
线程池
https://github.com/CodingHanYa/workspace
包括组件:阻塞队列;
阻塞队列
阻塞队列是线程池中用于管理任务的核心组件,它提供线程安全的任务队列,确保多个线程可以安全地向队列中添加任务或从队列中取任务。每次执行push_back或emplace_back时,队列都会加锁,以避免并发写入导致的数据竞争。
- 线程安全性: 使用
std::mutex保护队列的读写操作,确保线程间的同步。 - 灵活性: 支持在队列前后插入元素(
push_front和push_back),使任务调度更为灵活。 - 尝试弹出:
try_pop方法允许尝试从队列中获取元素,如果队列为空,则返回false,否则将返回队列前端的任务。这种非阻塞方式能够避免线程在获取任务时被永久阻塞。
template <typename T>
class BlockingQueue {
public:
using size_type = typename std::deque<T>::size_type;
BlockingQueue() = default;
BlockingQueue(const BlockingQueue&) = delete;
BlockingQueue(BlockingQueue&&) = default;
BlockingQueue& operator=(const BlockingQueue&) = delete;
BlockingQueue& operator=(BlockingQueue&&) = default;
void push_back(const T& v) {
std::lock_guard<std::mutex> lock(mtx_);
data_.push_back(v);
}
void push_back(T&& v) {
std::lock_guard<std::mutex> lock(mtx_);
data_.push_back(std::move(v));
}
void emplace_back(const T& v) {
std::lock_guard<std::mutex> lock(mtx_);
data_.emplace_back(v);
}
void emplace_back(T&& v) {
std::lock_guard<std::mutex> lock(mtx_);
data_.emplace_back(std::move(v));
}
void push_front(const T& v) {
std::lock_guard<std::mutex> lock(mtx_);
data_.push_front(v);
}
void push_front(T&& v) {
std::lock_guard<std::mutex> lock(mtx_);
data_.push_front(std::move(v));
}
void emplace_front(const T& v) {
std::lock_guard<std::mutex> lock(mtx_);
data_.emplace_front(v);
}
void emplace_front(T&& v) {
std::lock_guard<std::mutex> lock(mtx_);
data_.emplace_front(std::move(v));
}
bool try_pop(T& v) {
std::lock_guard<std::mutex> lock(mtx_);
if(!data_.empty()) {
v = std::move(data_.front());
data_.pop_front();
return true;
}
return false;
}
size_type size() const {
std::lock_guard<std::mutex> lock(mtx_);
return data_.size();
}
private:
mutable std::mutex mtx_;
std::deque<T> data_;
};
线程封装
std::thread 不可拷贝与不可赋值
std::thread t1([](){ /* do something */ });
std::thread t2 = t1; // 错误:std::thread 不允许拷贝构造
- 不可拷贝性:
std::thread明确禁止了拷贝构造和拷贝赋值操作。这是因为拷贝一个线程会导致两个线程对象共享相同的底层线程资源,而这会引发严重的并发问题,如资源竞争、双重释放等。因此,C++ 标准库选择不支持这种危险的操作。 - 不可赋值性: 同样地,
std::thread不支持赋值操作,因为赋值意味着在另一个线程对象上释放或转移资源,这会带来线程状态混乱。线程的运行状态、资源的所有权是独立且唯一的,无法简单地复制或共享。
std::thread 可移动
std::thread t1([](){ /* do something */ });
std::thread t2 = std::move(t1); // 合法:std::thread 支持移动
