


《漫谈线上问题排查》笔记-20210701
《漫谈线上问题排查》作者骆俊武,2013 年北航计算机系硕士毕业,互联网行业工作 8 年,现在独角兽公司做技术总监。作者对实际工作过程中经历过的线上案例进行
提炼,一方面是自我的复盘总结,另一方面也想公开出去,以便更多的人受益。
联系方式:
微信号:luojunwu1988
邮箱:luojunwu1988@163.com
大佬分享的2句话,一起共勉:
1、获得人生的成功,需要的专注和坚持不懈,多过天才和机会
2、世界上有两种最耀眼的光芒:一种是太阳,一种是我们努力的模样!
第一章 线上问题排查的方法论
1.1 线上问题的处理流程
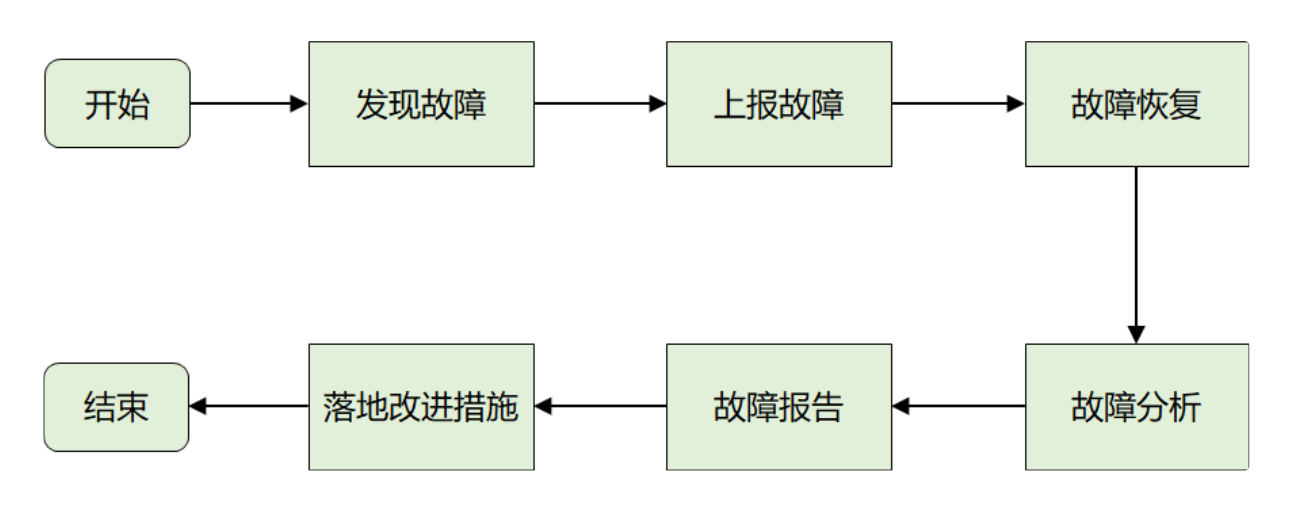
1.2 排查问题的技巧
针对处理流程中的 3 个关键环节:发现故障、恢复故障、故障分析,常用的技巧。
1) 快速发现故障,取决于两个方面:
(1) 对系统是否足够了解?
(a)、对系统架构的了解:出现问题后,你需要知道关联的上下游系统都有哪些?依赖
的存储、中间件都有哪些?这样你才会形成很清晰的链路,然后去定位问题出现在哪
个环节上?
(b)、对业务的了解:只有对业务足够了解,你才能从业务逻辑上判断它到底是不是故
障?这个故障具体是哪个业务环节出问题了?然后再回到系统、服务或者代码层面去
做进一步定位。
(2)系统的监控建设是否足够完善?
(a)是否有配套的监控系统:首先要解决有无的问题,从机器、到操作系统(CPU、内存、磁盘、IO)、到各种中间件(DB、MQ、Redis)、再到应用层(JVM、接口性能、流量、业务指标)等,是否有配套的监控手段
(b)对监控系统的使用是否到位了:有工具了,然后再考虑业务上如何使用好这些工具?要建立哪些监控指标?告警阈值如何进行合理设置?技术同学对于监控系统的使用是否熟练?团队是否有成熟的线上问题处理机制?
2) 快速恢复故障
出现故障后的原则一定是:第一时间恢复,以尽可能地减少对业务的影响。
快速恢复的常见手段有:回滚到上一个版本、紧急修复、服务扩容、服务降级、摘机、重启等
在恢复故障的同时,还有一件很重要的事情不能遗漏,那就是:保留现场,方便后续进行根因分析
对于 Java 程序,常见的几种保留现场方法是:
1)、执行 jstack stack.log,每隔几秒钟保存一次堆栈信息 2)、执行 jstat -gcutil ,查看堆内存各区域的使用率以及GC情况 3)、执行 jmap -histo | head -n20,查看堆内存中的存活对象,并按空间排序 4)、执行 jmap -dump:format=b,file=heap ,dump堆内存文件,dump之前可以从做摘机处理,因为dump过程中会发生FGC,引发STW 5)、执行 top 命令,shift + p 可以按 CPU 使用率倒排,记录最消耗资源的进程信息 6)、执行 free -m 命令,shift + m 可以按照内存使用量倒排,记录最好资源的进程\信息
3) 快速定位故障
非常依赖个人经验、甚至是对底层原理的掌握深度。
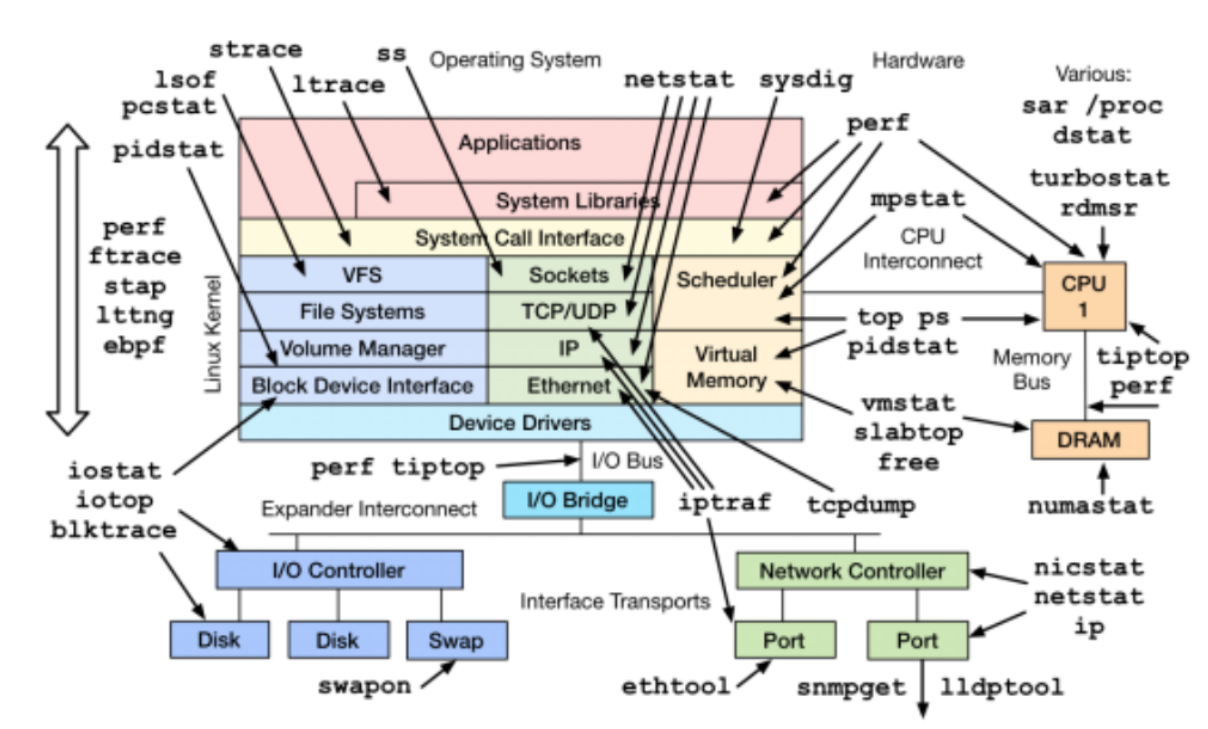
Linux 定位工具
此外,还有这些非常高频的命令行和工具:
磁盘:df -h 网络:netstat -nat | awk '{print $6}' | sort | uniq -c | sort -rn IO:iostat 内存:free -m CPU:top -Hp JVM:jstack(线程)、jmap(内存)、jstat(GC) 其他工具:JVisual、MAT、arthas
1.3 监控体系建设
1.监控系统的7大作用

- 实时采集监控数据:包括 硬件、操作系统、中间件、应用程序等各个维度的数据。
- 实时反馈监控状态:通过对采集的数据进行多维度统计和可视化展示,能实时体现监控对象的状态是正常还是异常。
- 预知故障和告警:能够提前预知故障风险,并及时发出告警信息。
- 辅助定位故障:提供故障发生时的各项指标数据,辅助故障分析和定位。
- 辅助性能调优:为性能调优提供数据支持,比如慢SQL,接口响应时间等。
- 辅助容量规划:为服务器、中间件以及应用集群的容量规划提供数据支撑。
- 辅助自动化运维:为自动扩容或者根据配置的SLA进行服务降级等智能运维提供数据支撑。
2. 正确姿势的使用监控系统
一个成熟的研发团队通常会定一个监控规范,用来统一监控系统的使用方法。
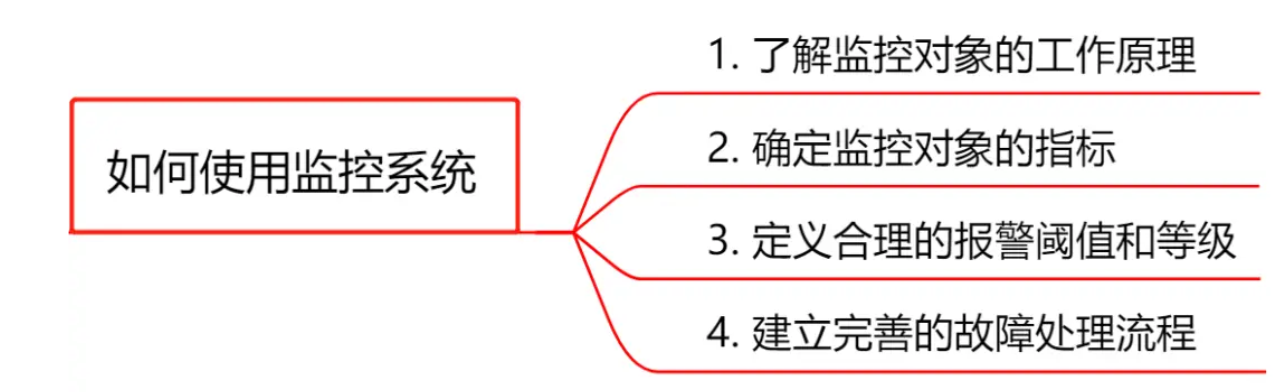
- 了解监控对象的工作原理:要做到对监控对象有基本的了解,清楚它的工作原理。比如想对JVM进行监控,你必须清楚JVM的堆内存结构和垃圾回收机制。
- 确定监控对象的指标 :清楚使用哪些指标来刻画监控对象的状态?比如想对某个接口进行监控,可以采用请求量、耗时、超时量、异常量等指标来衡量。
- 定义合理的报警阈值和等级:达到什么阈值需要告警?对应的故障等级是多少?不需要处理的告警不是好告警,可见定义合理的阈值有多重要,否则只会降低运维效率或者让监控系统失去它的作用。
- 建立完善的故障处理流程:收到故障告警后,一定要有相应的处理流程和oncall机制,让故障及时被跟进处理。
3. 监控的对象和指标都有哪些?
