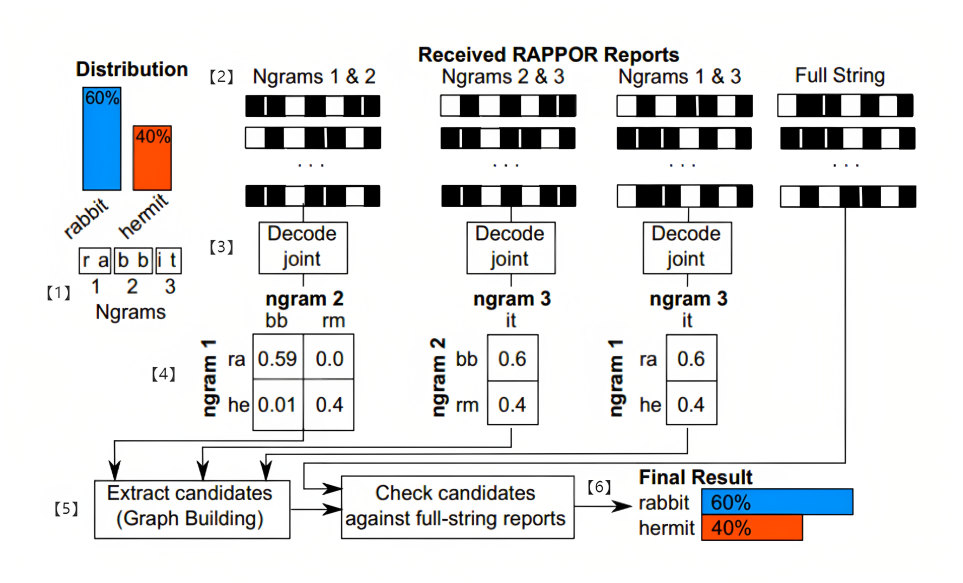
【1】构建n-gram字典:
n-gram(x,i):在字符串x中,从第 i 个字符开始的,长度为n的字符串片段。
构建一个字段长度为n字符串片段,原则上允许这些字段出现重叠,但不允许相同。图中示例为了便于演示因此采用了相邻可整除的字符串片段。
【2】根据n-gram字典中生成的所有字符串片段,依照采样位置将它们拆分成一个个互斥组用于比较。例子中采用了相邻整除的片段因此分组相对简单。
【3】根据每个位置的分组,利用EM算法进行分布概率的计算:
步骤一:初始化两个片段X和Y的联合分布pij

步骤二:计算基于pij生成的联合分布条件概率期望Pxy

步骤三:使用极大似然估计更新联合分布直至收敛
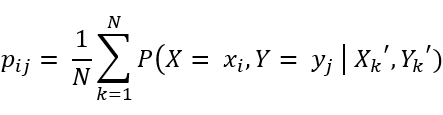
【4】将【3】中结果带入各组进行分析并根据一个阈值进行筛选,得到候选字符串片段
【5】构建一个由候选字符串片段构成的图,分析全连通子图来筛选哪些构成的字符串能进入候选集C
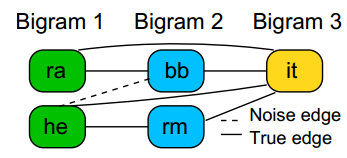
【6】使用完整字符串报告集合X‘和候选集C进行RAPPOR算法训练,但使用的隐私预算为ε/3,这么做的目的是为了筛除实际上并不存在的字符串
应用案例
1、STT-MRAM在物联网数据隐私保护系统中的应用