可移动性: std::thread 是可移动的,允许使用移动构造函数或移动赋值操作将一个线程对象的资源转移给另一个线程对象。这种机制允许将线程的所有权转交给另一个对象,避免线程资源的浪费或不必要的占用。
当一个 std::thread 对象被移动后,原来的对象将变为无效状态,表示不再与任何线程关联。通常情况下,这样的无效线程可以通过调用 joinable() 来检查其状态(如果返回 false,则表示没有关联的线程)。
移动语义提供了一种高效且安全的方式来管理线程的生命周期,特别是在需要动态分配或转移线程所有权的场景中。
为什么需要管理 std::thread 的生命周期
线程的生命周期管理是指确保在线程运行结束后,相关的资源(如内存、系统句柄等)能被正确释放。这不仅仅是一个性能问题,更关乎程序的正确性和稳定性。以下是管理 std::thread 生命周期的几个重要原因:
- 避免资源泄漏: 每个
std::thread对象在创建时都会占用系统资源(如线程句柄、堆栈空间等)。如果不正确管理线程的生命周期(例如没有 join 或 detach 线程),这些资源将得不到释放,导致资源泄漏。 - 防止程序崩溃: 当一个
std::thread对象被销毁时,如果它仍然是可join的(即线程没有结束或没有调用 join()),程序会异常终止。这是为了防止程序无意中丢失对线程的控制,导致难以追踪的并发问题。因此,必须在线程对象销毁前明确管理它的状态。 - 确保线程同步: 使用
join()可以确保主线程等待子线程完成任务后再继续执行。这种同步操作在依赖子线程结果或任务顺序时尤为重要。如果不使用join(),主线程可能会在子线程完成之前就退出程序,导致未预料的行为。 - 防止竞争条件: 如果线程的生命周期管理不当,多个线程可能会同时访问共享资源而没有同步机制,导致数据竞争、死锁或其他并发错误。通过正确管理线程,可以有效避免这些问题。
RAII管理
线程封装类AutoThread负责管理线程的生命周期,确保线程在任务完成后能够正确处理(如join或detach)。线程封装提供了方便的RAII机制,自动管理线程的资源。
- join模式: AutoThread
封装了线程的join操作,确保线程在析构时被安全地回收,避免线程资源泄漏。 - detach模式: AutoThread
则使用detach将线程分离,允许线程在后台独立执行,不会阻塞主线程。 - 移动语义支持: 通过移动构造和移动赋值操作,可以安全高效地将线程转移到另一个对象中,避免不必要的拷贝。
#include <thread>
struct join{};
struct detach{};
template <typename T> class AutoThread{};
template <> class AutoThread<join>{
private:
std::thread _t;
public:
explicit AutoThread(std::thread&& t): _t(std::move(t)){}
AutoThread(const AutoThread&) = delete;
AutoThread& operator=(const AutoThread&) = delete;
AutoThread(AutoThread &&other) noexcept : _t(std::move(other._t)){}
AutoThread& operator=(AutoThread&& other) noexcept
{
if(this != &other)
{
_t= std::move(other._t);
}
return *this;
}
~AutoThread(){if(_t.joinable()) _t.join();}
using id = std::thread::id;
[[nodiscard]] id get_id() const {return t_.get_id();}
}
template <> class AutoThread<detach>{
private:
std::thread _t;
public:
explicit AutoThread(std::thread&& t): _t(std::move(t)){}
AutoThread(const AutoThread&) = delete;
AutoThread& operator=(const AutoThread&) = delete;
AutoThread(AutoThread &&other) noexcept : _t(std::move(other._t)){}
AutoThread& operator=(AutoThread&& other) noexcept
{
if(this != &other)
{
_t= std::move(other._t);
}
return *this;
}
~AutoThread(){if(_t.joinable()) _t.detach();}
using id = std::thread::id;
[[nodiscard]] id get_id() const {return t_.get_id();}
}
futures封装