常用的监控对象以及监控指标分类整理:

a. 硬件监控
包括:电源状态、CPU状态、机器温度、风扇状态、物理磁盘、raid状态、内存状态、网卡状态
b. 服务器基础监控
CPU:单个CPU以及整体的使用情况
内存:已用内存、可用内存
磁盘:磁盘使用率、磁盘读写的吞吐量
网络:出口流量、入口流量、TCP连接状态
c. 数据库监控
包括:数据库连接数、QPS、TPS、并行处理的会话数、缓存命中率、主从延时、锁状\态、慢查询
d. 中间件监控
Nginx:活跃连接数、等待连接数、丢弃连接数、请求量、耗时、5XX错误率
Tomcat:最大线程数、当前线程数、请求量、耗时、错误量、堆内存使用情况、GC次数和耗时
缓存 :成功连接数、阻塞连接数、已使用内存、内存碎片率、请求量、耗时、缓存命中率
消息队列:连接数、队列数、生产速率、消费速率、消息堆积量
e. 应用监控
HTTP接口:URL存活、请求量、耗时、异常量RPC接口:请求量、耗时、超时量、拒绝量
JVM :GC次数、GC耗时、各个内存区域的大小、当前线程数、死锁线程数
线程池:活跃线程数、任务队列大小、任务执行耗时、拒绝任务数
连接池:总连接数、活跃连接数
日志监控:访问日志、错误日志
业务指标:视业务来定,比如PV、订单量等
4. 监控系统的基本流程
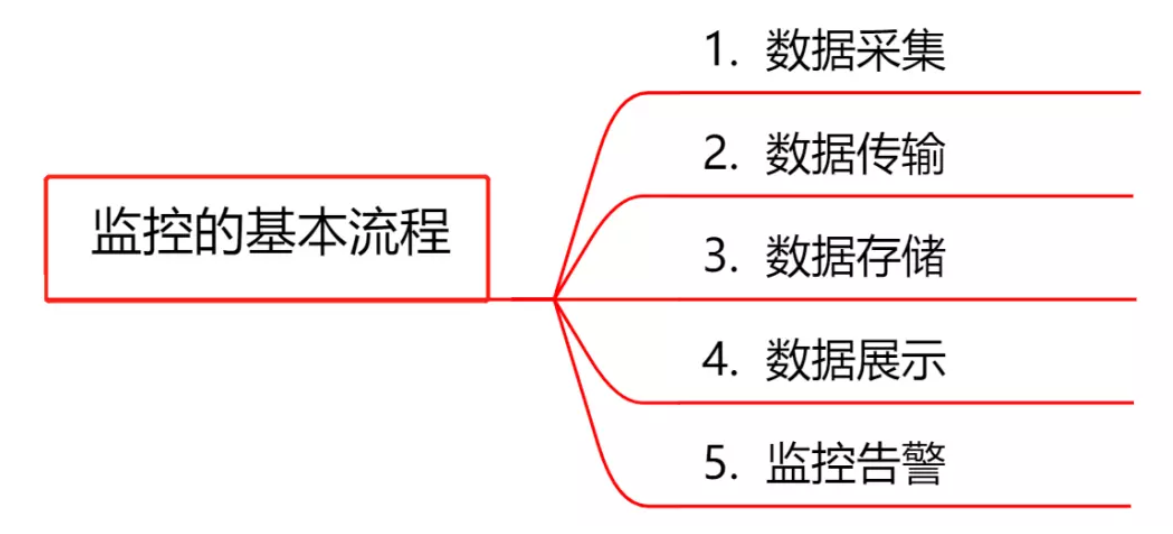
- 数据采集:采集的方式有很多种,包括 日志埋点进行采集(通过Logstash、Filebeat等进行上报和解析), JMX标准接口输出监控指标,被监控对象提供RESTAPI进行数据采集(如Hadoop、ES),系统命令行,统一的SDK进行侵入式的埋点和上报等。
- 数据传输:将采集的数据以TCP、UDP或者HTTP协议的形式上报给监控系统,有主动Push模式,也有被动Pull模式。
- 数据存储:有使用MySQL、Oracle等RDBMS存储的,也有使用时序数据库RRDTool、OpentTSDB、InfluxDB存储的,还有使用HBase存储的。
- 数据展示:数据指标的图形化展示。
- 监控告警:灵活的告警设置,以及支持邮件、短信、IM等多种通知通道。
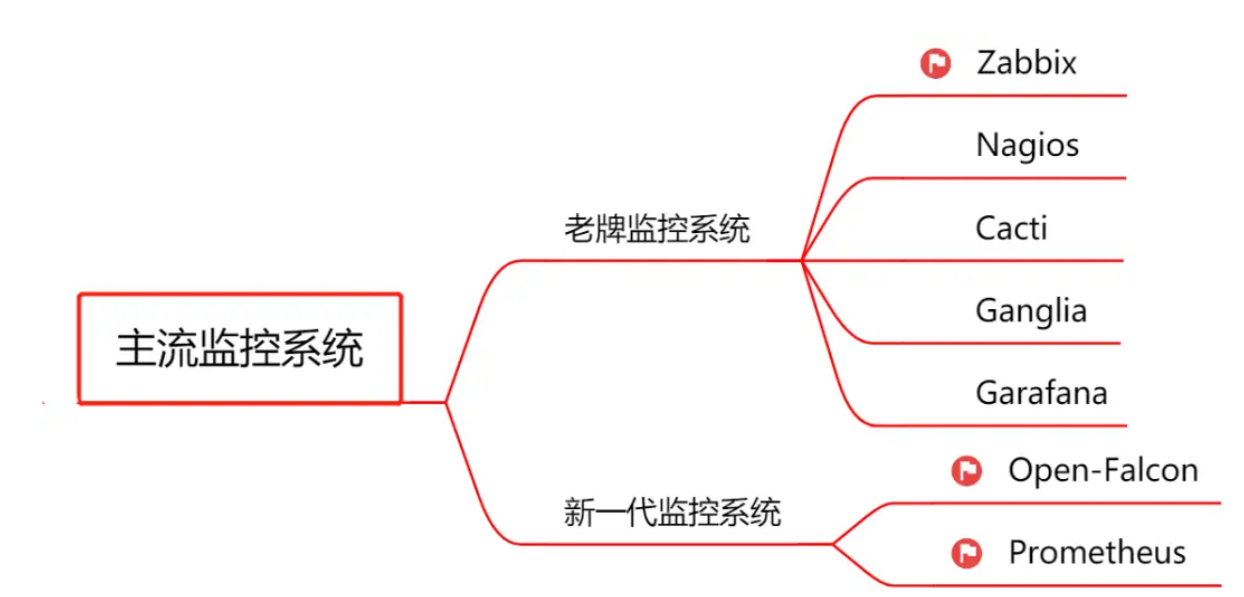
主流监控系统:
第二章 典型案例的排查分析过程
2.1 案例一:多线程死锁问题排查
1 业务背景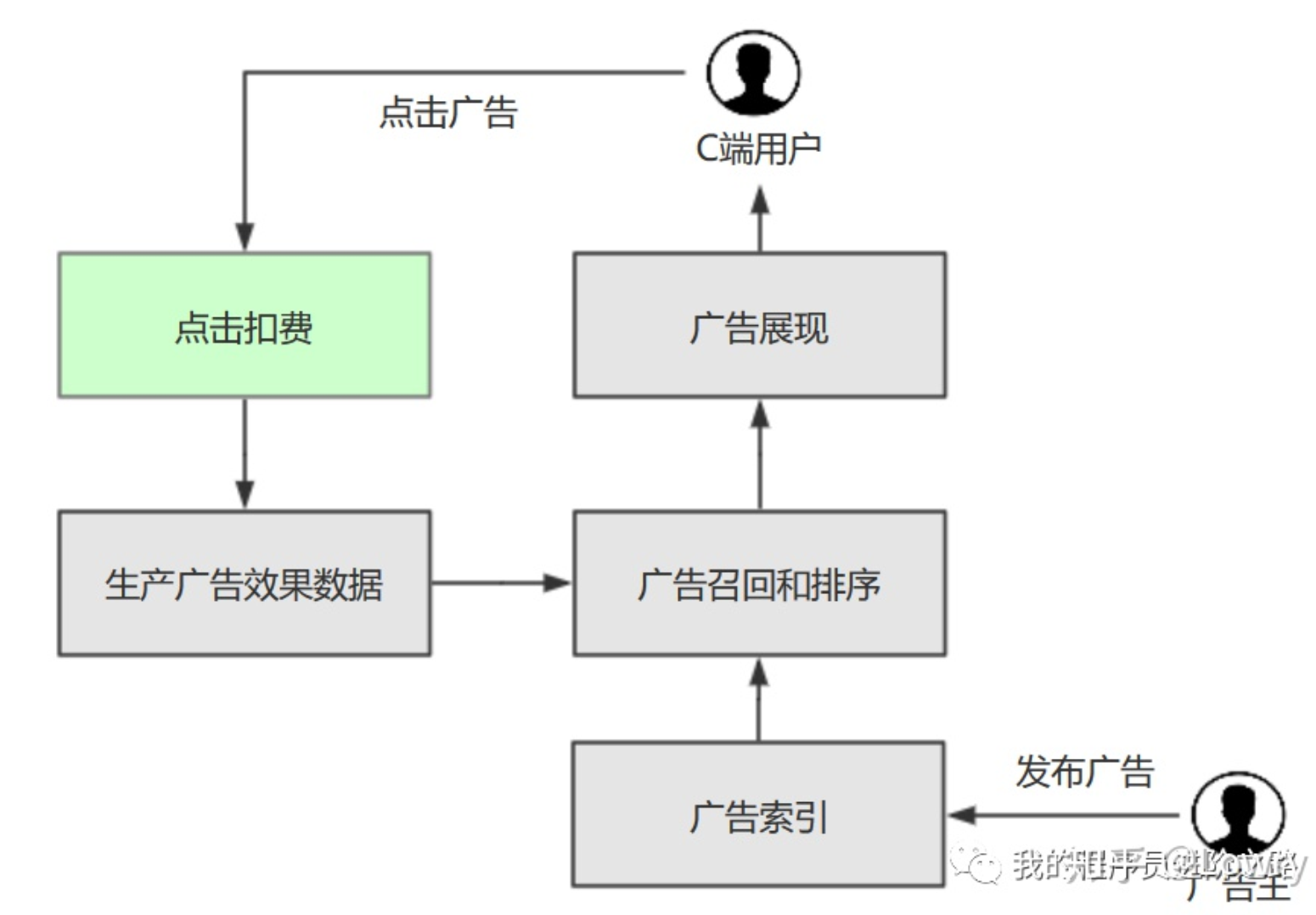
2 问题现象
扣费服务的线程池任务队列大小远远超出了设定阈值,而且队列大小随着时间推移还在持续变大。
3 问题调查和事故解决过程
- 第1步:查看了扣费服务各个维度的实时数据:包括服务调用量、超时量、错误日志、JVM监控,均未发现异常
- 第2步:排查了扣费服务依赖的存储资源(MySQL、Redis、MQ)、外部服务,发现了事故期间存在大量的数据库慢查询,MySQL的所有读写性能都受到了影响,发现insert操作的耗时也远远大于正常时期。猜测数据库慢查询影响了扣费流程的性能,从而造成了任务队列的积压。但是停止抽取任务后,数据库的insert性能恢复到正常水平了,可阻塞队列大小仍然还在持续增大,告警并未消失。
- 第3步:尝试万能的重启打法,果然重启服务后,各项业务指标都恢复正常。为了保留事故现场,保留了一台服务器未做重启,把这台机器从服务管理平台摘掉。
4 问题根本原因的分析过程
- 第1步:再次上线保留环境的服务器,发现线程池积压的几千个任务,经过1个晚上都没被线程池处理掉,猜测应该存在死锁情况
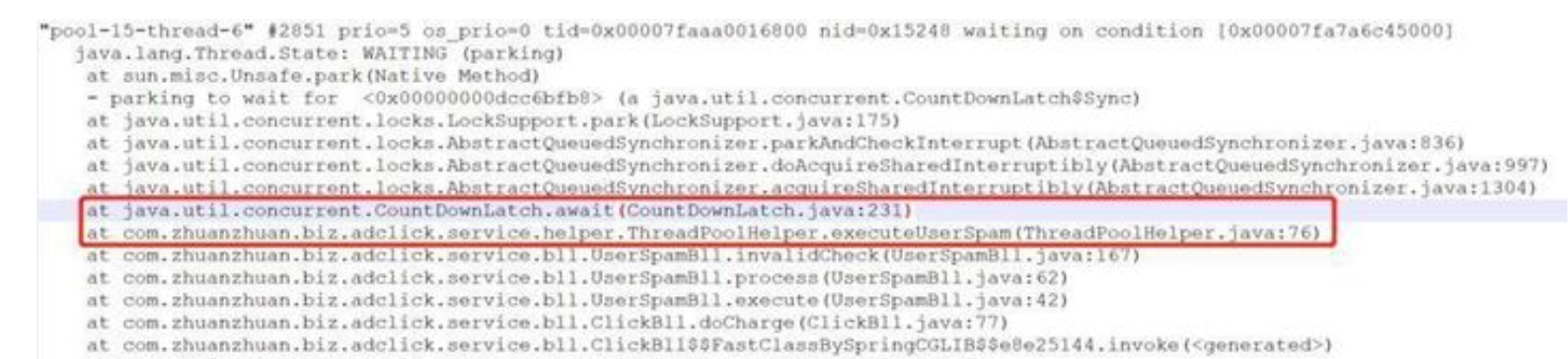
通过 jstack 命令 dump 线程快照:
#找到扣费服务的进程号 $ ps aux | grep "adclick" # 通过进程号dump线程快照,输出到文件中 $ jstack pid > /tmp/stack.txt
在 jstack 的日志文件中,发现用于扣费的业务线程池的所有线程都处于 waiting状态,这行代码调用了countDownLatch 的 await() 方法,即等待计数器变为 0 后释放共享锁。
第2步:找到上述异常后,看了下业务代码中使用了 newFixedThreadPool 线程池,核心线程数设置为 25。针对newFixedThreadPool ,JDK文档的说明如下:
创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。如果在所有线程处于活跃状态时提交新任务,则在有可用线程之前,新任务将在队列中等待
关于newFixedThreadPool,核心包括两点:
1、最大线程数 = 核心线程数,当所有核心线程都在处理任务时,新进来的任务会提交到任务队列中等待;
2、使用了无界队列:提交给线程池的任务队列是不限制大小的,如果任务被阻塞或者处理变慢,那么显然队列会越来越大。
所以结论是:核心线程全部死锁,新进的任务不对涌入无界队列,导致任务队列不断增加。
第3步:死锁的真正原因:一次扣费行为属于父任务,同时它又包含了多次子任务:子任务用于并行执行反作弊策略,而父任务和子任务使用的是同一个业务线程池。当线程池中全部都是执行中的父任务时,并且所有父任务都存在子任务未执行完,这样就会发生死锁。
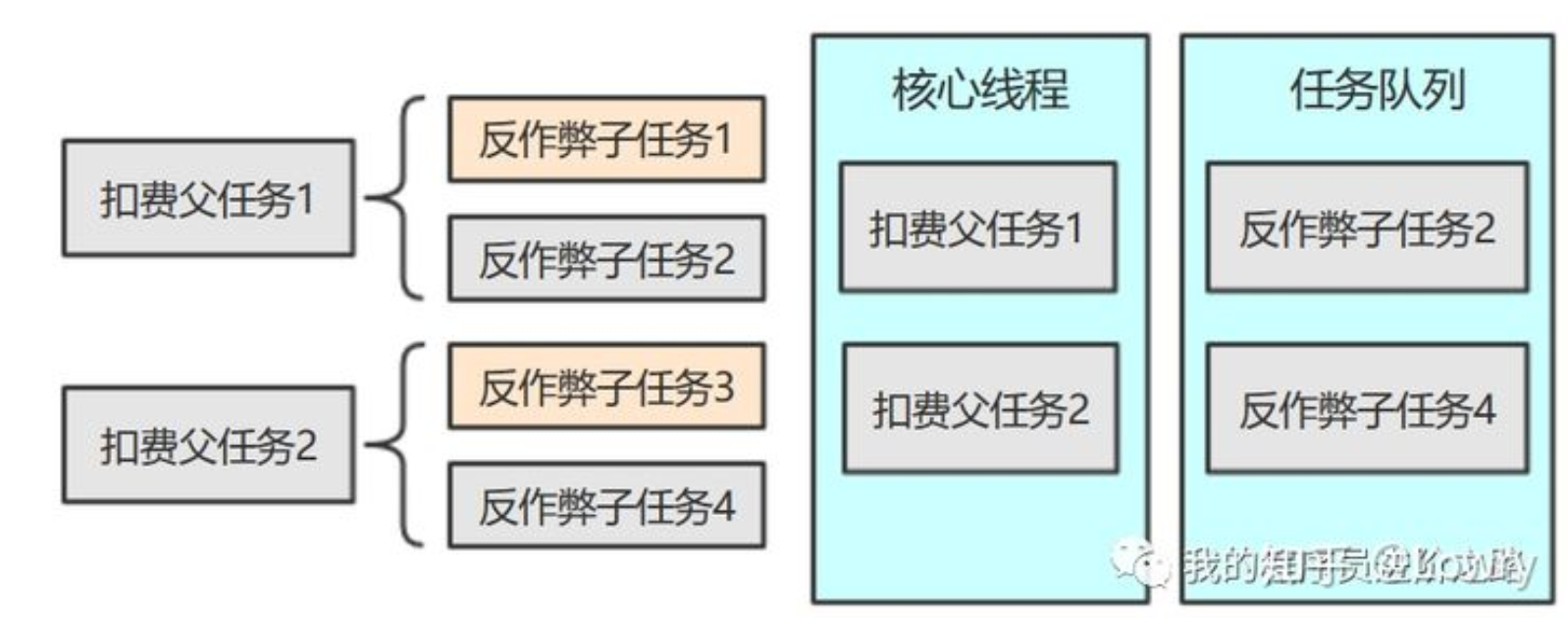
5 解决方案
最简单的解决方案就是:增加一个新的业务线程池,用来隔离父子任务,现有的线程池只用来处理扣费任务,新的线程池用来处理反作弊任务。这样就可以彻底避免死锁的情况了。
6 问题总结
存在以下几点待继续优化:
1)、使用固定线程数的线程池存在 OOM 风险,在阿里巴巴 Java 开发手册中也明确指出,而且用的词是『不允许』使用 Executors 创建线程池。而是通过ThreadPoolExecutor去创建,这样让写的同学能更加明确线程池的运行规则和核心参数设置,规避资源耗尽的风险。
2)、广告的扣费场景是一个异步过程,通过线程池或者 MQ来实现异步化处理都是可选的方案。另外,极个别的点击请求丢失不扣费从业务上是允许的,但是大批量的请求丢弃不处理且没有补偿方案是不允许的。后续采用有界队列后,拒绝策略可以考虑发送 MQ 做重试处理。
2.2 案例二:RPC超时问题排查
1 业务问题和业务背景
业务问题:APP 首页除了banner 图和导航区域,下方的推荐模块变成空白页了。
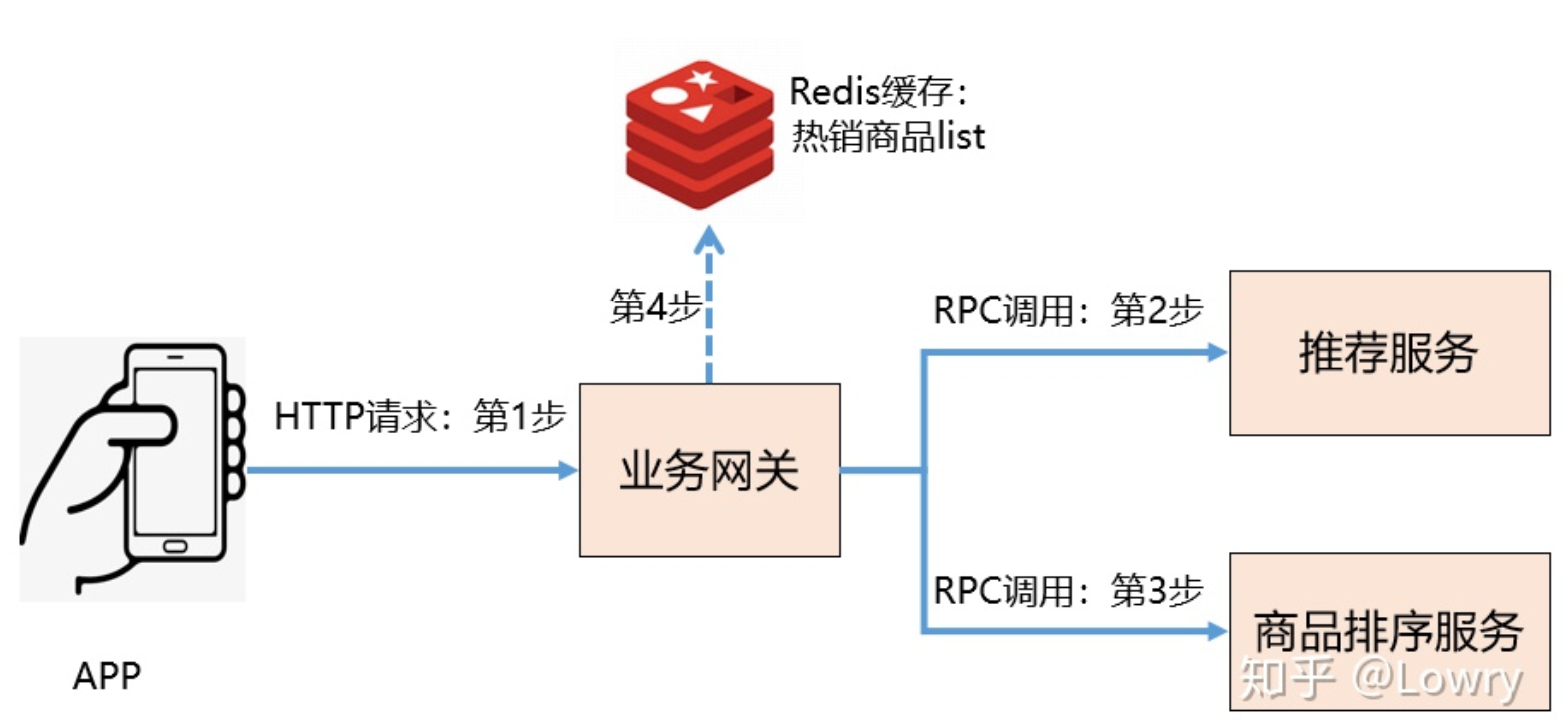
业务背景
2 问题调查和原因分析
- 第1步:APP端通过抓包发现:HTTP请求存在接口超时(超时时间设置的是5秒)。
- 第2步:业务网关通过日志发现:调用推荐服务的RPC接口出现了大面积超时(超时时间设置的是3秒)
- 第3步:推荐服务通过日志发现:dubbo的线程池耗尽。
- 第4步:进一步调查得出:是因为推荐服务依赖的redis集群不可用导致了超时,进而导致线程池耗尽。
最终跟踪分析找到了根本原因:APP端调用业务网关的超时时间是5秒,业务网关调用推荐服务的超时时间是3秒,同时还设置了3次超时重试,这样当推荐服务调用失败进行第2次重试时,HTTP请求就已经超时了,因此业务网关的所有降级策略都不会生效。
