[自然语言处理进阶]四、BERT
四、BERT
学习路线参考:
https://blog.51cto.com/u_15298598/3121189
https://github.com/Ailln/nlp-roadmap
https://juejin.cn/post/7113066539053482021
https://zhuanlan.zhihu.com/p/100567371
https://cloud.tencent.com/developer/article/1884740
本节学习使用工具&阅读文章:
https://zhuanlan.zhihu.com/p/51413773
https://www.cnblogs.com/nickchen121/p/15114385.html
https://www.cnblogs.com/zackstang/p/15387549.html
https://blog.csdn.net/qq_39521554/article/details/83062188
https://paddlepedia.readthedocs.io/en/latest/tutorials/pretrain_model/bert.html
1. BERT概述
BERT(Bidirectional Encoder Representation from Transformers)是2018年10月由Google AI研究院提出的一种预训练模型,它的网络架构使用的是多层Transformer结构中的Encoder模块。可以简单理解为一个双向的Transformer编码器。
BERT整体框架包含pre-train和fine-tune两个阶段。pre-train阶段模型是在无标注的标签数据上进行训练,fine-tune阶段,BERT模型首先是被pre-train模型参数初始化,然后所有的参数会用下游的有标注的数据进行训练。
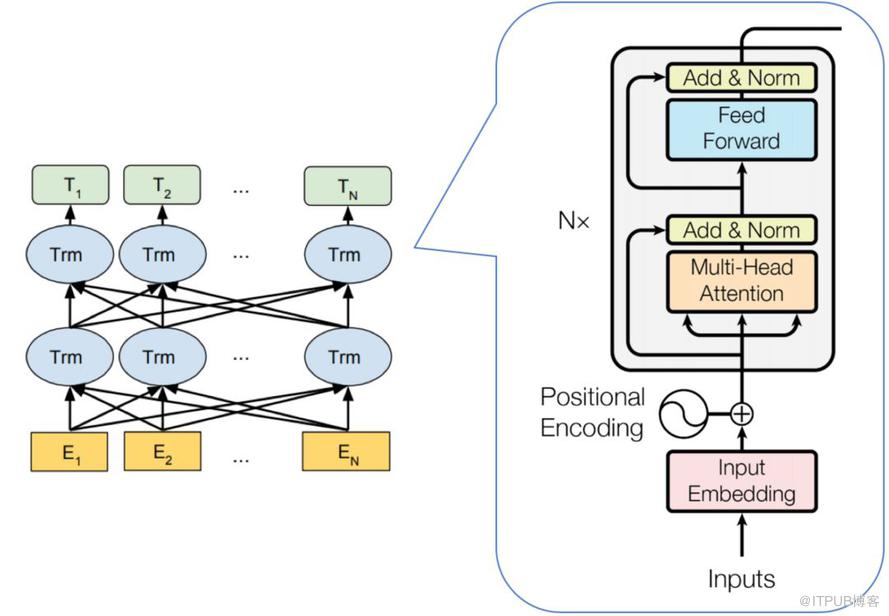
2. BERT模型结构
-
Embedding模块:输入嵌入是token embeddings, segmentation embeddings和position embeddings的总和。
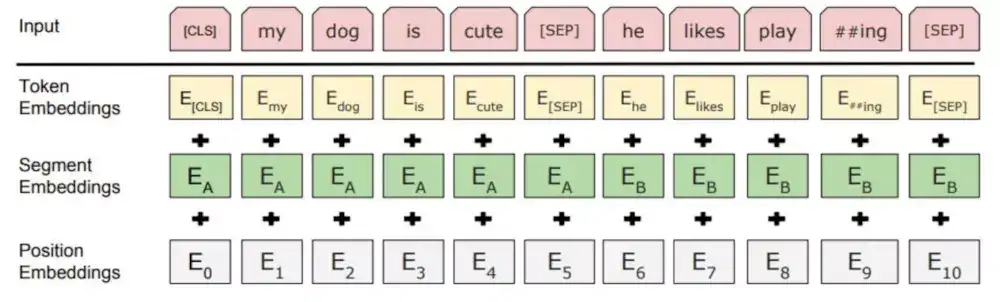
具体如下:
- Token Embeddings:是词向量,第一个单词是CLS标志,可以用于之后的分类任务。[SEP]表示分句符号。
- Segment Embeddings:用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings:和Transformer不一样,不是三角函数而是学习出来的
-