std::future 是 C++11 引入的用于异步操作结果获取的类,它和 std::promise、std::async 等一起构成了标准库中的异步任务框架。与 std::thread 类似,std::future 也是不可拷贝、不可赋值的,但它是可移动的。正确管理 std::future 的生命周期也至关重要,以确保异步任务结果能够安全可靠地获取和处理。
std::future 不可拷贝与不可赋值
- 不可拷贝性:
std::future对象不允许被拷贝。这是因为std::future代表了一个一次性异步操作的结果,拷贝一个std::future会产生两个对象共享同一个结果,这可能会导致不确定的行为。为了避免同一结果被多个std::future同时使用,C++ 标准明确禁止了拷贝构造和赋值操作。 - 不可赋值性: 同样,
std::future也不允许通过赋值来共享结果。赋值操作可能导致多个future对象同时访问同一个异步结果,而结果的状态是唯一的、不可共享的。
std::future 可移动
std::future<int> fut1 = std::async([]{ return 42; });
std::future<int> fut2 = std::move(fut1); // 合法:std::future 支持移动
可移动性: std::future 是可移动的,允许通过移动构造函数或移动赋值操作将 future 对象的所有权转移给另一个 future 对象。这意味着一个 future 对象的异步结果可以安全地从一个对象转移到另一个对象,而不会出现数据竞争或资源共享的问题。
移动语义对于 std::future 特别重要,因为它允许异步操作的结果所有权能够在多个线程或对象之间有效转移,而不会引起结果的多次访问或重复计算。
当一个 std::future 被移动之后,原来的 future 对象将不再有效,其状态会变为“无效状态”,即 valid() 方法将返回false。
std::future<int> fut = std::async([]{ return 42; });
std::future<int> fut2 = fut; // 错误:std::future 不允许拷贝构造
future封装队列deque
template <typename T>
class futures{
private:
std::deque<std::future<T>> _futs;
public:
using iterator = typename std::deque<std::future<T>>::iterator;
void wait(){for(auto &each_f: _futs) each_f.wait();}
[[nodiscard]] std::size_t size() const {return _futs.size();}
std::vector<T> get(){
std::vector<T> res(_futs.size());
for(auto& f: _futs){res.emplace_back(f.get());}
return res;
}
iterator begin() {return _futs.begin();}
iterator end() {return _futs.end();}
void push_front(std::future<T>&& fut){_futs.emplace_front(std::move(fut));}
void push_back(std::future<T>&& fut){_futs.emplace_back(std::move(fut));}
void for_each(iterator first, std::function<void(std::future<T> &)> deal){
for(auto it = first; it != _futs.end(); ++it){deal(*it);}
}
void for_each(iterator first, iterator last,std::function<void(std::future<T> &)> deal){
for(auto it = first; it != last; ++it){deal(*it);}
}
std::future<T>& operator[](const std::size_t idx){return _futs[idx];}
}
任务队列
在这个线程池中,任务队列被定义为 BlockingQueue<std::function<void()>>,即一个存储 std::function<void()> 类型的双端队列。std::function<void()> 表示可调用对象,这些对象既可以是普通函数、lambda 函数,也可以是成员函数。
这个任务队列支持三种不同的任务类型,每种类型根据它的优先级或需求被放置在队列的不同位置:
normal:一般任务,任务会被添加到队列的尾部,按照先进先出(FIFO)规则进行执行。
urgent:紧急任务,这类任务的优先级更高,任务会被插入到队列的头部,优先被执行。