示意图如下: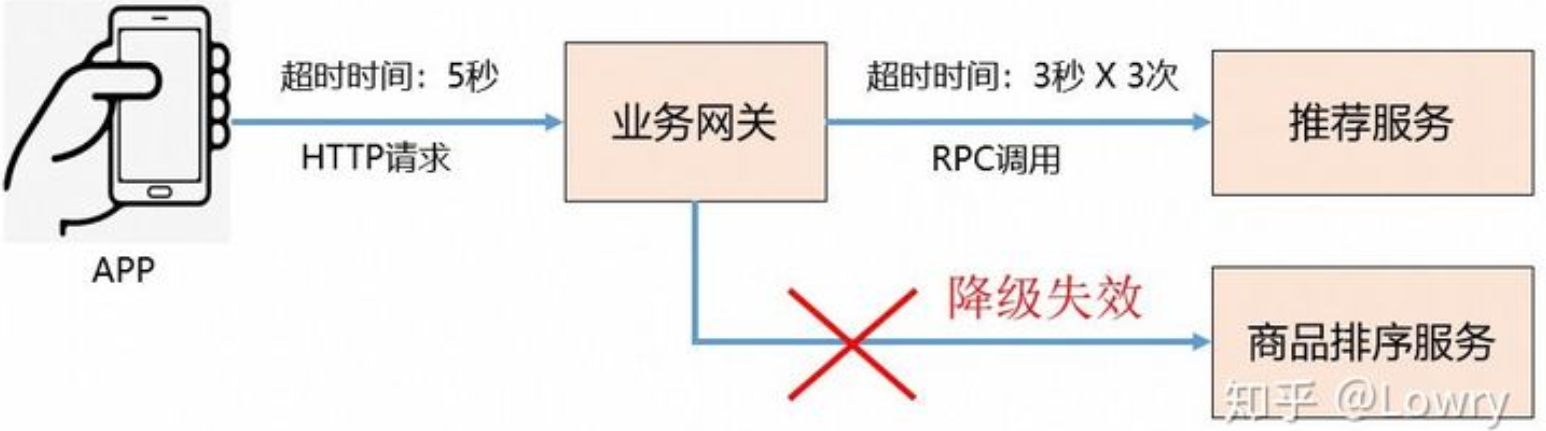
3 解决方案
1、将业务网关调用推荐服务的超时时间改成了800ms(推荐服务的TP99大约为540ms),超时重试次数改成了2次
2、将业务网关调用商品排序服务的超时时间改成了600ms(商品排序服务的TP99大约为400ms),超时重试次数也改成了2次
4 RPC框架的超时实现原理
dubbo可在两个地方配置超时时间:分别是 provider(服务端,服务提供方)和 consumer(消费端,服务调用方)。服务端的超时配置是消费端的缺省配置,也就是说只要服务端设置了超时时间,则所有消费端都无需设置,可通过注册中心传递给消费端,这样:一方面简化了配置,另一方面因为服务端更清楚自己的接口性能,所以交给服务端进行设置也算合理。
dubbo 支持非常细粒度的超时设置,包括:方法级别、接口级别和全局。如果各个级别同时配置了,优先级为:消费端方法级 > 服务端方法级 > 消费端接口级 > 服务端接口级 >消费端全局 > 服务端全局。
服务端的超时设置并不会影响实际的调用过程,就算超时也会执行完整个处理逻辑。
消费端的超时逻辑同时受到超时时间和超时次数两个参数的控制,像网络异常、响应超时等都会一直重试,直到达到重试次数。
RPC 框架的超时重试机制的目的:
从微服务架构这个宏观角度来说,它是为了确保服务链路的稳定性,提供了一种框架级的容错能力。
微观上:
1)、consumer 调用 provider,如果不设置超时时间,则consumer的响应时间肯定会大于 provider 的响应时间。当provider性能变差时,consumer的性能也会受到影响,因为它必须无限期地等待 provider的返回。假如整个调用链路经过了 A、B、C、D 多个服务,只要 D 的性能变差,就会自下而上影响到 A、B、C,最终造成整个链路超时甚至瘫痪,因此设置超时时间是非常有必要的。
2)、假设 consumer 是核心的商品服务,provider 是非核心的评论服务,当评价服务出现性能问题时,商品服务可以接受不返回评价信息,从而保证能继续对外提供服务。这样情况下,就必须设置一个超时时间,当评价服务超过这个阈值时,商品服务不用继续等待。
3)、provider 很有可能是因为某个瞬间的网络抖动或者机器高负载引起的超时,如果超时后直接放弃,某些场景会造成业务损失(比如库存接口超时会导致下单失败)。因此,对于这种临时性的服务抖动,如果在超时后重试一下是可以挽救的,所以有必要通过重试机制来解决。
引入超时重试机制后,问题解决。但它同样会带来副作用,这些是开发RPC接口必须要考虑,同时也是最容易忽视的问题:
1)、重复请求:有可能provider执行完了,但是因为网络抖动consumer认为超时了,这种情况下重试机制就会导致重复请求,从而带来脏数据问题,因此服务端必须考虑接口的幂等性。
2)、降低consumer的负载能力:如果provider并不是临时性的抖动,而是确实存在性能问题,这样重试多次也是没法成功的,反而会使得consumer的平均响应时间变长。比如正常情况下provider的平均响应时间是1s,consumer将超时时间设置成1.5s,重试次数设置为2次,这样单次请求将耗时3s,consumer的整体负载就会被拉下来,如果consumer是一个高QPS的服务,还有可能引起连锁反应造成雪崩。
3)、爆炸式的重试风暴:假如一条调用链路经过了4个服务,最底层的服务D出现超时,这样上游服务都将发起重试,假设重试次数都设置的3次,那么B将面临正常情况下3倍的负载量,C是9倍,D是27倍,整个服务集群可能因此雪崩。
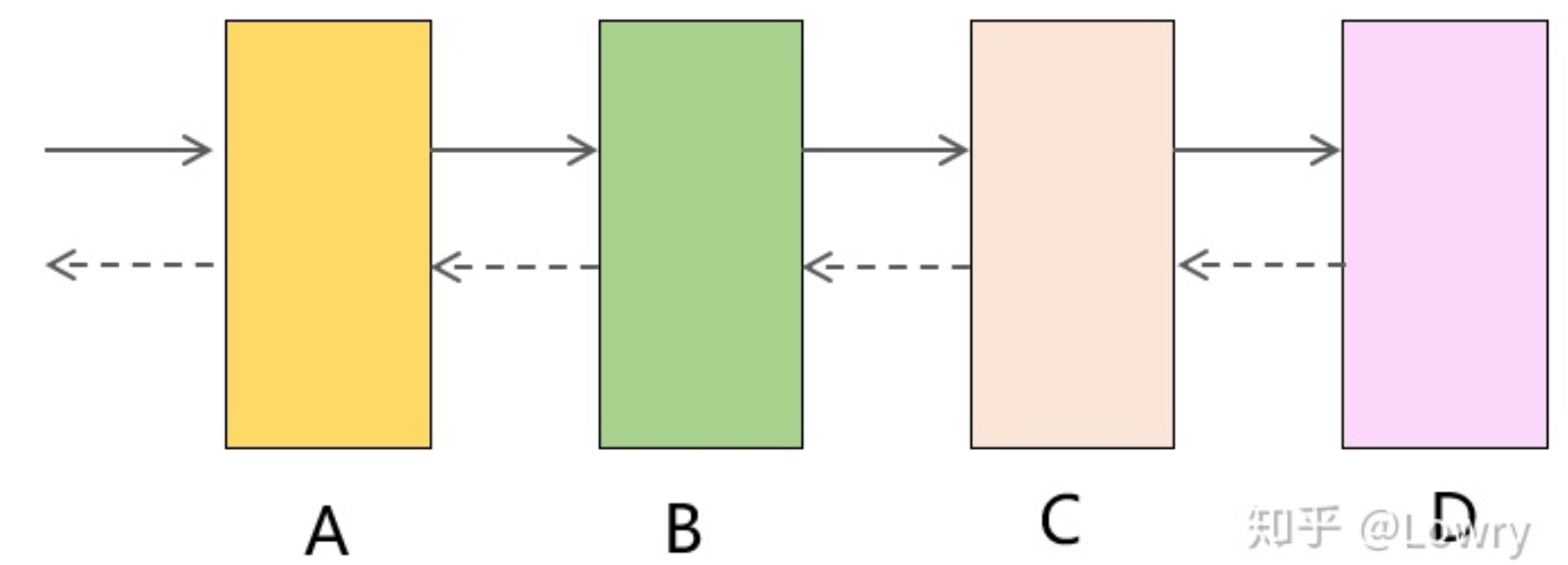
设置合理的超时时间:
1)、设置调用方的超时时间之前,先了解清楚依赖服务的 TP99 响应时间是多少(如果依赖服务性能波动大,也可以看 TP95),调用方的超时时间可以在此基础上加50%
2)、如果 RPC框架支持多粒度的超时设置,则:全局超时时间应该要略大于接口级别最长的耗时时间,每个接口的超时时间应该要略大于方法级别最长的耗时时间,每个方法的超时时间应该要略大于实际的方法执行时间
3)、区分是可重试服务还是不可重试服务,如果接口没实现幂等则不允许设置重试次数。注意:读接口是天然幂等的,写接口则可以使用业务单据 ID 或者在调用方生成唯一 ID 传递给服务端,通过此 ID 进行防重避免引入脏数据
4)、如果 RPC 框架支持服务端的超时设置,同样基于前面 3 条规则依次进行设置,这样能避免客户端不设置的情况下配置是合理的,减少隐患
5)、如果从业务角度来看,服务可用性要求不用那么高(比如偏内部的应用系统),则可以不用设置超时重试次数,直接人工重试即可,这样能减少接口实现的复杂度,反而更利于后期维护
6)、重试次数设置越大,服务可用性越高,业务损失也能进一步降低,但是性能隐患也会更大,这个需要综合考虑设置成几次(一般是2次,最多3次)
7)、如果调用方是高QPS服务,则必须考虑服务方超时情况下的降级和熔断策略。(比如超过10%的请求出错,则停止重试机制直接熔断,改成调用其他服务、异步MQ机制、或者使用调用方的缓存数据)
5 问题总结
RPC 接口的超时设置看似简单,实际上有很大学问。不仅涉及到很多技术层面的问题(比如接口幂等、服务降级和熔断、性能评估和优化),同时还需要从业务角度评估必要性。
2.3 案例三:FGC问题排查
线上服务的GC问题,是Java程序非常典型的一类问题,非常考验工程师排查问题的能力。同时,几乎是面试必考题,但是能真正答好此题的人并不多,要么原理没吃透,要么缺乏实战经验。
系统出现了多次和GC相关的线上问题,有Full GC过于频繁的,有Young GC耗时过长的,这些问题带来的影响是:GC过程中的程序卡顿,进一步导致服务超时从而影响业务稳定。
1.FGC频繁的案例
1.问题调查和原因分析
- 第1步:通过以下命令查看JVM的启动参数:ps aux | grep "applicationName=adsearch"
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:ParallelGCThreads=5 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFraction=80
可以看到堆内存为 4G,新生代为 2G,老年代也为 2G,新生代采用 ParNew 收集器,老年代采用并发标记清除的 CMS 收集器,当老年代的内存占用率达到 80% 时会进行FGC。
进一步通过 jmap -heap 7276 | head -n20 可以得知新生代的 Eden 区为1.6G,S0 和S1 区均为0.2G。
第2步:通过观察老年代的使用情况,可以看到:每次FGC后,内存都能回到500M左右,因此我们排除了内存泄漏的情况。
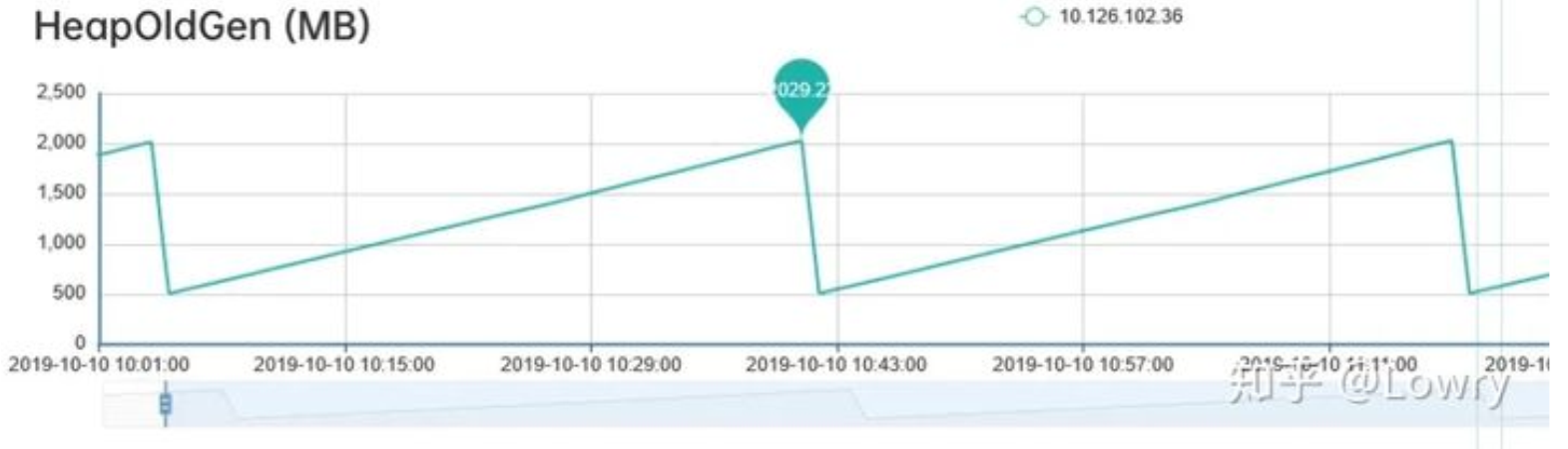