Transformer模块:特征提取部分,结构上与Transformer的编码器完全相同。在Transformer中,模型的输入会被转换成512维的向量,然后分为8个head,每个head的维度是64维,但是BERT的维度是768维度,然后分成12个head,每个head的维度是64维,这是一个微小的差别。
BERT模型分为24层和12层两种,其差别就是使用transformer encoder的层数的差异,BERT-base使用的是12层的Transformer Encoder结构,BERT-Large使用的是24层的Transformer Encoder结构。
3. Pre-training
BERT是一个多任务模型,它的预训练(Pre-training)任务是由两个自监督任务组成,即MLM和NSP。
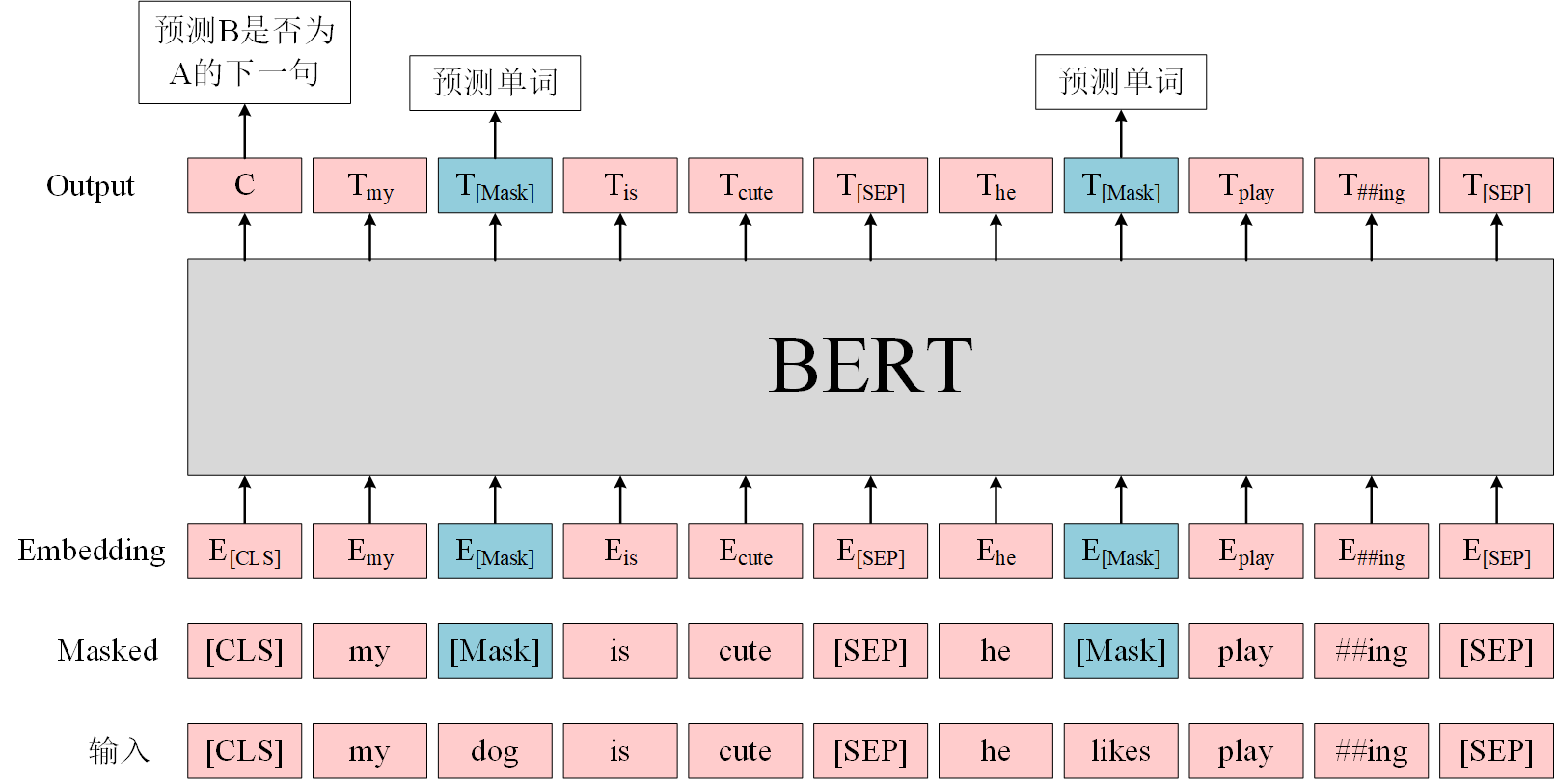
4. MLM-语言掩码
在训练的时候随即从输入语料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。
正如传统的语言模型算法和RNN匹配那样,MLM的这个性质和Transformer的结构是非常匹配的。在BERT的实验中,15%的WordPiece Token会被随机Mask掉。在训练模型时,一个句子会被多次喂到模型中用于参数学习,但是Google并没有在每次都mask掉这些单词,而是在确定要Mask掉的单词之后,做以下处理。
- 80%的时候会直接替换为[Mask],将句子 “my dog is cute” 转换为句子 “my dog is [Mask]”。
- 10%的时候将其替换为其它任意单词,将单词 “cute” 替换成另一个随机词,例如 “apple”。将句子 “my dog is cute” 转换为句子 “my dog is apple”。
- 10%的时候会保留原始Token,例如保持句子为 “my dog is cute” 不变。
这么做的原因是如果句子中的某个Token 100%都会被mask掉,那么在fine-tuning的时候模型就会有一些没有见过的单词。加入随机Token的原因是因为Transformer要保持对每个输入token的分布式表征,否则模型就会记住这个[mask]是token。另外文章指出每次只预测15%的单词,因此模型收敛的比较慢。
优点
- 被随机选择15%的词当中以10%的概率用任意词替换去预测正确的词,相当于文本纠错任务,为BERT模型赋予了一定的文本纠错能力;
- 被随机选择15%的词当中以10%的概率保持不变,缓解了finetune时候与预训练时候输入不匹配的问题(预训练时候输入句子当中有mask,而finetune时候输入是完整无缺的句子,即为输入不匹配问题)。
缺点
