软件实践第二次作业
软件实践第二次作业
| 这个作业属于哪一个课程 | 2021春软件工程实践|S班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 学习《构建之法》、边完成词频统计作业边学习相关知识 |
| 其他参考文献 | 《构建之法》 《腾讯C++代码规范》 《现代软件工程讲义2》 《廖雪峰的git教程》 |
目录
任务一:我对《构建之法》的几个疑问
创新真的要顾及到一部分人的利益吗?
348页:“不但大众不喜欢创新,甚至连创新者自己都不例外,有些创新者甚至恨创新。”
当我在老师的提示下阅读第十六章“IT行业的创新”时,我感到很困惑,书中提到了很多人都讨厌创新,因为这可能会影响到其他大部分人甚至自己的利益,可是,如果不创新,怎么能开发出新的市场?我觉得这样顾此失彼的做法是有待商榷的。
拥有好想法的人不应该更容易获胜吗?
350页:“16.1.3 迷思之三:好的想法会赢”
书中认为,光有好的创新想法是不行的,就比如书中所说的键盘例子。可我认为,只是凭所谓的“习惯”而不去做创新,当好想法被公布出来时,所谓的“习惯”将会被淘汰掉,因为别人的点子更出色。
如何实现单元测试的自动化?
28页:“单元测试应该集成到自动测试的框架中:另一个重要的措施是要把单元测试自动化,这样每个人都能随时、随地运行单元测试。”
这一次的作业中使用到了单元测试,可是我对单元测试还是不太了解,文中提到测试最好使用自动化,可自动化是什么呢?和自己手动测试有什么比较大的不同呢?
什么阶段最适合“效能提高”?
34页:“大家也要注意避免没有做分析就过早地进行“效能提高”,如果我们不经分析就盲目优化,也许会事倍功半。”
书中说到如果太早的进行“效能提高”,可能会导致盲目话,可我认为如果不能再最开始就进行一个完善的算法思考,最后进行提高的话不仅会增加工作量,而且会导致大规模的代码变动,这样难道会更合理吗?
是否在项目正式启动前确定代码风格?
出自《构建之法》第四章
阅读完该章节,每个程序员都有属于自己的代码规范,那么在集体编程的时候,是应该按照一个统一的代码规范来编程,还是按照自己认为正确的代码规范来编程呢?
附加题
大家知道了软件和软件工程的起源,请问软件工程发展的过程中有什么你觉得有趣的冷知识和故事?
在程序中bug一词用于技术错误。这一术语最初由爱迪生在1878年提出的,但当时并没有流行起来。
在这的几年之后,美国上将Grace Hopper在她的日志本中,写下了她在Mark II电脑上发现的一项bug。
不过实际上,她说的真的是“虫子”问题,因为一只蛾子被困在电脑的继电器中,导致电脑的操作无法正常运行。
任务二:完成词频统计个人作业
在大数据环境下,搜索引擎,电商系统,服务平台,社交软件等,都会根据用户的输入来判断最近搜索最多的词语,从而分析当前热点,优化自己的服务。首先当然是统计出哪些词语被搜索的频率最高啦,请设计一个程序,能够满足一些词频统计的需求。
1、项目github链接
2、codestyle链接
3、PSP表格
| Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | ||
| • 估计这个任务需要多少时间 | 5 | 5 |
| • 开发 | ||
| • 需求分析 (包括学习新技术) | 120 | 180 |
| • 生成设计文档 | 60 | 50 |
| • 设计复审 | 30 | 20 |
| • 代码规范 (为目前的开发制定合适的规范) | 40 | 35 |
| • 具体设计 | 60 | 50 |
| • 具体编码 | 720 | 1200 |
| • 代码复审 | 30 | 30 |
| • 测试(自我测试,修改代码,提交修改) | 540 | 480 |
| 报告 | 60 | 50 |
| • 测试报告 | 30 | 20 |
| • 计算工作量 | 30 | 10 |
| • 事后总结, 并提出过程改进计划 | 30 | 20 |
| 合计 | 1725 | 2130 |
代码实现:
数据存储:
使用最简单的存储方式:创建一个大小为10000的字符数组存储从文件中读取的每一个字符,数组存储优点在于可以进行快速存储,缺点则是存储空间有限,如果文件过大可能会导致溢出
char buffer[MAXWORDS] = {}; //MAXWORDS为宏定义,大小为100000读取方式:
使用文件流按字符读取数据并存入数组中(因不区分大小写,此处读取的时候把所有小写字母转变为了大写字母,便于后面的判断)
ifstream inFile; inFile.open(argv[1]); char x; while ((x=inFile.get())!=EOF) { if (x <= 'z' && x >= 'a') { x = x - 32; } buffer[i] = x; i++; }函数实现:
统计字符,此处直接使用了C++库中带有的字符统计函数strlen()来获得字符长度:
int GetCharacters(char *str) { return strlen(str); }统计单词数量,此处通过空格和回车来判定一个字符串是否满足成为单词的一个条件,然后再通过判断截取到的字符串长度是否大于等于4,如果满足,则最后再判断改字符串前四个字母是否为英文字母,如果全部满足,则将该字符串存入一个字符串数组中(通过字符二维数组来实现),若不满足则抛弃:
int GetWords(char* str) { char temp[MAXWORD][MAXWORD]; int j = 0; int num = 0; for (int i = 0; i < strlen(str); i++) { if (str[i] != ' '&&str[i]!='\n') { temp[num][j] = str[i]; j++; } if (j == strlen(str)) //如果没有空格,判断该字符串是否为唯一单词 { } else if (str[i] == ' '||i == strlen(str)-1||str[i]=='\n') { num++; //判断是否满足单词的条件结果满足单词数就加 } if (num >= 11) //当单词数大于10则停止循环 { break; } } return num; }统计行数,判断是否有回车,且判断如果一个回车字符后面还是回车字符,则为空字符,直接跳过:
int GetLines(char* str) { int n = strlen(str); int num = 0; if (str[n - 1] == '\n') { num--; } for (int i = 0; i < n; i++) { if (str[i] == '\n') { if (str[i + 1] != '\n') { num++; } } } return num+1;}
```
将字符串数组中的每一个值通过冒泡排序方法排序并统计出现次数,出现过的字符串在接下来遇到的时候变为“0”(代替删除),然后创建一个数组来保存出现次数,这两个数组通过下表相等来相互对映,结果直接通过Show()函数来输出:
/*将二维数组存的单词放入字符串数组中*/ for (int i = 0; i < num; i++) { for (int j = 0; j < MAXWORD; j++) { if (temp[i][j] != 0) { strx[i]+=temp[i][j]; } } } /*通过冒泡排序交换位置并记录次数*/ for (int i = 0; i < n; i++) { for (int j = 0; j < n; j++) { if (a[i] > a[j]) { swap(a[i], a[j]); swap(str[i], str[j]); } } }
单元测试
- 测试统计字符函数:
``` c++ TEST_METHOD(TestMethod1) { ifstream inFile; inFile.open("F:\\test.txt"); char buffer[MAXWORDS] = {}; long i = 0; char x; while ((x = inFile.get()) != EOF) { buffer[i] = x; i++; } Assert::AreEqual(GetCharacters(buffer), 44); } ```
- 测试统计单词量函数:
``` c++ TEST_METHOD(TestMethod2) { ifstream inFile; inFile.open("F:\\test.txt"); char buffer[MAXWORDS] = {}; long i = 0; char x; while ((x = inFile.get()) != EOF) { buffer[i] = x; i++; } Assert::AreEqual(GetWords(buffer), 5); } ```
- 测试统计行数函数:
``` c++ TEST_METHOD(TestMethod3) { ifstream inFile; inFile.open("F:\\test.txt"); char buffer[MAXWORDS] = {}; long i = 0; char x; while ((x = inFile.get()) != EOF) { buffer[i] = x; i++; } Assert::AreEqual(GetLines(buffer), 6); } ```
- 测试结果展示:
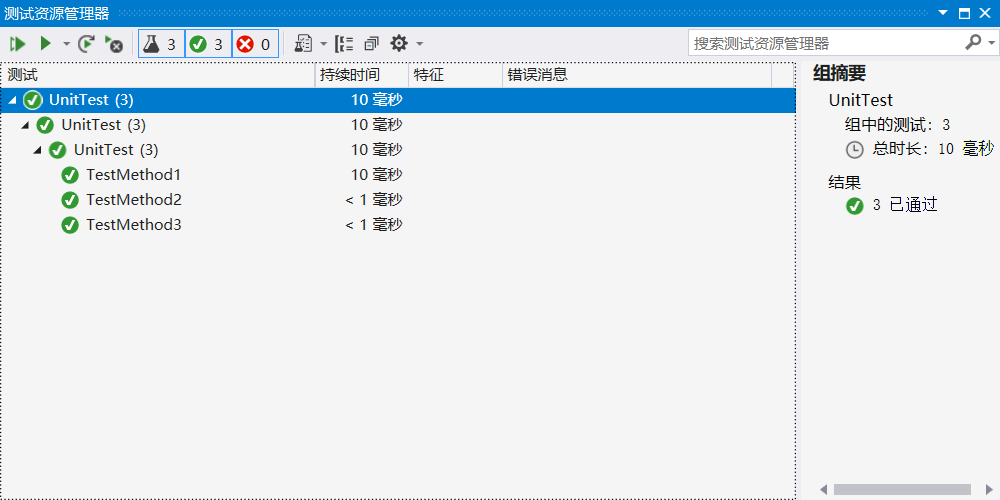
代码覆盖率检测:

成品展示:
1、input.txt:

2、运行后输出:

3、结果保存在output.txt中:

异常处理展示:
因为对输入输出流进行了处理,创建流的时候使用了ios::app,所以如果不存在该文件的话,不会报错,而是在该目录下面为用户创建一个文件:
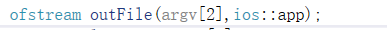
心路历程与收获
- 这是我第一次使用GitHub,我从中学会了很多关于GitHub的操作,我感到非常兴奋;
- 这次话了很多时间在了解及学习git上,通过git,我可以更加方便的管理我的文档,非常的使用;
- 第一次使用单元测试,虽然很早以前知道单元测试是可以不通过运行代码来判断函数真确性的知识,但是一直没有实践过,通过这次作业,深入体会了单元测试的便利性,在未来的编程中,我一定会更加频繁的使用它
- 本次作业我有许多的不足,这次作业如果使用C++的类来编写,用上向量或者图的话会非常的高效且方便,可是这一次我对作业认知不足,曾经边编边想的坏习惯也导致了我在编程中绕弯路,以后一定先认真思考每一个项目的编程方向再下手,确保不会再犯第二次错误。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号