第3步:通过jmap命令查看堆内存中的对象,通过命令 jmap -histo 144677 | head -n20
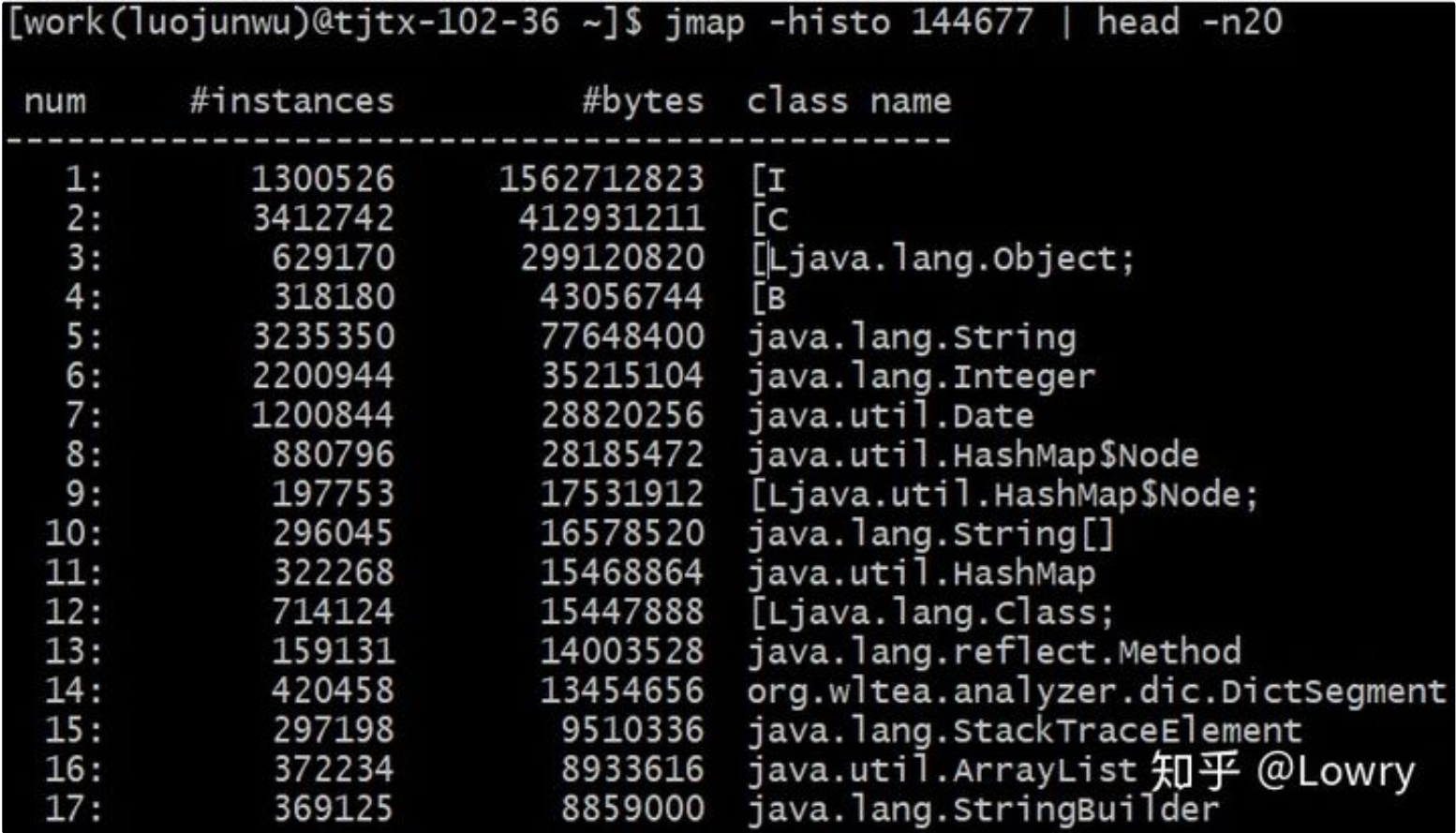
可以看到排名第一的是:int[],而且所占内存大小远远超过其他存活对象。至此,我们将怀疑目标锁定在了 int[]。
第4步:进一步dump堆内存文件进行分析。锁定 int[] 后,我们打算 dump 堆内存文件,通过可视化工具进一步跟踪对象的来源。考虑堆转储过程中会暂停程序,因此我们先从服务管理平台摘掉了此节点,然后通过以下命令 dump 堆内存:
jmap -dump:format=b,file=heap 7276
通过 JVisualVM 工具导入 dump 出来的堆内存文件,同样可以看到各个对象所占空间,其中 int[] 占到了 50% 以上的内存,进一步往下便可以找到 int[] 所属的业务对象。
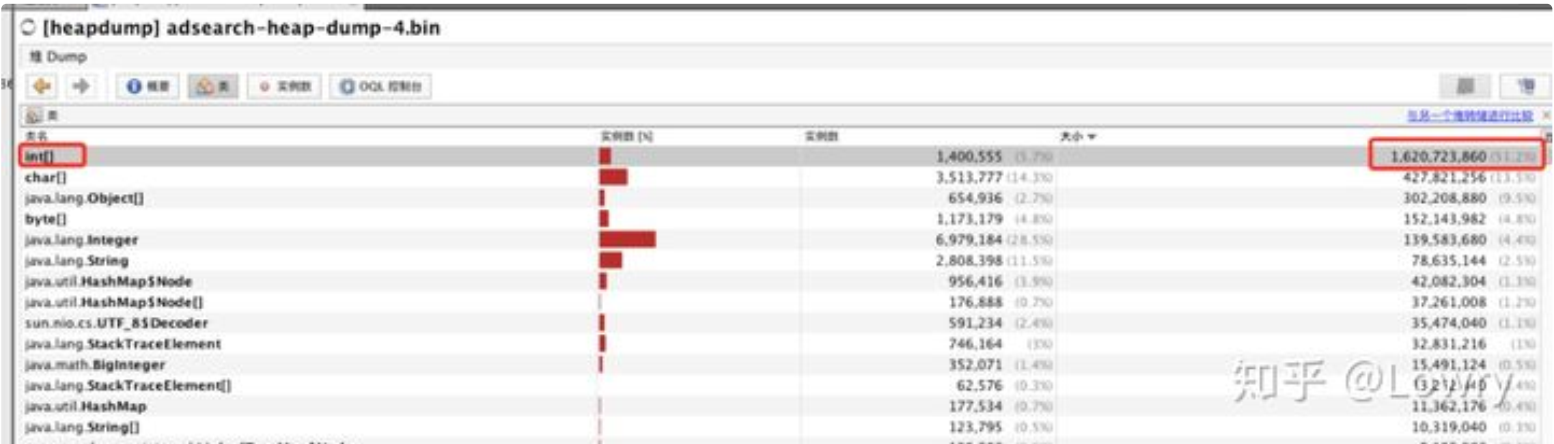
第5步:通过代码分析,每分钟会生成约 40M大小的 int数组,用于统计TP99和TP90,数组的生命周期是一分钟。而根据第2步观察老年代的内存变化时,发现老年代的内存基本上也是每分钟增加40多M,因此推断:这40M的int数组应该是从新生代晋升到老年代。
进一步查看了YGC的频次监控,看到大概1分钟有8次左右的YGC,这样基本验证了我们的推断:因为 CMS 收集器默认的分代年龄是6次,即YGC 6次后还存活的对象就会晋升到老年代,而大数组生命周期是1分钟,刚好满足这个要求。
2.解决方案
将CMS收集器的分代年龄改成了15次,改完后FGC频次恢复到了2天一次,后续如果YGC的频次超过每分钟15次还会再次触发此问题。
根本的解决方案是:优化程序以降低YGC的频率,同时缩短codis组件中int数组的生命周期。
2 GC的运行原理介绍
1.堆内存结构
GC 分为 YGC 和 FGC,它们均发生在 JVM 的堆内存上。
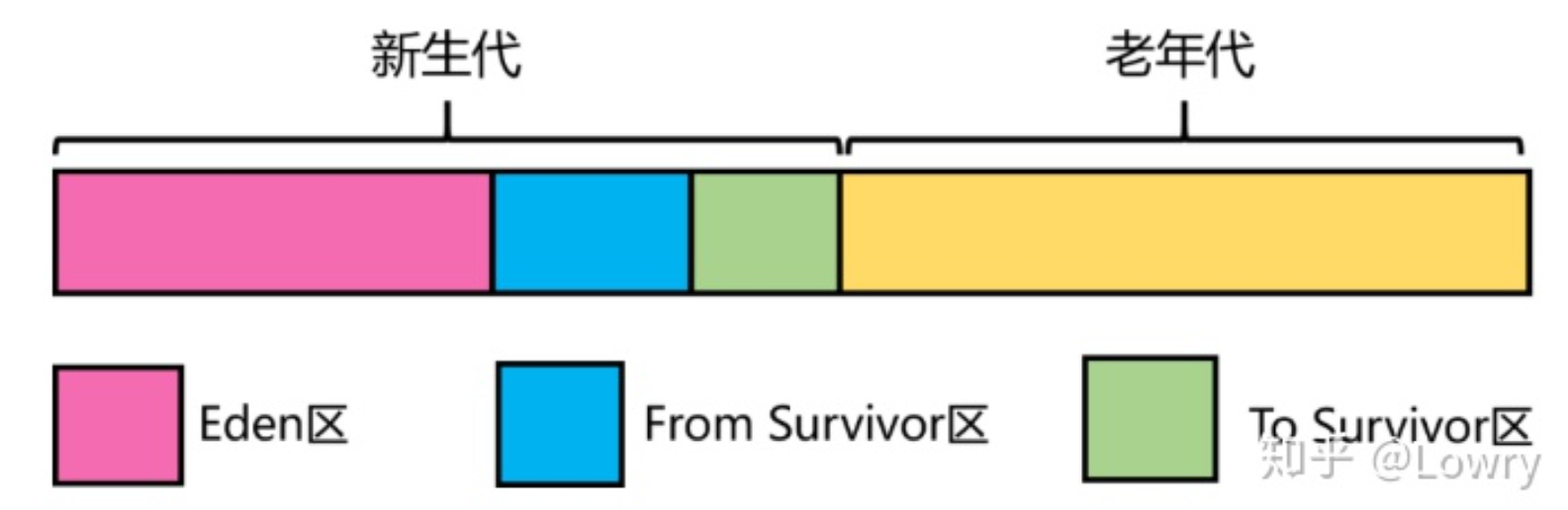
JDK8的堆内存结构
堆内存采用了分代结构,包括新生代和老年代。新生代又分为:Eden区,From Survivor区(简称S0),To Survivor区(简称S1区),三者的默认比例为8:1:1。另外,新生代和老年代的默认比例为1:2。
堆内存之所以采用分代结构,是考虑到绝大部分对象都是短生命周期的,这样不同生命周期的对象可放在不同的区域中,然后针对新生代和老年代采用不同的垃圾回收算法,从而使得GC效率最高。
2. YGC是什么时候触发的?
大多数情况下,对象直接在年轻代中的Eden区进行分配,如果Eden区域没有足够的空间,那么就会触发YGC(Minor GC),YGC处理的区域只有新生代。因为大部分对象在短时间内都是可收回掉的,因此YGC后只有极少数的对象能存活下来,而被移动到S0区(采用的是复制算法)。
当触发下一次YGC时,会将Eden区和S0区的存活对象移动到S1区,同时清空Eden区和S0区。当再次触发YGC时,这时候处理的区域就变成了Eden区和S1区(即S0和S1进行角色交换)。每经过一次YGC,存活对象的年龄就会加1。
3. FGC是什么时候触发的?
下面4种情况,对象会进入到老年代中:
1)、YGC时,To Survivor区不足以存放存活的对象,对象会直接进入到老年代。
2)、经过多次YGC后,如果存活对象的年龄达到了设定阈值,则会晋升到老年代中。
3)、动态年龄判定规则,To Survivor区中相同年龄的对象,如果其大小之和占到了To Survivor区一半以上的空间,那么大于此年龄的对象会直接进入老年代,而不需要达到默认的分代年龄。
4)、大对象:由-XX:PretenureSizeThreshold启动参数控制,若对象大小大于此值,就会绕过新生代, 直接在老年代中分配。
当晋升到老年代的对象大于了老年代的剩余空间时,就会触发FGC(Major GC),FGC处理的区域同时包括新生代和老年代。
除此之外,还有以下4种情况也会触发FGC:
1)、老年代的内存使用率达到了一定阈值(可通过参数调整),直接触发FGC。
2)、空间分配担保:在YGC之前,会先检查老年代最大可用的连续空间是否大于新生代所有对象的总空间。如果小于,说明YGC是不安全的,则会查看参数HandlePromotionFailure 是否被设置成了允许担保失败,如果不允许则直接触发Full GC;如果允许,那么会进一步检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果小于也会触发 Full GC。
3)、Metaspace(元空间)在空间不足时会进行扩容,当扩容到了-XX:MetaspaceSize 参数的指定值时,也会触发FGC。
4)、System.gc() 或者Runtime.gc() 被显式调用时,触发FGC。
4. 在什么情况下,GC会对程序产生影响?
不管YGC还是FGC,都会造成一定程度的程序卡顿(即Stop The World问题:GC线程开始工作,其他工作线程被挂起),即使采用ParNew、CMS或者G1这些更先进的垃圾回收算法,也只是在减少卡顿时间,而并不能完全消除卡顿。
根据GC对程序产生影响的严重程度从高到底,包括以下4种情况:
1)、FGC过于频繁:FGC通常是比较慢的,正常情况FGC每隔几个小时甚至几天才执行一次,对系统的影响还能接受。但是,一旦出现FGC频繁(比如几十分钟就会执行一次),这种肯定是存在问题的,它会导致工作线程频繁被停止,让系统看起来一直有卡顿现象,也会使得程序的整体性能变差。
2)、YGC耗时过长:一般来说,YGC的总耗时在几十或者上百毫秒是比较正常的,虽然会引起系统卡顿几毫秒或者几十毫秒,这种情况几乎对用户无感知,对程序的影响可以忽略不计。但是如果YGC耗时达到了1秒甚至几秒(都快赶上FGC的耗时了),那卡顿时间就会增大,加上YGC本身比较频繁,就会导致比较多的服务超时问题。
3)、FGC耗时过长:FGC耗时增加,卡顿时间也会随之增加,尤其对于高并发服务,可能导致FGC期间比较多的超时问题,可用性降低,这种也需要关注。
4)、YGC过于频繁:即使YGC不会引起服务超时,但是YGC过于频繁也会降低服务的整体性能,对于高并发服务也是需要关注的。
其中,「FGC过于频繁」和「YGC耗时过长」,这两种情况属于比较典型的GC问题,大概率会对程序的服务质量产生影响。剩余两种情况的严重程度低一些,但是对于高并发或者高可用的程序也需要关注。
3 排查FGC问题的实践指南
1. 清楚从程序角度,有哪些原因导致FGC?
1)、大对象:系统一次性加载了过多数据到内存中(比如SQL查询未做分页),导致大对象进入了老年代。
2)、内存泄漏:频繁创建了大量对象,但是无法被回收(比如IO对象使用完后未调用close方法释放资源),先引发FGC,最后导致OOM.
3)、程序频繁生成一些长生命周期的对象,当这些对象的存活年龄超过分代年龄时便会进入老年代,最后引发FGC. (即本文中的案例)
4)、程序BUG导致动态生成了很多新类,使得 Metaspace 不断被占用,先引发FGC,最后导致OOM.
