Hadoop学习总结 (四) —— MAPREDUCE(1)
1、MapReduce的定义
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
2、优缺点
优点:
(1)MapReduce易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
(2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
(3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
(4)适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点:
1)不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3)不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
3、核心思想
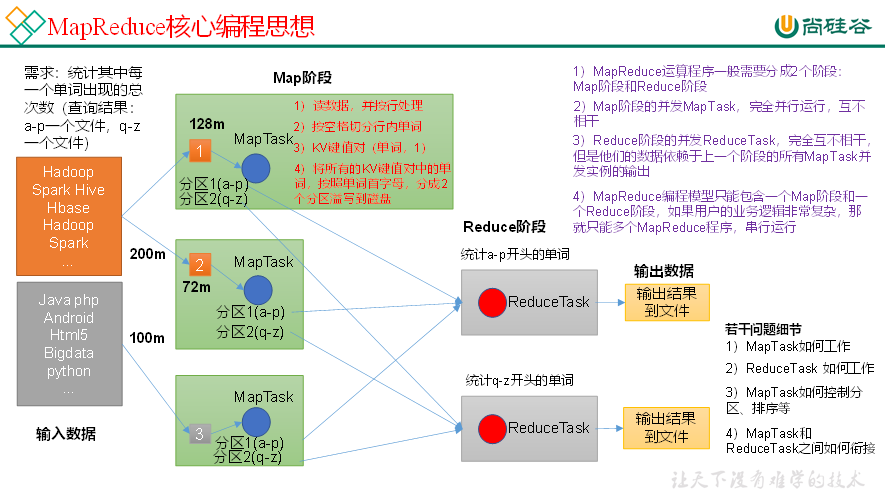
(1)分布式的运算程序往往需要分成至少2个阶段。
(2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
(3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
(4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
4、MapReduce进程
一个完整的MapReduce程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责Map阶段的整个数据处理流程。
(3)ReduceTask:负责Reduce阶段的整个数据处理流程。
5、Hadop常用数据类型
|
Java类型 |
Hadoop Writable类型 |
|
Boolean |
BooleanWritable |
|
Byte |
ByteWritable |
|
Int |
IntWritable |
|
Float |
FloatWritable |
|
Long |
LongWritable |
|
Double |
DoubleWritable |
|
String |
Text |
|
Map |
MapWritable |
|
Array |
ArrayWritable |
|
Null |
NullWritable |
6、MapReduce编程规范


7、编程注意事项
(1)编写前
注意SDK、JDK、JAR等的版本对应问题,过高或过低的版本在打包运行的过程中都会遇到问题
SDK——软件开发工具包
