
并发编程数据结构-栈
有锁栈
有锁栈 - 基础线程安全栈
Stack1 是一个简单的线程安全栈实现,使用了 std::mutex 来保证 push 和 pop 操作的原子性。主要特点包括:
- 使用
std::lock_guard确保操作期间栈的线程安全。 - 提供了两种
push操作(左值引用和右值引用),优化了性能。 pop操作抛出自定义的EmptyStackError异常,以处理栈为空的情况。- 提供了
pop(T& v)和pop()两种接口,方便用户选择直接传引用或返回shared_ptr。 - 问题:用户需要不断检查
empty()并手动处理栈空的情况,这在多线程环境下并不高效。
template <typename T>
class Stack1
{
public:
Stack1() = default;
~Stack1() = default;
Stack1(const Stack1&) = delete;
Stack1& operator=(const Stack1&) = delete;
Stack1(Stack1&& other) noexcept{
std::scoped_lock lock(_mtx, other._mtx);
_stack = std::move(other._stack);
}
Stack1& operator=(Stack1&& other) noexcept
{
if(this != &other)
{
std::scoped_lock lock(_mtx, other._mtx);
_stack = std::move(other._stack);
}
return *this;
}
void push(const T&v)
{
std::lock_guard<std::mutex> lock(_mtx);
_stack.emplace(v);
}
void push(T &&v)
{
std::lock_guard<std::mutex> lock(_mtx);
_stack.emplace(std::move(v));
}
void pop(T &v)
{
std::lock_guard<std::mutex> lock(_mtx);
if(_stack.empty()) throw EmptyStackError();
v = std::move(_stack.top());
_stack.pop();
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(_mtx);
if(_stack.empty()) throw EmptyStackError();
auto res = std::make_shared<T>(std::move(_stack.top()));
_stack.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lock(_mtx);
return _stack.empty();
}
private:
std::stack<T> _stack;
mutable std::mutex _mtx;
};
有锁栈 - 引入条件变量的栈
Stack2 在 Stack1 的基础上,通过引入条件变量 std::condition_variable 改进了 pop 操作,使得线程在栈为空时可以阻塞等待,直到有数据入栈时才唤醒。
- 使用
wait_pop代替普通的pop,在栈为空时阻塞线程,避免繁琐的轮询检查。 - 每次
push操作后,会通知阻塞的线程,解除等待状态。 - 问题:在
wait_pop中,如果在获得了cv的通知之后抛出异常,导致其他的线程无法获得该notify,因此全部阻塞。
template<typename T>
class Stack2
{
public:
Stack2() = default;
~Stack2() = default;
Stack2(const Stack2&) = delete;
Stack2& operator=(const Stack2&) = delete;
Stack2(Stack2&& other) noexcept
{
std::scoped_lock lock(_mtx, other._mtx);
_stack = std::move(other._stack);
}
Stack2& operator=(Stack2&& other) noexcept
{
if(this != &other)
{
std::scoped_lock lock(_mtx, other._mtx);
_stack = std::move(other._stack);
}
return *this;
}
void push(const T& v) // 入栈,唤醒阻塞的线程
{
std::unique_lock<std::mutex> lock(_mtx);
_stack.emplace(v);
_cv.notify_one();
}
void push(T&& v) // 入栈,唤醒阻塞的线程
{
std::unique_lock<std::mutex> lock(_mtx);
_stack.emplace(std::move(v));
_cv.notify_one();
}
void wait_pop(T& v)
{
std::unique_lock<std::mutex> lock(_mtx);
_cv.wait(lock, [this]()->bool{return !_stack.empty();});
v = std::move(_stack.top());
_stack.pop();
}
std::shared_ptr<T> wait_pop()
{
std::unique_lock<std::mutex> lock(_mtx);
_cv.wait(lock, [this]()->bool{return !_stack.empty();});
auto res = std::make_shared<T>(std::move(_stack.top())); // 当此处抛出异常,由于本线程获得了cv的通知,导致其他的线程无法获得改notify,因此全部阻塞
_stack.pop();
return res;
}
void pop(T &v)
{
std::lock_guard<std::mutex> lock(_mtx);
if(_stack.empty()) throw EmptyStackError();
v = std::move(_stack.top());
_stack.pop();
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(_mtx);