5)、代码中显式调用了gc方法,包括自己的代码甚至框架中的代码。
6)、JVM参数设置问题:包括总内存大小、新生代和老年代的大小、Eden区和S区的大小、元空间大小、垃圾回收算法等等。
2. 清楚排查问题时能使用哪些工具
1)、公司的监控系统:大部分公司都会有,可全方位监控JVM的各项指标。
2)、JDK的自带工具,包括jmap、jstat等常用命令:
查看堆内存各区域的使用率以及GC情况 jstat -gcutil -h20 pid 1000 查看堆内存中的存活对象,并按空间排序 jmap -histo pid | head -n20 dump堆内存文件 jmap -dump:format=b,file=heap pid
3)、可视化的堆内存分析工具:JVisualVM、MAT等
3. 排查指南
1)、查看监控,以了解出现问题的时间点以及当前FGC的频率(可对比正常情况看频率是否正常)
2)、了解该时间点之前有没有程序上线、基础组件升级等情况。
3)、了解JVM的参数设置,包括:堆空间各个区域的大小设置,新生代和老年代分别采用了哪些垃圾收集器,然后分析JVM参数设置是否合理。
4)、再对步骤1中列出的可能原因做排除法,其中元空间被打满、内存泄漏、代码显式调用gc方法比较容易排查。
5)、针对大对象或者长生命周期对象导致的FGC,可通过 jmap -histo 命令并结合dump堆内存文件作进一步分析,需要先定位到可疑对象。
6)、通过可疑对象定位到具体代码再次分析,这时候要结合GC原理和JVM参数设置,弄清楚可疑对象是否满足了进入到老年代的条件才能下结论。
2.4 案例四:YGC问题排查
2.4.1 案例分析过程
问题现象:服务超时量突然大面积增加,1分钟内甚至达到了上千次接口超时。
1.查看监控
发现YoungGC耗时过长的异常。由于 YGC期间程序会 Stop The World ,而我们上游系统设置的服务超时时间都在几百毫秒,因此推断:是因为YGC耗时过长引发了服务大面积超时。
通过jmap命令dump了堆内存文件用来保留现场,jmap -dump:format=b,file=heap pid ,最后对线上服务做了回滚处理。
jmap -dump:format=b,file=server.txt 21993
2.检查JVM的参数
堆内存为4G,新生代和老年代均为2G,新生代采用ParNew收集器。通过命令 jmap -heap pid 查到:新生代的Eden区为1.6G,S0和S1区均为0.2G。本次上线并未修改JVM相关的任何参数,同时我们服务的请求量基本和往常持平。因此,此问题大概率和上线的代码相关。
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:ParallelGCThreads=5 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC-XX:+UseCMSCompactAtFullCollection -XX:CMSInitiatingOccupancyFraction=80
3.检查代码
回到YGC的原理,一次YGC的过程主要包括两个步骤:
1)、从GC Root扫描对象,对存活对象进行标注
2)、将存活对象复制到S1区或者晋升到Old区
根据监控图可以看出:正常情况下,Survivor区的使用率一直维持在很低的水平(大概30M左右),但上线后,Survivor区的使用率开始波动,最多的时候快占满0.2G。而且,YGC耗时和Survivor区的使用率基本成正相关。因此我们推测:应该是长生命周期的对象越来越多,导致标注和复制过程的耗时增加。
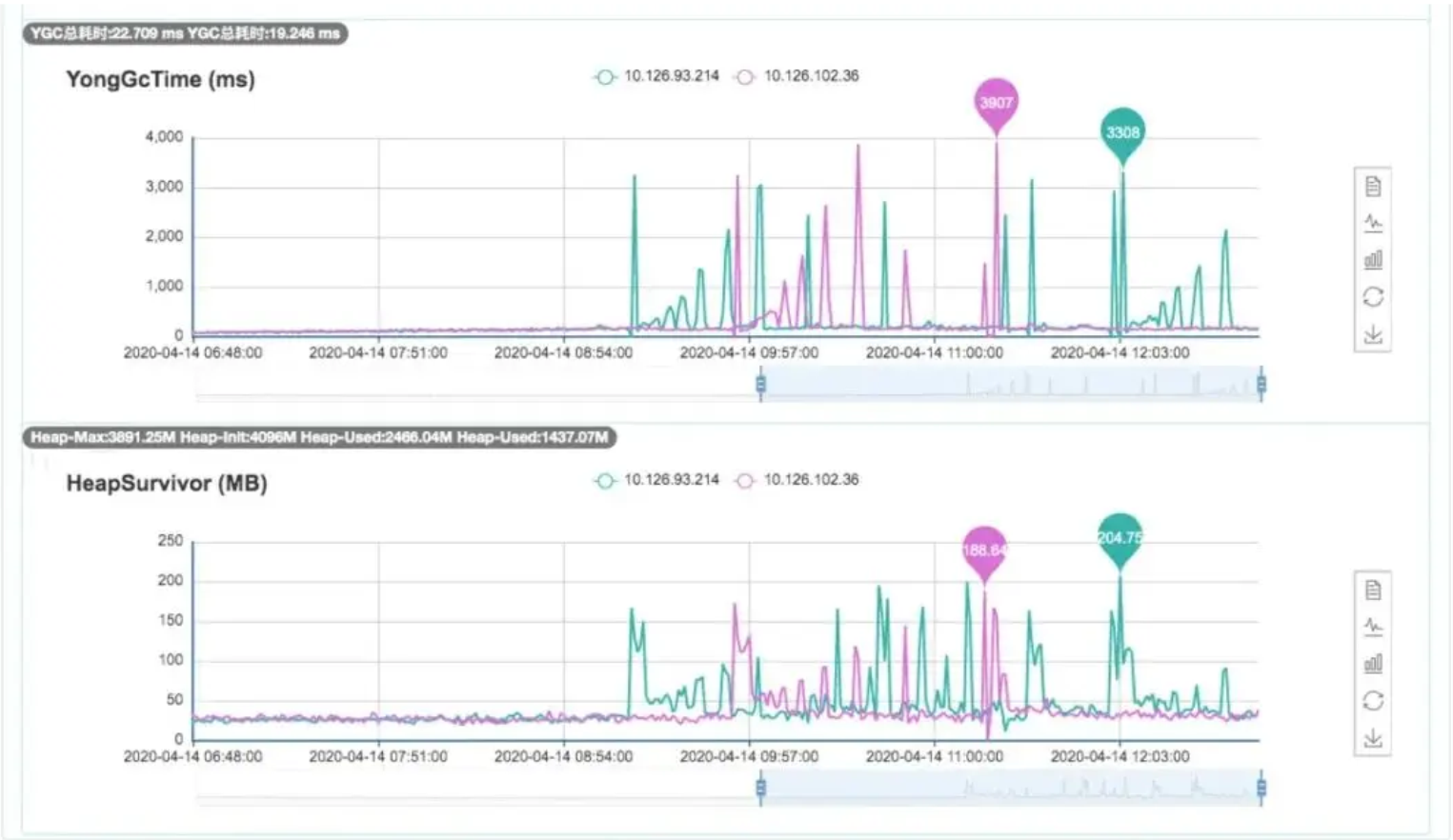
回到服务的表现:上游流量并没有出现明显变化,核心接口的响应时间也基本在200ms以内,YGC的频率大概每8秒进行1次。
进一步将怀疑对象锁定在:程序的全局变量或者类静态变量上。但是diff了本次上线的代码,并未发现代码中有引入此类变量。
4.对dump的堆内存文件进行分析
代码排查没有进展后,我们开始从堆内存文件中寻找线索,使用MAT工具导入dump出来的堆文件后,然后通过Dominator Tree视图查看到了当前堆中的所有大对象。
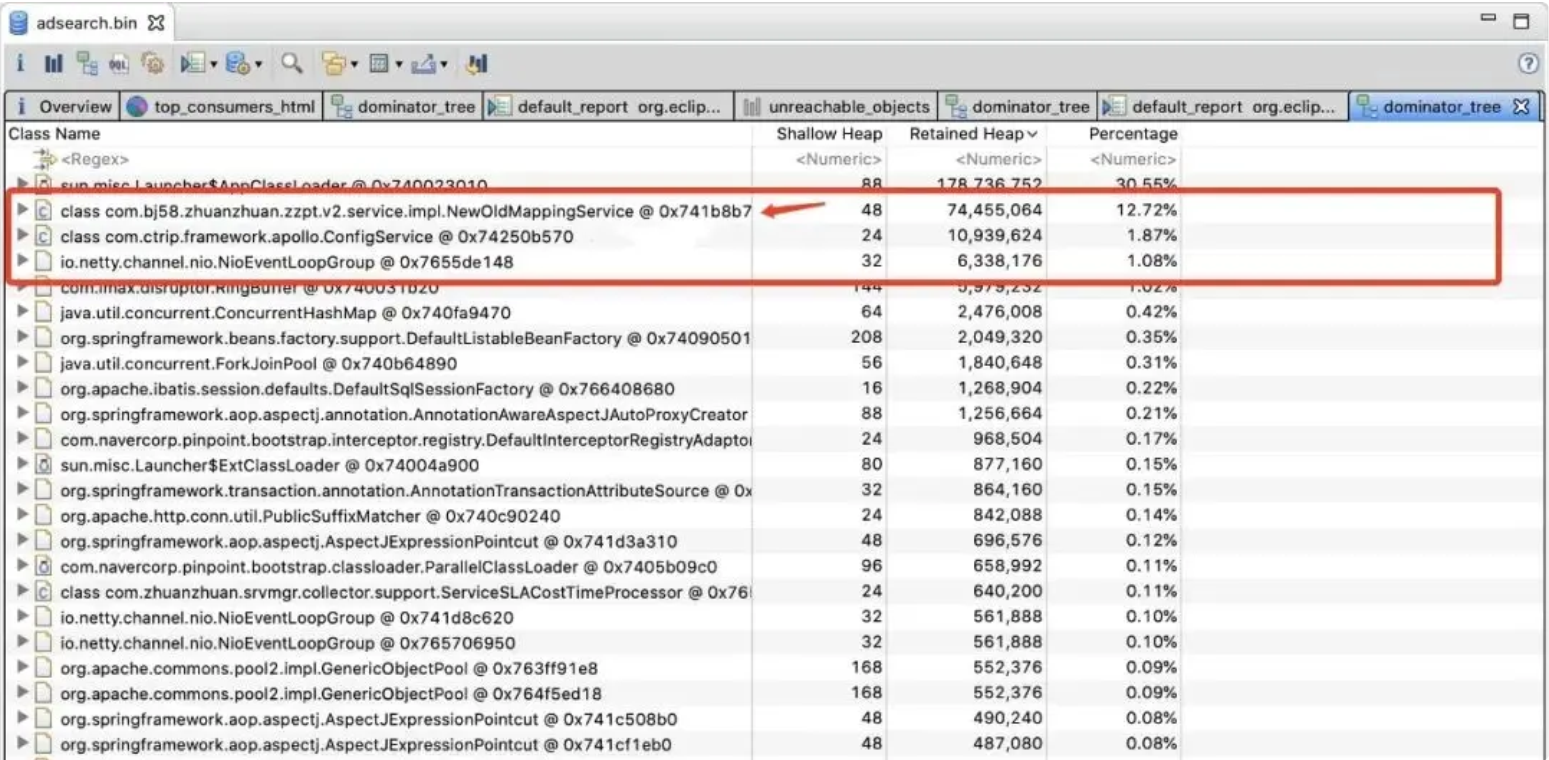
立马发现NewOldMappingService这个类所占的空间很大,发现这个类中存在大量的静态HashMap,用于缓存新旧类目转换时需要用到的各种数据,以减少RPC调用,提高转换性能。但是深入排查发现:这个类的所有静态变量全部在类加载时就初始化完数据了,虽然会占到100多M的内存,但是之后基本不会再新增数据。并且,这个类早在3月份就上线使用了,版本也一直没变过。
经过种种分析,这个类的静态HashMap会一直存活,经过多轮YGC后,最终晋升到老年代中,它不应该是YGC持续耗时过长的原因。
5.分析YGC处理Reference的耗时
发现YGC问题的原因基本集中在这两类上:
1)、对存活对象标注时间过长:比如重载了Object类的Finalize方法,导致标注FinalReference耗时过长;或者String.intern方法使用不当,导致YGC扫描StringTable时间过长。
2)、长周期对象积累过多:比如本地缓存使用不当,积累了太多存活对象;或者锁竞争严重导致线程阻塞,局部变量的生命周期变长。
针对第1类问题,可以通过以下参数显示GC处理Reference的耗时-XX:+PrintReferenceGC。 添加此参数后,可以看到不同类型的 reference 处理耗时都很短,因此又排除了此项因素。

6. 再回到长周期对象进行分析
最终峰回路转,重新从MAT堆内存中找到了第二个怀疑点。
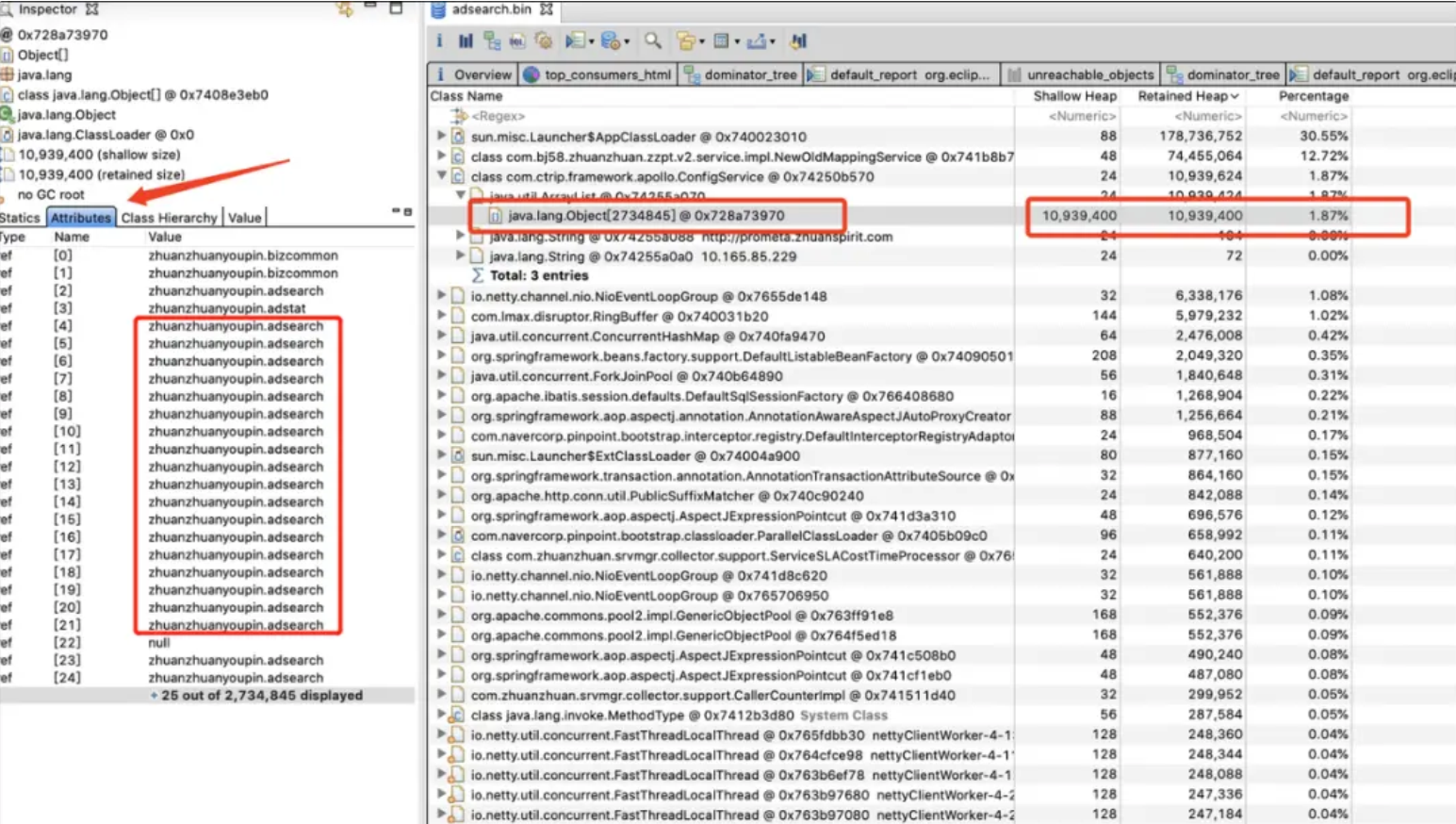
可以看到,大对象中排在第3位的ConfigService类进入了我们的视野,该类的一个ArrayList变量中竟然包含了270W个对象,而且大部分都是相同的元素。通过代码可以看出,每次调用getConfig方法时都会往List中添加元素,并且未做去重处理,从而引发此问题。至此,整个问题终于水落石出了。
这个BUG是因为架构部在对apollo client包进行定制化开发时不小心引入的,并且刚好在上线前一天发布到了中央仓库中,而公司基础组件库的版本是通过super-pom方式统一维护的,业务无感知。
7. 解决方案
用旧版本的apollo client包进行了替换,然后重启了服务,观察了将近20分钟,YGC恢复正常。最后修复BUG,重新发布了super-pom,彻底解决了这个问题。
2.4.2 YGC的相关知识点总结
1.重新认识新生代
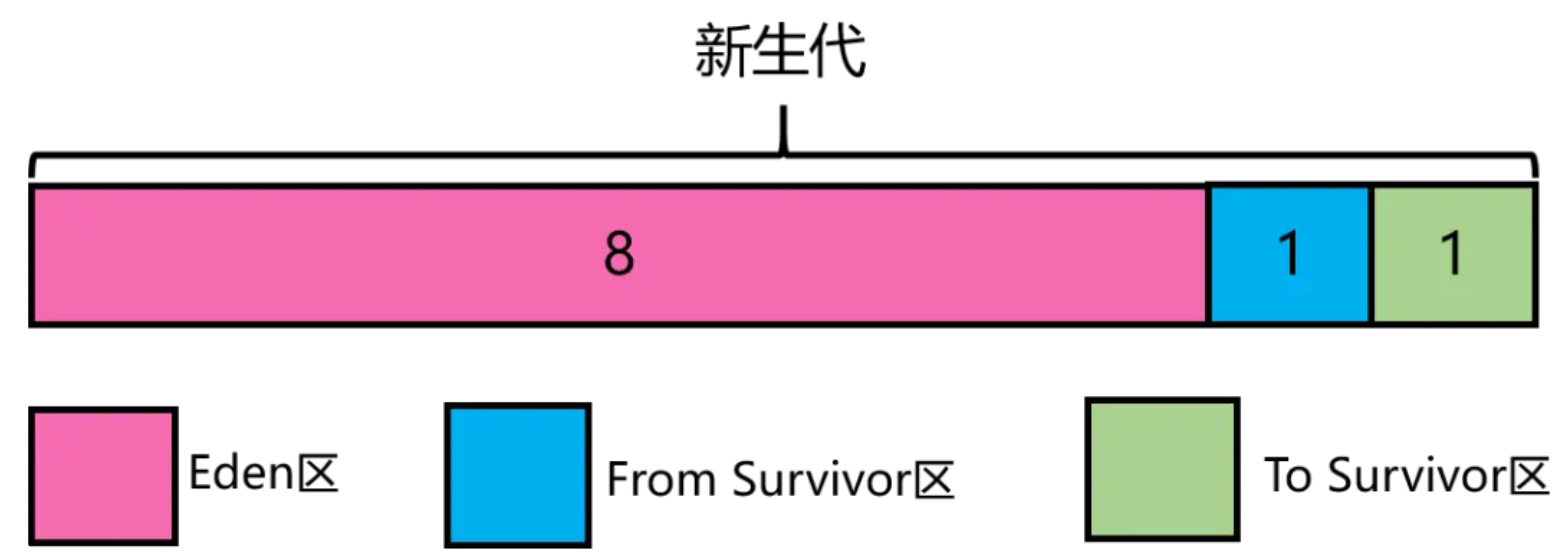
YGC在新生代中进行,新生代分为Eden区和两个Survivor区,其中Eden:from:to = 8:1:1 (比例可以通过参数 –XX:SurvivorRatio 来设定)。
为什么会有新生代?
