[自然语言处理进阶]三、ELMo
三、ELMo
学习路线参考:
https://blog.51cto.com/u_15298598/3121189
https://github.com/Ailln/nlp-roadmap
https://juejin.cn/post/7113066539053482021
https://zhuanlan.zhihu.com/p/100567371
https://cloud.tencent.com/developer/article/1884740
本节学习使用工具&阅读文章:
https://www.cnblogs.com/yifanrensheng/p/13167787.html
https://www.cnblogs.com/nickchen121/p/16470569.html#tid-nz4b3T
https://paddlepedia.readthedocs.io/en/latest/tutorials/pretrain_model/ELMo.html
https://arxiv.org/abs/1802.05365
https://blog.csdn.net/Dream_Poem/article/details/122768058
1. ELMo概述
word embedding是现在自然语言处理中最常用的 word representation 的方法。但word2vec本质上是一个静态模型,所谓静态指的是训练好之后每个单词的表达就固定住了,以后使用的时候,不论新句子上下文单词是什么,这个单词的 Word Embedding 不会跟着上下文场景的变化而改变。
ELMo的提出就是为了解决这种语境问题,动态的去更新词的word embedding。
ELMo的本质思想是:我事先用语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在我实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了。所以ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
ELMo表征是“深”的,就是说它们是BiLM的所有层的内部表征的函数。这样做的好处是能够产生丰富的词语表征。高层的LSTM的状态可以捕捉词语以一种和语境相关的特征(比如可以应用在语义消歧),而低层的LSTM可以找到语法方面的特征(比如可以做词性标注)。如果把它们结合在一起,会在下游的NLP任务中显出优势。
2. ELMo模型结构
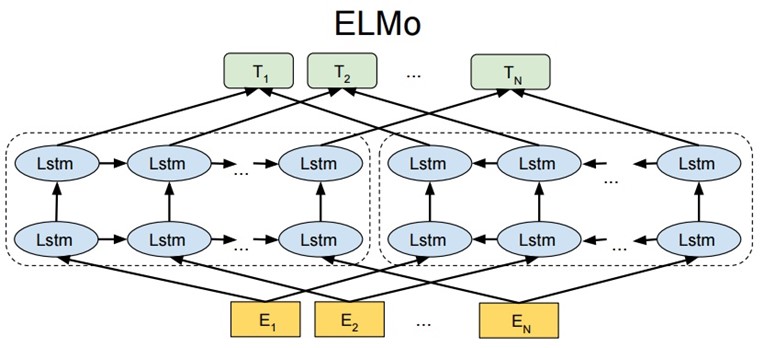
从上面的架构图中可以看到, 宏观上ELMo分三个主要模块.
-
最底层黄色标记的Embedding模块:采用CNN对字符级进行编码, 本质就是获得一个静态的词嵌入向量作为网络的底层输入
-
中间层蓝色标记的两部分双层LSTM模块:这是整个ELMo中最重要的部分, 架构中分成左侧的前向LSTM网络, 和右侧的反向LSTM网络。ELMo的做法是我们只预训练一个Language Model, 而word embedding是通过输入的句子实时给出的, 这样单词的嵌入向量就包含了上下文的信息, 也就彻底改变了Word2Vec和GloVe的静态词向量的做法。
这个部分里有两层双向LSTM,第一层双向LSTM包含更多的句法信息,第二层双向LSTM包含更多的语义信息。
左端的前向双层 LSTM 代表正方向编码器,输入的是从左到右顺序的除了预测单词外 \(W_i\) 的上文 Context-before;右端的逆向双层 LSTM 代表反方向编码器,输入的是从右到左的逆序的句子下文Context-after。
-
最上层绿色标记的词向量表征模块:到这里为止每个输入都由三部分组成:对token直接进行CNN编码的结果,前向LSTM的输出结果,每一层都会有一个输出,总共L层就会有L个输出; 后向LSTM的输出结果,每一层都会有一个输出,总共L层就会有L个输出; 综合三部分的输出加在一起,就是\(2L+1\)个输出向量。
通过整个网络,每一个token得到了2L+1个表示向量,但是我们希望每一个token能对应一个向量。最简单的做法就是取最上层的输出结果作为token的表示向量,更通用的做法是加入若干参数来融合所有层的信息。即对于2L+1个向量, 每一个前面都加上一个权重稀疏,然后直接融合成一个向量,最后再乘一个系数作为最终该token的词向量。
3. 下游应用
- 将句子 X 输入ELMo网络中,这样句子 X 中每个单词在ELMo网络中都能获得对应的三个Embedding;
- 之后赋予每个Embedding一个权重a,这个权重可以由学习得来,根据权重求和之后将三个Embedding整合为一个;
- 将整合后的Embedding作为相应的单词输入,作为新特征给下游任务使用;
4. 优缺点
优点:
- 考虑上下文,针对不同的上下文生成不同的词向量。表达不同的语法或语义信息。如“活动”一词,既可以是名词,也可以是动词,既可以做主语,也可以做谓语等。针对这种情况,ELMo能够根据不同的语法或语义信息生成不同的词向量。
- 6 个 NLP 任务中性能都有幅度不同的提升,最高的提升达到 25% 左右,而且这 6 个任务的覆盖范围比较广,包含句子语义关系判断,分类任务,阅读理解等多个领域,这说明其适用范围是非常广的,普适性强,这是一个非常好的优点。
缺点:
- 使用LSTM提取特征,而LSTM提取特征的能力弱于Transformer
- 使用向量拼接方式融合上下文特征,这种方式获取的上下文信息效果不如想象中好
- 训练时间长,这也是RNN的本质导致的,和上面特征提取缺点差不多;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号