Hadoop学习总结 (三) —— HDFS
1、HDFS产生的背景和定义
1)HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
2)HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
2、优缺点
优点:
(1)高容错性,数据自动备份副本,丢失可自动回复
(2)适合处理大数据
数据规模大(PB级别)
文件规模大(百万级别)
(3)可以构建在廉价机器上,多副本提高可靠性
缺点:
(1)不适合低延时数据访问(毫秒级存储数据)
(2)无法高效应对大量小文件的存储
这会占用大量NameNode内存用于存储
小文件存储寻址时间会超过读取时间,违反HDFS设计目标
(3)不支持并发写入和文件随机修改
一个文件只能一个写,不允许多线程写
只允许追究,不支持文件的随机修改
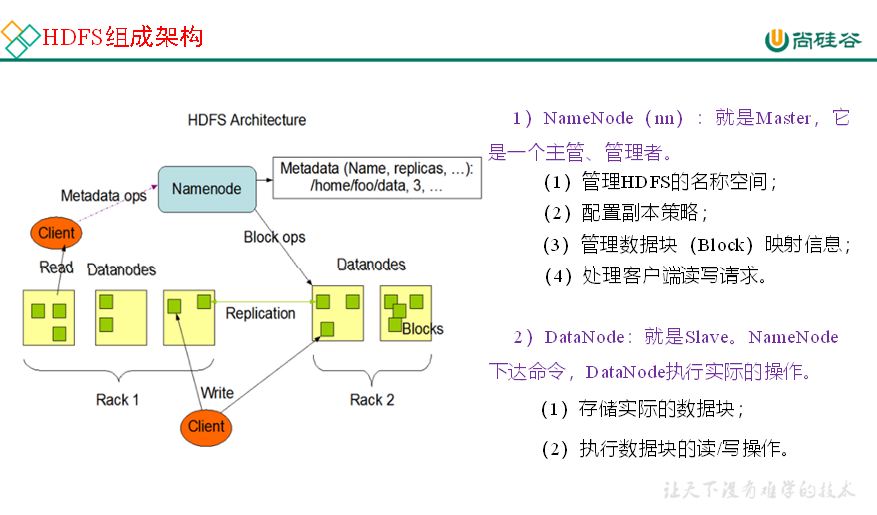
3、HDFS组成架构

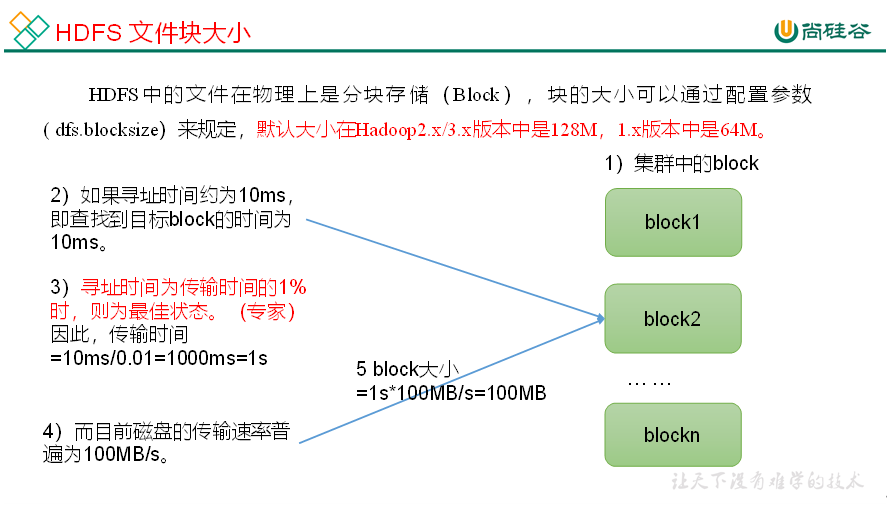
4、HDFS文件块大小

5、HDFS常用SHELL命令
Hadoop fs 具体命令 OR hdfs dfs 具体命令
两个命令相同
常用命令
1)启动Hadoop集群(方便后续的测试)
102:sbin/start-dfs.sh:
103:sbin/start-yarn.sh
上传
1)-moveFromLocal:从本地剪切粘贴到HDFS
hadoop fs -moveFromLocal ./shuguo.txt /sanguo
2)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
hadoop fs -copyFromLocal weiguo.txt /sanguo
