数模国赛 训练日志
| 年份 | A | B | C |
|---|---|---|---|
| 2022 | 物理、工程 | 平面几何,构造 | 统计、找规律 |
| 2021 | 物理、工程 | 评价 | |
| 2020 | |||
| 2019 | |||
| 2018 |
Day1 2023年7月16日 星期日
-
高阶常微分方程的数值解迭代逼近方法:龙格塔库算法
-
写论文的第七点:模型总结
- 模型优点
- 模型缺点
- 模型推广与改进
//推广指的是这个抽象模型的实际应用,改进指的是针对模型缺点做出的调整(比如加入一些参数,收集更多数据后再进行实验)
- 搜索算法的进阶版:遗传算法和改进遗传算法
Day2 2023年7月17日 星期一
- 中心化对数比变换
- pearson卡方检验法
- Yates校正卡方检验法
- 决策树法
- R型聚类法 Q型聚类法
- 灰色关联分析模型
python SPSS statistic 神经网络算法 excel表导入
Day3 2023年7月18日 星期二
- python基础语言学习(详情见手写笔记、B站两小时的视频https://www.bilibili.com/video/BV16A411i7W7/?spm_id_from=333.337.search-card.all.click&vd_source=8c7dc8bb8d3df0ec8a6e9ecbeea40e4a、山哥的课件(非常详细,当字典用))
- 用Python进行excel和CSV文件的数据导入初步(具体参考https://blog.csdn.net/weixin_50538485/article/details/131595828)
Day4 2023年7月19日 星期三
SPSS(统计数据分析工具)相关:
https://www.spsspro.com/help/frequency/#_1、作用
https://www.spsspro.com/mydata/index
https://www.bilibili.com/video/BV1GK4y1E73Q/?spm_id_from=333.999.0.0
Latex安装:
https://mirrors.pku.edu.cn/ctan/systems/texlive/Images/
https://www.ngui.cc/el/3722783.html?action=onClick
Day5 2023年7月20日 星期四
- 交换代码文件的时候必须整个文件一起传输,不要复制代码内容来传输,避免格式和不可见字符的问题。
- 强化参数法 联合调整法
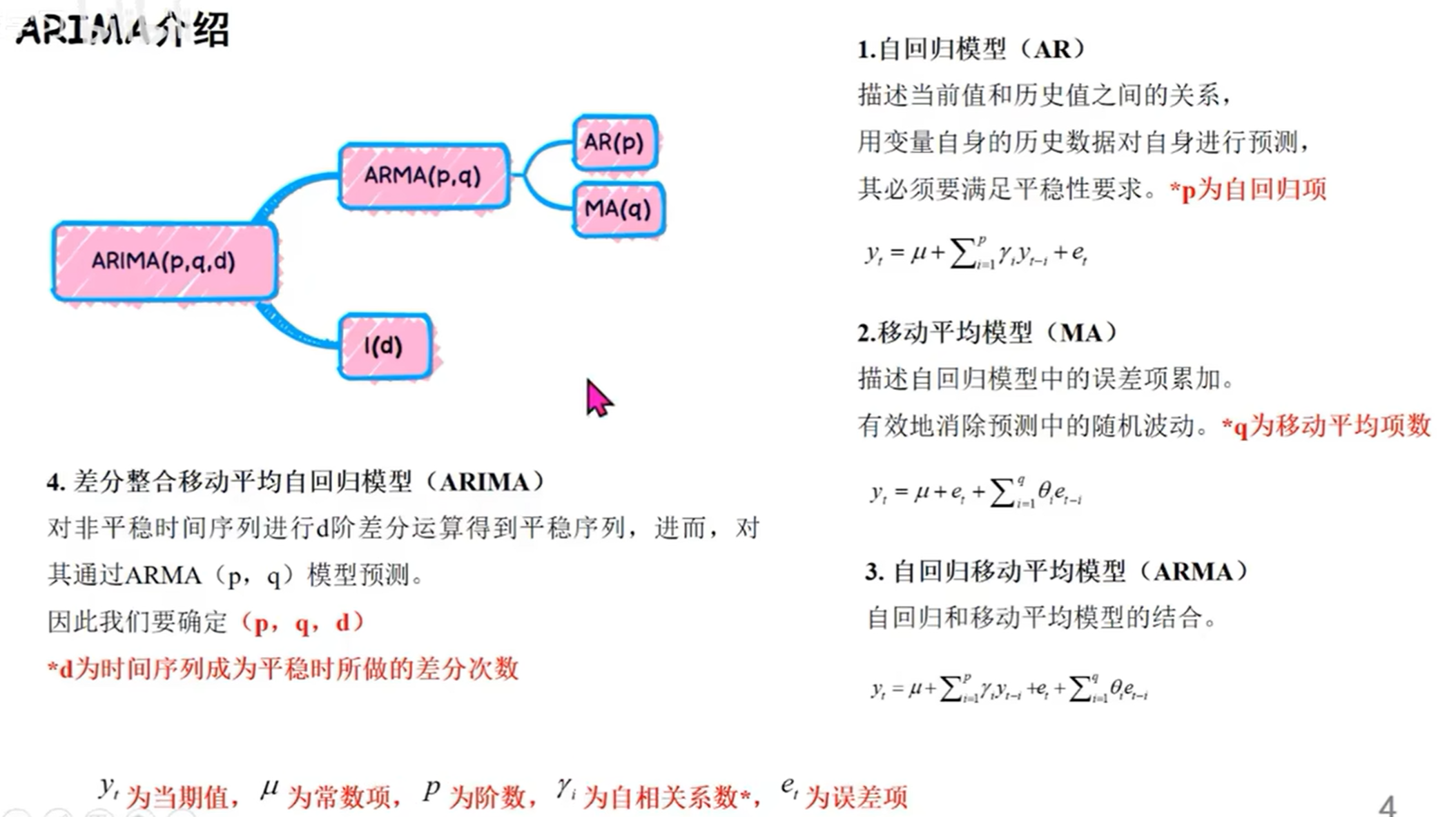
- 时间序列的几种模型(自回归模型 AR( p )、移动平均模型 MA(q)、自回归移动平均模型 ARMA(p,q)、自回归差分移动平均模型 ARIMA(p,d,q))
- 简单一次移动平均预测法 加权一次移动平均预测法 一次指数平滑预测法 二次指数平滑预测法 三次指数平衡预测法
- K-均值聚类 ARIMA模型
时间序列模型:https://blog.csdn.net/qq_34160248/article/details/127218452 时间序列的特点是统计有关任意时间线的事物发生规律,与回归分析不同。 指数平滑法有几种不同形式:一次指数平滑法针对没有趋势和季节性的序列,二次指数平滑法针对有趋势但没有季节性的序列,三次指数平滑法针对有趋势也有季节性的序列。
- 一次指数平滑法:
![]()
- 二次指数平滑法:
- 三次指数平滑法:

Day6 2023年7月21日 星期五
-
字符串尽可能用单引号,用双引号会表示一个整体,即length为1
-
![]()
-
上图有一个错误,randi的上下界确定了之后,是生成闭区间内的随机整数,不是开区间
-
矩阵的展开方法是竖着的,即先遍历第一列,再遍历第二列,……
-
![]()
-
A'是转置矩阵,inv(A)是求逆(方阵),A(:)是对矩阵按列展开。
-
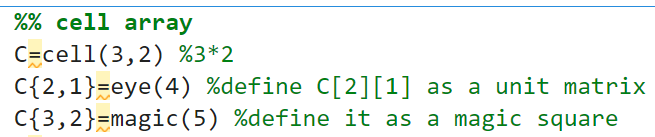
元胞数组
![]()
-
结构体\(2k-1\)位置是下标名称,\(2k\)是对应的内容,什么形式都可以,{}括起来的是cell,[]括起来的是矩阵,''括起来的是字符串,还可以是数字。
![]()
books.name(1)是cell
books.name{1}是值,是一个字符串 -
![]()
-
![]()
-
![]()
-
![]()
-
![]()
-
![]()








