
自行编译spark适配CDH 6.3.2的spark-sql
一开始觉得简单,参考某些文章用apache编译后的2.4.0的包直接替换就行,发现搞了好久spark-sql都不成功。
于是下决心参考网上的自己编译了。
软件版本:jdk-1.8、maven-3.6.3、scala-2.11.12 、spark-3.1.2
1.下载软件
wget http://distfiles.macports.org/scala2.11/scala-2.11.12.tgz wget https://archive.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz wget https://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2.tgz
把压缩包放在/opt目录,全部解压,设置jdk、scala、maven 的环境变量
#####java##### export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera export JRE_HOME=$JAVA_HOME/jre export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib ######maven####### export PATH=/opt/apache-maven-3.6.3/bin:$PATH ####scala##### export SCALA_HOME=/opt/scala-2.11.12 export PATH=${SCALA_HOME}/bin:$PATH
2.编译spark3
修改spark3的pom配置 /opt/spark-3.1.2/pom.xml,增加cloudera maven仓库
<repositories>
<repository>
<id>central</id>
<!-- This should be at top, it makes maven try the central repo first and then others and hence faster dep resolution -->
<name>Maven Repository</name>
<url>https://repo1.maven.org/maven2</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
修改pom文件中的hadoop版本
默认是带的hadoop 3.2 ,需要将 hadoop.version 属性改为 3.0.0-cdh6.3.2
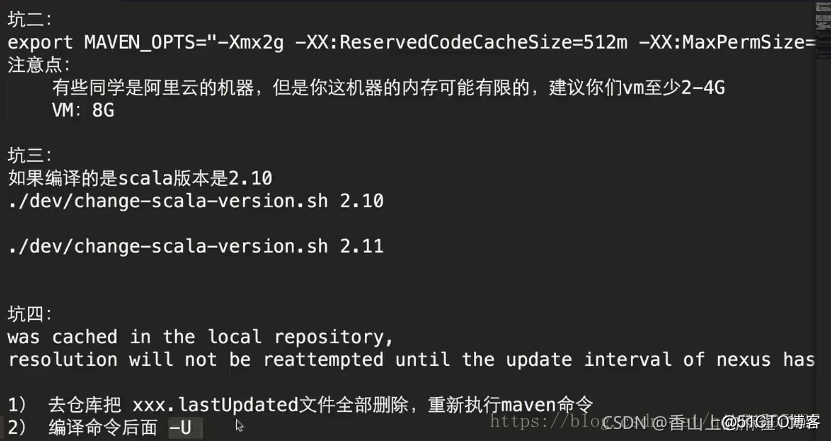
注意2:maven环境内存要符合条件。如果用maven进行编译需要先设置maven内存,如果用make-distribution.sh ,则在这个/opt/spark-3.1.2/dev/make-distribution.sh脚本中进行修改:
编译的时候,Xmx设置的4G,CacheSize设置的2G,否则编译总是失败
export MAVEN_OPTS="-Xmx4g -XX:ReservedCodeCacheSize=2g"
注意3:如果scala 版本为2.10.x ,需要进行
# cd /opt/spark-3.1.2
# ./dev/change-scala-version.sh 2.10
如果为2.11.x,需要进行
# cd /opt/spark-3.1.2
#./dev/change-scala-version.sh 2.11
注意4:
推荐使用一下命令编译:
./dev/make-distribution.sh \ --name 3.0.0-cdh6.3.2 --tgz -Pyarn -Phadoop-3.0 \ -Phive -Phive-thriftserver -Dhadoop.version=3.0.0-cdh6.3.2 -X
用的是spark的make-distribution.sh脚本进行编译,这个脚本其实也是用maven编译的,
- –tgz 指定以tgz结尾
- –name后面跟的是我们Hadoop的版本,在后面生成的tar包我们会发现名字后面的版本号也是这个(这个可以看make-distribution.sh源码了解)
- -Pyarn 是基于yarn
- -Dhadoop.version=3.0.0-cdh6.3.2 指定Hadoop的版本。
编译报错报错信息:
/root/spark-3.1.2/build/mvn: 行 212: 6877 已杀死 "${MVN_BIN}" -DzincPort=${ZINC_PORT} "$@"
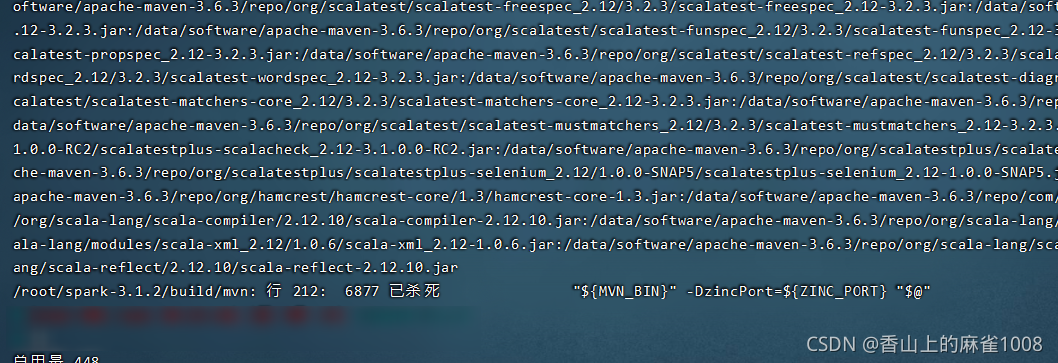
解决方法:
修改./dev/make-distribution.sh文件,将原来的maven地址指定为自己系统里装的maven环境:
# cat make-distribution.sh # Figure out where the Spark framework is installed SPARK_HOME="$(cd "`dirname "$0"`/.."; pwd)" DISTDIR="$SPARK_HOME/dist" MAKE_TGZ=false MAKE_PIP=false MAKE_R=false NAME=none #MVN="$SPARK_HOME/build/mvn" MVN="/opt/apache-maven-3.6.3/bin/mvn"
编译过程很漫长:
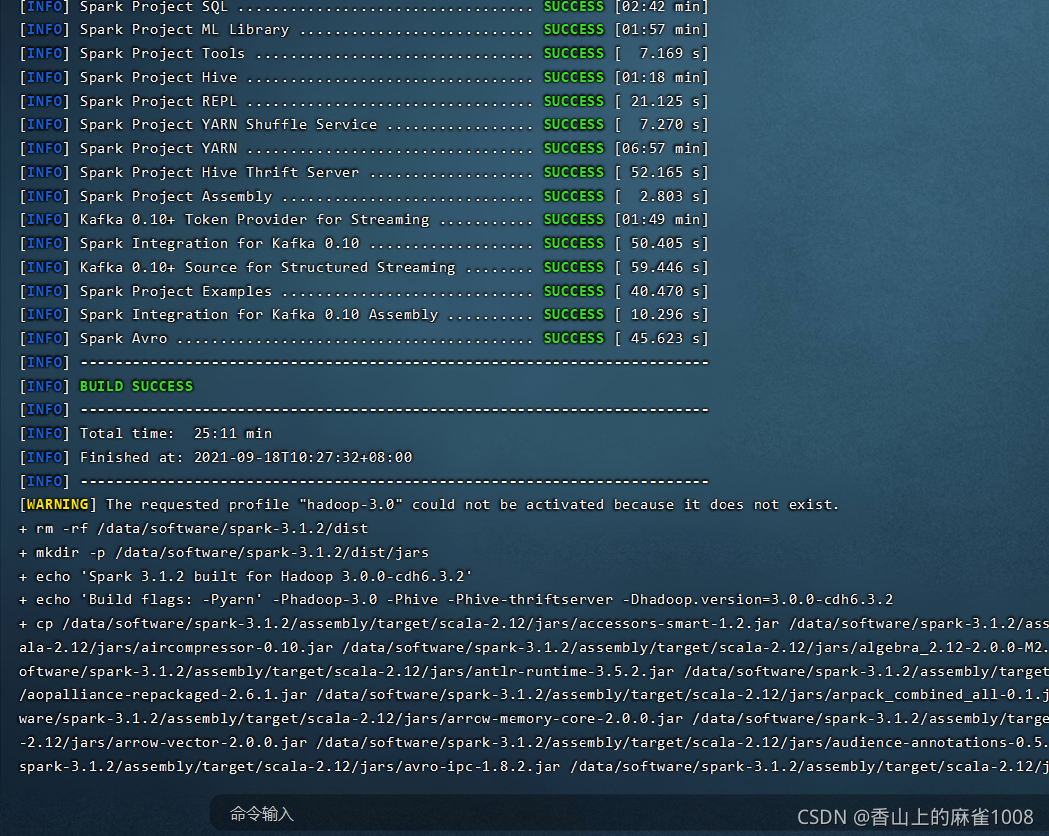
编译成功后的目录:
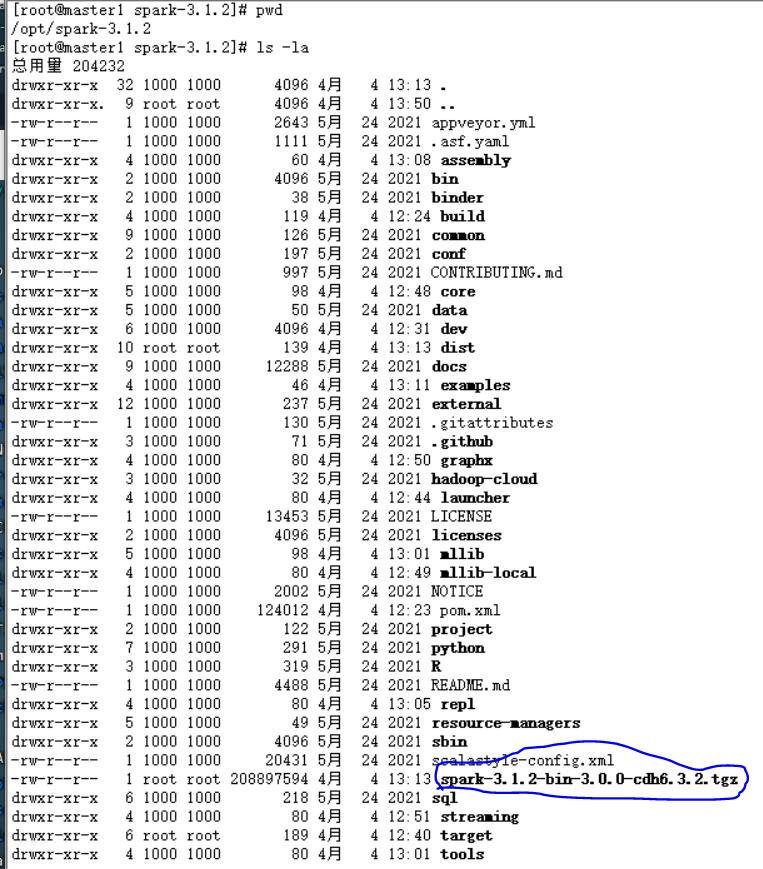
编译完后的spark文件就是:
spark-3.1.2-bin-3.0.0-cdh6.3.2.tgz
3.部署
tar zxvf spark-3.1.2-bin-3.0.0-cdh6.3.2.tgz /opt/cloudera/parcels/CDH/lib/spark3
将CDH集群的spark-env.sh 复制到/opt/cloudera/parcels/CDH/lib/spark3/conf 下:
cp /etc/spark/conf/spark-env.sh /opt/cloudera/parcels/CDH/lib/spark3/conf
然后将spark-home 修改一下:
[root@master1 conf]# cat spark-env.sh #!/usr/bin/env bash ## # Generated by Cloudera Manager and should not be modified directly ## SELF="$(cd $(dirname $BASH_SOURCE) && pwd)" if [ -z "$SPARK_CONF_DIR" ]; then export SPARK_CONF_DIR="$SELF" fi #export SPARK_HOME=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/spark export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark3
将gateway节点的hive-site.xml复制到spark2/conf目录下,不需要做变动:
cp /etc/hive/conf/hive-site.xml /opt/cloudera/parcels/CDH/lib/spark3/conf/
配置yarn.resourcemanager,查看你CDH的yarn配置里是否有如下配置,需要开启:
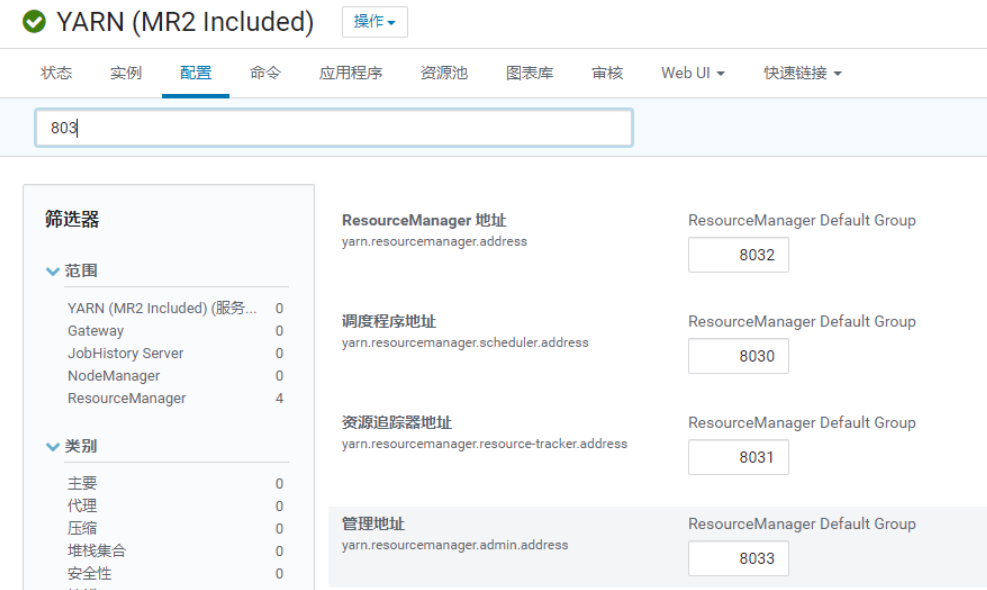
正常情况下,resourcemanager应该会默认启用以上配置的,
创建spark-sql
cat /opt/cloudera/parcels/CDH/bin/spark-sql #!/bin/bash # Reference: http://stackoverflow.com/questions/59895/can-a-bash-script-tell-what-directory-its-stored-in export HADOOP_CONF_DIR=/etc/hadoop/conf export YARN_CONF_DIR=/etc/hadoop/conf SOURCE="${BASH_SOURCE[0]}" BIN_DIR="$( dirname "$SOURCE" )" while [ -h "$SOURCE" ] do SOURCE="$(readlink "$SOURCE")" [[ $SOURCE != /* ]] && SOURCE="$BIN_DIR/$SOURCE" BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )" done BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )" LIB_DIR=$BIN_DIR/../lib export HADOOP_HOME=$LIB_DIR/hadoop # Autodetect JAVA_HOME if not defined . $LIB_DIR/bigtop-utils/bigtop-detect-javahome exec $LIB_DIR/spark3/bin/spark-submit --class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver "$@"
配置快捷方式
alternatives --install /usr/bin/spark-sql spark-sql /opt/cloudera/parcels/CDH/lib/spark3/bin/spark-sql 1
测试:

参考:
https://its401.com/article/qq_26502245/120355741
https://blog.csdn.net/Mrheiiow/article/details/123007848

 浙公网安备 33010602011771号
浙公网安备 33010602011771号