3)-put:等同于copyFromLocal,生产环境更习惯用put
hadoop fs -put ./wuguo.txt /sanguo
4)-appendToFile:追加一个文件到已经存在的文件末尾
hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt
下载
1)-copyToLocal:从HDFS拷贝到本地
hadoop fs -copyToLocal /sanguo/shuguo.txt ./
2)-get:等同于copyToLocal,生产环境更习惯用get
hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt
客户端代码常套路:
1、获取一个客户端对象
2、执行相关操作命令
3、关闭资源
6、HDFS读写流程
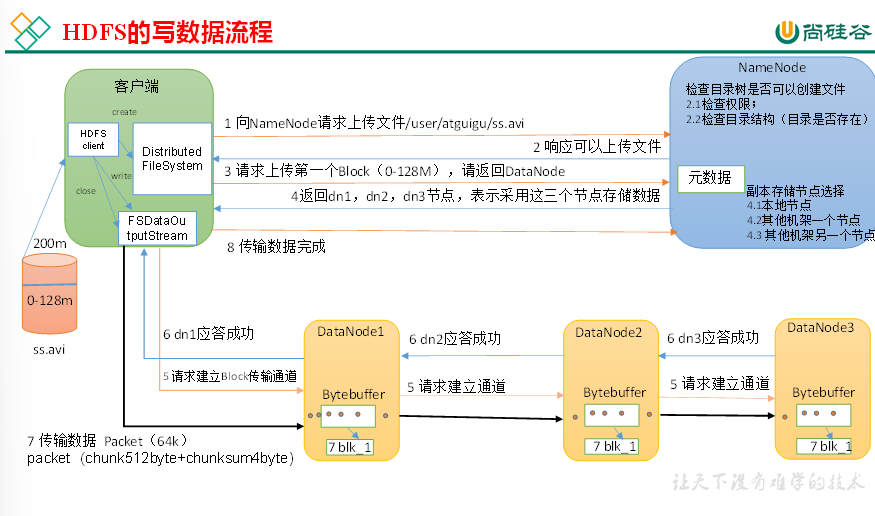
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)
网络拓扑-节点距离计算
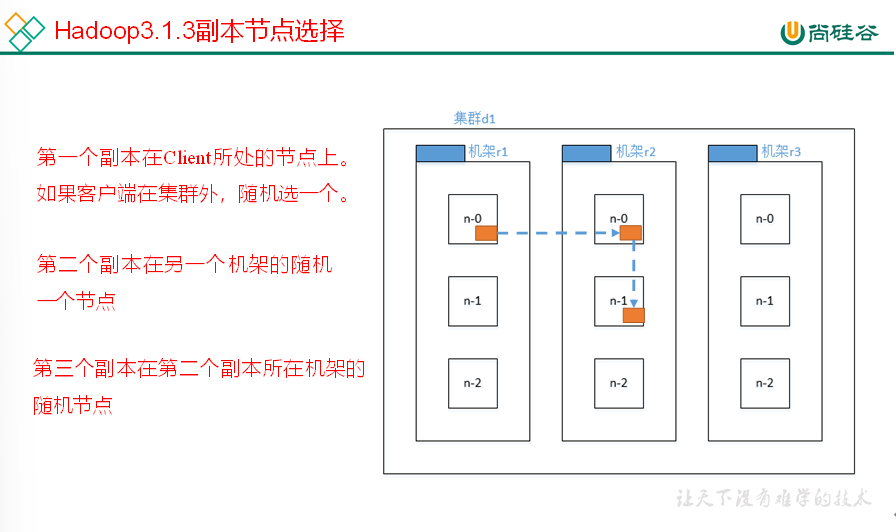
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
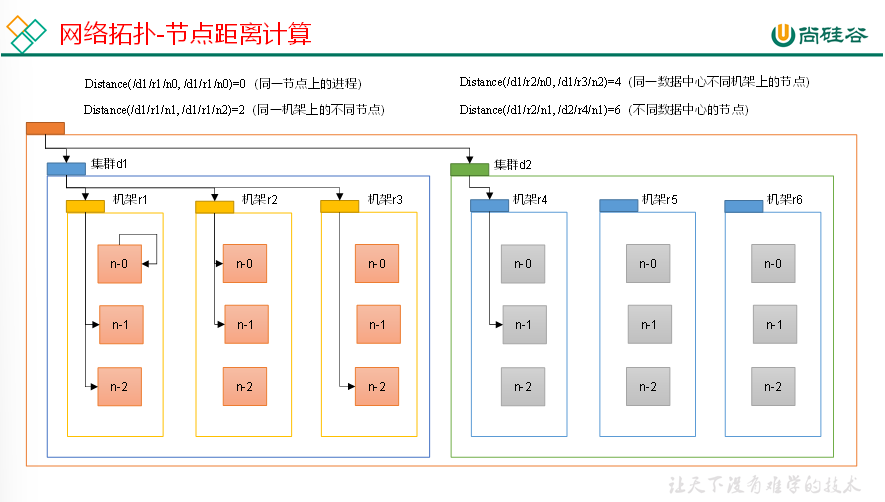
机架感知(副节点的选择)
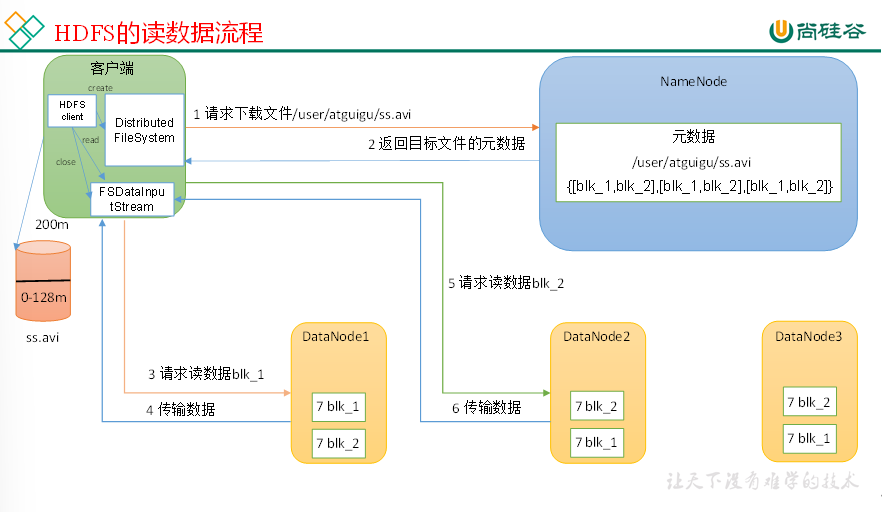
(1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
7、NN&2NN
(1)NN和2NN工作机制
问题一:namenode的元数据存储在哪里?
存在磁盘中可靠但是慢
存在内存中快但是不可靠
因此元数据产生在磁盘中备份元数据的FsImage。
问题二:如果元数据更新同时更新FsImage会导致效率低,不更新又会导致一致性问题
因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
问题三:长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。
因此,需要定期进行FsImage和Edits的合并
问题四:如果这个操作由NameNode节点完成,又会效率过低。
因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
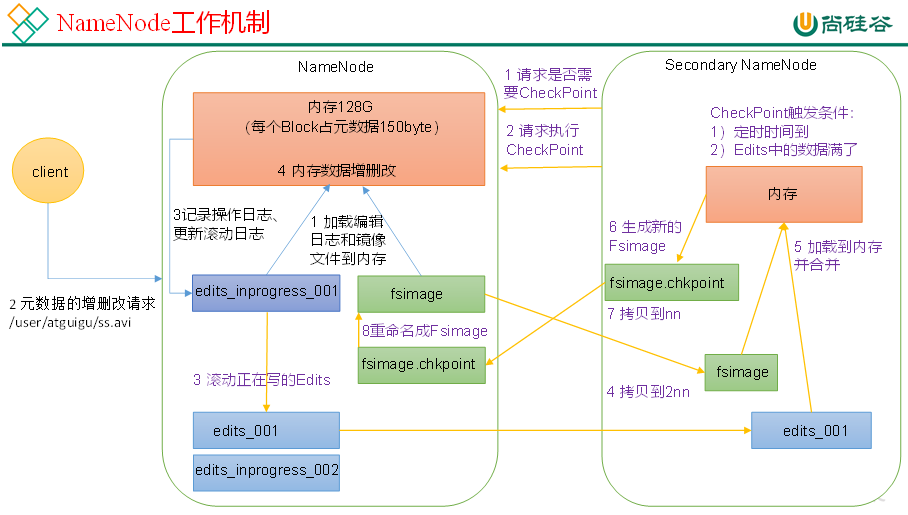
1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
8、Fsimage和Edits解析

查看Fsimage
基本语法
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
查看Edits
基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
CheckPoint时间设置
1)通常情况下,SecondaryNameNode每隔一小时执行一次。
2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
9、DataNode工作机制
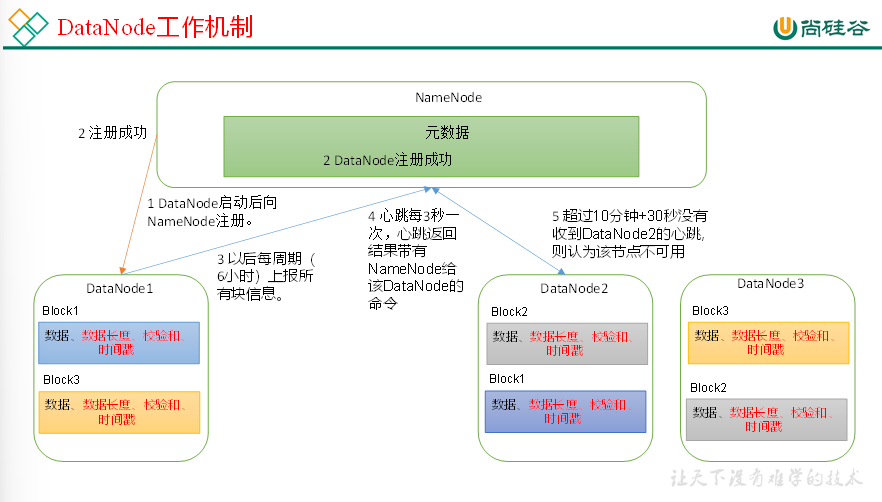
(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2)DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息。
10、总结
1、HDFS文件块大小(面试重点)
硬盘读写速度
在企业中 一般128m(中小公司) 256m (大公司)
2、HDFS的Shell操作(开发重点)
3、HDFS的读写流程(面试重点)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号