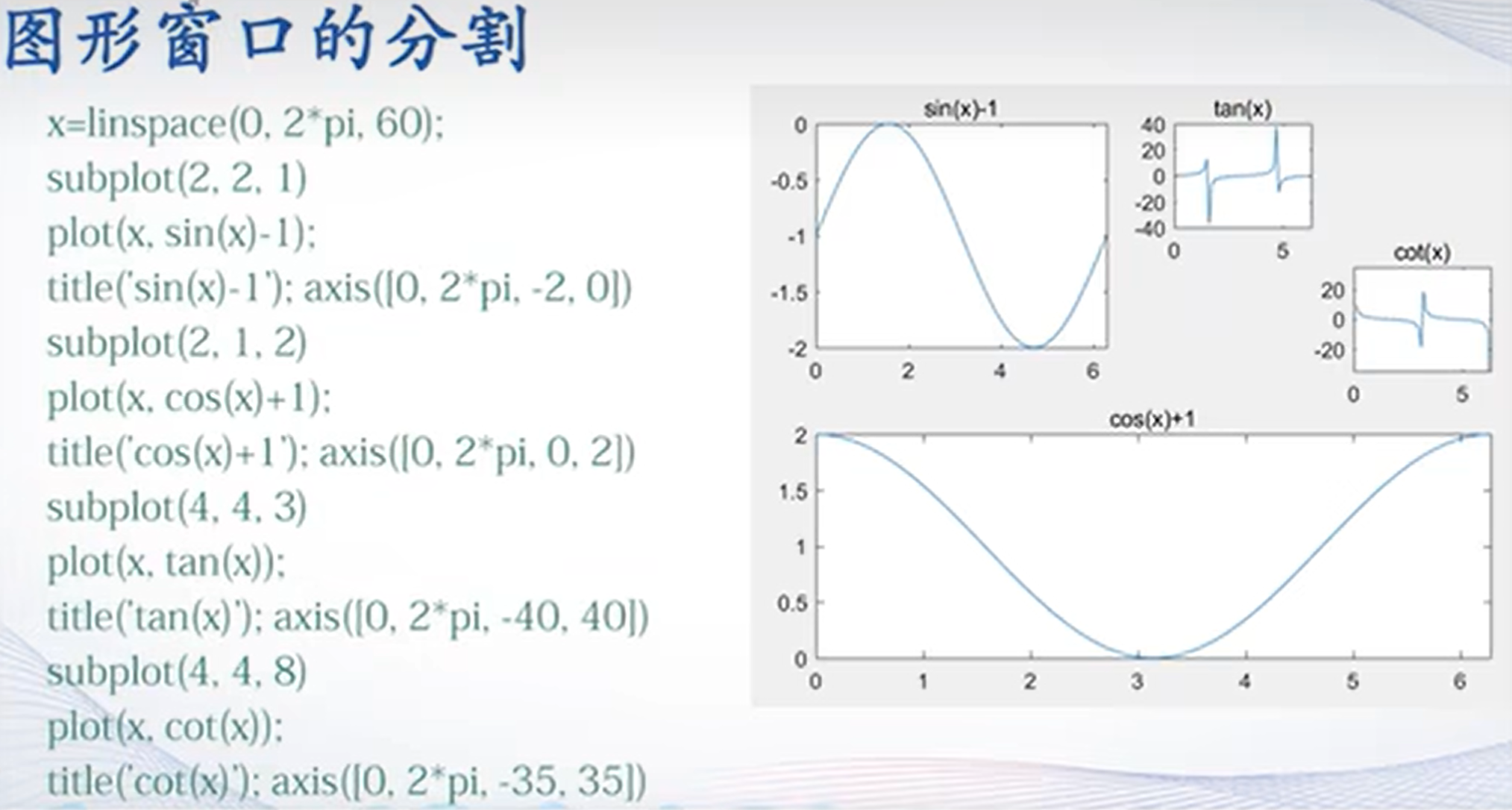
%1.二维平面绘图
x = 0:0.01:2*pi;
y = sin(x);
figure %建立一个幕布
plot(x,y)
title('y= sin(x)')
xlabel('x')
ylabel('sin(x)')
xlim([0 2*pi]) %确定x轴的最大最小值
x = 0:0.01:20;
yl = 200*exp(-0.05*x).*sin(x);
y2 = 0.8*exp(-0.5*x).*sin(10*x);
figure
[AX, H1,H2] = plotyy(x, yl, x, y2,'plot');
set (get (AX(1),'Ylabel'),'String','Slow Decay')
set (get (AX(2),'Ylabel'),'String','Fast Decay')
xlabel1('Time (\musec)')
title('Multiple Decay Rates')
set(Hl,'LineStyle','--')
set(H2,'LineStyle',':')
% 2.三维立体绘图
t = 0:pi/50:10*pi;
plot3(sin(t),cos(t),t)
xlabel('sin(t)')
ylabel('cos(t)')
zlabel('t')
grid on
axis square
- hold on
![]()
插值和拟合
https://www.bilibili.com/video/BV1VF411Q7Zo/?spm_id_from=333.337.search-card.all.click&vd_source=889d369471e89b54176f10e16cad832e
https://www.bilibili.com/video/BV18N41127Cn/?vd_source=889d369471e89b54176f10e16cad832e
- 插值得出的曲线会经过每一个已知的数据点,常用于求出缺失值。得出的函数一般比较复杂。
- 拟合得出的曲线符合总体的趋势,不一定经过每一个数据点,常用于找到数据的变化关系和趋势。得到的函数比较简单,但是需要调参。
有时可以一起用。
一维函数插值
![]()

%% one dimention
x0=[0 3 5 7 9 11 12 13 14 15]
y0=[0 1.2 1.7 2.0 2.1 2.0 1.8 1.2 1.0 1.6]
plot(x0,y0,'o');
plot(x0,y0);
clc
hold off
x1=0:0.01:15;
y1=interp1(x0,y0,x1,"linear");
% figure;plot(x1,y1,"or",x0,y0,'ob')
figure;plot(x1,y1);
y2=interp1(x0,y0,x1,"spline");
% figure;plot(x1,y2,"or",x0,y0,"ob")
figure;plot(x1,y2);
x1(6)
y1(6)
y2(6)
插值完如果要查询某个点的坐标,需要手算出对应的x1的下标编号是多少,然后y1的编号也与之对应,因为x1和y1是向量组,是离散的,需要用下标编号来确定。
注意:二维插值的时候需要注意向量组的都是列向量,所以定义x=[](或x=a:p:b),作为每一列,y=[]'(或y=(c:q:d)'),作为每一行,然后再导入矩阵,输出的时候用mesh(x,y,z)函数。
%% 二维插值 interp2
x0 = 100:100:500;%4行5列 列数对应x
y0 =(100:100:400)’; %x和y必须方向不同 所以转置 网格化的语法更麻烦可以自行学习
z0 =[636 697 624 478 450 :698 712 630 478 420:680 674 598 412 400; 662 626 552 334 310]; %不会画图怎么办 直接选中自动画
mesh(x0y0,z0)
xi = 100:10:500;
yi =(100:10:400)’
zi = interp2(x0,y0,z0,xi,yi,"cubic"); %初始值查询点 方法(最后一个参数外插设置)mesh(xi,yi,zi);
- 拟合所用到的cftool全名是Curve Fitting Toolbox。
曲线拟合工具箱cftool
Custom Equations: 用户自定义的函数类型
Exponential: 指数逼近,有2种类型,a* exp(bx)、a exp(b x)+cexp(d x)