如果不分代,所有对象全部在一个区域,每次GC都需要对全堆进行扫描,存在效率问题。分代后,可分别控制回收频率,并采用不同的回收算法,确保GC性能全局最优。
为什么新生代会采用复制算法?
新生代的对象朝生夕死,大约90%的新建对象可以被很快回收,复制算法成本低,同时还能保证空间没有碎片。虽然标记整理算法也可以保证没有碎片,但是由于新生代要清理的对象数量很大,将存活的对象整理到待清理对象之前,需要大量的移动操作,时间复杂度比复制算法高。
为什么新生代需要两个Survivor区?
为了节省空间考虑,如果采用传统的复制算法,只有一个Survivor区,则Survivor区大小需要等于Eden区大小,此时空间消耗是8 * 2,而两块Survivor可以保持新对象始终在Eden区创建,存活对象在Survivor之间转移即可,空间消耗是8+1+1,明显后者的空间利用率更高。
新生代的实际可用空间是多少?
YGC后,总有一块Survivor区是空闲的,因此新生代的可用内存空间是90%。在YGC的log中或者通过 jmap -heap pid 命令查看新生代的空间时,如果发现capacity只有90%,不要觉得奇怪。
Eden区是如何加速内存分配的?
HotSpot虚拟机使用了两种技术来加快内存分配。分别是bump-the-pointer和TLAB(Thread Local Allocation Buffers)。
由于Eden区是连续的,因此bump-the-pointer在对象创建时,只需要检查最后一个对象后面是否有足够的内存即可,从而加快内存分配速度。
TLAB技术是对于多线程而言的,在Eden中为每个线程分配一块区域,减少内存分配时的锁冲突,加快内存分配速度,提升吞吐量。
2. 新生代的4种回收器
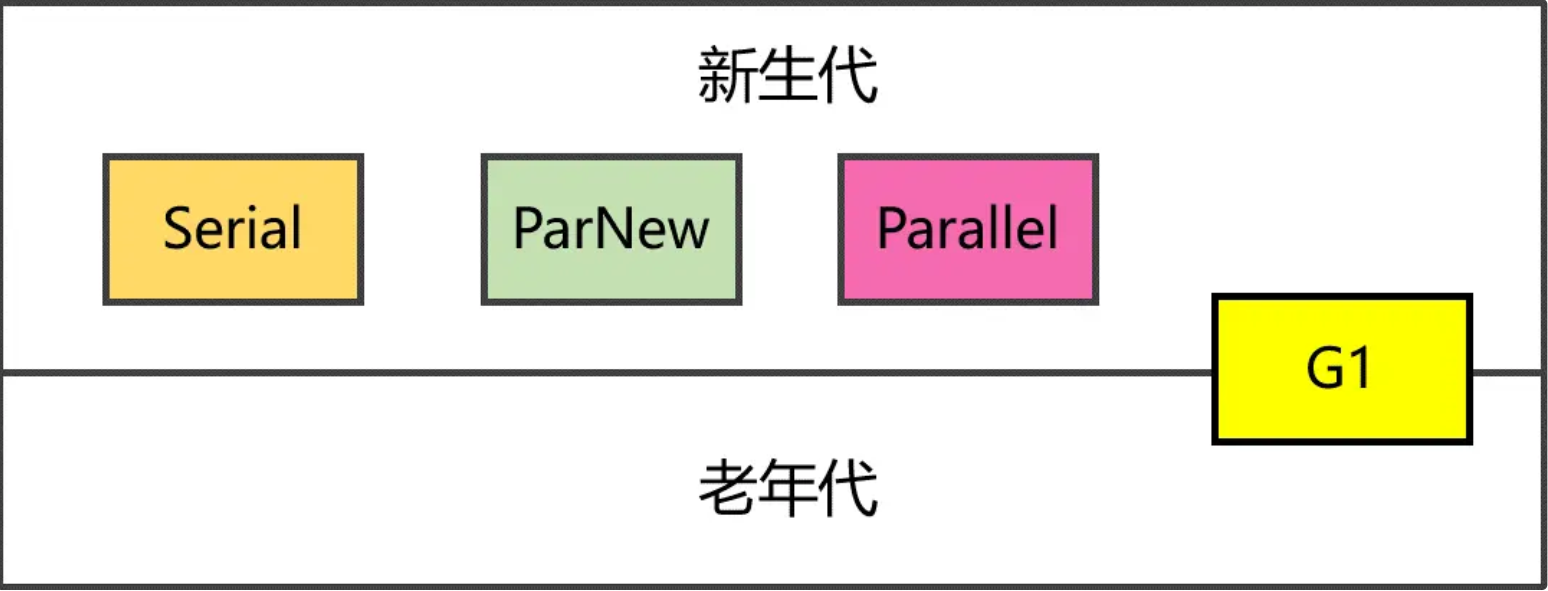
SerialGC(串行回收器),最古老的一种,单线程执行,适合单CPU场景。
ParNew(并行回收器),将串行回收器多线程化,适合多CPU场景,需要搭配老年代CMS回收器一起使用。
ParallelGC(并行回收器),和ParNew不同点在于它关注吞吐量,可设置期望的停顿时间,它在工作时会自动调整堆大小和其他参数。
G1(Garage-First回收器),JDK 9及以后版本的默认回收器,兼顾新生代和老年代,将堆拆成一系列Region,不要求内存块连续,新生代仍然是并行收集。
上述回收器均采用复制算法,都是独占式的,执行期间都会Stop The World。
3. YGC的触发时机
当Eden区空间不足时,就会触发YGC。结合新生代对象的内存分配看下详细过程:
1)、新对象会先尝试在栈上分配,如果不行则尝试在TLAB分配,否则再看是否满足大对象条件要在老年代分配,最后才考虑在Eden区申请空间。
2)、如果Eden区没有合适的空间,则触发YGC。
3)、YGC时,对Eden区和From Survivor区的存活对象进行处理,如果满足动态年龄判断的条件或者To Survivor区空间不够则直接进入老年代,如果老年代空间也不够了,则会发生promotion failed,触发老年代的回收。否则将存活对象复制到ToSurvivor区。
4)、此时Eden区和From Survivor区的剩余对象均为垃圾对象,可直接抹掉回收。
此外,老年代如果采用的是CMS回收器,为了减少CMS Remark阶段的耗时,也有可能会触发一次YGC。
4. YGC的执行过程
YGC采用的复制算法,主要分成以下两个步骤:
1)、查找GC Roots,将其引用的对象拷贝到S1区。
2)、递归遍历第1步的对象,拷贝其引用的对象到S1区或者晋升到Old区。
上述整个过程都是需要暂停业务线程的(STW),不过ParNew等新生代回收器可以多线程并行执行,提高处理效率。YGC通过可达性分析算法,从GC Root(可达对象的起点)开始向下搜索,标记出当前存活的对象,那么剩下未被标记的对象就是需要回收的对象。
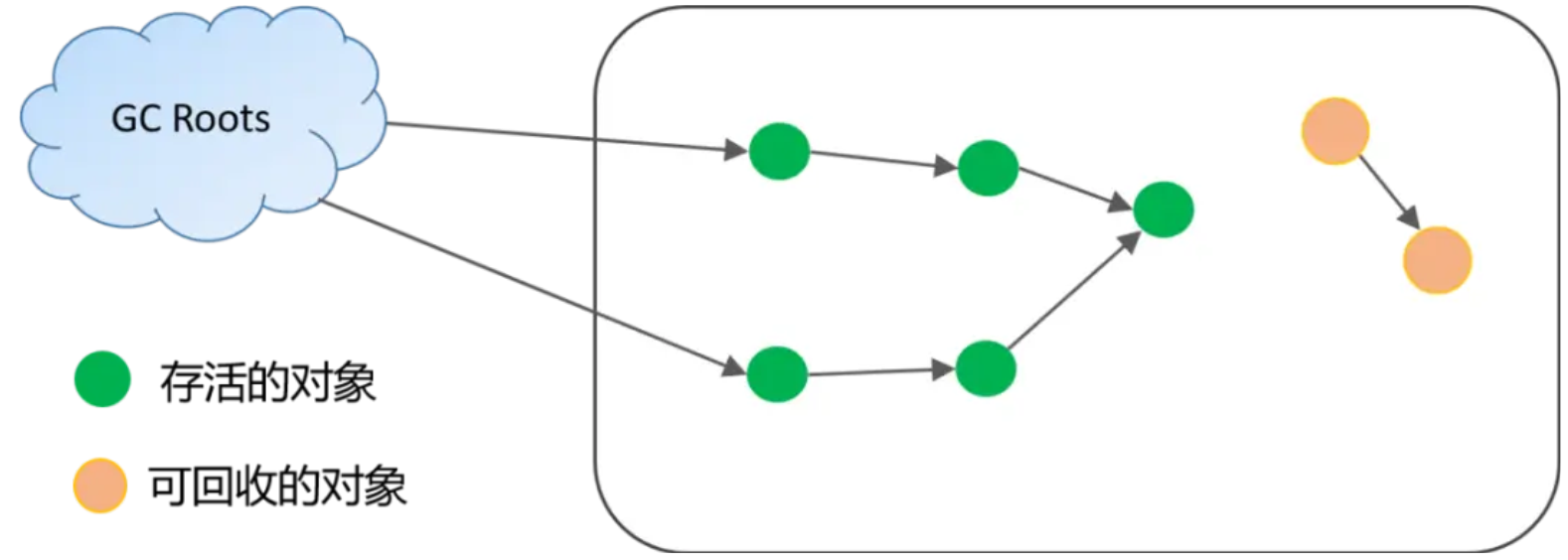
可作为YGC时GC Root的对象包括以下几种:
1)、虚拟机栈中引用的对象
2)、方法区中静态属性、常量引用的对象
3)、本地方法栈中引用的对象
4)、被Synchronized锁持有的对象
5)、记录当前被加载类的SystemDictionary
6)、记录字符串常量引用的StringTable
7)、存在跨代引用的对象
