[自然语言处理进阶]二、GPT
二、GPT
学习路线参考:
https://blog.51cto.com/u_15298598/3121189
https://github.com/Ailln/nlp-roadmap
https://juejin.cn/post/7113066539053482021
https://zhuanlan.zhihu.com/p/100567371
https://cloud.tencent.com/developer/article/1884740
本节学习使用工具&阅读文章:
https://zhuanlan.zhihu.com/p/350017443
https://paddlepedia.readthedocs.io/en/latest/tutorials/pretrain_model/GPT.html
1. GPT系列概述
Generative Pre-trained Transformer(GPT)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的NLP任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A等,而完成这些任务并不需要有监督学习进行模型微调。而对于一个新的任务,GPT仅仅需要非常少的数据便可以理解这个任务的需求并达到接近或者超过state-of-the-art的方法。
当然,如此强大的功能并不是一个简单的模型能搞定的,GPT模型的训练需要超大的训练语料,超多的模型参数以及超强的计算资源。GPT系列的模型结构秉承了不断堆叠transformer的思想,通过不断的提升训练语料的规模和质量,提升网络的参数数量来完成GPT系列的迭代更新的。GPT也证明了,通过不断的提升模型容量和语料规模,模型的能力是可以不断提升的。
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
| GPT | 2018 年 6 月 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 1,750 亿 | 45TB |
GPT 基于 Transformer 架构,先在大规模语料上进行无监督预训练、再在小得多的有监督数据集上为具体任务进行精细调节(fine-tune)的方式。先训练一个通用模型,然后再在各个任务上调节,这种不依赖针对单独任务的模型设计技巧能够一次性在多个任务中取得很好的表现。这中模式也是 2018 年中自然语言处理领域的研究趋势,就像计算机视觉领域流行 ImageNet 预训练模型一样。
-
GPT的动机:NLP 领域中只有小部分标注过的数据,而有大量的数据是未标注,如何只使用标注数据将会大大影响深度学习的性能,所以为了充分利用大量未标注的原始文本数据,需要利用无监督学习来从文本中提取特征,最经典的例子莫过于词嵌入技术。但是词嵌入只能 word-level 级别的任务(同义词等),没法解决句子、句对级别的任务(翻译、推理等)。出现这种问题原因有两个:
- 不清楚下游任务,所以也就没法针对性的进行优化;
- 就算知道了下游任务,如果每次都要大改模型也会得不偿失。
为了解决以上问题,作者提出了 GPT 框架,用一种半监督学习的方法来完成语言理解任务,GPT 的训练过程分为两个阶段:无监督Pre-training 和 有监督Fine-tuning。在Pre-training阶段使用单向 Transformer 学习一个语言模型,对句子进行无监督的 Embedding,在fine-tuning阶段,根据具体任务对 Transformer 的参数进行微调,目的是在于学习一种通用的 Representation 方法,针对不同种类的任务只需略作修改便能适应。
2. GPT模型结构总览
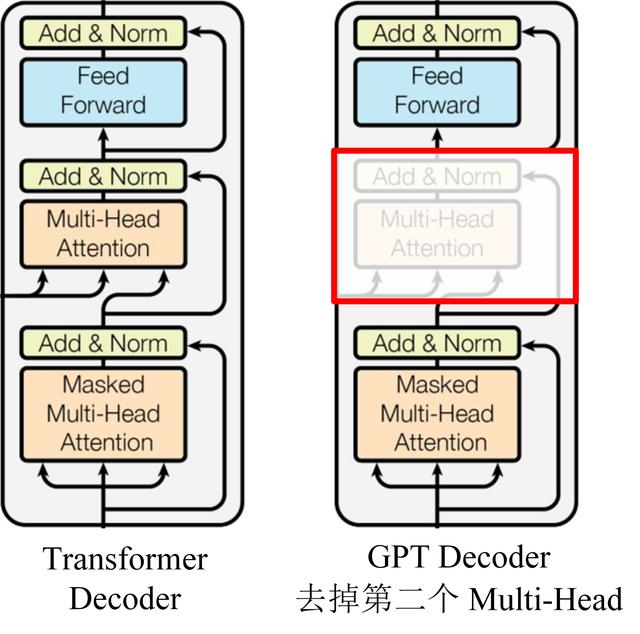
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention。下图是 GPT 整体模型图。
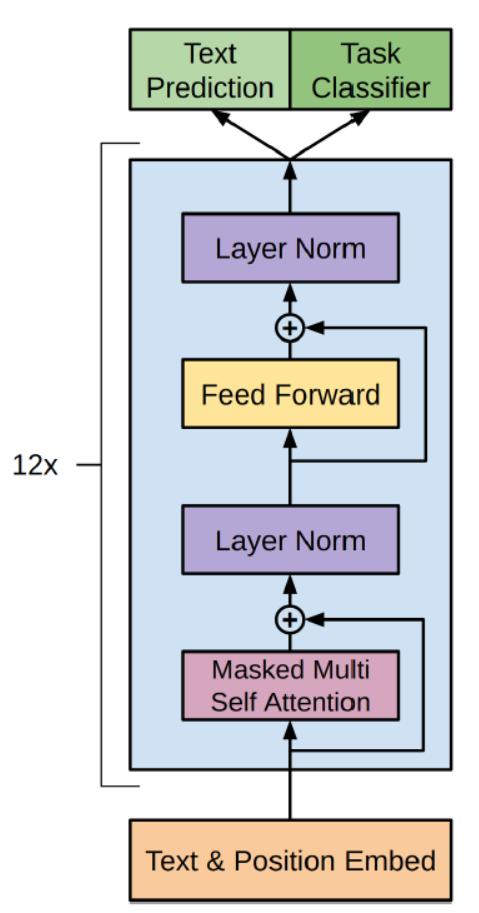
GPT只使用了 Transformer 的 Decoder 部分,并且每个子层只有一个 Masked Multi Self-Attention(768 维向量和 12 个 Attention Head)和一个 Feed Forward,共叠加使用了 12 层的 Decoder。
为什么只用 Decoder 部分:语言模型是利用上文预测下一个单词的,因为 Decoder 使用了 Masked Multi Self-Attention 屏蔽了单词的后面内容,所以 Decoder 是现成的语言模型。又因为没有使用 Encoder,所以也就不需要 encoder-decoder attention 了。
3. GPT训练过程
-
无监督的预训练
给定一个未标注的预料库\(U=\{u_1,u_2,……,u_n\}\),我们训练一个语言模型,对参数进行最大(对数)似然估计:\(L_1(U)=\sum_ilogP(u_i|u_1,…u_{k-1};\theta)\)
其中,k 是上下文窗口的大小,P 为条件概率,\(\theta\)为条件概率的参数,参数更新采用随机梯度下降(GPT实验实现部分具体用的是Adam优化器)。
训练的过程也非常简单,就是将 n 个词的词嵌入\(W_e\)加上位置嵌入\(W_p\),然后输入到 Transformer 中,n 个输出分别预测该位置的下一个词。可以看到 GPT 是一个单向的模型,GPT 的输入用 \(h_0\) 表示,0代表的是输入层,\(h_0\)的计算公式如下\(h_0=UW_e+W_p\)。在GPT中,作者对position embedding矩阵进行随机初始化,并让模型自己学习,而不是采用正弦余弦函数进行计算。