SDK(Software Development Kit),软件开发工具包,是一个覆盖范围相当广的名词,可以说辅助开发某一类软件的相关文档、范例和工具的集合都可以叫做 SDK。
SDK是一系列文件的集合,他为软件的开发提供一个平台为软件开发使用提供各种API提供便利。
JDK——Java开发工具包
JDK(Java Development Kit)Java开发工具包,是SUN Microsystems针对Java开发者的产品,JDK已经成为使用最广泛的JAVA SDK 。
可以认为JDK是SDK的一个子集 。
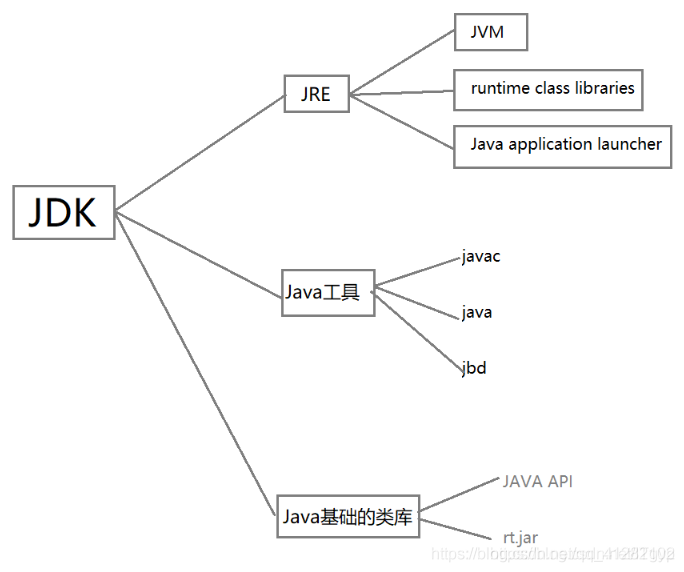
JRE - Java运行环境
JRE(Java Runtime Environment),Java运行环境,是运行基于Java语言编写的程序所不可缺少的运行环境。也是通过它,Java的开发者才得以将自己开发的程序发布到用户手中,让用户使用。
-
JRE中包含了Java virtual machine(JVM),runtime class libraries和Java application launcher,这些是运行Java程序的必要组件。
-
与大家熟知的JDK不同,JRE是Java运行环境,并不是一个开发环境,所以没有包含任何开发工具(如编译器和调试器),只是针对于使用Java程序的用户。
JVM
JVM(Java Virtual Mechinal),JAVA虚拟机。
JVM是JRE的一部分,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM有自己完善的硬件架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。
关系图

如果需要调整版本,应设置三个地方
setting->compiler
Project Structer->Module&Project
需要统一版本
最后,需要在Project Structer的SDKs选项中导入Hadoop的bin目录
(2)编写时
Mapper&Reducer
需要对原有的类进行重写,更改输入输出的类型,以及修改操作内容,使用context进行写操作提交参数
Driver驱动类
// 1 获取配置信息以及获取job对象 Configuration conf = new Configuration(); Job job = Job.getInstance(conf); // 2 关联本Driver程序的jar job.setJarByClass(WordCountDriver.class); // 3 关联Mapper和Reducer的jar job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); // 