if(_stack.empty()) throw EmptyStackError();
auto res = std::make_shared<T>(std::move(_stack.top()));
_stack.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lock(_mtx);
return _stack.empty();
}
private:
mutable std::mutex _mtx;
std::condition_variable _cv;
std::stack<T> _stack;
};
有锁栈- 内存提前分配的优化栈
Stack3 进一步优化了 Stack2 中的潜在问题,通过提前在 push 时进行内存分配,避免在 wait_pop 中由于内存分配失败而抛出异常。内部栈_stack中直接存储数据的shared_ptr而不是数据本身,这样在pop时避免了构造返回值shared_ptr抛出异常的问题。
将数据分配内存的时间提前到push的过程中,这样wait_pop就不会因为无法分配内存抛出异常了
template<typename T>
class Stack3
{
public:
Stack3() = default;
~Stack3() = default;
Stack3(const Stack3&) = delete;
Stack3& operator=(const Stack3&) = delete;
Stack3(Stack3&& other) noexcept
{
std::scoped_lock lock(_mtx, other._mtx);
_stack = std::move(other._stack);
}
Stack3& operator=(Stack3&& other) noexcept
{
if(this != &other)
{
std::scoped_lock lock(_mtx, other._mtx);
_stack = std::move(other._stack);
}
return *this;
}
void push(const T& v) // 入栈,唤醒阻塞的线程
{
auto t = std::make_shared<T>(v);
std::unique_lock<std::mutex> lock(_mtx);
_stack.push(t);
_cv.notify_one();
}
void push(T&& v) // 入栈,唤醒阻塞的线程
{
auto t = std::make_shared<T>(std::move(v));
std::unique_lock<std::mutex> lock(_mtx);
_stack.push(t);
_cv.notify_one();
}
void wait_pop(T& v)
{
std::unique_lock<std::mutex> lock(_mtx);
_cv.wait(lock, [this]()->bool{return !_stack.empty();});
v = std::move(*_stack.top());
_stack.pop();
}
std::shared_ptr<T> wait_pop()
{
std::unique_lock<std::mutex> lock(_mtx);
_cv.wait(lock, [this]()->bool{return !_stack.empty();});
auto res = _stack.top(); // 当此处抛出异常,由于本线程获得了cv的通知,导致其他的线程无法获得改notify,因此全部阻塞
_stack.pop();
return res;
}
void pop(T &v)
{
std::lock_guard<std::mutex> lock(_mtx);
if(_stack.empty()) throw EmptyStackError();
v = std::move(*_stack.top());
_stack.pop();
}
std::shared_ptr<T> pop()
{
std::lock_guard<std::mutex> lock(_mtx);
if(_stack.empty()) throw EmptyStackError();
auto res = _stack.top();
_stack.pop();
return res;
}
bool empty() const
{
std::lock_guard<std::mutex> lock(_mtx);
return _stack.empty();
}
private:
mutable std::mutex _mtx;
std::condition_variable _cv;
std::stack<std::shared_ptr<T>> _stack;
};
无锁栈
无锁栈需要考虑内存回收机制,pop出元素的时候不能立马删除该节点,因为可能有其他线程同时引用该节点,因此需要一种机制,当多个线程在pop中引用同一个节点时,由最后一个引用节点的线程负责回收。
下面是一个有问题的无锁栈:
template <typename T>
class LockFreeStack1
{
private:
struct Node
{
std::shared_ptr<T> data;
Node* next;
};
public:
LockFreeStack1()= default;
~LockFreeStack1() = default;
void push(const T& t)
{
auto new_node = new Node{std::make_shared<T>(t), nullptr};
new_node->next = _head.load();
while(!_head.compare_exchange_weak(new_node->next, new_node));
}
std::shared_ptr<T> pop()
{
// 当获取到old_head后,可能其他的线程在pop中也持有这个old_head,怎么安全的delete?
auto old_head = _head.load();
while(old_head && !_head.compare_exchange_weak(old_head, old_head->next)){}
return old_head? old_head->data : std::make_shared<T>();
}
private:
std::atomic<Node*> _head;
};
当线程A获取到old_head后,可能其他的线程在pop中也持有这个old_head,怎么安全的delete?
无锁栈 - 线程计数
- 线程计数 (
_threads_in_pop):LockFreeStack2使用一个std::atomic<int>的计数器 _threads_in_pop 来记录当前有多少线程正在执行pop()操作。这个计数器的目的是确保在只有一个线程正在 pop() 时,可以安全地进行内存回收。 - 延迟删除 (
_to_be_deleted):当多个线程同时执行pop()操作时,节点不能立即被删除,因此设计了一个_to_be_deleted链表,用来存放待删除的节点。这些节点在之后合适的时机(即只有一个线程执行 pop() 时)再进行统一删除。
核心逻辑:
- 在
pop()函数中,每个线程都会首先将_threads_in_pop加 1,表示自己正在进行pop()操作。 - 当一个线程发现
old_head节点已经被弹出后,它会尝试调用try_reclaim()来删除节点。 - 如果此时只有一个线程在执行
pop()(_threads_in_pop == 1),那么该线程可以直接删除待删除节点。 - 如果有多个线程在
pop(),那么该节点会被加入到_to_be_deleted链表中,并等待将来合适的时机统一删除。
关键问题: 这种设计存在一个潜在的缺陷:如果始终有多个线程在执行 pop(),那么内存中的待删除节点可能永远无法被回收。这是因为 _threads_in_pop 始终大于 1,导致删除节点的逻辑无法触发。因此,这种方法在高并发的场景下可能会导致内存无法及时释放,造成内存泄漏。
template <typename T>
class LockFreeStack2
{
private:
struct Node
{
std::shared_ptr<T> data;
Node* next;
};
public:
LockFreeStack2()= default;
~LockFreeStack2() = default;
LockFreeStack2(const LockFreeStack2&) = delete;
LockFreeStack2(LockFreeStack2&& ) = delete;
LockFreeStack2& operator=(const LockFreeStack2&) = delete;
LockFreeStack2& operator=(LockFreeStack2&&) = delete;
void push(const T& t)
{
auto new_node = new Node{std::make_shared<T>(t), nullptr};
new_node->next = _head.load();
while(!_head.compare_exchange_weak(new_node->next, new_node));
}
void push(T&& t)
{
auto new_node = new Node(std::make_shared<T>{std::move(t)), nullptr};
new_node->next = _head.load();
while(!_head.compare_exchange_weak(new_node->next, new_node));
}
std::shared_ptr<T> pop()
{
_threads_in_pop.fetch_add(1);
auto old_head = _head.load();
while(old_head && !_head.compare_exchange_weak(old_head, old_head->next)){}
auto res = std::make_shared<T>();
if(old_head) res.swap(old_head->data);
try_reclaim(old_head);
return res;
}
void pop(T& t)
{
_threads_in_pop.fetch_add(1);
auto old_head = _head.load();
while(old_head && !_head.compare_exchange_weak(old_head, old_head->next)){}
if(old_head) t = std::move(old_head->data);
try_reclaim(old_head);
}
private:
void try_reclaim(Node* old_head)
{
if(_threads_in_pop == 1) // 仅仅一个线程正在执行pop,那么就可以删除节点,以及待节点列表
{
// 获取待删除节点列表
Node* need_to_be_deleted = _to_be_deleted.exchange(nullptr);
if(!--_threads_in_pop) // 再次确保只有一个线程
{
while(need_to_be_deleted)
{
auto tmp = need_to_be_deleted;
need_to_be_deleted = need_to_be_deleted->next;
delete tmp;
}
}
else // 有多个线程,那么就将两个待删除列表合并
{
if(need_to_be_deleted)
{
auto last = need_to_be_deleted;
while(last && last->next) last = last->next;
last->next = _to_be_deleted.load();
while(!_to_be_deleted.compare_exchange_weak(last->next, need_to_be_deleted));
}
}
delete old_head; // 后续进入pop的线程必然不会持有old_head;
}
else // 有多个线程,将待删除节点添加到列表后面
{
old_head->next = _to_be_deleted.load();
while(!_to_be_deleted.compare_exchange_weak(old_head->next, old_head)){}
--_threads_in_pop;
}
}
private:
std::atomic<Node*> _head;
std::atomic<int> _threads_in_pop{};
std::atomic<Node*> _to_be_deleted;
};
无锁栈 - 共享指针管理内存
LockFreeStack3 的设计目标是通过 std::shared_ptr 的引用计数机制来实现无锁栈的内存管理。此设计的关键在于利用 shared_ptr 的自动内存管理功能,让最后一个引用的线程负责删除节点。以下是对该实现的详细解析,以及一些潜在问题的讨论和改进建议。
- 共享指针管理内存:
LockFreeStack3的设计目标是通过std::shared_ptr的引用计数机制来实现无锁栈的内存管理。此设计的关键在于利用shared_ptr的自动内存管理功能,让最后一个引用的线程负责删除节点。以下是对该实现的详细解析,以及一些潜在问题的讨论和改进建议。
**设计思路: **
- 共享指针管理内存:
LockFreeStack3使用了std::shared_ptr来管理每个栈节点 (Node) 的生命周期。当一个节点不再被任何线程引用时,shared_ptr会自动调用析构函数来回收该节点的内存。这样避免了手动管理内存,并且通过引用计数器,能够在多线程环境中实现安全的内存释放。 - 原子操作维护栈:栈的头节点
_head使用了std::shared_ptr,并通过std::atomic_load和std::atomic_compare_exchange_weak来进行原子操作。这样可以确保多个线程对_head的访问和修改是线程安全的,无需加锁。
核心问题:内存回收
无锁编程的核心挑战是如何安全地进行内存回收。即使节点从栈中被弹出,也不能立即删除,因为其他线程可能还持有该节点的引用。使用 shared_ptr 的引用计数机制可以解决这个问题。当最后一个引用该节点的线程完成操作时,shared_ptr 会自动释放该节点。
然而,shared_ptr 的引用计数操作本身可能并不是无锁的。在某些平台上,std::shared_ptr 的实现并不保证其是无锁的,因此其性能可能不如期望中的高效。
template <typename T>
class LockFreeStack3
{
private:
struct Node
{
std::shared_ptr<T> data;
std::shared_ptr<Node> next;
explicit Node(const T& t):data(std::make_shared<T>(data)){}
};
public:
LockFreeStack3()= default;
~LockFreeStack3() = default;
LockFreeStack3(const LockFreeStack3&) = delete;
LockFreeStack3(LockFreeStack3&& ) = delete;
LockFreeStack3& operator=(const LockFreeStack3&) = delete;
LockFreeStack3& operator=(LockFreeStack3&&) = delete;
void push(const T& t)
{
auto new_node = std::make_shared<Node>(t);
new_node->next = std::atomic_load(&_head);
while(!std::atomic_compare_exchange_weak(&_head, &new_node->next, new_node));
}
void push(T&& t)
{
auto new_node = std::make_shared<Node>(std::move(t));
new_node->next = std::atomic_load(&_head);
while(!std::atomic_compare_exchange_weak(&_head, &new_node->next, new_node));
}
std::shared_ptr<T> pop()
{
// 无锁编程最大的问题,内存回收
// 当获取到old_head后,可能其他的线程在pop中也持有这个old_head,怎么安全的delete?
auto old_head = std::atomic_load(&_head);
while(old_head && !std::atomic_compare_exchange_weak(&_head, &old_head, old_head->next)){}
return old_head? old_head->data : std::make_shared<T>();
}
private:
std::shared_ptr<Node> _head;
};
无锁栈 - 双引用计数
栈的结构

head是一个CountedNodePtr的原子类型:
std::atomic<CountedNodePtr> head;
CountedNodePtr封装真正的数据节点指针Node*以及它的外部计数external_count。
初始状态

初始时, head中的ptr指向nullptr,通过判断ptr是否为空来判断栈是否为空。
push操作
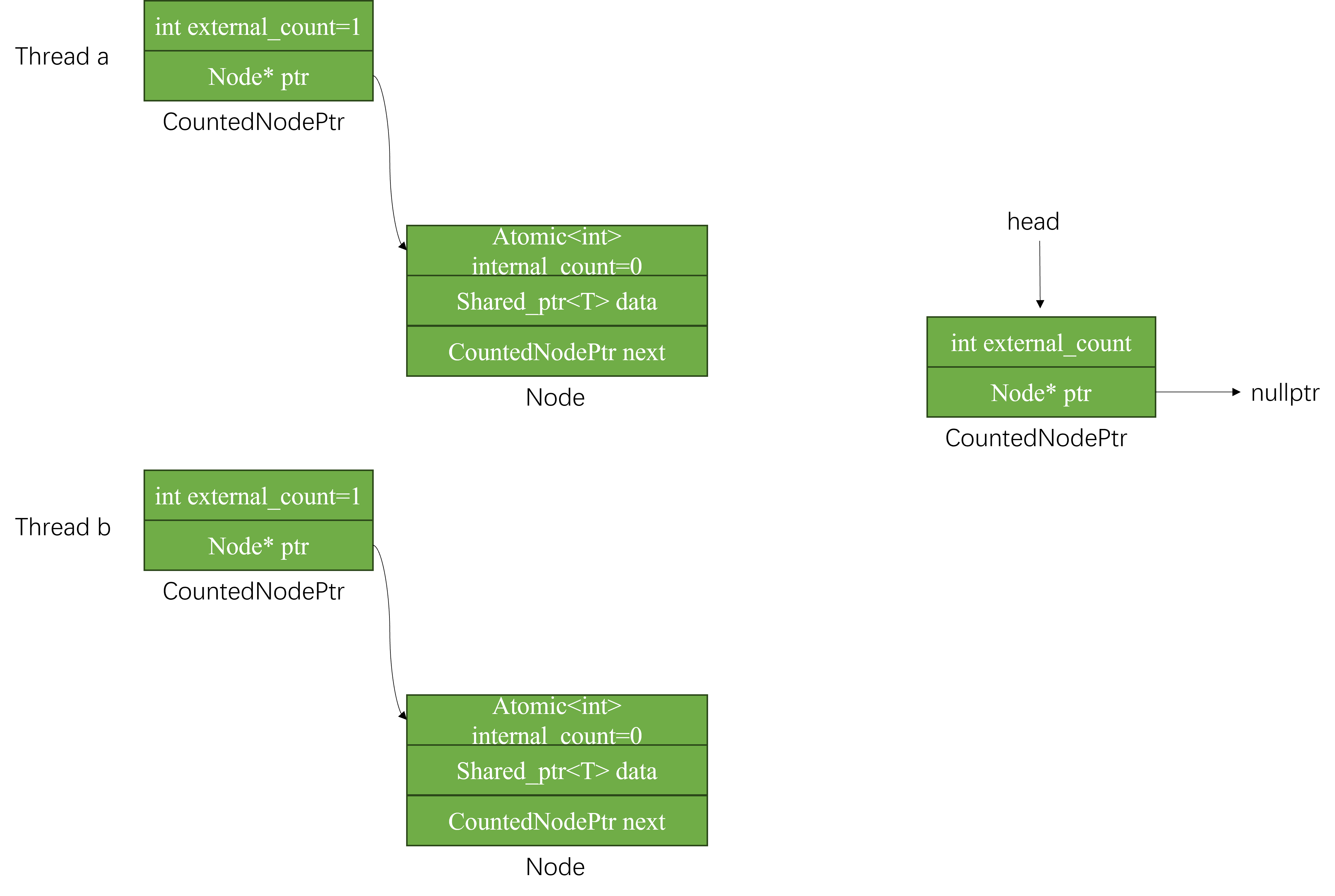
首先每个线程进入push操作时,先构建需要插入的新节点,这一阶段没有修改不变量head,因此不需要任何同步操作。
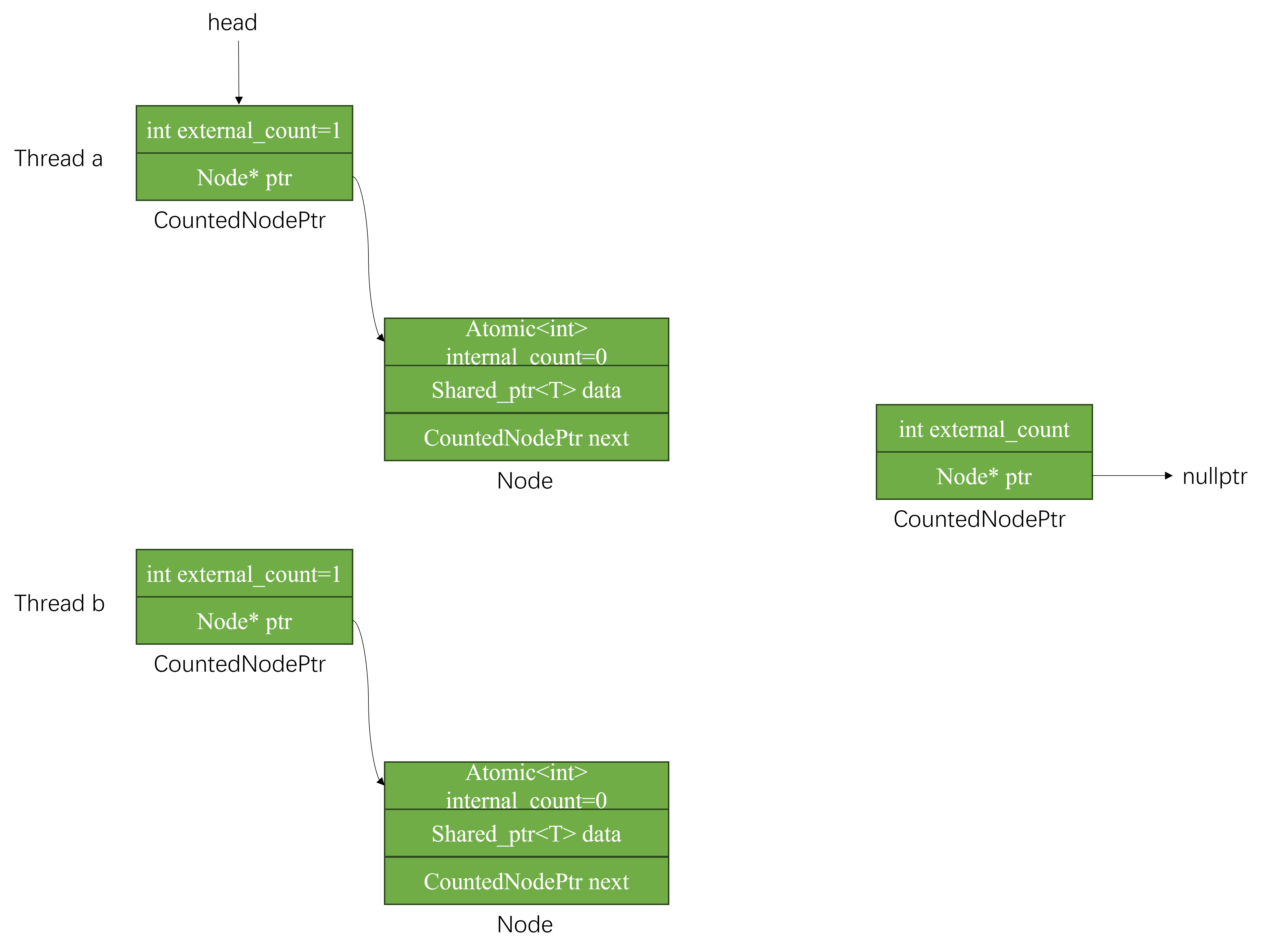
假设Thread a先push,那么需要完成的操作有两个:
- 新节点的
next指向head。 head赋值为新插入的节点。
这个过程中间,其他线程可能会修改head,因此需要不断的重试,直到一次性完成两个操作且中间无其他线程修改head。
完成的关键是CAS(Compare and Swap)操作,当发现head被修改是就不断重试。
void push(const T& t){
auto new_node = new CountedNodePtr;
auto node = new Node(t);
new_node.ptr = node;
// 不断重试
new_node.ptr->next = head.load();
while(!head.compare_exchange_weak(new_node.ptr->next, new_node));
}
pop操作
无锁栈最大的难点在于pop操作,因为回收内存时需要确保没有其他线程正在引用这个节点。
因此双引用计数,就是通过外部引用去区分是否有其他线程正在引用,内部计数去判断是否执行删除。由最后一个引用该节点的线程负责删除。
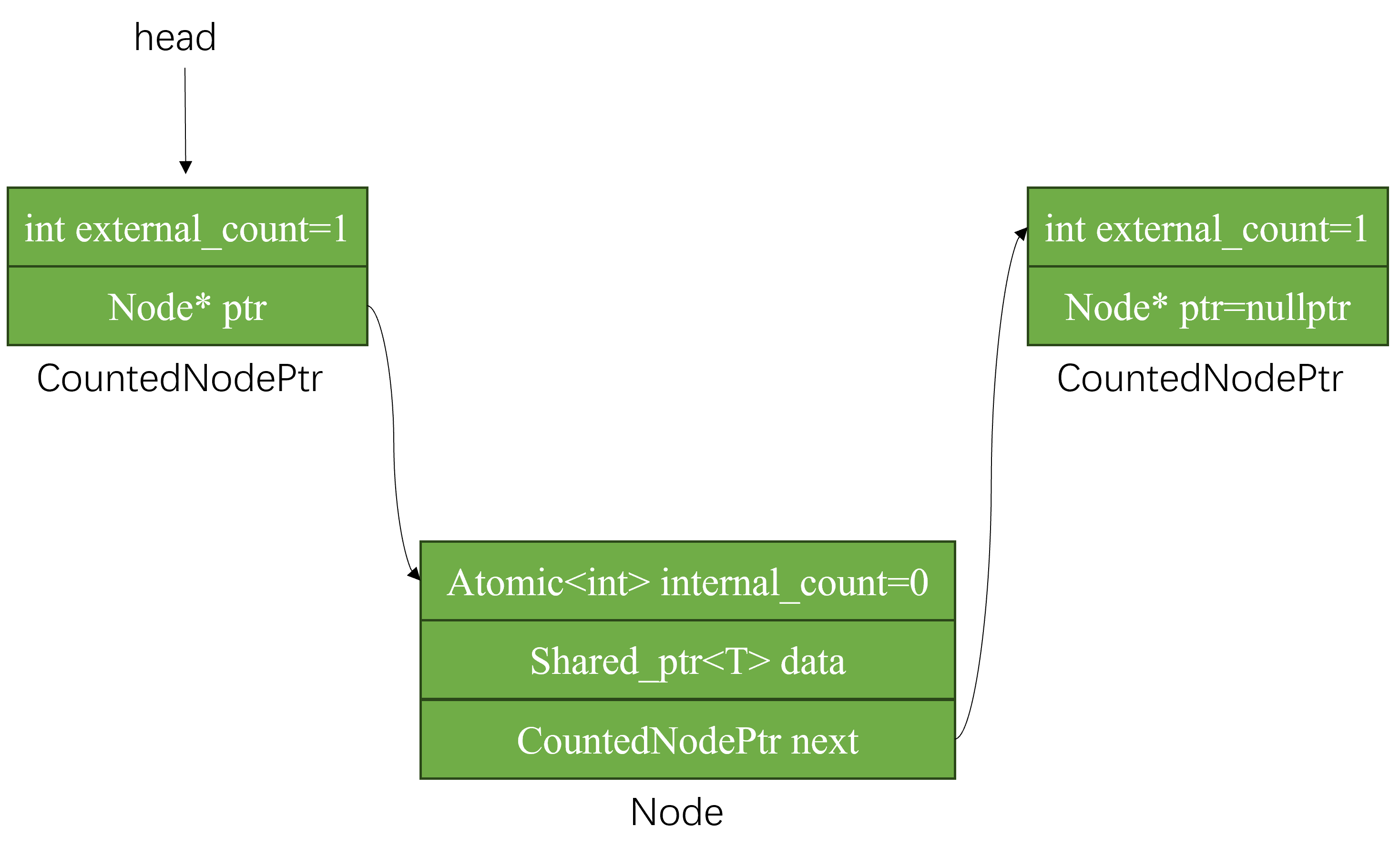
假设这是栈的状态,此时栈只有一个元素。
当某一个线程执行pop时,首先需要对external_count执行+1操作,宣告其他线程,这个节点此时已经有一个线程引用了,你们不要删除。
由于在+1还没完成时,其他线程可能修改head,因此此过程也需要不断重试:
auto old_head = head.load();
CountedNodePtr new_head;
do{
new_head = old_head;
new_head.external_count++;
}while(!head.compare_exchange_weak(old_head, new_head));
old_head.extenal_count = new_head.external_count;
+1成功后就代表本线程正在引用此节点,那么其他线程便不会删除该节点;
下一步就是判断是否pop出该结点,因为多个线程同时引用时只能有一个线程可以pop出数据。如果这个节点是末尾节点,那么就代表栈已经空。
if(old_head.ptr == nullptr) return shread_ptr<T>();
pop出一个节点需要完成3个操作:
- 让
head指向head.ptr->next; - 读取已经
pop出节点中的数据; delete节点。
这里的关键是:pop出节点的线程,如果是最后一个引用该节点的线程,那么负责删除;如果不是,那么就由其他引用该节点的线程删除;如果线程发现自己无法pop出节点,那么就需要重新执行pop操作,重新获取一个新节点尝试pop,因此整个pop操作需要放在一个循环里,直至能够pop出一个元素或者栈空。
如何限制只有一个线程pop出该节点呢?
答案是原子操作,获得该节点的pop权后立马修改节点,那么其他线程发现节点被修改后,就知道这个节点已经被其他线程pop,自己则负责删除工作。
shared_ptr<T> pop(){
while(true){
// 外部引用+1
auto old_head = head.load();
CountedNodePtr new_head;
do{
new_head = old_head;
new_head.external_count++;
}while(!head.compare_exchange_weak(old_head, new_head));
old_head.extenal_count = new_head.external_count;
//判断是否栈空
Node *ptr = old_head.ptr;
if(ptr == nullptr) return shared_ptr<T>();
// 如果不为空,尝试获得该节点的pop权限
if(_head.compare_exchange(old_head, ptr->next)){
// pop元素,然后再判断是否需要删除
std::shared_ptr<T> res;
res.swap(ptr->data);
// 更新内部计数
int count_increase = old_node.external_count - 2;
if(ptr->internal_count.fetch_add(count_increase) == -count_increase) delete ptr;
return res; // 7
}
else{
// 没有获得pop权限,判断是否需要删除。
if(ptr->internal_count.fetch_sub(1) == 1) delete ptr
}
}
}
如何判断是否需要删除?需要删除的节点一定是被pop出的节点,那么如何判断一个节点是已经被pop出的节点呢?
答案是获得pop的线程,负责更新节点的internal_count,如果一个节点的internal_count>0,则标志该节点已经被pop。如果 <=0,则表示未被pop。
template <typename T>
class LockFreeStack4
{
private:
struct Node;
struct CountedNodePtr
{
int external_count{1};
Node* ptr{nullptr};
};
struct Node
{
std::shared_ptr<T> data{nullptr};
std::atomic<int> internal_count{0};
CountedNodePtr next{nullptr};
explicit Node(const T& d)
:data(std::make_shared<T>(d)),
internal_count(0){}
};
public:
LockFreeStack4()= default;
~LockFreeStack4() = default;
LockFreeStack4(const LockFreeStack4&) = delete;
LockFreeStack4(LockFreeStack4&& ) = delete;
LockFreeStack4& operator=(const LockFreeStack4&) = delete;
LockFreeStack4& operator=(LockFreeStack4&&) = delete;
void push(const T& t)
{
CountedNodePtr new_node;
new_node.ptr = new Node(t);
new_node.external_count = 1;
new_node.ptr->next = _head.load(std::memory_order_relaxed);
while(!_head.compare_exchange_weak(
new_node.ptr->next,
new_node,
std::memory_order_release,
std::memory_order_relaxed)){}
}
std::shared_ptr<T> pop()
{
CountedNodePtr old_node = _head.load(std::memory_order_relaxed);
while(true)
{
increase_head_count(old_node); // external_count+ 1,表示当前线程引用,并且保证读取到最新的head
Node* ptr = old_node.ptr; // 当计数增加,就能安全的解引用ptr,并读取head指针的值,就能访问指向的节点
if(!ptr) return std::shared_ptr<T>(); // 如果指针是空指针,那么将会访问到链表的最后。
if (_head.compare_exchange_strong(old_node, ptr->next), std::memory_order_relaxed) // 为什么只需要next,而不需要一直循环? 因为外层有个while(true)
// 当compare_exchange_strong()成功时,就拥有对应节点的所有权,并且可以和data进行交换;
// 不可能多个线程同时进入这个if分支
{
std::shared_ptr<T> res;
res.swap(ptr->data);
int count_increase = old_node.external_count - 2; // 因为increase_head_count已经加了1次
if(ptr->internal_count.fetch_add(count_increase, std::memory_order_release) == -count_increase) delete ptr; // 将所有外部引用更新到内部引用中,让其他线程删除或者本线程删除
return res; // 7
}
// 当“比较/交换”③失败,就说明其他线程在之前把对应节点删除了,或者其他线程添加了一个新的节点到栈中。
// 无论是哪种原因,需要通过“比较/交换”的调用,对具有新值的head重新进行操作。
// 不过,首先需要减少节点(要删除的节点)上的引用计数。这个线程将再也没有办法访问这个节点了。
// 如果当前线程是最后一个持有引用(因为其他线程已经将这个节点从栈上删除了)的线程,那么内部引用计数将会为1,
// 所以减一的操作将会让计数器为0。这样,你就能在循环⑧进行之前将对应节点删除了。
if(ptr->internal_count.fetch_sub(1, std::memory_order_relaxed) == 1)
{
ptr->internal_count.load(std::memory_order_acquire);
delete ptr; // 其他线程读到internal_count=1时,表明本线程是最后一个引用该节点的,负责删除。
}
}
}
private:
void increase_head_count(CountedNodePtr& old_header)
{
// 这里是因为CountedNodePtr的external_count不是原子的,改变他需要不断的重试
// 其次,读取到的head可能不是最新的。
CountedNodePtr new_counter;
do
{
new_counter = old_header;
++new_counter.external_count;
}while (!_head.compare_exchange_strong(
old_header, new_counter,
std::memory_order_acquire,
std::memory_order_relaxed)); //1 通过增加外部引用计数,保证指针在访问期间的合法性。
old_header.external_count = new_counter.external_count;
}
std::atomic<CountedNodePtr> _head;
};
