python基础学习23----IO模型(简)
对于一个网络IO(network IO),它会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,该操作会经历两个阶段:
1.等待数据准备
2.将数据从系统内核拷贝到进程当中
当收到数据后,这些数据会先存放到系统所用的内存当中,之后在由系统将数据从内核中拷贝到使用的进程当中
不同的IO模型的区别就在于上述的两个阶段
一.阻塞IO (blocking IO)
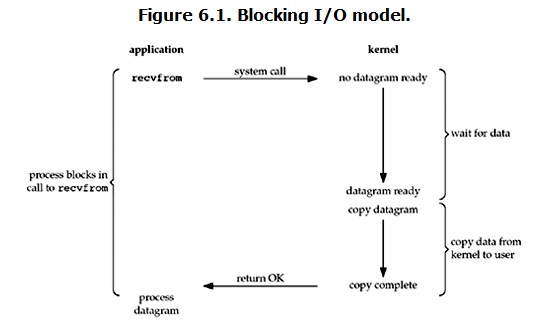
recvfrom进行系统调用后,等待数据和拷贝数据的两个阶段都被阻塞了
二.非阻塞IO (nonblocking IO)
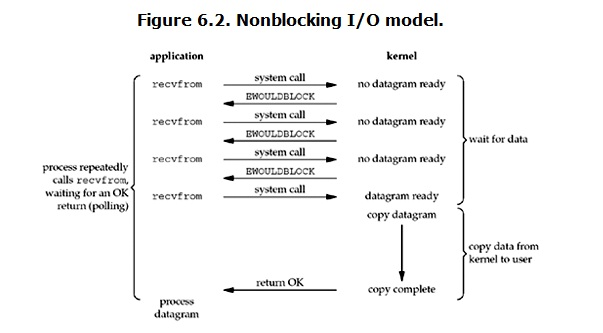
recvfrom不断的向kernel要数据,如果没有数据就马上返回一个提示,紧接着recvfrom继续去要数据,直到数据准备好, 然后再从内核拷贝到进程中。
这里等待数据的阶段并没有阻塞,但是数据从内核中拷贝到使用的进程的过程中还是处于阻塞状态。
缺点:循环调用recv()将大幅度推高CPU占用率,任务完成的响应延迟增大了,因为每过一段时间才去轮询一次read操作,而任务可能在两次轮询之间的任意时间完成。这会导致整体数据吞吐量的降低。
三.多路复用IO (IO multiplexing)
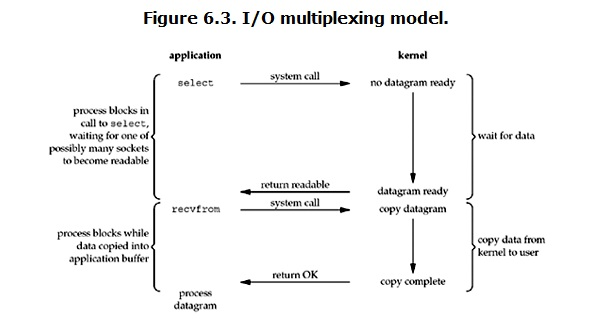
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这里两个阶段都处于阻塞状态,看似和阻塞IO没有太大区别,甚至比它效率更低,但是select能够处理多个连接。
#服务端
from socket import * import select s=socket(AF_INET,SOCK_STREAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind(('127.0.0.1',8081)) s.listen(5) s.setblocking(False) read_l=[s,] while True: r_l,w_l,x_l=select.select(read_l,[],[]) print(r_l) for ready_obj in r_l: if ready_obj == s: conn,addr=ready_obj.accept() read_l.append(conn) else: try: data=ready_obj.recv(1024) if not data: read_l.remove(ready_obj) continue ready_obj.send(data.upper()) except ConnectionResetError: read_l.remove(ready_obj)
#客户端 from socket import * c=socket(AF_INET,SOCK_STREAM) c.connect(('127.0.0.1',8081)) while True: msg=input('>>: ') if not msg:continue c.send(msg.encode('utf-8')) data=c.recv(1024) print(data.decode('utf-8'))
四.异步IO(asynchronous IO)
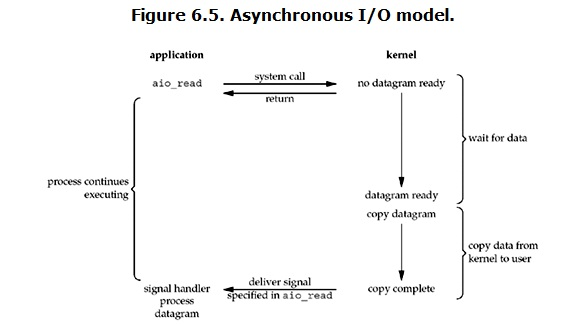
异步IO两个阶段都没有阻塞
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
具体参考https://www.cnblogs.com/haiyan123/p/7465486.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号