随后,将\(h_0\)依次传入 GPT 的所有 Transformer Decoder 里,最终得到\(h_n\)。\(h_l=transformer\_block(h_{l-1},l∈[l,n])\),n为神经网络的层数。最后得到\(h_n\)再预测下个单词的概率\(P(u)=softmax(h_nW^T_e)\)
至此,预训练过程结束。
-
有监督的Fine-Tuning
假设监督数据集合\(C\)的输入是\(X=\{x^1,x^2,……,x^m\}\),输出是一个分类\(Y={y^1,y^2,……,y^n}\)的标签。将\(X\)输入模型,得到输出\(H_l=\{h^1_l,h^2_l,……,h^m_l\}\)。
\(H_l\)通过我们新增的一个 Softmax 层(参数为\(W_y\))进行分类,最后用交叉熵计算损失,从而根据标准数据调整 Transformer 的参数以及 Softmax 的参数\(W_y\) 。这等价于最大似然估计:\(P(y|x^1,……,x^m)=softmax(h^m_lW_y)\)
微调时候需要最大化以下函数: \(L_2(C)=\sum_{x,y}logP(y|x^1,……,x^m)\)
正常来说,我们应该调整参数使得\(L_2\)最大,但是为了提高训练速度和模型的泛化能力,我们使用 Multi-Task Learning,GPT 在微调的时候也考虑预训练的损失函数,同时让它最大似然 \(L_3(C)=L_2(C)+\lambda*L_1(C)\)
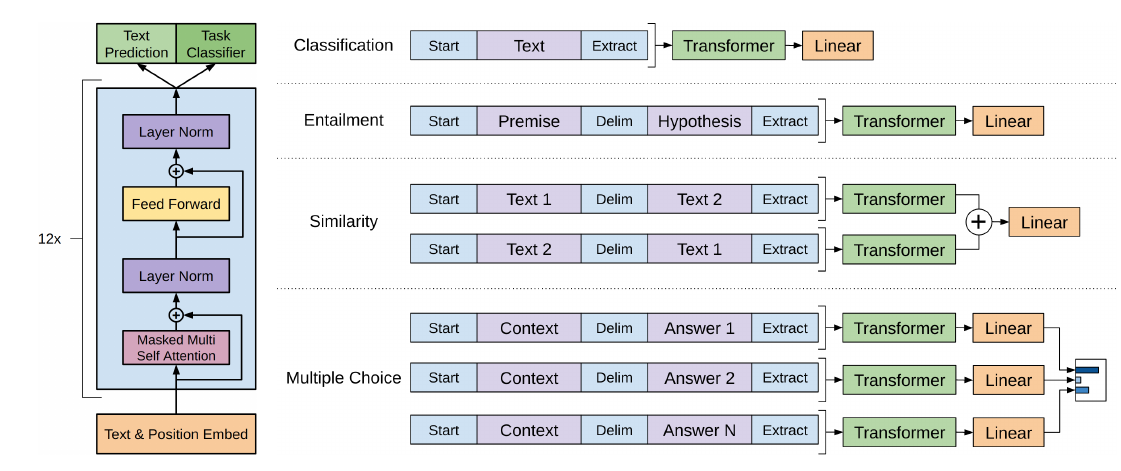
针对不同任务,需要简单修改下输入数据的格式,例如对于相似度计算或问答,输入是两个序列,为了能够使用 GPT,我们需要一些特殊的技巧把两个输入序列变成一个输入序列。
- Classification:对于分类问题,不需要做什么修改
- Entailment:对于推理问题,可以将先验与假设使用一个分隔符分开
- Similarity:对于相似度问题,由于模型是单向的,但相似度与顺序无关,所以要将两个句子顺序颠倒后,把两次输入的结果相加来做最后的推测
- Multiple-Choice:对于问答问题,则是将上下文、问题放在一起与答案分隔开,然后进行预测
4. 优缺点
优点:特征抽取器使用了强大的 Transformer,能够捕捉到更长的记忆信息,且较传统的 RNN 更易于并行化;方便的两阶段式模型,先预训练一个通用的模型,然后在各个子任务上进行微调,减少了传统方法需要针对各个任务定制设计模型的麻烦。
缺点:GPT 最大的问题就是传统的语言模型是单向的;我们根据之前的历史来预测当前词。但是我们不能利用后面的信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号