Fourier: 傅立叶逼近,有7种类型,基础型是 a0+a1 cos(x * w)+b1* sin(x* w);
Gaussian: 高斯逼近,有8种类型,基础型是 a1 * exp(-((x - b1)/c1)^2);
Interpolant: 插值逼近,有4种类型,Nearest neighbor、 Linear、Cubic、Shape-preserving (PCHIP)
Linear Fitting: 线性拟合;
Polynomial:多形式逼近:
Power: 幂逼近,有2种类型,axb、a*xb+c;
Rational: 有理数逼近;
smoothing Spline:平滑逼近
Sum of sin Functions: 正弦曲线逼近,有8种类型,基础型是 a1 sin(b1 x+c1);
Weibull: 只有一种,abx^(b -1)exp(-a*x^b);
可以用cftool导出某几种拟合方法的代码,然后再修改其中的参数,从而调整拟合度。
配色网站:https://mycolor.space/
素材网站:https://www.freepik.com/
python:seaborn库:https://zhuanlan.zhihu.com/p/81553421?utm_source=wechat_session
matlab:绘图代码示例:知乎:阿昆的科研日常 https://www.zhihu.com/column/c_1074615528869531648
小提琴图:https://zhuanlan.zhihu.com/p/411001831
figurebest美化:b站搜图通道
作图网站:https://www.bioladder.cn/web/#/pro/index
网络图绘制:Gephi
地理图绘制:tableau https://www.bilibili.com/video/BV1E4411B7ef/?spm_id_from=333.337.search-card.all.click
ppt和excel绘图: https://www.bilibili.com/video/BV1c5411W7U9/?spm_id_from=333.337.search-card.all.click&vd_source=f7911a26eb7ea5e958e9d6718b09c9c0
Day7 2023年7月22日 星期六
教程: https://www.spsspro.com/help/frequency/#_1、作用
SPSS的在线编辑网站: https://www.spsspro.com/mydata/index
数据分析
1. 描述性分析(略)
2. 问卷分析:
问卷分析
信度分析 问卷是否可信,问题设置是否合理
多项分析 多选选项比例,哪些选项更为重要,帕累托图,交叉图。(多选单选,单选多选,多选多选)
NPS净推荐值分析 产品口碑,客户的推荐指数,一般0-10分分成3档
对应分析(R-Q 型因子分析)变量之间的对应关系,一般应用于定类变量,常对两个变量做列联分析(可列出列联表也可以画图(xy坐标))。
区分度分析 各分组的区分性,差异性较大则问卷设计合理
效度分析 问卷的有效性,问题的合理性
联合分析 先判断每个属性是否影响因变量(是否关联),再判断属性的影响力(哪个因素更为重要)。
路径分析 变量的复杂路径关系(建成一个有向图,看A对B的影响程度)
结构方程模型(SEM) 路径分析扩展,例如一个变量有很多个影响方面,先分析这些方面对变量的影响,再分析变量对目标的影响
调节作用 中间变量起作用的时间和大小
验证性因子分析 因子相关度是否符合原设计
权重分析(熵权法) 指标的重要性的权重
MaxDiff模型 受访者客户对产品属性的偏好程度,最重要和最不重要的选项
产品定价模型 设置价格断裂点,确定产品的最优价格,看用户最接受的价位
Kano模型 确定产品功能优先级,分成正向题和负向题来分析出该属性的特点(魅力,必要,不必要),分析该属性的定位
平行中介效应 中间变量的调节作用,判断从X到Y是否经过中间变量M的影响
链式中介效应 再加入中间变量的相互影响
TURF分析 资源/空间有限的策略或营销组合,例如分析该给哪些广告公司工作才能收获最大的达到率。
惩罚分析 消费者对感官属性的喜好度,低分表示过弱,高分表示过强(这两者都不喜欢),中分表示刚刚好。
DP专项算法 先求交叉列联表,再两两相关列分别执行列比例检验差异性,注意只能上传SPSS专用的.sav文件
多维尺度分析 利用平面距离反映对象之间的相似程度,距离越远代表相似程度越大
Day8 2023年7月23日 星期日
数据分析
3. 综合分析:
综合评价 本质上就是各种求分项目权重占比的方法
层次分析法 多目标的复杂问题的定性与定量相结合的决策分析方法,有若干个影响因素Bi会影响A的选择(A有几个),然后分别两两对Bi进行评分,分析出Ai的得分以及Bi的影响权重
因子分析(探索性)减少因子个数来反映原始信息,并反映这些独立的公洞因子的内在关系及权重
数据包络分析 评价多输入指标和多输出指标,即调整各投入项目和各产出项目的比例,使得效率最优
模糊综合评价 将边界不清、不易定量的因素定量化进行综合性评价(例如好吃,一般般,不好吃)
优劣解距离法(TOPSIS) 精确地反映各评价方案之间的差距,找出最优和最劣的方案以及各个方案的相近程度
秩和比综合评价法(RSR) 效益型指标、成本型指标排名计算秩和比,效益指标小到大排序,成本指标大到小排序,得出对象的优劣程度
耦合协调度 反应多个系统之间的相互作用影响看协调发展水平,看是否良性协调发展
层次分析法(AHP简化版)多目标的复杂问题的定性与定量相结合的决策分析方法,各方案的量化得分或者同一级的指标权重,层次分析法(AHP专业版)的弱化版
熵值法 用熵值来判断某个指标的离散程度和对综合评价的影响,离散程度越高,该指标权重越大,熵值越小。若某项指标全部相等,则该指标不起作用
CRITIC权重法 对比强度和冲突性指标,消除一些相关性较强的指标的影响,计算去量纲化后(归一化)后的权值
独立性权系数法 客观赋权法,共线性强弱来确定指标权重,如果一个变量可以被其他变量线性表示,那它的重要度就低
变异系数法 客观赋权法,当前值与目标值的变异程度来对各指标进行赋权,当前值与目标值差距越大,越难实现,权值应该越高
灰色关联分析 对一个系统发展变化态势的定量描述和比较的方法,反映了曲线间的关联程读。两者变化趋势一致,则关联程度较高。通过确定参考数据列和若干个比较数据列的几何形状相似程度来判断其联系是否紧密,它反映了曲线间的关联程度
多准则妥协解排序法(VIKOR) 评价对象进行排序的方法得到评价对象的优劣级别,首先计算评价对象总的最优解和最差解,然后比较各评价对象与最优解和最差解之间的距离大小来确定评价对象的排序,进而获得待评价对象的优劣级别
解释结构模型(ISM) 得到要素之间的复杂相互关系和层次构建多级递阶结构模型,通过构建初阶的邻接矩阵(对行而言,若为1则代表x对y有影响),计算最终的影响矩阵(即有向图中xi能否到达yi)
Day9 2023年7月24日 星期一
数据分析
4. 差异性分析
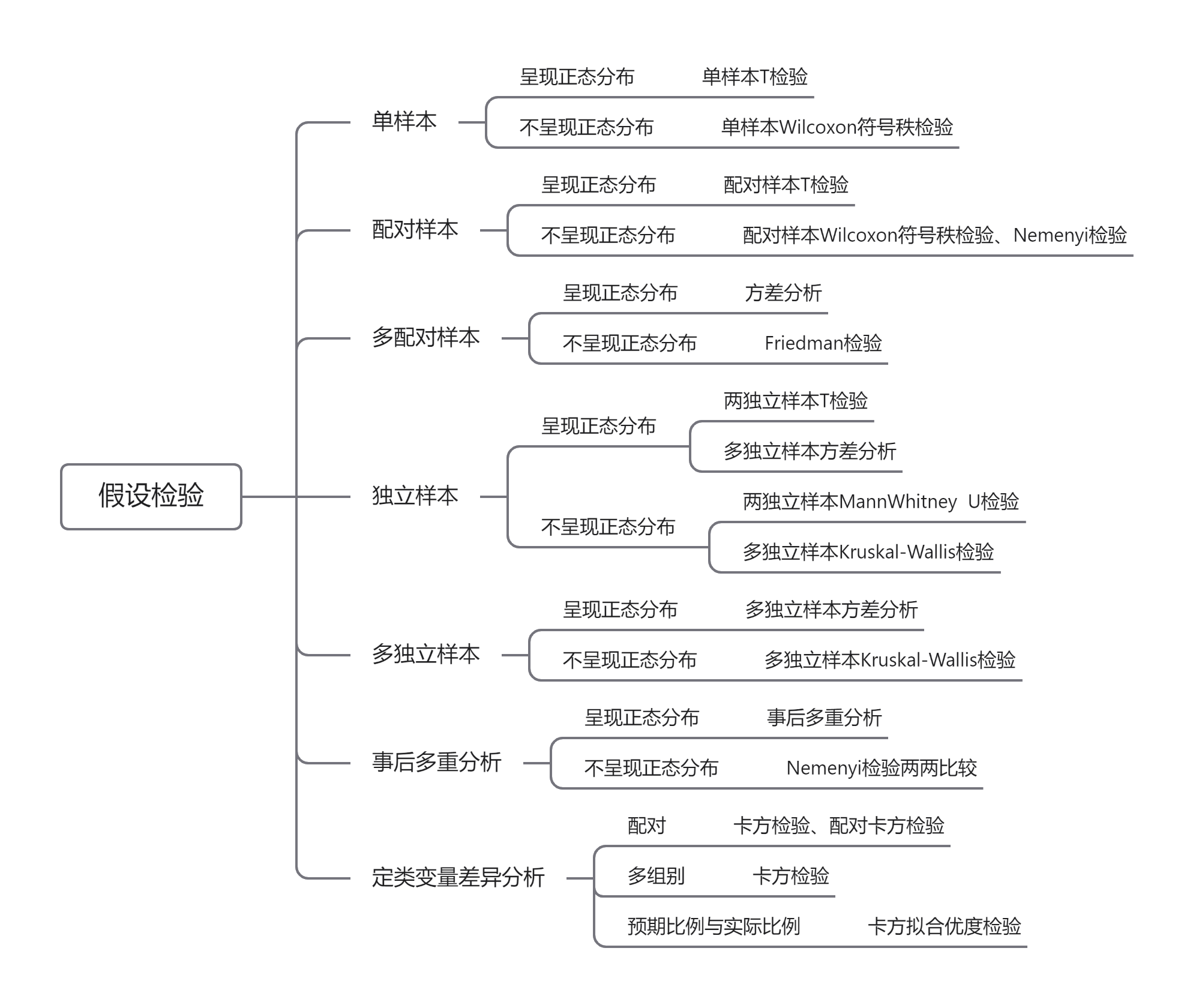
差异性分析,本质上就是假设检验,计算数据的统计量,看差异性
差异性分析自动求解器:
差异性分析方法的选取混乱,故对众多差异性分析方法的选择方法存在疑惑时,可以使用差异性模块的自动求解器功能进行分析。差异性分析自动求解器整合了上图除去事后多重分析(事后多重比较可在差异性模块中自行使用)其他部分的差异性分析内容,系统将根据拖入的变量提示可用的差异性分析方法。
参数检验(知道总体分布形式,对总体分布的参数如均值、方差进行推断):
//T检验类只能应用于二分类定类变量,即两个集合,方差分析可以用于多个集合
单样本T检验 正态性分布的样本数据与一个特定数值之间的差异情况
配对样本T检验 配对的连续变量 X1,X2 之间的差异情况(作差,看差是否满足正态分布),配对变量差值呈现正态性分布
独立样本T检验 两个数集(集合大小不一定一样)是否存在明显差异
单因素方差分析 方差分析(单因素方差分析或 F 检验),一个定类字段(X)上的定量字段(Y)之间的差异性,分析同一个因素不同分组(如:不同的受教育程度 X)对定量变量(如:工资 Y)产生/不产生显著性影响
事后多重比较 做完方差分析后(只能判定总体均值是否完全相同),若不完全相同,则可分析出是哪些总体均值与众不同
多因素方差分析 分析多个(≥2)自变量(定类变量)对因变量(定量变量)带来的显著性影响,注意自变量之间可能会发生相互影响从而影响因变量
摘要单因素方差分析 没有原始数据时只利用样本量、平均值、标准差来分析检验差异是否显著
摘要T检验 没有原始数据时只利用样本量、平均值、标准差来分析差异是否显著
非参数检验(总体分布形式未知,在推断中不涉及总体分布的参数):
卡方检验 Pearson卡方检验,比较定类变量X中的各个Xi对定类变量Y中的各个Yi的影响是否有差异,卡方越大偏差越大
单样本Wilcoxon符号秩检验 样本数据中位数与特定数值之间的差异情况,无需正态分布(区别单样本T分布)
配对样本Wilcoxon符号秩检验:样本X1和X2的变化值是否有差异,无需正态分布(区别配对样本T分布)