sequence:任务序列,可以一次性添加多个任务,这些任务会被打包成一个顺序执行的函数,整体作为一个任务被放置在队列的末尾。这样保证了这些任务按照顺序被执行。
task_warpper
为了确保任务能够被安全地执行,并且在发生异常时进行捕获,所有任务都会通过 task_wrapper 进行封装。这是为了确保 std::function<void()> 的类型统一,同时捕获执行过程中抛出的异常。
template <typename F>
static std::function<void> task_warpper(F&& task){
auto res = [task](){
try{
task();
} catch (const std::exception& ex){
std::cerr<<"workspace: worker["<< std::this_thread::get_id()<<"] caught exception:\n what(): "<<ex.what()<<'\n'<<std::flush;
} catch (...){
std::cerr<<"workspace: worker["<< std::this_thread::get_id()<<"] caught unknown exception\n"<<std::flush;
}
}
return res;
}
无返回值的submit
为了使得任务队列支持三种不同类型的任务,使用模板参数 T 来表达任务类型。每种任务类型对应不同的入队规则,normal、urgent 和 sequence 分别将任务放置在队列的不同位置。
-
std::enable_if_t的作用:std::enable_if_t是 C++11 中std::enable_if的简便形式,std::enable_if是一种SFINAE(Substitution Failure Is Not An Error)机制的实现,通常用于在模板实例化时进行条件限制。它能够根据条件决定某个模板是否可用,避免无效代码的生成。在 std::enable_if 中,只有当条件为 true 时,模板才会被实例化,反之则不会生成该模板代码。常见的用法是限制某个函数或类模板的使用条件。 -
std::is_void_v<R>的作用:std::is_void_v<R>是 C++17 中提供的类型特征,它返回一个布尔值,表示类型R是否为void。在 C++11 或 C++14 中,这个可以写作std::is_void<R>::value。std::is_void_v<R>用于判断任务的返回值R是否为void,这样可以区分无返回值任务和有返回值任务,便于不同的处理逻辑。 -
std::is_same_v<T, normal>的作用:std::is_same_v<T, normal>也是 C++17 的类型特征,返回一个布尔值,表示类型T是否与normal类型相同。它在 C++11 和 C++14 中写作std::is_same<T, normal>::value。std::is_same_v<T, normal>用于判断任务的类型T是否是normal类型,以选择不同的任务处理策略。
**std::enable_if_t 在 submit 函数中的作用: **
- 用于区分返回值类型(
void与非void),在处理任务时,有些任务可能会有返回值(如int、std::string等),而有些任务则没有返回值(即void)。为了确保正确处理不同的任务,你需要对submit函数进行模板实例化时的区分 - 用于区分任务类型(
normal、urgent、sequence), 处理不同优先级的任务时,你使用了std::enable_if_t来对submit函数进行不同的实例化。
noraml
使用 std::enable_if_t 和 std::is_same_v<T, normal> 确保当 T 为 normal 时才实例化这个 submit 函数。
struct normal{};
struct urgent{};
struct sequence{};
tempalte <
typename T = normal,
typename F,
typename R = std::result_of_t<F>,
typename DR = std::enable_if_t<std::if_void_v<R>>
>
auto submit(F &&task) -> std::enable_if_t<std::is_same_v<T, normal>>{
tasks.push_back(task_warpper(std::forward<F>(task)));
}
urgent
tempalte <
typename T,
typename F,
typename R = std::result_of_t<F>,
typename DR = std::enable_if_t<std::if_void_v<R>>
>
auto submit(F &&task) -> std::enable_if_t<std::is_same_v<T, urgent>>{