8)、和GC Root处于同一CardTable的对象
另外,针对下图中跨代引用的情况,老年代的对象A也必须作为GC Root的一部分,但如果每次YGC时都去扫描老年代,肯定存在效率问题。在HotSpot JVM,引入卡表(Card Table)来对跨代引用的标记进行加速。
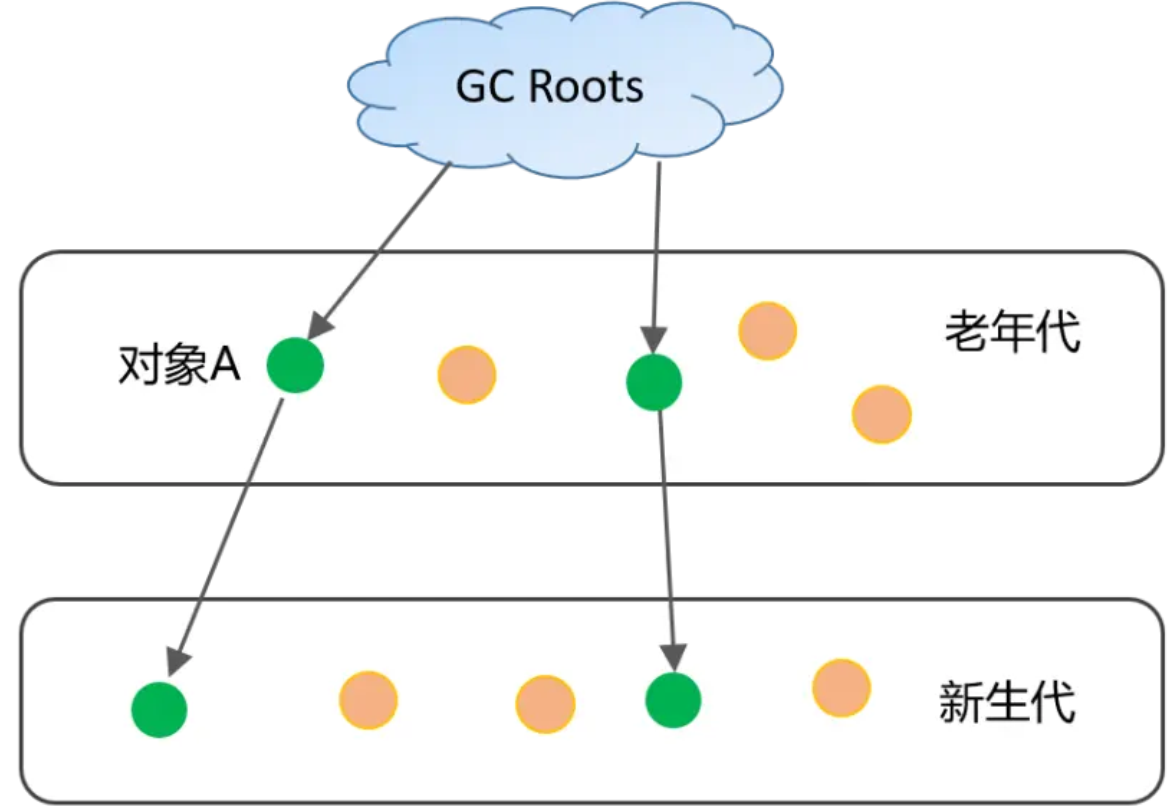
Card Table,简单理解是一种空间换时间的思路,因为存在跨代引用的对象大概占比不到1%,因此可将堆空间划分成大小为512字节的卡页,如果卡页中有一个对象存在跨代引用,则可以用1个字节来标识该卡页是dirty状态,卡页状态进一步通过写屏障技术进行维护。
遍历完GC Roots后,便能够找出第一批存活的对象,然后将其拷贝到S1区。接下来,就是一个递归查找和拷贝存活对象的过程。
S1区为了方便维护内存区域,引入了两个指针变量: _saved_mark_word和_top,其中_saved_mark_word表示当前遍历对象的位置,_top表示当前可分配内存的位置,很显然,_saved_mark_word到_top之间的对象都是已拷贝但未扫描的对象。
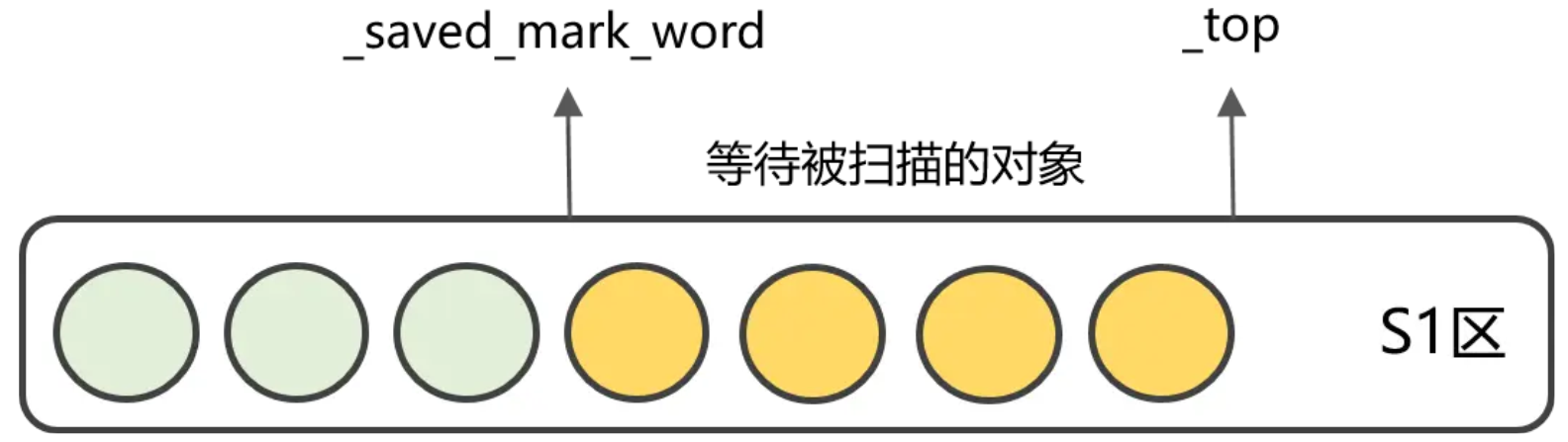
如图所示,每次扫描完一个对象,_saved_mark_word会往前移动,期间如果有新对象也会拷贝到S1区,_top也会往前移动,直到_saved_mark_word追上_top,说明S1区所有对象都已经遍历完成。
要注意的是:拷贝对象的目标空间不一定是S1区,也可能是老年代。如果一个对象的年龄(经历的YGC次数)满足动态年龄判定条件便直接晋升到老年代中。对象的年龄保存在Java对象头的mark word数据结构中。
2.4.3 总结
1、首先要清楚YGC的执行原理。
2、YGC的核心步骤是标注和复制,绝部分YGC问题都集中在这两步,因此可以结合YGC日志和堆内存变化情况逐一排查,同时d ump的堆内存文件 需要仔细分析。
3、对JVM性能调优和GC案例感兴趣,建议关注前阿里大牛「你假笨」创建的PerfMa社区,里面有很多高质量的JVM文章。
2.5 案例五:数据库中间件Bug排查
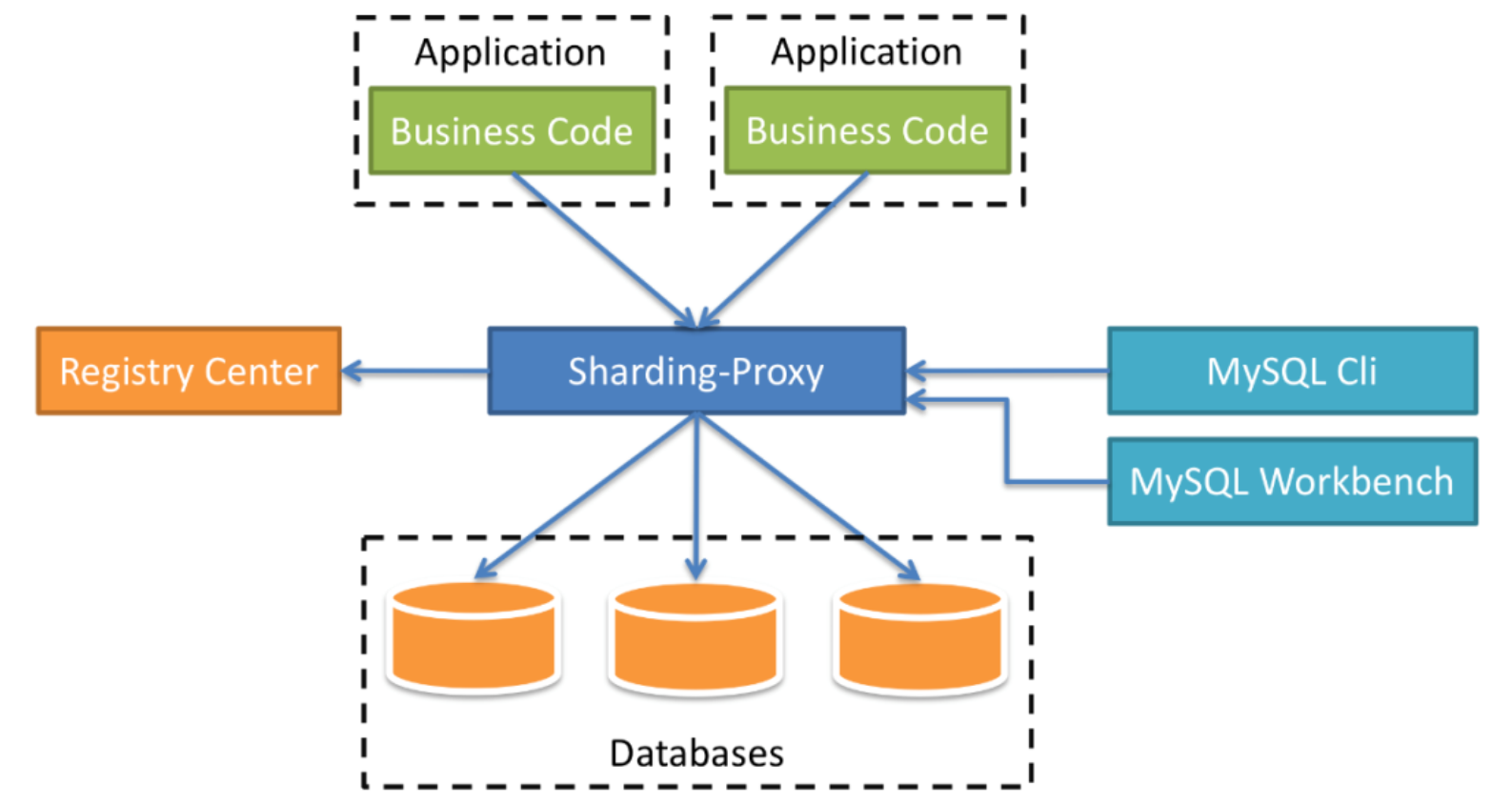
1. ShardingProxy
可以把 ShardingProxy 当做数据库代理,能用 MySQL 客户端工具(Navicat)或者命令行和它直接交互,而 ShardingProxy 内部则通过 MySQL原生协议与真实的 MySQL 服务器通信。
2. ShardingProxy 的内部架构
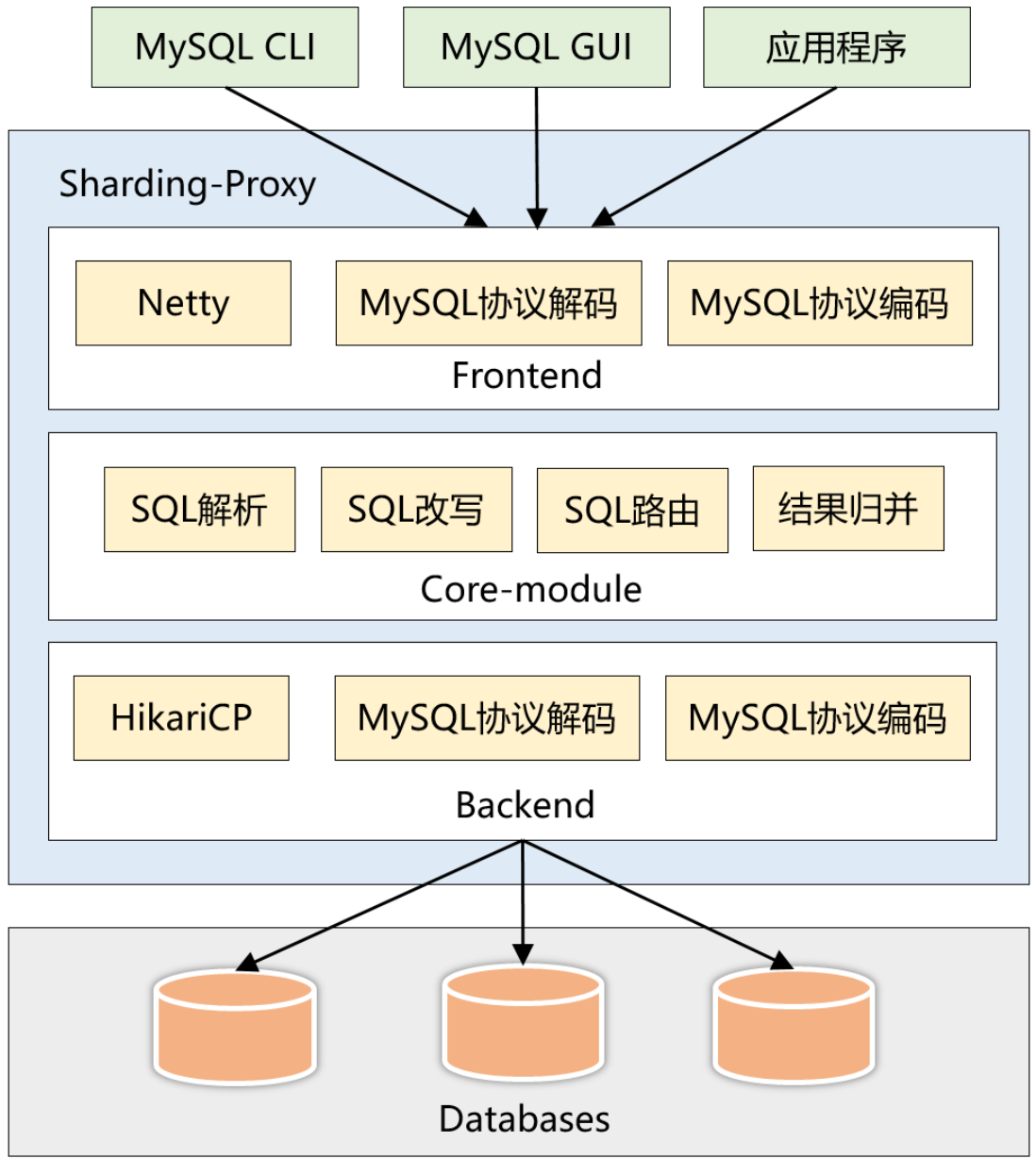
整个架构分为前端、核心组件和后端:
前端(Frontend)负责与客户端进行网络通信,采用的是 NIO 框架,在通信的过程中完成对MySQL协议的编解码。
核心组件(Core-module)得到解码的 MySQL 命令后,开始调用 Sharding-Core 对SQL 进行解析、改写、路由、归并等核心功能。
后端(Backend)与真实数据库交互,采用 Hikari 连接池,同样涉及到 MySQL 协议的编解码。
3. ShardingProxy 的预编译 SQL 功能
预编译 SQL(PreparedStatement),在数据库收到一条 SQL 到执行完毕,一般分为以下 3 步:
1)、词法和语义解析
2)、优化 SQL,制定执行计划
3)、执行并返回结果
但是很多情况下,一条 SQL 语句可能会反复执行,只是执行时的参数值不同。而预编译功能将这些值用占位符代替,最终达到一次编译、多次运行的效果,省去了解析优化等过程,能大大提高 SQL 的执行效率。
假设我们要执行下面这条 SQL 两次:
SELECT * FROM t_user WHERE user_id = 10;
那 JDBC 和 MySQL 之间的协议消息如下:

通过上述流程可以看到:
第 1 条消息是PreparedStatement,查询语句中的参数值用问号代替了,它告诉 MySQL 对这个SQL 进行预编译;
第 2 条消息 MySQL 告诉 JDBC 准备成功了;
第 3 条消息 JDBC 将参数设置为 1 ;
第 4 条消息 MySQL 返回查询结果;
第 5条和第 6 条消息表示第二次执行同样的 SQL,已经无需再次预编译了。
