
单生产者单消费者无锁队列
伪共享:
下图是计算的基本结构。L1、L2、L3分别表示一级缓存、二级缓存、三级缓存,越靠近CPU的缓存,速度越快,容量也越小。所以L1缓存很小但很快,并且紧靠着在使用它的CPU内核;L2大一些,也慢一些,并且仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。
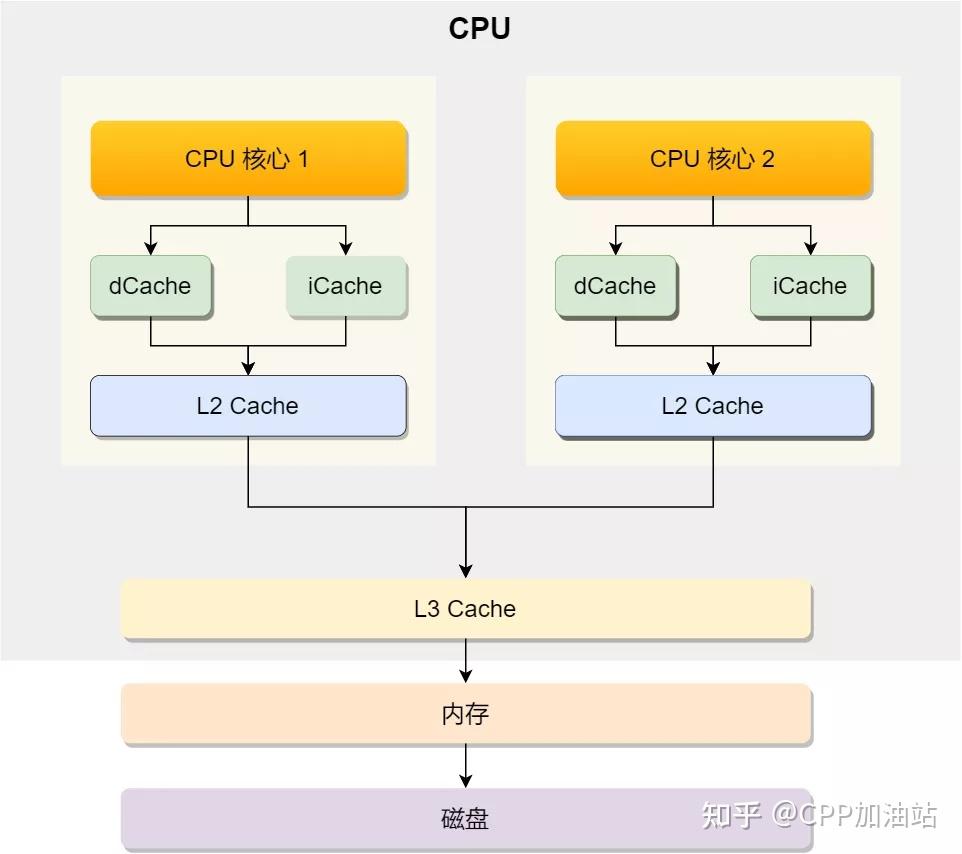
级别越小的缓存,越接近CPU, 意味着速度越快且容量越少。
- L1是最接近CPU的,它容量最小,速度最快,每个核上都有一个L1 Cache(准确地说每个核上有两个L1 Cache, 一个存数据 L1d Cache, 一个存指令 L1i Cache);
- L2 Cache 更大一些,例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2 Cache;二级缓存就是一级缓存的缓冲器:一级缓存制造成本很高因此它的容量有限,二级缓存的作用就是存储那些CPU处理时需要用到、一级缓存又无法存储的数据。
- L3 Cache是三级缓存中最大的一级,例如12MB,同时也是最慢的一级,在同一个CPU插槽之间的核共享一个L3 Cache。三级缓存和内存可以看作是二级缓存的缓冲器,它们的容量递增,但单位制造成本却递减。
L3 Cache是三级缓存中最大的一级,例如12MB,同时也是最慢的一级,在同一个CPU插槽之间的核共享一个L3 Cache。三级缓存和内存可以看作是二级缓存的缓冲器,它们的容量递增,但单位制造成本却递减。
缓存行 cache line
缓存,是由缓存行Cache Line组成的。一般一行缓存行有64字节。所以使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用;换句话说,CPU存取缓存都是按照一行,为最小单位操作的。
Cache Line可以简单的理解为CPU Cache中的最小缓存单位。目前主流的CPU Cache的Cache Line大小都是64Bytes。假设我们有一个512字节的一级缓存,那么按照64B的缓存单位大小来算,这个一级缓存所能存放的缓存个数就是512/64 = 8个。
伪共享问题
CPU的缓存系统是以缓存行(cache line)为单位存储的,一般的大小为64bytes。在多线程程序的执行过程中,存在着一种情况,多个需要频繁修改的变量存在同一个缓存行当中。
假设:有两个线程分别访问并修改X和Y这两个变量,X和Y恰好在同一个缓存行上,这两个线程分别在不同的CPU上执行。那么每个CPU分别更新好X和Y时将缓存行刷入内存时,发现有别的修改了各自缓存行内的数据,这时缓存行会失效,从L3中重新获取。这样的话,程序执行效率明显下降。为了减少这种情况的发生,其实就是避免X和Y在同一个缓存行中,可以主动添加一些无关变量将缓存行填充满,比如在X对象中添加一些变量,让它有64 Byte那么大,正好占满一个缓存行。

两个线程(Thread1 和 Thread2)同时修改一个同一个缓存行上的数据 X Y:
如果线程1打算更改a的值,而线程2准备更改b的值:
Thread1:x=3;
Thread2:y=2;
由x值被更新了,所以x值需要在线程1和线程2之间传递(从线程1到线程2),x的变更会引起整块64bytes被交换,因为cpu核之间以cache lines的形式交换数据(cache lines的大小一般为64bytes)。
每个线程在不同的核中被处理。x,y是两个频繁修改的变量,x,y,还位于同一个缓存行.
如果,CPU1修改了变量x时,L3中的缓存行数据就失效了,也就是CPU2中的缓存行数据也失效了,CPU2需要的y需要重新从内存加载。
如果,CPU2修改了变量y时,L3中的缓存行数据就失效了,也就是CPU1中的缓存行数据也失效了,CPU1需要的x需要重新从内存加载。
x,y在两个cpu上进行修改,本来应该是互不影响的,但是由于缓存行在一起,导致了相互受到了影响。
对缓存行中的单个变量进行修改了,导致整个缓存行数据也就失效了,并且,会导致其他CPU的含有被改动的共享变量的缓存行也失效了,就是所谓的伪共享问题。
而缓存行是为了解决缓存一致性的问题,所引入的。所以,解决缓存一致性的问题,又导致了伪共享问题的出现。
block
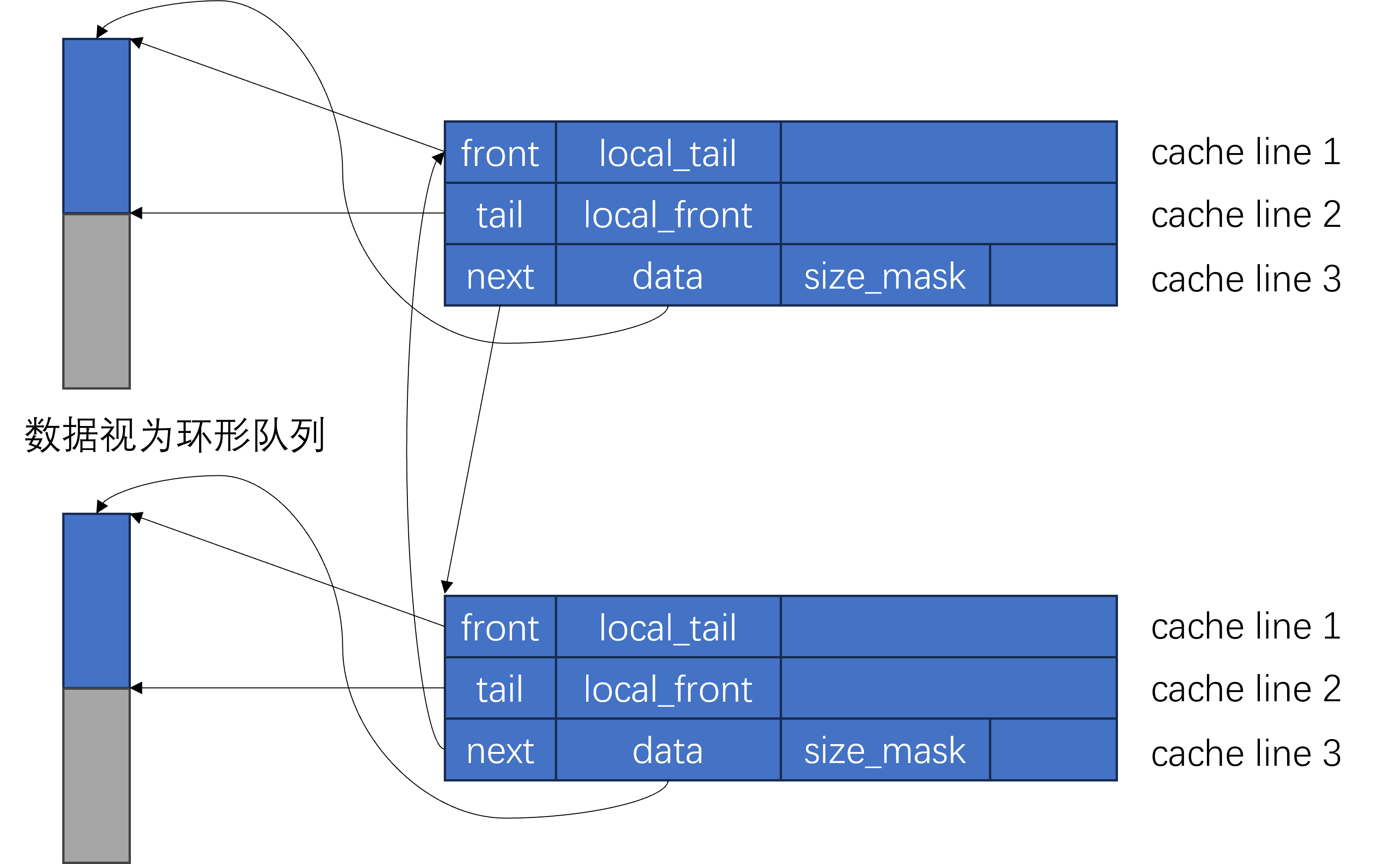
队列被组织为一个一个的缓冲块所构成的循环单链表:
- 每个块里都有一个缓冲区
data,用于构造T对象. front,tail表示data中存放数据的其实位置和末尾位置,相当于data就是一个数组构成小型队列。都为原子类型。- 在实现中,块的内存向
cache line对齐,大小为64,由于多个线程会频繁的访问front和tail,因此需要将它们分别放到不同的cache line为了防止伪共享问题。
TODO: 有空再更。