4 设置Mapper输出的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5 设置最终输出kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6 设置输入和输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 提交job boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1);
(3)编写后
如果需要打包发送到别的系统进行使用,可以进行package打包成jar包
8、Hadoop序列化
(1)什么是序列化
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储到磁盘(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
(2)为什么要序列化
一般来说,“活的”对象只生存在内存里,关机断电就没有了。而且“活的”对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。 然而序列化可以存储“活的”对象,可以将“活的”对象发送到远程计算机。
(3)为什么不用Java的序列化
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输。所以,Hadoop自己开发了一套序列化机制(Writable)。
(4)Hadoop序列化特点:
紧凑 :高效使用存储空间。
快速:读写数据的额外开销小。
互操作:支持多语言的交互
9、自定义Bean对象实现序列化接口
在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
具体实现bean对象序列化步骤如下7步。
(1)必须实现Writable接口
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造
public FlowBean(){ super(); }
(3)重写序列化方法
@Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow);
}
(4)重写反序列化方法
@Override public void readFields(DataInput in) throws IOException { upFlow = in.readLong(); downFlow = in.readLong(); sumFlow = in.readLong();
}
(5)注意反序列化的顺序和序列化的顺序完全一致
(6)要想把结果显示在文件中,需要重写toString(),可用"\t"分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。详见后面排序案例。
@Override public int compareTo(FlowBean o) { // 倒序排列,从大到小 return this.sumFlow > o.getSumFlow() ? -1 : 1; }
10、MapReduce框架原理
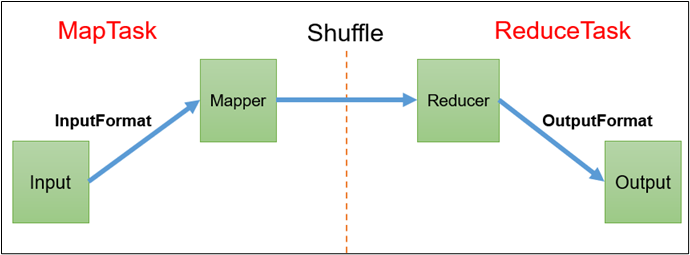
11、InputFormat数据输入
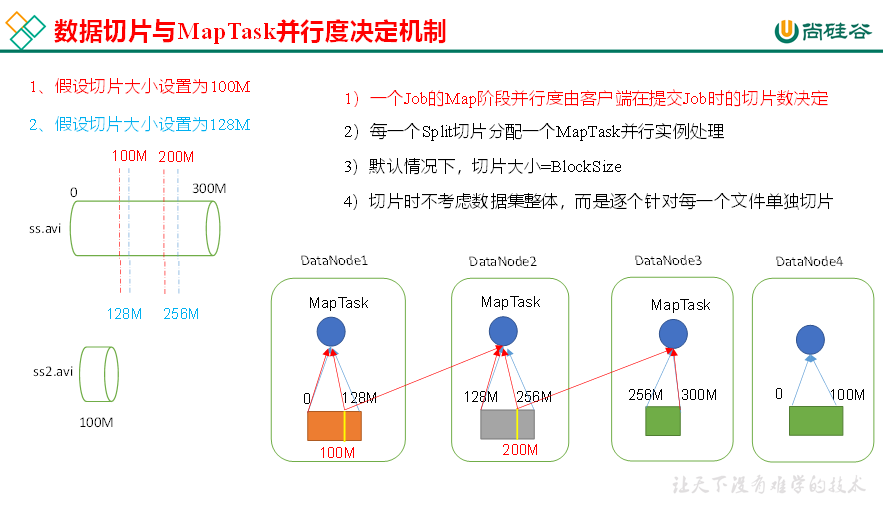
(1)MapTask并行度决定机制
数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。
数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapReduce程序计算输入数据的单位,一个切片会对应启动一个MapTask。
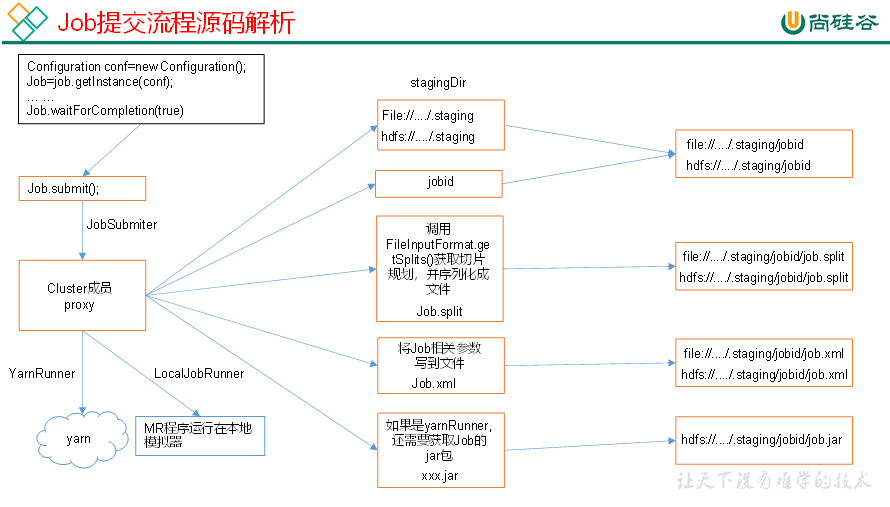
(2)Job提交流程源码
waitForCompletion() submit(); // 1建立连接 connect(); // 1)创建提交Job的代理 new Cluster(getConfiguration()); // 2)判断是本地运行环境还是yarn集群运行环境 initialize(jobTrackAddr, conf); // 2 提交job submitter.submitJobInternal(Job.this, cluster) // 1)创建给集群提交数据的Stag路径 Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); // 2)获取jobid ,并创建Job路径 JobID jobId = submitClient.getNewJobID(); // 3)拷贝jar包到集群 copyAndConfigureFiles(job, submitJobDir); rUploader.uploadFiles(job, jobSubmitDir); // 4)计算切片,生成切片规划文件 writeSplits(job, submitJobDir); maps = writeNewSplits(job, jobSubmitDir); input.getSplits(job); // 5)向Stag路径写XML配置文件 writeConf(conf, submitJobFile); conf.writeXml(out); // 6)提交Job,返回提交状态 status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