(1)背景说明
在用户操作物联网设备(例如车辆电子控制单元)时会产生一系列行为数据,这些数据对一些组织(例如汽车公司和计算机公司)具有很高的价值。
但使用这些数据势必会造成隐私问题,因此需要在和相关组织共享这些数据前对其进行隐私保护,但仍然需要保留它们的统计属性,从而便于分析。
(2)设备介绍
自旋力矩转移磁性随机存取存储器(STT-MRAM):一种具有高耐久性和长续航性的存储器。它可以用作于嵌入式的非易失性存储。

带有STT-MRAM控制板的物联网设备
(3)RAPPOR算法的应用
在STT-MRAM的控制电路中,通过使用RAPPOR算法来对客户端数据进行统计,同时也满足了差分隐私的保护。
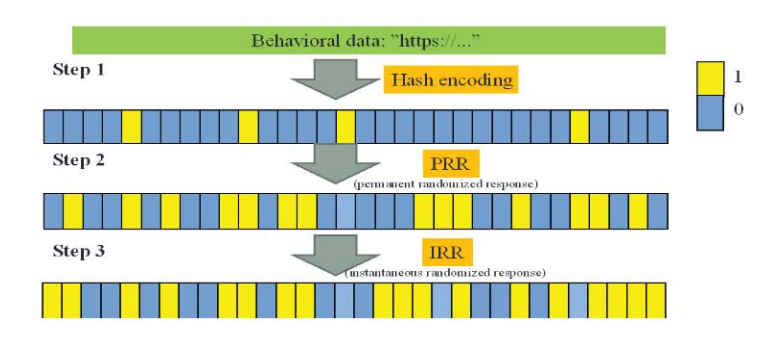
(4)示例
SPI协议:一种同步串行传输规范,至少拥有四根线:
【1】/SS : 片选线,用于芯片选择
【2】SCK:同步时钟信号,保证相关的电子组件得以同步运作
【3】MOSI: 主设备数据输出
【4】MISO: 主设备数据输入
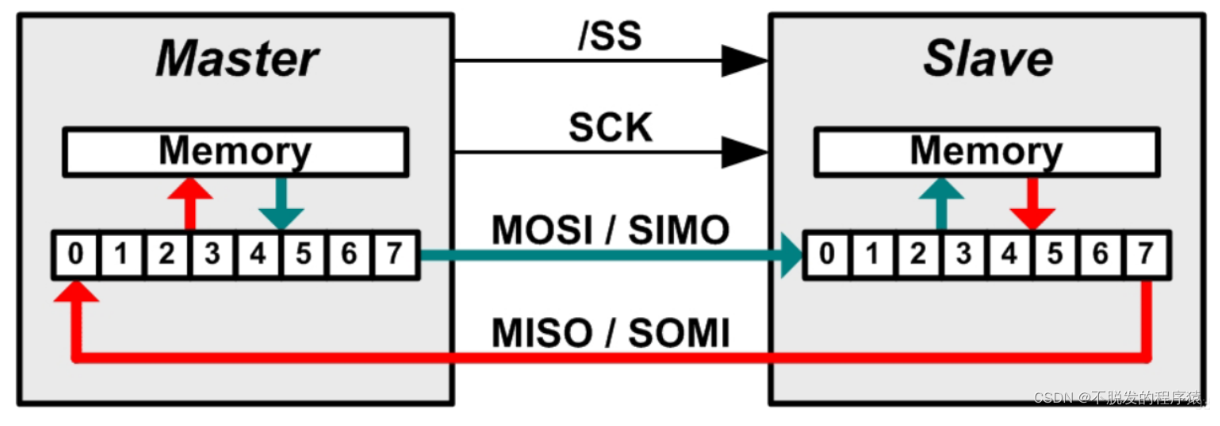
如图所示:
信道 1 为同步时钟信号SCK
信道 2 为MOSI主设备输出
信道 3 为MISO主设备输入
信道 4 为/SS,此处没有使用
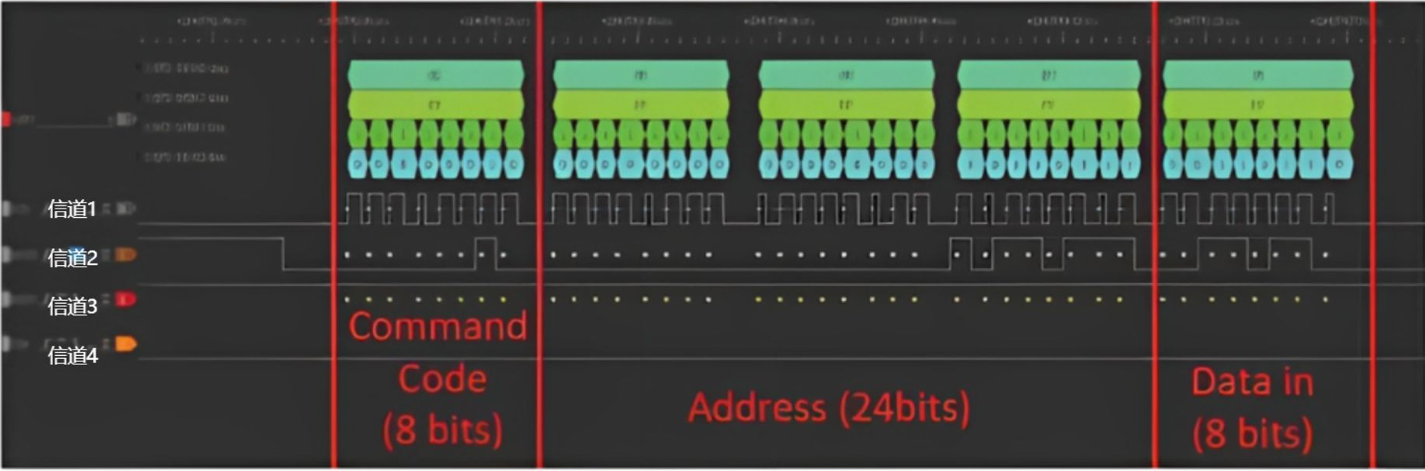 写入数据
写入数据
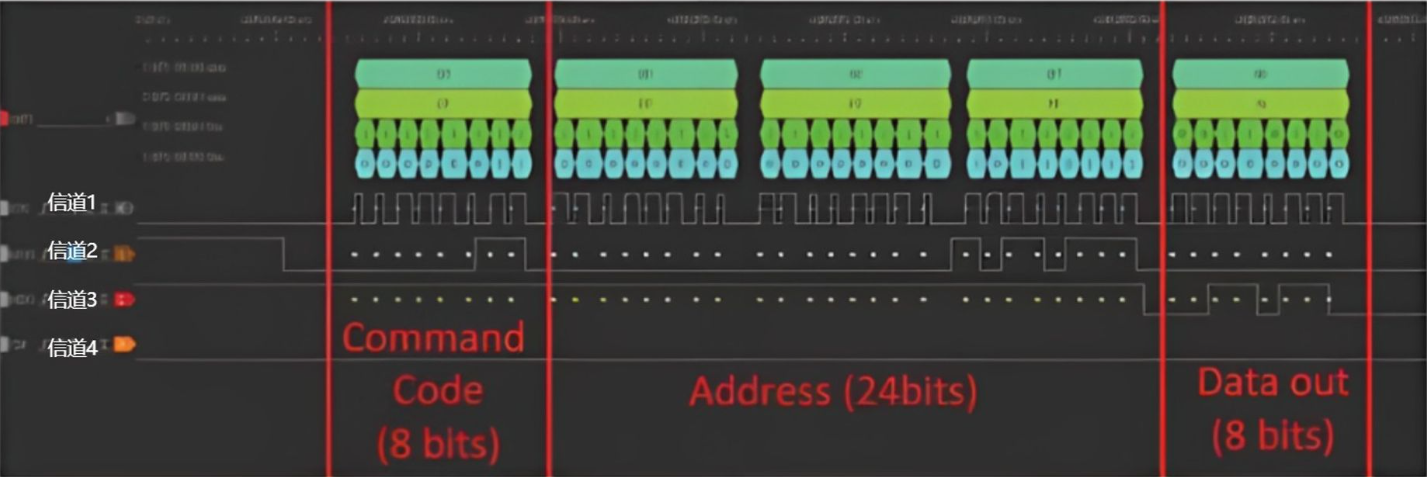 读取数据
读取数据
算法评价
优点:
1、隐私保护:该算法通过使用随机响应技术实现了差分隐私,为用户的个人隐私数据提供了保护。
2、聚合性:该算法在保证用户数据隐私的同时实现了对用户数据信息的统计,且能够保证一定的准确率。
3、可扩展性:该算法在运算过程中使用了字典,可以方便地进行字段添加,适用于大规模的数据收集分析。
4、易于实现性:由于客户端算法所使用的的方法相对简单,因此易于在各种设备上进行部署使用。
缺点:
1、信息损失:由于RAPPOR算法对用户数据实行了随机化处理,因此无法避免地会引入一些信息损失。在EM算法中,受限于字段长度也会导致一些较长的字段会出现不全的情况,进而导致结果的准确性下降。
2、联合估计解码成本过高:尽管大部分RAPPOR算法过程可以并行化执行,但是在EM算法中的联合估计解码中,每次迭代都是基于前一次迭代以及整个数据集。当用户量过大时会导致内存和算力消耗过大。
3、缺乏参数和隐私预算最优选择方法:在目前的工作中,该算法还没有找到一个高效选择参数和隐私预算的最优方法,因此难以最大化估计算法的准确性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号