tasks.push_front(task_warpper(std::forward<F>(task)));
}
sequence
添加任务序列,需要将序列中的任务依次执行。通过递归展开调用可达到。
# 递归出口
template <typename F>
void rexec(F &&task){task();}
# 递归解包
tempalte <typename First, typename ...Others>
void rexec(First&& first, Others&& ...others){
first();
rexec(std::forward<Others>(others)...);
}
tempalte <
typename T,
typename ...Fs,
>
auto submit(Fs&& ...tasks) -> std::enable_if_t<std::is_same_v<T, sequence>>{
tasks.push_back(task_warpper(
[this](){
this->rexec(std::forward<Fs>(tasks)...);
}));
}
带返回值的submit
std::shared_ptr<std::promise
normal
template <
typename T = normal,
typename F,
typename R = std::result_of_t<F>,
typename DR = std::enable_if_t<!std::if_void_v<R>>
>
auto submit(F&& task, std::enable_if<std::is_same_v<T, normal>, normal> = {}) -> std::future<R>{
std::function<R()> exec(std::forward<F>(task));
std::shared_ptr<std::promise<R>> take_promise = std::make_shared<std::promise<R>>();
tasks.push_back( task_wrapper(
[exec, take_promise](){take_promise->set_value(exec());})
);
return take_promise->get_future();
}
urgent
template <
typename T = normal,
typename F,
typename R = std::result_of_t<F>,
typename DR = std::enable_if_t<!std::if_void_v<R>>
>
auto submit(F&& task, std::enable_if<std::is_same_v<T, normal>, normal> = {}) -> std::future<R>{
std::function<R()> exec(std::forward<F>(task));
std::shared_ptr<std::promise<R>> take_promise = std::make_shared<std::promise<R>>();
tasks.push_front( task_wrapper(
[exec, take_promise](){take_promise->set_value(exec());})
);
return take_promise->get_future();
}
线程池
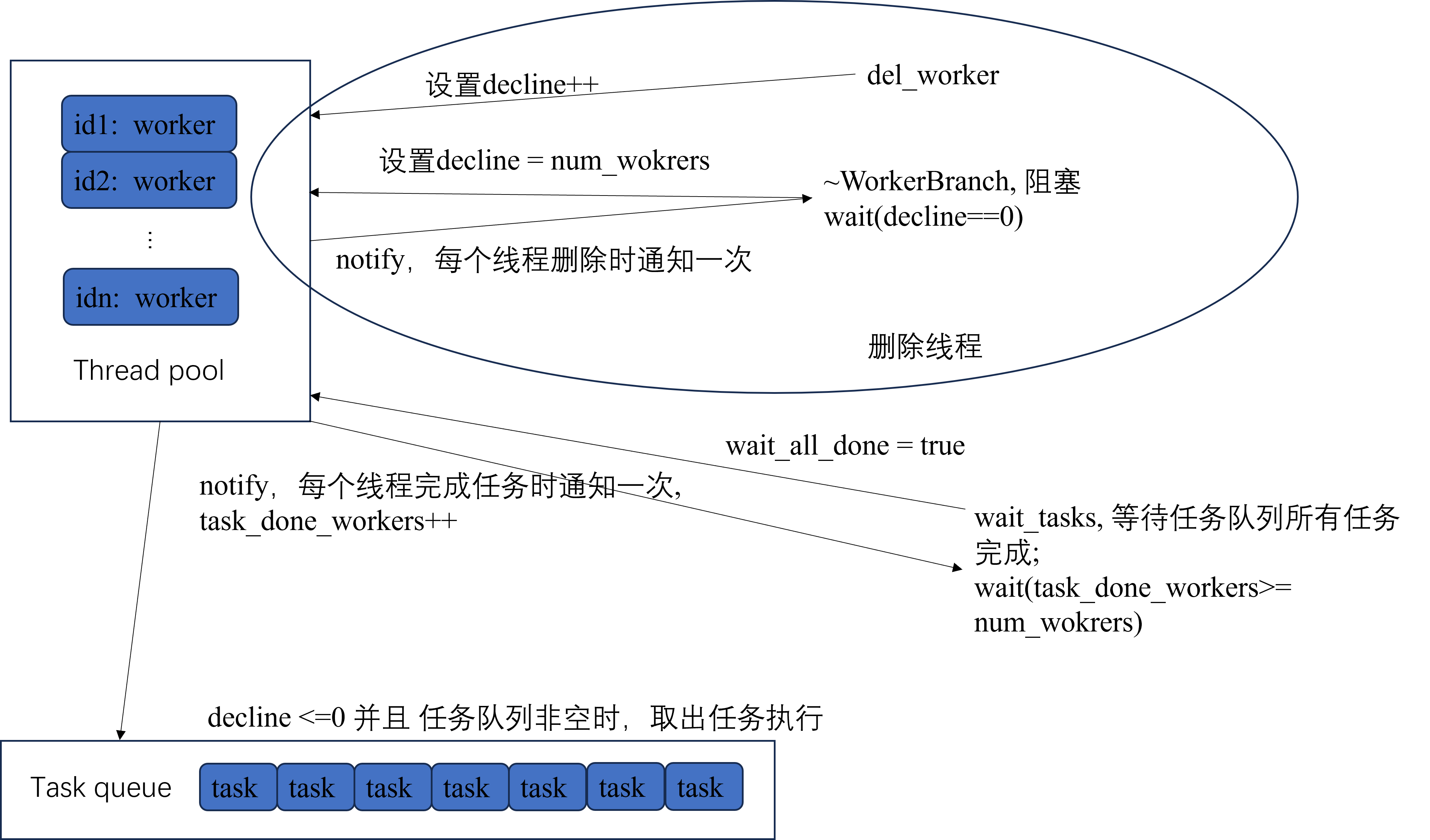
根据上面图片,线程池有四个状态:
- 线程池需要删除线程,那么通知删除线程的方式有主动删除
del_worker, 被动析构~WorkerBranch,被动析构需要被阻塞,直至所有线程都被删除。因此,需要一个bool区分是del_worker还是~WorkerBranch;需要一个int变量用于指示需要被删除线程的数量;需要一个std::mutex和std::condition_variable阻塞~WorkerBranch。 - 线程池不需要删除线程,且任务队列不为空,那么此时获取任务并执行。
- 线程池不需要删除线程,任务队列为空,且没有正在等在所有任务完成,那么此时正常让出
cpu时间片。 - 线程池不需要删除线程,任务队列为空,且正在等在所有任务完成。由于
wait_task需要被阻塞,那么阻塞条件便是空闲线程数 >= 线程池中的线程数。(可能有些线程被删除);那么这需要一个std::mutex和std::condition_variable阻塞wait_task;需要一个int变量用于指示空闲线程数量;由于判断条件是阻塞条件便是空闲线程数 >= 线程池中的线程数。, 那么当一个线程被删除时,也需要通知wait_task,因此还需要一个bool变量表明是否实在等待任务结束。
class WorkBranch {
using worker = AutoThread<detach>;
using worker_map = std::map<worker::id, worker>;
private:
worker_map workers{}; // 线程池
BlockingQueue<std::function<void()>> tasks{}; // 任务队列
bool is_destructing = false; // 是否正在被析构
int decline = 0; // 需要被删除的线程数
std::condition_variable wait_to_destruct;
int ilde_worker = 0; // 空闲进程数
bool is_waiting_task_all_done; // 是否正在等待任务结束
std::condition_variable wait_to_task_all_done;
std::condition_variable wait_to_run;
}
工作线程的增删改
由于操作的是线程池,防止多个线程同时操作导致数据竞争,因此需要一个锁锁住线程池。
private:
mutable std::mutex worker_map_mtx;
public:
std::size_t num_workers() const {
std::lock_guard<std::mutex> lock(worker_map_mtx);
return workers.size();
};
void add_worker(){
std::thread t(&WorkBranch::mission, this);
std::lock_guard<std::mutex> lock(worker_map_mtx);
workers.emplace(t.get_id(), std::move(t));
}
void del_worker(){
std::lock_guard<std::mutex> lock(worker_map_mtx);
if(workers.empty()) throw std::runtime_error("workspace: No worker in workbranch to delete");
++decline;
}
构造与析构
构造函数指定初始创建多少个线程; 析构需要等待所有线程结束,析构时的锁可以用worker_map_mtx。
public:
explicit WorkBranch(int wks=1) {
for(int i = 0; i <= std::max(wks, 1); ++i)
add_worker();
}
~WorkBranch(){
is_destructing = true;
std::unique_lock<std::mutex> lock(worker_map_mtx);
decline = workers.size();
wait_to_destruct.wait(worker_map_mtx, [this](){return decline == 0;})
}
等待所有任务结束
等待条件是ilde_worker >= workers.size()
public:
bool wait_tasks(unsigned timeout=1){
bool res;
{
std::unique_lock<std::mutex> lock(worker_map_mtx);
is_waiting_task_all_done = true;
res = wait_to_task_all_done.wait(lock, std::chrono::mileseconds(timeout), [this](){return ilde_worker >= workers.size();});
ilde_worker = 0; // 重置
is_waiting_task_all_done = false; //重置
}
wait_to_run.notify_all();
return res;
}
线程任务
void mission(){
std::function<void()> f;
while(true){
if(decline > 0) { // 需要删除,可能多个线程同时判断需要删除,因此需要double-check
std::lock_guard<std::mutex> lock(worker_map_mtx);
if(decline > 0){
--decline;
workers.erase(std::this_thread::get_id());
if(is_waiting_task_all_done) wait_to_task_all_done.notify();
if(is_destructing ) wait_to_destruct.notify();
return;
}
}
else if(tasks.try_pop(f)) f();
else if(is_waiting_task_all_done){
std::unique_lock<std::mutex> lock(worker_map_mtx);
++idle_worker;
wait_to_task_all_done.notify();
wait_to_run(lock);
}
else std::this_thread::yield();
}
}