- 针对有两个及两个以上连续字组成的词,随机mask字割裂了连续字之间的相关性,使模型不太容易学习到词的语义信息。主要针对这一短板,因此google此后发表了BERT-WWM,国内的哈工大联合讯飞发表了中文版的BERT-WWM。
5. NSP-下句预测
在很多自然语言处理的下游任务中,如问答和自然语言推断,都基于两个句子做逻辑推理,而语言模型并不具备直接捕获句子之间的语义联系的能力,或者可以说成单词预测粒度的训练到不了句子关系这个层级,为了学会捕捉句子之间的语义联系,BERT 采用了下句预测(NSP)作为无监督预训练的一部分。
为了训练一个理解句子的模型关系,预先训练一个二进制化的下一句测任务,这一任务可以从任何单语语料库中生成。具体地说,当选择句子A和B作为预训练样本时,B有50%的可能是A的下一个句子,也有50%的可能是来自语料库的随机句子。
连续句对:[CLS]今天天气很糟糕[SEP]下午的体育课取消了[SEP]
随机句对:[CLS]今天天气很糟糕[SEP]鱼快被烤焦啦[SEP]
其中 [SEP] 标签表示分隔符。 [CLS] 表示标签用于类别预测,结果为 1,表示输入为连续句对;结果为 0,表示输入为随机句对。
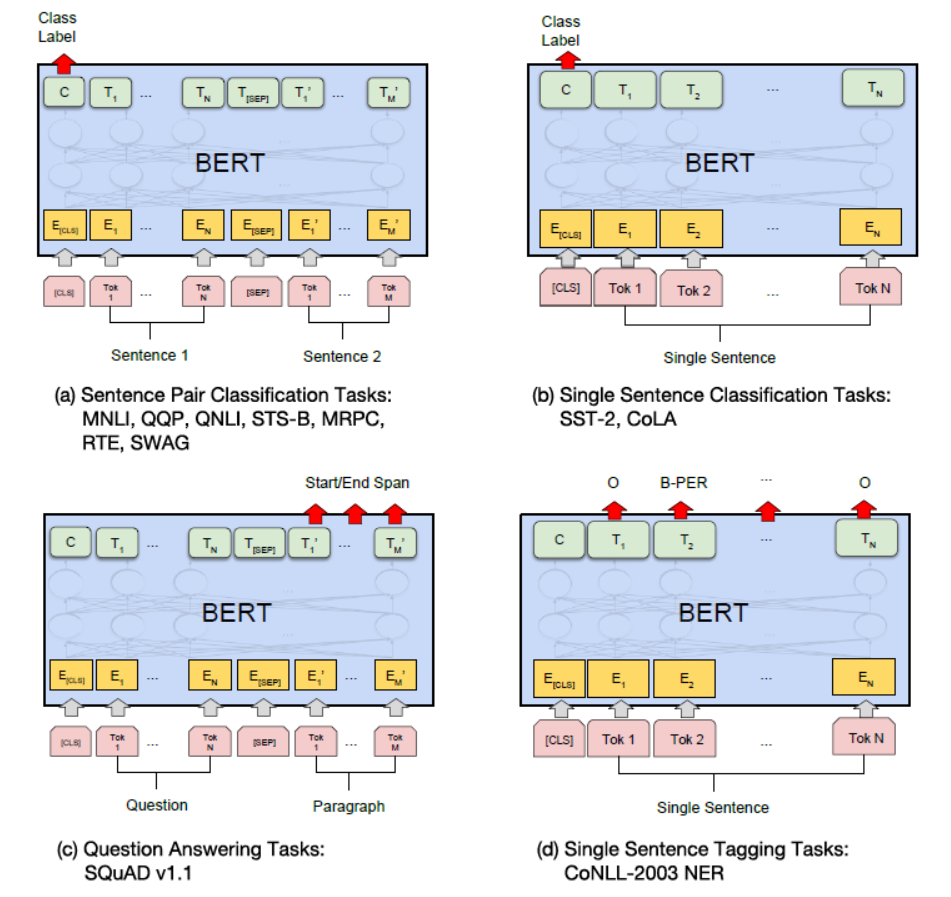
6. 下游任务应用
在海量的语料上训练完BERT之后,便可以将其应用到NLP的各个任务中了。 微调(Fine-Tuning)的任务包括:基于句子对的分类任务,基于单个句子的分类任务,问答任务,命名实体识别等。
-
基于句子对的分类任务
给定两个句子,判断它们的关系,称为句对分类,例如判断句对是否相似、判断后者是否为前者的答案。
针对句对分类任务,BERT 在预训练过程中就使用了 NSP 训练方法获得了直接捕获句对语义关系的能力。
实际应用时,句对用 [SEP] 分隔符拼接成文本序列,在句首加入标签 [CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
针对二分类任务,BERT 不需要对输入数据和输出数据的结构做任何改动,直接使用与 NSP 训练方法一样的输入和输出结构就行。针对多分类任务,需要在句首标签 [CLS] 的输出特征向量后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 arg max 操作(取最大值时对应的索引序号)得到相对应的类别结果。
-
基于单个句子的分类任务
给定一个句子,判断该句子的类别,统称为单句分类,例如判断情感类别、判断是否为语义连贯的句子。
针对单句二分类任务,也无须对 BERT 的输入数据和输出数据的结构做任何改动。