回到 ShardingProxy,如果需要支持预编译功能,交互流程肯定是需要变的,因为Proxy 在收到 JDBC 的PreparedStatement 命令时,SQL 里的分片键是问号,它根本不知道该路由到哪个真实数据库。
因此,流程变成了下面这样:
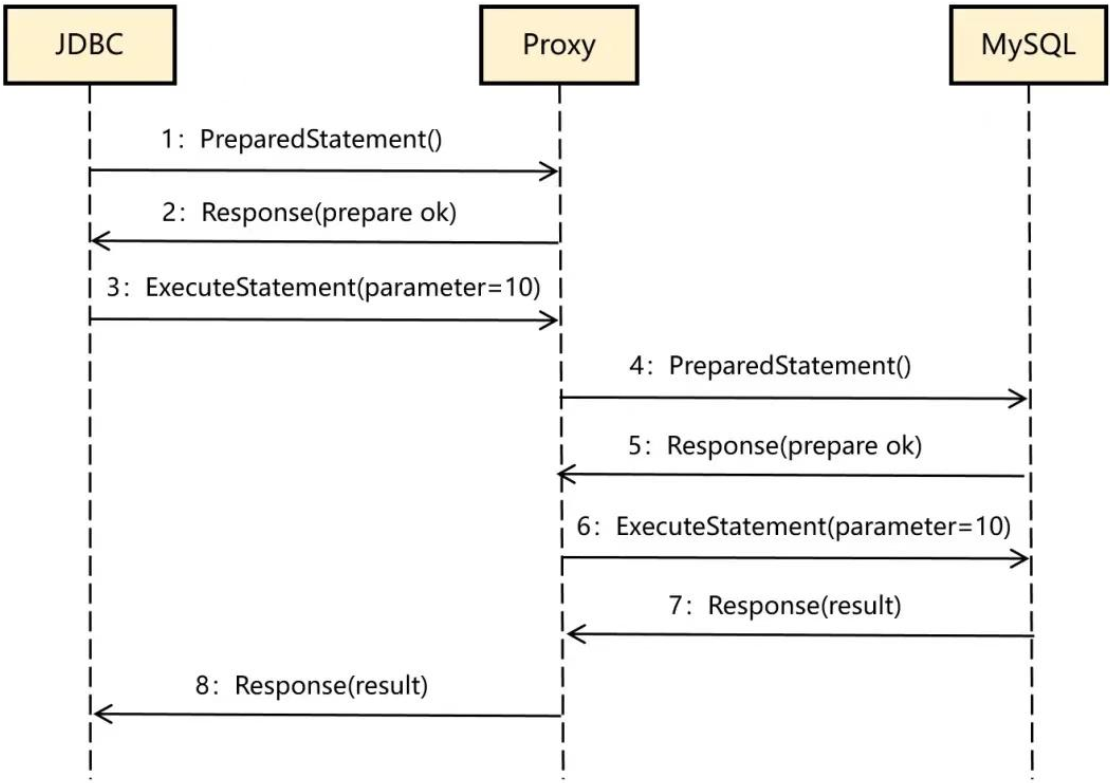
可以看到,Proxy在收到 PreparedStatement 命令后,并不会把这条消息转发给MySQL,只是缓存了这个 SQL,在收到 ExecuteStatement 命令后,才根据分片键和传过来的参数值确定真实的数据库,并与 MySQL 交互。
Wireshark抓取 MySQL 协议的数据包,将 Wireshark 的过滤条件设置成:
mysql || tcp.port==3307
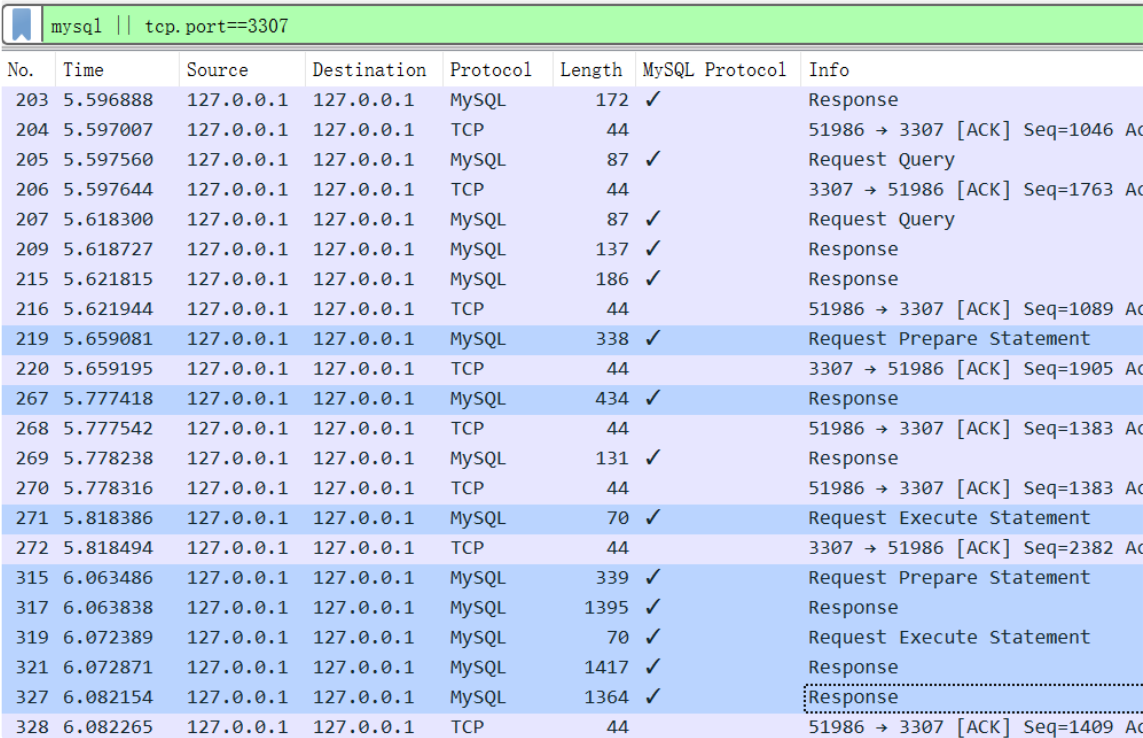
这里的 8个深蓝色数据包和ShardingProxy 的原理介绍是完成吻合的。
结合 ShardingProxy 的架构图来思考下:Proxy 仅仅作为一个中间代理,介于应用程序和 MySQL Server 之间,它完全实现了 MySQL 协议,以便对 MySQL 命令进行解码和编码,然后加上自己的分库分表逻辑。
如果 ShardingProxy 内部存在 Bug,那一定是某个数据包出现了问题。顺着这个思路,很快就能发现:执行完 ExecuteStatement 后,MySQL Server 返回正确数据包给 Proxy了,但是 Proxy 没有返回正确的数据包给应用程序。
下面截图的是倒数第 2 个 Response 数据包,由 MySQL Server 返回给 Proxy 的,Payload 中能看到那条记录的数据:
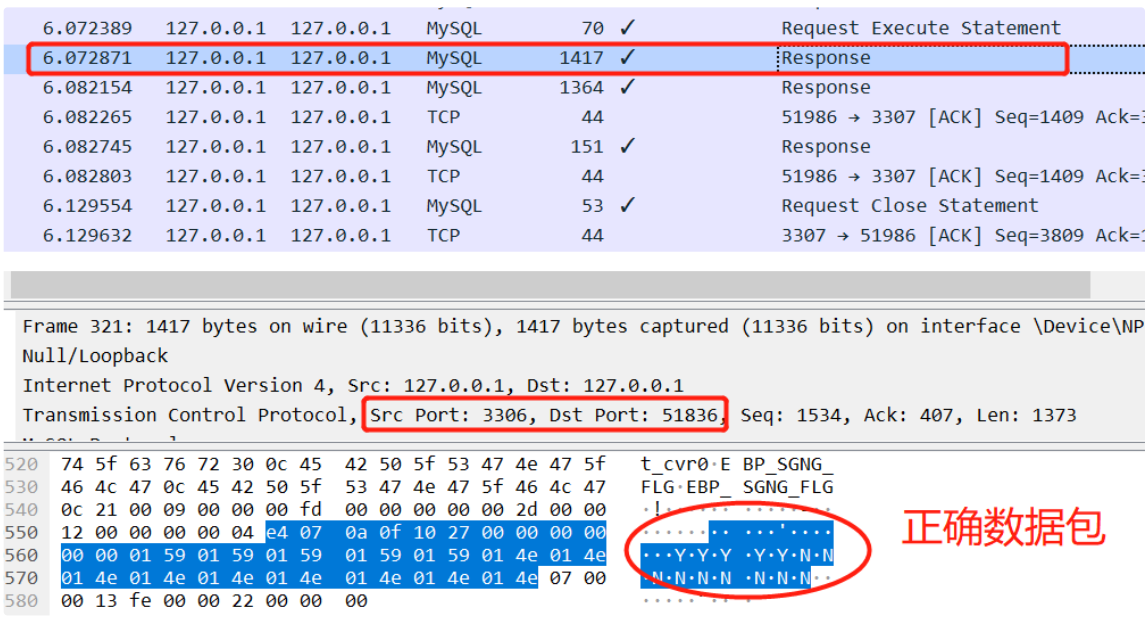
下面截图的是最后 1 个 Response 数据包,由 Proxy 返回给应用程序的,Payload 中只能看到表字段的定义,那条记录已经不翼而飞了。
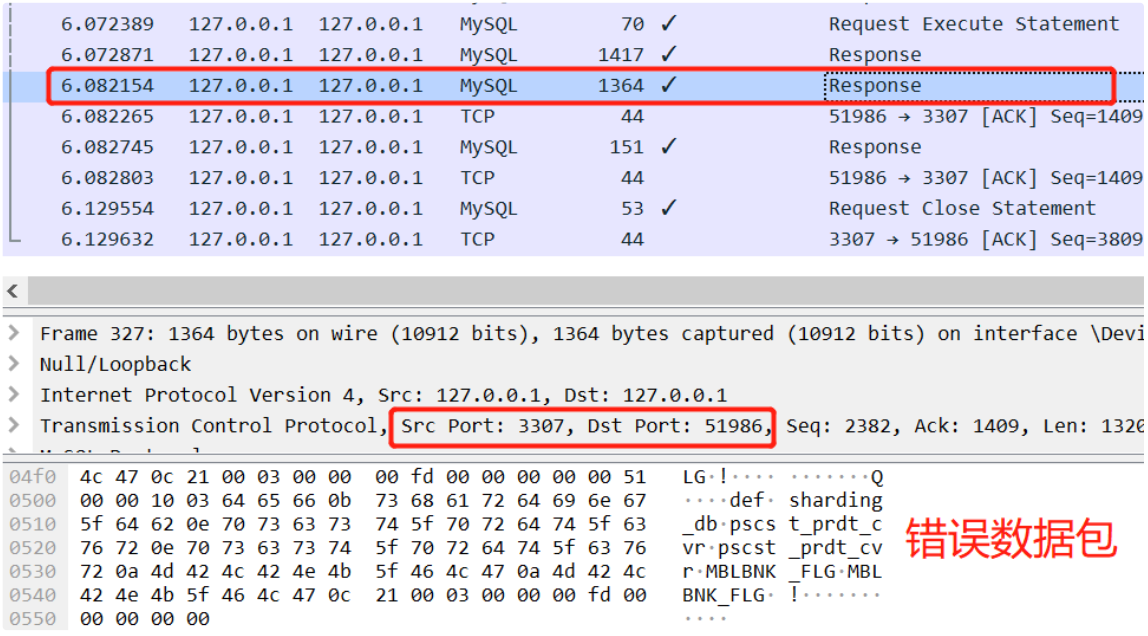
4.根本原因定位
官方开发者仅仅修改了一行代码:
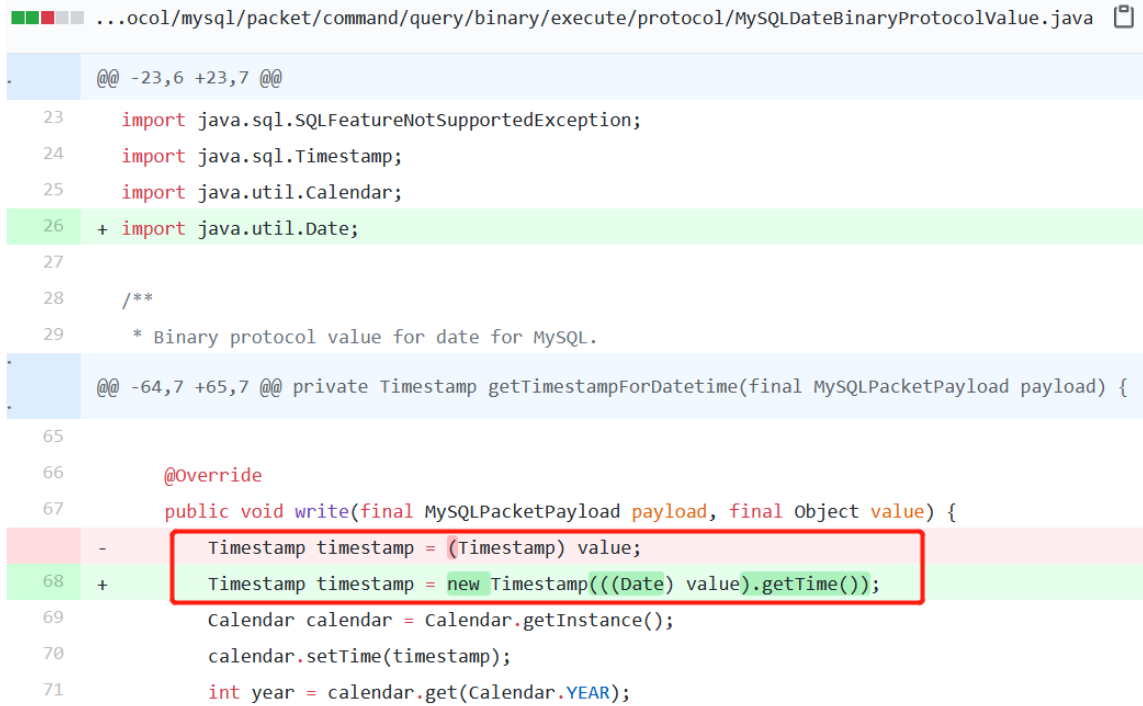
改动的这行代码,就是在 ShardingProxy 再次组装数据包返回给应用程序时抛出来的。
由于我们的数据表中存在一个 date 类型的字段,改动的这行代码却强制将 date 类型转换成了 Timestamp 类型。
1、为什么代码抛异常了,但是 ShardingProxy 的控制台没打印
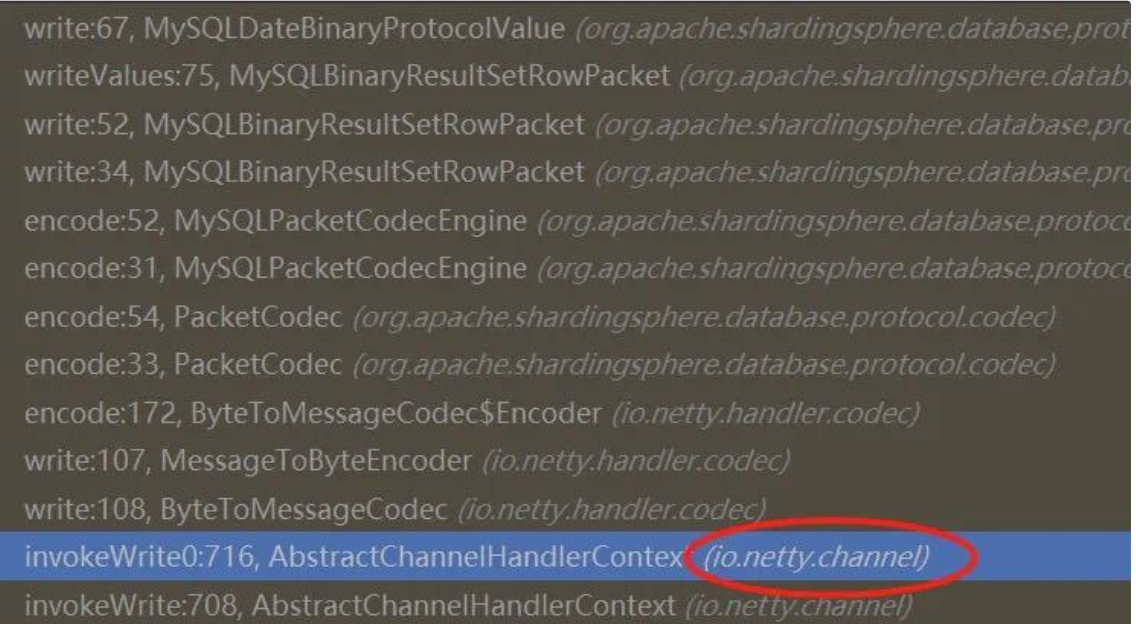
上面截图的是:抛出 ClassCastException 那个方法的整个调用链。由于 ShardingProxy并没有捕获这个 RuntimeException 以及打印日志,最终这个异常被 netty 吞掉了。
2、为什么 ShardingProxy 需要做 date 到 Timestamp 的类型转换
可以从 ShardingProxy 的架构来理解,因为 Proxy 只有对 MySQL 协议进行编解码后,才能在中间插入它的分库分表逻辑。针对 date 类型的字段,ShardingProxy 通过 JDBC 的 API 从查询结果中拿到的仍然是Date 类型,之所以要转换成 Timestamp,这个又跟 MySQL 的协议有关了,下面是MySQL 官方文档的说明:
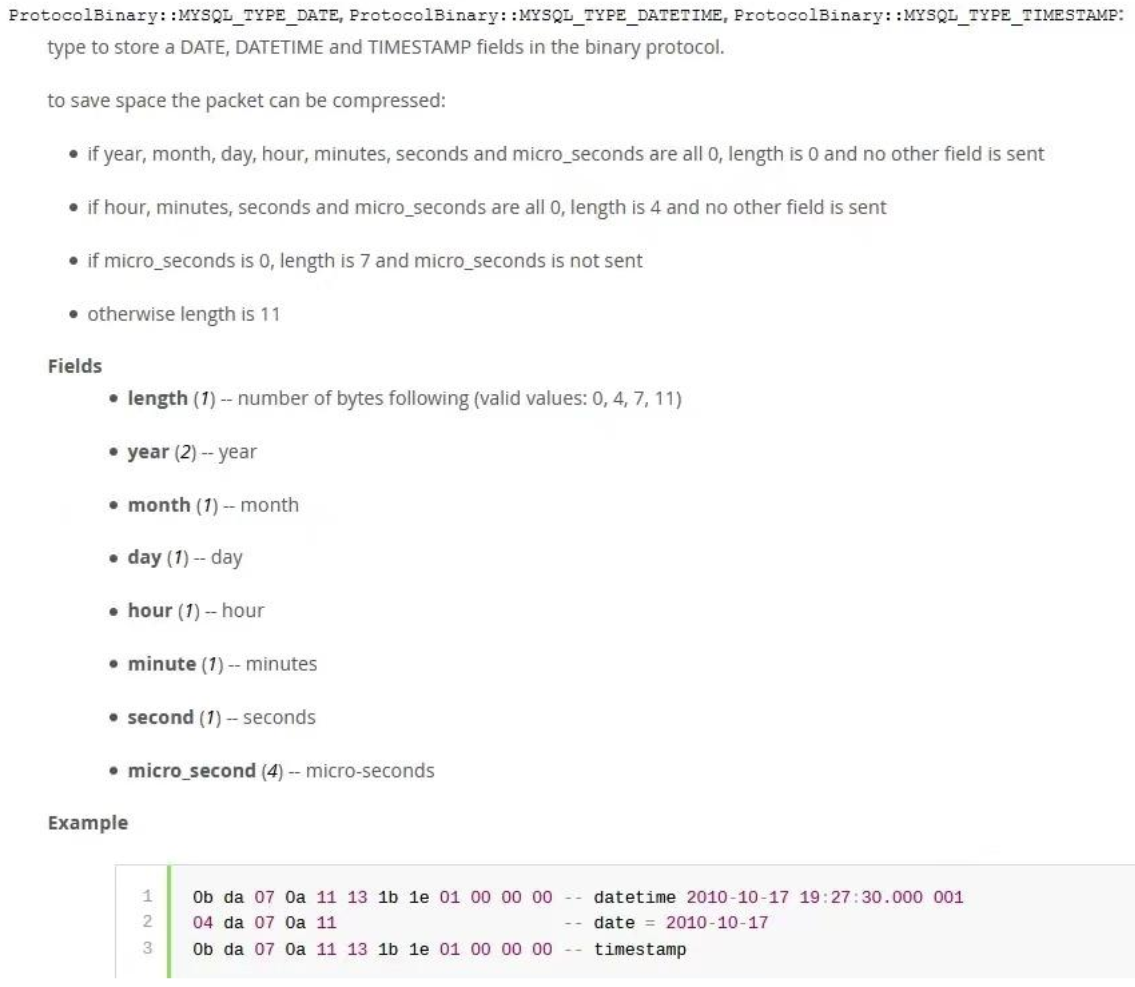
简单理解就是:ShardingProxy 在代码实现时,用了一个范围最大的 timestamp 存了三种可能的值 date, datetime 和 timestamp,然后再按照上面这个协议规范进行二进制的写入。
3、这个 Bug 是只有在使用 SQL 预编译功能时才会被触发吗?
是的,只有在处理 ExecuteStatement 命令时,这个方法才会被调用到。那普通的 SQL查询场景为什么用不到呢?这个又跟 MySQL 协议有关了,普通的 SQL 查询场景,payload 不是二进制协议的,而是普通的文本协议。这种情况下,无需调用这个类进行转换。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix