[剑指Offer]17~20
[剑指Offer]17~20
学习使用工具
剑指Offer http://itmyhome.com/sword-means-offer/sword-means-offer.pdf
LeetCode的剑指Offer题库 https://leetcode.cn/problemset/all/
剑指 Offer 17. 打印从1到最大的n位数
输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数 999。
示例 1:
输入: n = 1
输出: [1,2,3,4,5,6,7,8,9]
说明:
- 用返回一个整数列表来代替打印
- n 为正整数
解法:
啊这题竟然不考大数问题?很惊诧,秒了。
def printNumbers(self, n: int) -> List[int]:
max = 0
for i in range(n):
max *= 10
max += 9
return list(range(1, max + 1))
翻了下原书,确实是要考大数问题的,这里记录一下。原书问题如下:
题目:输入数字n,按顺序打印出从1最大的n位十进制数。比如输入3,则打印出1、2、3一直到最大的3位数即999。
这里的实际思路应当使用字符串去模拟数字进行打印而规避发生大数溢出的问题。原书提供的全排列思路:
如果我们在数字前面补0的话,就会发现n位所有十进制数其实就是n个从0到9的全排列。也就是说,我们把数字的每一位都从0到9排列一遍,就得到了所有的十进制数。只是我们在打印的时候,数字排在前面的0我们不打印出来罢了。
全排列用递归很容易表达,数字的每1位都可能是0~9中的一个数,然后设置下一位。递归结束的条件是我们已经设置了数字的最后1位。
代码实现(使用C/C++):
void Print1ToMaxOfNDigits(int n){
if(n <= 0)
return;
char* number = new char[n + 1] ;
number[n] = '\0';
for(int i=0;i<10;++i)
number[0] = i + '0';
Print1ToMaxOfNDigitsRecursively (number, n, 0) ;
delete[] number;
}
void Print1ToMaxOfNDigitsRecursively (char* number, int length, int index){
if(index == length 一1)
PrintNumber (number) ;
return;
}
for(int i=0;i<10;++i)
number [index + 1] = i + '0';
Print1ToMaxOfNDigitsRecursively(number, length, index + 1) ;
}
}
剑指 Offer 18. 删除链表的节点
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。返回删除后的链表的头节点。
注意:此题对比原题有改动
示例 1:
输入: head = [4,5,1,9], val = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
示例 2:
输入: head = [4,5,1,9], val = 1
输出: [4,5,9]
解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.
说明:
-
题目保证链表中节点的值互不相同
-
若使用 C 或 C++ 语言,你不需要
free或delete被删除的节点
解法:
比较简单,先判空,如果头结点就是要删除的节点则直接返回头节点的下一个节点即可。如果不是就搜索,删除特定节点后返回初始头结点。
def deleteNode(self, head: ListNode, val: int) -> ListNode:
if not head:
return None
if head.val == val:
return head.next
else:
temp = head
while(temp.next):
if not temp.next.val == val:
temp = temp.next
else:
temp.next = temp.next.next
break
return head
这里再翻一下原书:
题目:给定单向链表的头指针和一个结点指针,定义一个函数在0(1)时间删除该结点。
这也是一个很简单的题,只要将节点的next节点覆盖此节点即可,不再赘述。
剑指 Offer 19. 正则表达式匹配
请实现一个函数用来匹配包含'. '和'*'的正则表达式。模式中的字符'.'表示任意一个字符,而'*'表示它前面的字符可以出现任意次(含0次)。在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串"aaa"与模式"a.a"和"ab*ac*a"匹配,但与"aa.a"和"ab*a"均不匹配。
示例 1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:
s = "aa"
p = "a*"
输出: true
解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
输入:
s = "ab"
p = ".*"
输出: true
解释: ".*" 表示可匹配零个或多个('*')任意字符('.')。
示例 4:
输入:
s = "aab"
p = "c*a*b"
输出: true
解释: 因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
示例 5:
输入:
s = "mississippi"
p = "mis*is*p*."
输出: false
s可能为空,且只包含从a-z的小写字母。p可能为空,且只包含从a-z的小写字母以及字符.和*,无连续的'*'。
解法:
我做错了什么要在大晚上刷到正则表达式匹配题?Offer消失术!!
class Solution {
public boolean isMatch(String s, String p) {
return s.matches(p);
}
}
好吧,我除了硬配想不出来!要考虑的情况又太多了真真不好写。读了下答案,正经写的话用动态规划,不过条件转移方程不是很好写,官方又写的很难懂,这里就记录一个不写状态转移方程、纯记录状态的吧。
作者:Krahets
来源:力扣(LeetCode)
用 dp[i][j]表示 s 的前 i 个字符与 i 中的前 j 个字符是否能够匹配。
- 当
p[j - 1] = '*'时,dp[i][j]在当以下任一情况为true时等于true:dp[i][j - 2]: 即将字符组合p[j - 2] *看作出现0次时,能否匹配;dp[i - 1][j]且s[i - 1] = p[j - 2]: 即让字符p[j - 2]多出现1次时,能否匹配;dp[i - 1][j]且p[j - 2] = '.': 即让字符.多出现 1 次时,能否匹配;
- 当
p[j - 1] != '*'时,dp[i][j]在当以下任一情况为true时等于true:dp[i - 1][j - 1]且s[i - 1] = p[j - 1]: 即让字符p[j - 1]多出现一次时,能否匹配;dp[i - 1][j - 1]且p[j - 1] = '.': 即将字符.看作字符s[i - 1]时,能否匹配;
初始值:需要先初始化 dp 矩阵首行,以避免状态转移时索引越界。
dp[0][0] = turedp[0][j] = dp[0][j - 2]且p[j - 1] = '*': 首行s为空字符串,因此当p的偶数位为*时才能够匹配(即让p的奇数位出现0次,保持p是空字符串)。因此,循环遍历字符串p,步长为2(即只看偶数位)。
def isMatch(self, s: str, p: str) -> bool:
m, n = len(s) + 1, len(p) + 1
dp = [[False] * n for _ in range(m)]
dp[0][0] = True
for j in range(2, n, 2):
dp[0][j] = dp[0][j - 2] and p[j - 1] == '*'
for i in range(1, m):
for j in range(1, n):
dp[i][j] = dp[i][j - 2] or dp[i - 1][j] and (s[i - 1] == p[j - 2] or p[j - 2] == '.') \
if p[j - 1] == '*' else \
dp[i - 1][j - 1] and (p[j - 1] == '.' or s[i - 1] == p[j - 1])
return dp[-1][-1]
剑指 Offer 20. 表示数值的字符串
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。
数值(按顺序)可以分成以下几个部分:
- 若干空格
- 一个 小数 或者 整数
- (可选)一个
'e'或'E',后面跟着一个 整数 - 若干空格
小数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+'或'-') - 下述格式之一:
- 至少一位数字,后面跟着一个点
'.' - 至少一位数字,后面跟着一个点
'.',后面再跟着至少一位数字 - 一个点
'.',后面跟着至少一位数字
- 至少一位数字,后面跟着一个点
整数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(
'+'或'-') - 至少一位数字
部分数值列举如下:
["+100", "5e2", "-123", "3.1416", "-1E-16", "0123"]
部分非数值列举如下:
["12e", "1a3.14", "1.2.3", "+-5", "12e+5.4"]
示例 1:
输入:s = "0"
输出:true
示例 2:
输入:s = "e"
输出:false
示例 3:
输入:s = "."
输出:false
示例 4:
输入:s = " .1 "
输出:true
提示:
-
1 <= s.length <= 20 -
s仅含英文字母(大写和小写),数字(0-9),加号'+',减号'-',空格' '或者点'.'。
解法:
出这题的人,你食不食油饼?就真面向用例编程是吧,不要太过分了!
收录两个个人觉得挺不错的非面向用例编程办法,一个是尝试转float,成功则Ture,失败则False;另一个是正则。
def isNumber(self, s: str) -> bool:
try:
float(s)
return True
except ValueError:
return False
public boolean isNumber(String s) {
return s.trim().matches("[+-]?((\\d+(\\.\\d+)?)|(\\.\\d+)|(\\d+\\.))([eE][+-]?\\d+)?");
}
官方给的解答竟然是有限状态自动机!这谁想得到,虽然我学过形式语言与自动机但我真想不到(用的太少了)。
但是用自动机解题确实很方便,编码思路简单也不用和if-else搏斗,主要是前期分析花时间。这里收录一下官方题解:
import需要的库:from enum import Enum
输入字符:
-
数字
-
e
-
小数点
-
符号
-
空格
-
不符合条件的非法输入
Chartype = Enum("Chartype", [
"CHAR_NUMBER",
"CHAR_EXP",
"CHAR_POINT",
"CHAR_SIGN",
"CHAR_SPACE",
"CHAR_ILLEGAL"
])
def toChartype(ch: str) -> Chartype:
if ch.isdigit():
return Chartype.CHAR_NUMBER
elif ch.lower() == "e":
return Chartype.CHAR_EXP
elif ch == ".":
return Chartype.CHAR_POINT
elif ch == "+" or ch == "-":
return Chartype.CHAR_SIGN
elif ch == " ":
return Chartype.CHAR_SPACE
else:
return Chartype.CHAR_ILLEGAL
状态集合:
-
起始的空格
-
符号位
-
整数部分
-
左侧有整数的小数点
-
左侧无整数的小数点
-
小数部分
-
字符 e
-
指数部分的符号位
-
指数部分的整数部分
-
末尾的空格
State = Enum("State", [
"STATE_INITIAL",
"STATE_INT_SIGN",
"STATE_INTEGER",
"STATE_POINT",
"STATE_POINT_WITHOUT_INT",
"STATE_FRACTION",
"STATE_EXP",
"STATE_EXP_SIGN",
"STATE_EXP_NUMBER",
"STATE_END"
])
状态转移规则:
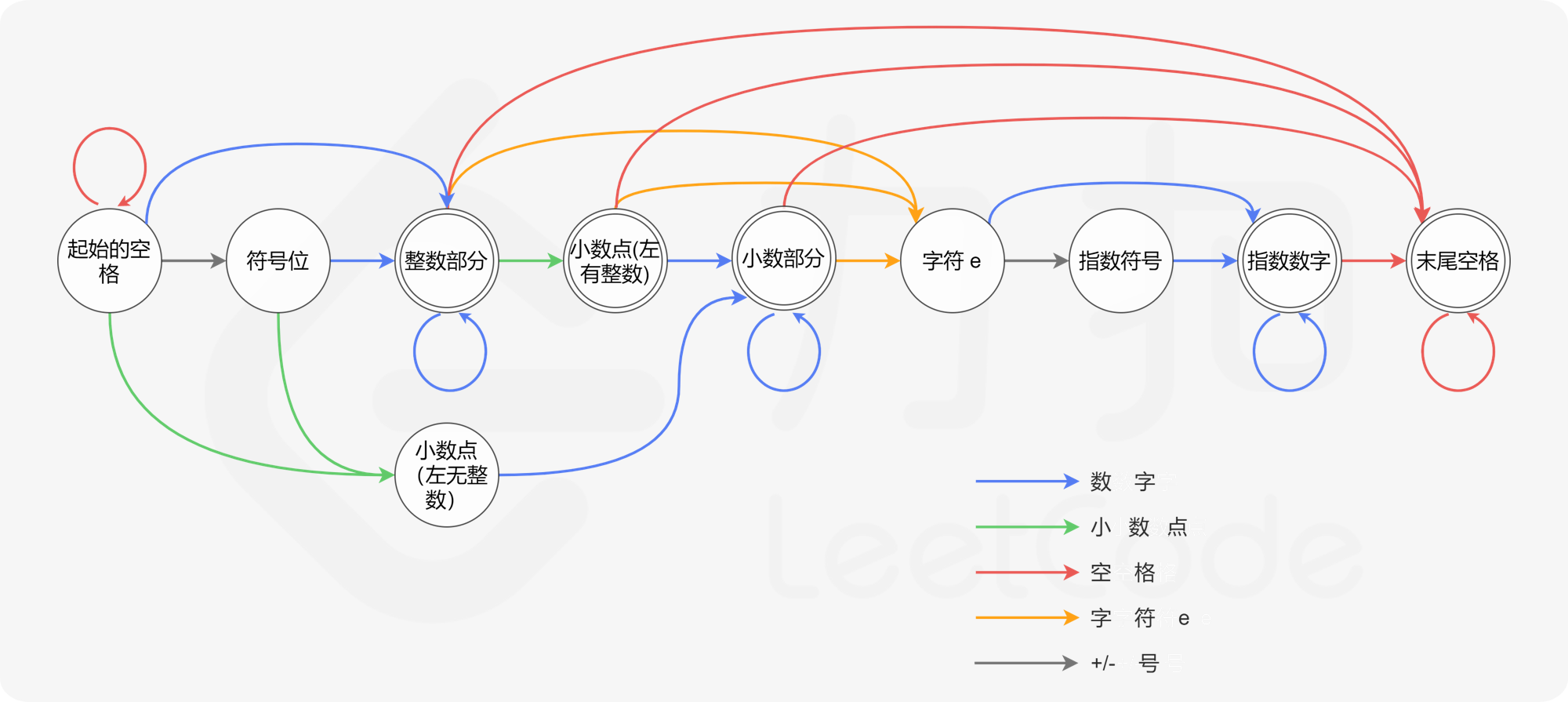
transfer = {
State.STATE_INITIAL: {
Chartype.CHAR_SPACE: State.STATE_INITIAL,
Chartype.CHAR_NUMBER: State.STATE_INTEGER,
Chartype.CHAR_POINT: State.STATE_POINT_WITHOUT_INT,
Chartype.CHAR_SIGN: State.STATE_INT_SIGN
},
State.STATE_INT_SIGN: {
Chartype.CHAR_NUMBER: State.STATE_INTEGER,
Chartype.CHAR_POINT: State.STATE_POINT_WITHOUT_INT
},
State.STATE_INTEGER: {
Chartype.CHAR_NUMBER: State.STATE_INTEGER,
Chartype.CHAR_EXP: State.STATE_EXP,
Chartype.CHAR_POINT: State.STATE_POINT,
Chartype.CHAR_SPACE: State.STATE_END
},
State.STATE_POINT: {
Chartype.CHAR_NUMBER: State.STATE_FRACTION,
Chartype.CHAR_EXP: State.STATE_EXP,
Chartype.CHAR_SPACE: State.STATE_END
},
State.STATE_POINT_WITHOUT_INT: {
Chartype.CHAR_NUMBER: State.STATE_FRACTION
},
State.STATE_FRACTION: {
Chartype.CHAR_NUMBER: State.STATE_FRACTION,
Chartype.CHAR_EXP: State.STATE_EXP,
Chartype.CHAR_SPACE: State.STATE_END
},
State.STATE_EXP: {
Chartype.CHAR_NUMBER: State.STATE_EXP_NUMBER,
Chartype.CHAR_SIGN: State.STATE_EXP_SIGN
},
State.STATE_EXP_SIGN: {
Chartype.CHAR_NUMBER: State.STATE_EXP_NUMBER
},
State.STATE_EXP_NUMBER: {
Chartype.CHAR_NUMBER: State.STATE_EXP_NUMBER,
Chartype.CHAR_SPACE: State.STATE_END
},
State.STATE_END: {
Chartype.CHAR_SPACE: State.STATE_END
},
}
运行:
st = State.STATE_INITIAL
for ch in s:
typ = toChartype(ch)
if typ not in transfer[st]:
return False
st = transfer[st][typ]
return st in [State.STATE_INTEGER, State.STATE_POINT, State.STATE_FRACTION, State.STATE_EXP_NUMBER, State.STATE_END]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号