独立样本MannWhitney检验 又称为U检验,分析一个定类变量(只能是二分类变量)与多个定量变量之间有无明显差异,无需正态分布(区别独立样本T检验)
多配对样本Friedman检验 分析多组样本数一致的定量变量之间有无明显差异,若呈现正态分布则用方差分析
多独立样本Kruskal-Wallis检验 多分类定类字段(不止二分类,是MannWhitney的进阶版)对一个或多个定量变量的差异性分析,无需正态分布(区分方差分析)
卡方拟合优度检验 判断期望频数的比例与观察频数的比例是否有显著差异,通常应用于问卷的多重响应频率分析里面的响应率与普及率分析
5. 相关性分析
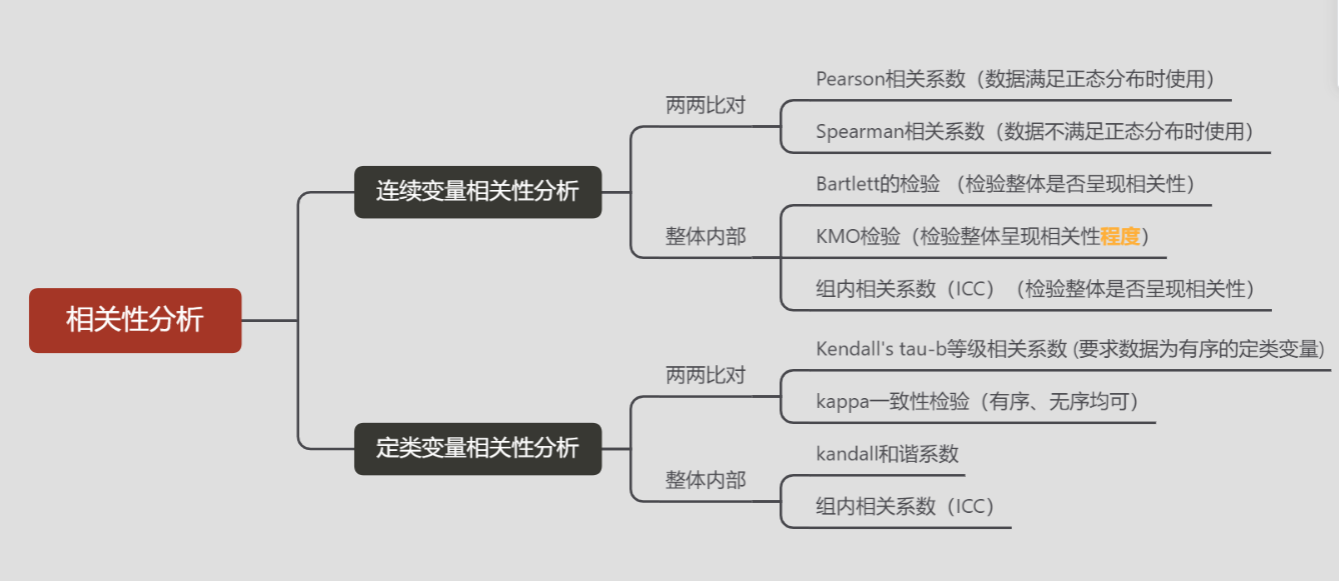
相关性分析,就是一些数据列两两或者整体是否符合一致性
相关性分析 对变量两两之间的相关程度进行分析,计算方式有三种,分别是 Pearson 相关系数(适用于定量数据,且数据满足正态分布)、Spearman 相关系数(数据不满足正态分布时使用),Kendall's tau-b 相关系数(有序定类变量,例如学历分为小学、初中、高中、大学)
Cochran's Q检验 分析多个样本(样本数一致)差异性的统计检验,与 Friedman 检验与 Nemenyi 检验不一样的是,Cochran's Q 检验只适用定类字段。检验三个字段或以上的数据总体差异性,注意定量变量必须是二分类且只有0/1两类。例如分析 50 个同学对一模、二模、三模的三次高考模拟考试的体验,体验分为难或简单,检验三次考试难度是否一样。
Kappa一致性检验 定类数据的相关性检验,检验两两变量之间是否显著相似即相似度(若为Flesis Kappa则要求三组或以上的定类变量且得出的是变量整体的一致性程度)
Kendall一致性检验 和谐系数,三组或以上的定类变量在若干个评分者中的整体一致性程度(区分Kappa系数、Pearson系数是比较两项之间的相关性)
组内相关系数 ICC,衡量和评价观察者间信度和复测信度的信度系数,两项或以上的定量变量或有序定类变量(量表量数据)是否具有一致性(信度大小)
6. 预测模型
预测模型,常见的类型是回归分析
线性回归(最小二乘法)至少一个自变量(定量变量或二分类定类变量)与因变量定量变量的线性回归,若是多元自变量则会拟合出多段直线
岭回归(Ridge) 最小二乘法的改良版,专用于共线性数据分析的有偏估计回归方法,牺牲部分信息、降低精度以获得更符合实际更可靠的回归方法。注意当因变量为定类变量时需用逻辑回归
分层回归 分层回归将核心研究的变量放在最后一步进入模型,以考察在排除了其他变量的贡献的情况下,该变量对回归方程的贡献。如果变量仍然有明显的贡献,那么就可以做出该变量确实具有其他变量所不能替代的独特作用的结论。常将难以确定是否有独特贡献的一个自变量放在第一层,第二层放核心研究变量,再指向因变量。
灰色预测模型GM(1,1) 对含有不确定因素的系统进行预测的方法,进行关联分析对原始数据生成变化规律。对于小于20个的时间序列的定量变量做出中短期预测
聚类分析(K-Means) 又称为K-均值聚类分析,用迭代法将样本分到 K个类中,使得每个样本与其所属类的中心或均值的距离之和最小。即将样本(可以含有多个变量)划分成预设个数的组别中
逻辑回归 研究定类变量(二分类或者多分类)因变量与一些影响因素(定类变量或定量变量均可)之间关系
Lasso回归 一种替代最小二乘法的压缩估计方法,建立一个 L1 正则化模型,在模型建立过程中会压缩一些系数和设定一些系数为零,当模型训练完成后,这些权值等于 0 的参数就可以舍去,从而使模型更为简单,并且有效防止模型过拟合。自变量为至少一个定量变量或二分类定类变量,因变量为定量变量
分层聚类 把一个数据集分割成不同的类或簇,作出一个变量划分的树状图(一定是二叉树,因为每次合并两个最接近的),再按照划分数对其进行选取。注意样本量不能太大,样本水平要比较接近(否则要先标准化处理)
有序逻辑回归 适用于因变量为有序定类变量,自变量是定量变量或定类变量(但要哑变量)的回归系数估计
偏最小二乘回归(PLSR) 多因变量(连续的定量变量)对多自变量(连续的定量变量或定类变量)的回归建模方法
客户价值划分(RFM) 用定量变量(最近一次消费间隔)、定量变量(消费频率)、定量变量(消费金额)和定类变量(索引变量)来衡量客户价值和客户创造利益能力,给客户分类定性
二分类概率单位回归(Probit) 分析多个自变量对二分类定类因变量Y的影响(注意里面所有的定类变量必须分类全面且互斥)
Deming's回归 在OLS(普通最小二乘法)的基础上同时考虑了自变量X和因变量Y的残差波动,无需无明显误差
Day10 2023年7月25日 星期二
国赛做题技巧及注意事项: https://www.zhihu.com/question/548364663/answer/2674633717
数据分析
7. 统计建模
统计建模,就是局部处理、合并、降维变量,并找出其关联性。
主成分分析(PCA) 以最少的维度解释原数据中尽可能多的信息为目标进行降维,这里的降维是使得新变量彼此线性无关,可以线性组合出原来的所有变量,且越往后比重越小(区别因子分析,因子分析保留的一定是原来数据的公共因子,这里可能是新的组合)
典型相关分析 多个变量和多个变量之间的线性相关关系,合并一些变量成为线性组合,一直合并知道剩下的变量已经线性相关,且自变量组和因变量组获得最大的相关系数
泊松分布检验 一个小概率事件在单位时间内发生的次数,且这个时间发生的频数不受时间及历史状态的影响
游程检验 本质是独立性检验,根据样本标志表现排列所形成的游程的多少进行判断(小灯泡寿命),即看某件事情发生的概率是否随机
逐步回归 以线性回归为基础,逐次引入变量,删除无用变量,直到没有新变量引入也没有旧变量删除,从而保证回归模型的每一个变量都有意义
线性判别 LDA,Fisher判别法,将样本投影到一条直线上,使得同类样本尽可能接近,所以也用于数据降维。同样的也是类似K-均值聚类的一种分类方法
关联分析 从大量数据中发现相互依赖关系和关联关系,针对待分析的定类变量和索引变量得出关联关系
8. 计量经济模型
计量经济模型,就是时间序列预测和进阶版的回归分析。
时间序列分析
单位根检验(ADF) 检测序列是否存在单位根从而确定时间序列是否平稳,有单位根则不平稳
差分分析 非平稳序列可通过差分变换转化为平稳序列,可以高阶差分,一般最多到2阶
(偏)自相关分析(pacf/acf) 自身某种程度的相关性,用于时间序列分析 AR、MA 的 p、q 进行定阶
时间序列分析(ARIMA) 自回归移动平均模型,用来进行时间序列预测的模型
GARCH模型 模拟时间序列变量的波动性的变化,并计算条件方差
格兰杰因果检验 检验一组时间序列是否为另一组时间序列的原因,若为格兰杰原因,则前者的变化会引起后者的变化
VAR向量自回归 用于估计多个变量之间的动态关系,分别对于每一个变量作为因变量Y时列出其他变量的滞后值为自变量的方程
季节性ARIMA模型 能识别数据的周期性效应(ARIMA的周期性/季节性进阶版)
进阶回归模型
稳健回归(RANSAC) 线性回归(OLS)异常点检测,是OLS的进阶,可以找出对模型影响最大的点
分位数回归 不同分位点处自变量 X 对于因变量 Y 的影响变化趋势,也研究不同分位点处哪些自变量X是主要影响因素
面板模型 综合样本信息来研究自变量 X 在时间序列上的数据对因变量 Y 的影响
两阶段回归 解决标准线性回归模型无法解决的内生性问题(内生性问题通常由 X 变量遗漏、X->Y 时 X 与 Y 没有相关关系、XY 双向影响三类产生),第一阶段,被解释变量(内生变量)与解释变量(工具变量、外生变量)进行回归,得到内生变量的拟合值;第二阶段,被解释变量(因变量)与解释变量(内生变量的拟合值、外生变量)进行回归
GMM估计 解决内生性问题的其中一种方法(另外一种是TSLS)
双重差分DID(倍差法) 观测数据模拟实验研究设计,对照组和实验组反映政策的净影响,即比较实验组和对照组的差值
Tobit回归 归并回归,专用于因变量 Y 取值范围有限制(一般是上下限)的改进性回归模型,中间连续部分的概率密度不变,而上限/下线的概率被挤到一个点上
计数数据回归 因变量Y只能取非负整数,则称此类数据为计数数据,常用模型有泊松回归、负二项回归
倾向得分匹配分组回归 用于比较实验组与控制组的结果变量是否存在差异,研究变量为二分类变量;结果变量为定量变量;干扰变量为定量变量,若为定类变量,建议自行对其进行哑变量化后再进行处理。
9. 医学统计模型
医学统计模型,就是有关医学、治疗具体背景的卡方分析模型
比例风险回归(COX回归) 以最终结局和生存时间为因变量,同时分析众多因素对生存时间的影响
Kaplan-Meier生存曲线 给定时间变量(生存时间),状态变量(患者状态),分析单一因素(是否给药)对生存期的影响
Ridit分析 研究定类变量自变量对有序定类变量因变量是否有差异性,且具体表现在哪里,例如三种药物对于疾病的疗效情况,来分析三种药物的疗效是否有显著差异,疗效为无效(1)、有效(2)、显效(3)、痊愈(4)(区分卡方检验,卡方检验只能得出是否有差异性,不能了解差异的源头)
卡方检验(自动选取最优求解器) (自动选取最优求解器)在Pearson卡方检验、Yates卡方检验、Fisher精确检验中选中,自动分析自变量和因变量(都是定类变量)是否有差异性
Pearson卡方检验 包括适配度检验和独立性检验,这里默认为独立性检验,适配度检验见 SPSSPRO【卡方拟合优度检验】
Yates校正卡方检验 在小样本情况下,降低将离散型频数数据近似到连续性卡方统计量的过程中的误差,即校正Pearson法中的误差
Fisher精确检验 当样本总量小于 40,或任何格子出现期望频数 T<1,或检验所得的 P 值接近于检验水准α,更适合使用 Fisher 精确检验
分层卡方分析 一个定类变量自变量 X 与定类变量因变量 Y,一个分层项(混杂变量 Z)(22k模型,即X和Y均是二元分类,Z有k个水平分类)。检验混杂变量 Z 是否具有意义;混杂变量 Z 不同分组的卡方检验结果以及整体卡方检验结果。
配对卡方检验 比较同一样本用A,B两种方法处理或样本前后对比的是否存在差异性
重复测量方差 一种用于重复测量数据的方差分析,通过分解方差-协方差矩阵代替对方差的分解。而重复测量数据,是一种医学研究常用数据,通过对不同时间点对同一对象的同一观察指标进行多次测量得到,该数据不具备独立性。由组内变量(大于等于2个)与因变量和个体变量,以及可选的组间变量可研究出组间、组内不同水平之间是否存在差异以及组间随着组内变量的变化趋势。(例如男女各50人分别测量吃早餐后4个给定时间点的血糖浓度,分析男女之间和各时间点之间是否存在差异)
条件逻辑回归 在配对数据使用非条件逻辑回归常高估了OR值,而条件逻辑回归考虑到了数据的分层和匹配情况,从而解决这个问题。其中配对数据一般是具有特定条件或属性的病例受试者与没有该条件的n个对照受试者相匹配而组成的。因变量Y为二分类定类变量,自变量X至少一项为定类变量或定量变量,其中二分类的变量选取会以一定的配比进行(例如1:2)
Bland-Altman法 可视化进行一致性检验的方法。其原理是一种用 2 种方法结果的差值、均值及 95%一致性(LoA)绘制图形直观的方法,从而得出 2 种方法结果是否具有一致性,但这两种方法侧重点不一样
竞争风险模型 一种考虑了竞争风险的改进生存分析模型,例如白血病移植血细胞有可能会很快死亡,有可能过后复发,这些都是风险。
10. 机器学习分类
机器学习分类,就是用机器学习的方法对数据集进行分类定性。
决策树分类 用树状结构把各个属性进行分割,节点后继对应一个属性的可能性,叶子节点输出变量的众数就是分类结果,总体来说,就是通过树形结构对含有多个属性的实例进行分类,例如某一层的分类标准为a>100,10<a<=100,a<=10,分成三叉树
随机森林分类 随机选取样本和特征,每次生成一颗决策树,对分类问题:采用投票的方式得到分类结果;对回归问题,计算均值作为结果。(由于随机森林具有随机性,每次运算的结果不一样)(具备优良的抗过拟合 以及抗噪能力),减少极端数据对最终情况的影响
adaboost分类 多次迭代,每次提高被他错分的样本权重,降低正确分类的样本权重,使得越到后面训练更注重难以识别的样本,直到样本被正确分类,本质上就是通过多次迭代的弱约束判断(迭代弱分类器),来不断细微调整各因素的权重(这里指的是从每次迭代的结果上来说)来试错,直到能够分类那些难以识别的样本(有随机性)
梯度提升树(GBDT)分类 cart回归树,类似二叉搜素的决策树。GBDT以cart回归树为基学习器,解决一般损失函数的优化问题。通过损失函数的负梯度拟合前一轮基学习器的残差,使每轮残差估计减小,加速收敛到局部或全局最优解(有随机性)
CatBoost分类 一种GBDT框架的树,对称决策树,每一层的所有左右子树的分类判断都是一样的,前一棵树的叶子都使用相同的条件进行拆分。CatBoost分类基于对称决策树算法的GBDT框架,高效合理地处理类别型特征和处理梯度偏差、预测偏移问题,提高算法的准确性和泛化能力(有随机性)
ExtraTrees分类 极其随机的森林,直接使用随机的特征(每次只选取某几个变量)和随机的阈值(权值)划分,每一棵决策树形状、差异就会更大、更随机。提高了对次优解的准确性和求解计算的灵活性(有随机性),是随机森林的进阶版
K近邻(KNN)分类 有监督学习中的分类算法,通过K个最近的实例投票决定新实例的类别。简单来说,就是离得近的k各为一类。(不需要训练),多少维度都可以,只看距离的远近
bp神经网络分类 按误差逆传播算法训练的多层前馈网络,使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的分类错误率最小。(简单来说,调整输入到隐含层到输出方向各节点之间的权值和阈值来缩小误差(类似网络流的图))(有随机性)
支持向量机(SVM)分类 按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。SVM就是找到各类样本点到超平面的最近距离最远,简单来说,就是把两类东西分到平面两边,并且使得两边到平面的距离最远(三维中)(有随机性)
XGBoost分类 GBDT的一种高效实现(进阶版),xgboost给损失函数增加了正则化项,并使用损失函数的二阶泰勒展开作为损失函数的拟合
LightGBM分类 XGBoost 一种高效实现,直接选取k个拟合函数的特征点,当k取比较大的时候,离散特征值构造直方图,在特征选择时根据直方图变量寻找最优分割点,并使用leaf-wise策略,节省时间和空间
朴素贝叶斯分类 假设特征之间强独立(朴素),用贝叶斯定理来返回简单概率分类器(有概率,不确定)
逻辑回归(梯度下降法) 一种名为“回归”的线性分类器,由线性回归变化而来的广义回归算法(随机性)
11. 机器学习回归
机器学习回归,就是用机器学习的方法对数据集求均值或其他的特征值。
方法与机器学习分类完全一致。
12. 研究模型
研究模型
需求优先级分析 基于 Kano 模型,对产品功能定位以及确定产品功能优先级
词云图 某词的出现频次越多,说明越重要,在词云图中的字体就越大
用户满意度分析 基于NPS净推荐值分析,计量某个客户将会向其他人推荐某个企业或服务可能性
趋势相关分析 基于灰色关联分析,根据序列的曲线几何形状的相似程度来判断其联系是否紧密,用来找主要因素
销售量预测 用ARIMA 模型(样本量 ≤20)或 XGBoost 模型(样本量>20)预测产品销量
PP图-QQ图 用于检验数据与某一特定分布是否相似,P-P 图比较的是真实的数据和待检验分布的累计概率,而 Q-Q 图比较的是真实数据和待检验分布的分位点数
产品定价模型 基于价格断裂点模型,先设几个价格调查用户是否接受,确定产品的最优价格以及分析产品价格变化对需求的影响
价格敏感度分析 研究问题与前者一样,能够得到最高价格,最优价格,和中位价格
ROC曲线 用于判断某检验变量是否能够良好地区分某状态变量,曲线面积越大说明效果越好
Day11 2023年7月26日 星期三
task: 2021B 乙醇制备 - 第一题
研究因变量Y和自变量X的关系 通法:
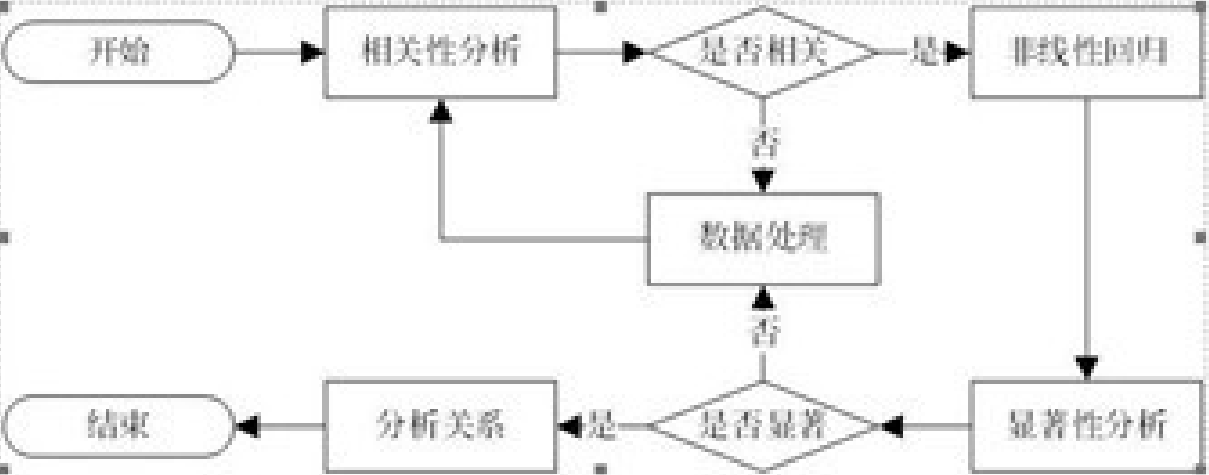
还可以加上一些其他的技巧,例如对自变量X进行降维、合并。
本题第一问还有一个有亮点的做法,就是事先对21种催化剂组合进行分类,分别阐述每一类的特征。
从建模的角度,发现这种数据分析题的建模方法,拟合曲线可能是多样的,但是每种只需要贴合实际言之有理都是正确的。在建模的时候可以考虑分组来分析数据和简化建模过程。建模完成后的数据评价很重要。
Day12 2023年7月27日 星期四
task: 2021B 乙醇制备 - 第二题、第三题、第四题
Q聚类和R聚类算法:https://blog.csdn.net/m0_72410588/article/details/130654236
Python读写Excel文件:https://pythonjishu.com/qjdqmviibfsjait/
多种影响因素对某一变量的影响程度:https://www.zhihu.com/question/363638770/answer/2816259030
实验设计方法:正交设计和均匀设计 https://zhuanlan.zhihu.com/p/24812876
Day13 2023年7月28日 星期五
task: 2021C 生产企业原材料的订购与运输 - 全部
Day14 2023年7月29日 星期六
task: 评价模型,最优化模型
综合评价与决策模型:https://www.bilibili.com/video/BV16h4y1t7KA/?spm_id_from=333.337.search-card.all.click&vd_source=c149533e353798fcd208327ad194b643
套路是先用熵权法跑出每个评判项目的权值,再用其他评判方法来跑总价值。
2018B
补充
Latex常用内容汇总
https://www.cnblogs.com/liangjianli/p/11616067.html
https://www.cnblogs.com/liangjianli/p/11616847.html
https://www.cnblogs.com/liangjianli/p/11617161.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号