(3)FileInputFormat切片源码解析(input.getSplits(job))



(4)TextInoutFormat
1)FileInputFormat实现类12、MapReduce工作流程
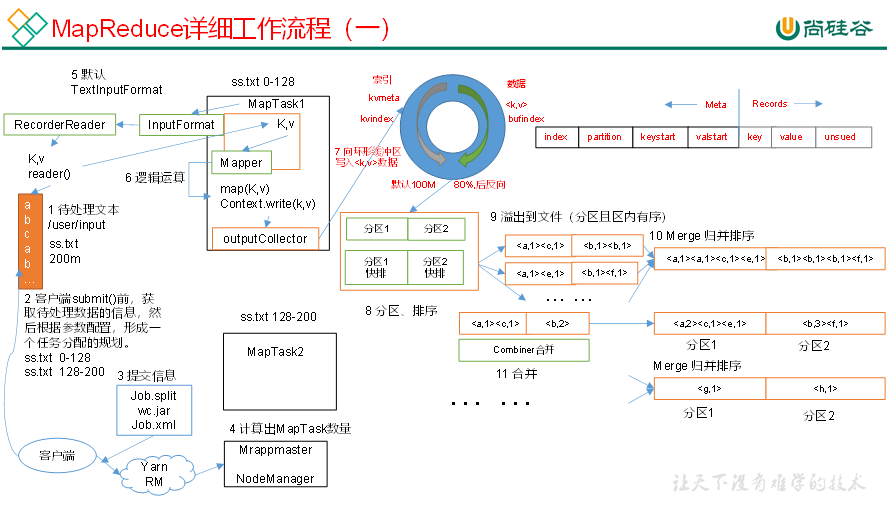
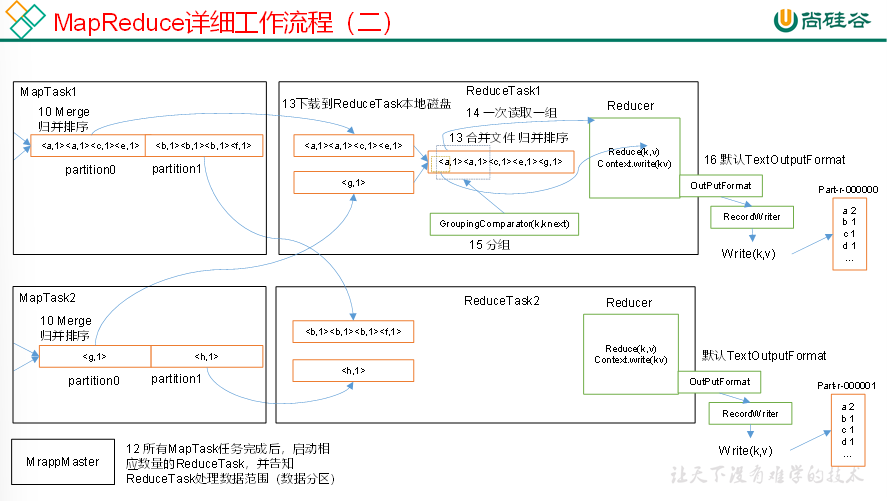
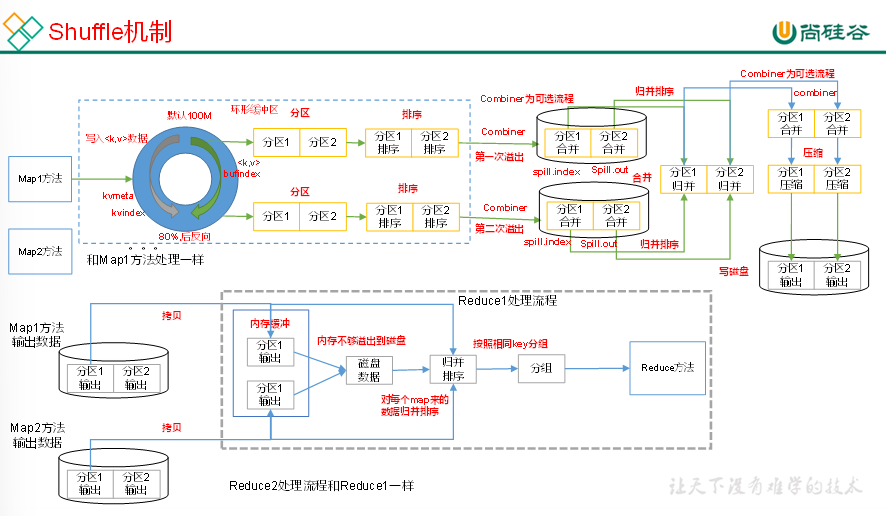
上面的流程是整个MapReduce最全工作流程,但是Shuffle过程只是从第7步开始到第16步结束,具体Shuffle过程详解,如下:
(1)MapTask收集我们的map()方法输出的kv对,放到内存缓冲区中
(2)从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
(3)多个溢出文件会被合并成大的溢出文件
(4)在溢出过程及合并的过程中,都要调用Partitioner进行分区和针对key进行排序
(5)ReduceTask根据自己的分区号,去各个MapTask机器上取相应的结果分区数据
(6)ReduceTask会抓取到同一个分区的来自不同MapTask的结果文件,ReduceTask会将这些文件再进行合并(归并排序)
(7)合并成大文件后,Shuffle的过程也就结束了,后面进入ReduceTask的逻辑运算过程(从文件中取出一个一个的键值对Group,调用用户自定义的reduce()方法)
注意:
(1)Shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
(2)缓冲区的大小可以通过参数调整,参数:mapreduce.task.io.sort.mb默认100M。
13、Shuffle机制
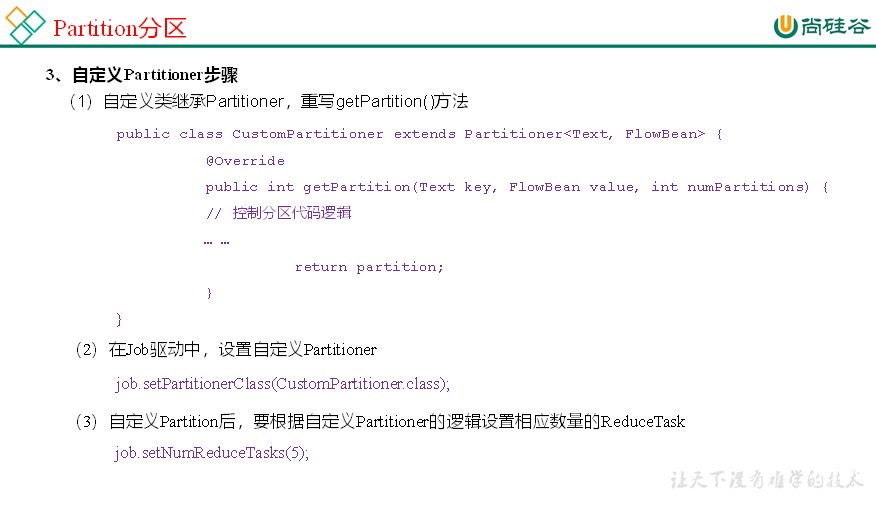
14、Partition分区


15、WritableComparable排序



原理分析:
bean对象做为key传输,需要实现WritableComparable接口重写compareTo方法,就可以实现排序。
@Override public int compareTo(FlowBean bean) { int result; // 按照总流量大小,倒序排列 if (this.sumFlow > bean.getSumFlow()) { result = -1; }else if (this.sumFlow < bean.getSumFlow()) { result = 1; }else { result = 0; } return result; }