单句分类在句首加入标签 [CLS],将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。同样,针对多分类任务,需要在句首标签 [CLS] 的输出特征向量后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 argmax 操作得到相对应的类别结果。
-
问答任务
给定一个问句和一个蕴含答案的句子,找出答案在后这种的位置,称为文本问答,例如给定一个问题(句子 A),在给定的段落(句子 B)中标注答案的其实位置和终止位置。
文本问答任何和前面讲的其他任务有较大的差别,无论是在优化目标上,还是在输入数据和输出数据的形式上,都需要做一些特殊的处理。
为了标注答案的起始位置和终止位置,BERT 引入两个辅助向量 s(start,判断答案的起始位置) 和 e(end,判断答案的终止位置)。
BERT 判断句子 B 中答案位置的做法是,将句子 B 中的每一个次得到的最终特征向量 \(T^{′}_i\) 经过全连接层(利用全连接层将词的抽象语义特征转化为任务指向的特征)后,分别与向量 s 和 e 求内积,对所有内积分别进行 softmax 操作,即可得到词 Token 作为答案起始位置和终止位置的概率。最后,取概率最大的片段作为最终的答案。
文本回答任务的微调训练使用了两个技巧:
- 用全连接层把 BERT 提取后的深层特征向量转化为用于判断答案位置的特征向量
- 引入辅助向量 s 和 e 作为答案起始位置和终止位置的基准向量,明确优化目标的方向和度量方法
-
命名实体识别
给定一个句子,标注每个次的标签,称为单句标注。例如给定一个句子,标注句子中的人名、地名和机构名。
单句标注任务和 BERT 预训练任务具有较大差异,但与文本问答任务较为相似。
在进行单句标注任务时,需要在每个词的最终语义特征向量之后添加全连接层,将语义特征转化为序列标注任务所需的特征,单句标注任务需要对每个词都做标注,因此不需要引入辅助向量,直接对经过全连接层后的结果做 Softmax 操作,即可得到各类标签的概率分布。
由于 BERT 需要对输入文本进行分词操作,独立词将会被分成若干子词,因此 BERT 预测的结果将会是 5 类(细分为 13 小类):
- O(非人名地名机构名,O 表示 Other)
- B-PER/LOC/ORG(人名/地名/机构名初始单词,B 表示 Begin)
- I-PER/LOC/ORG(人名/地名/机构名中间单词,I 表示 Intermediate)
- E-PER/LOC/ORG(人名/地名/机构名终止单词,E 表示 End)
- S-PER/LOC/ORG(人名/地名/机构名独立单词,S 表示 Single)
将 5 大类的首字母结合,可得 IOBES,这是序列标注最常用的标注方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号