[自然语言处理进阶]一、Transformer
一、Transformer
学习路线参考:
https://blog.51cto.com/u_15298598/3121189
https://github.com/Ailln/nlp-roadmap
https://juejin.cn/post/7113066539053482021
https://zhuanlan.zhihu.com/p/100567371
https://cloud.tencent.com/developer/article/1884740
本节学习使用工具&阅读文章:
https://arxiv.org/pdf/1706.03762.pdf
http://jalammar.github.io/illustrated-transformer/
https://zhuanlan.zhihu.com/p/46990010
https://www.cnblogs.com/baobaotql/p/11662720.html
https://zhuanlan.zhihu.com/p/80377698
https://zhuanlan.zhihu.com/p/372279569
https://blog.csdn.net/guofei_fly/article/details/105601979
1. Transformer概述
2017 年,Google 机器翻译团队发表的《Attention is All You Need》中提出了Transformer模型,完全抛弃了RNN和CNN等网络结构,仅仅采用Attention机制来进行机器翻译任务,取得了很好的效果。
2. 模型结构总览
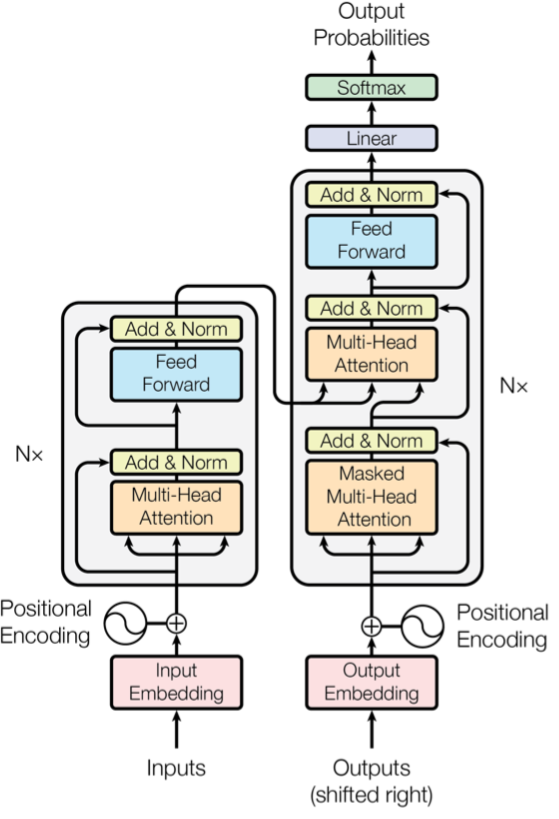
模型分为两大部分:Encoder与Decoder。
-
自编码器
这个结构最早在自编码器中出现。自编码器的原理很简单,可以理解为一个试图去还原其原始输入的系统。在深度学习中,自动编码器是一种无监督的神经网络模型,它可以学习到输入数据的隐含特征,这称为编码(coding),同时用学习到的新特征可以重构出原始输入数据,称之为解码(decoding)。
从直观上来看,自动编码器可以用于特征降维,类似主成分分析PCA,但是其相比PCA其性能更强,这是由于神经网络模型可以提取更有效的新特征。除了进行特征降维,自动编码器学习到的新特征可以送入有监督学习模型中,所以自动编码器可以起到特征提取器的作用。

如图所示,将手写数字图片进行编码,编码后生成的 \(ϕ1, ϕ2, ϕ3, ϕ4, ϕ5, ϕ6\) 较完整的保留了原始图像的典型特征,因此可较容易地通过解码恢复出原始图像。
自编码器三大特点:
- 自动编码器是数据相关的(data-specific 或 data-dependent),这意味着自动编码器只能压缩那些与训练数据类似的数据。比如,使用人脸训练出来的自动编码器在压缩别的图片,比如树木时性能很差,因为它学习到的特征是与人脸相关的。
- 自动编码器是有损的,意思是解压缩的输出与原来的输入相比是退化的,MP3,JPEG等压缩算法也是如此。这与无损压缩算法不同。
- 自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。
-
Transformer的编码器-解码器结构
在Transformer中,Encoder将输入读进去,Decoder进行输出。二者的结合方式如下:
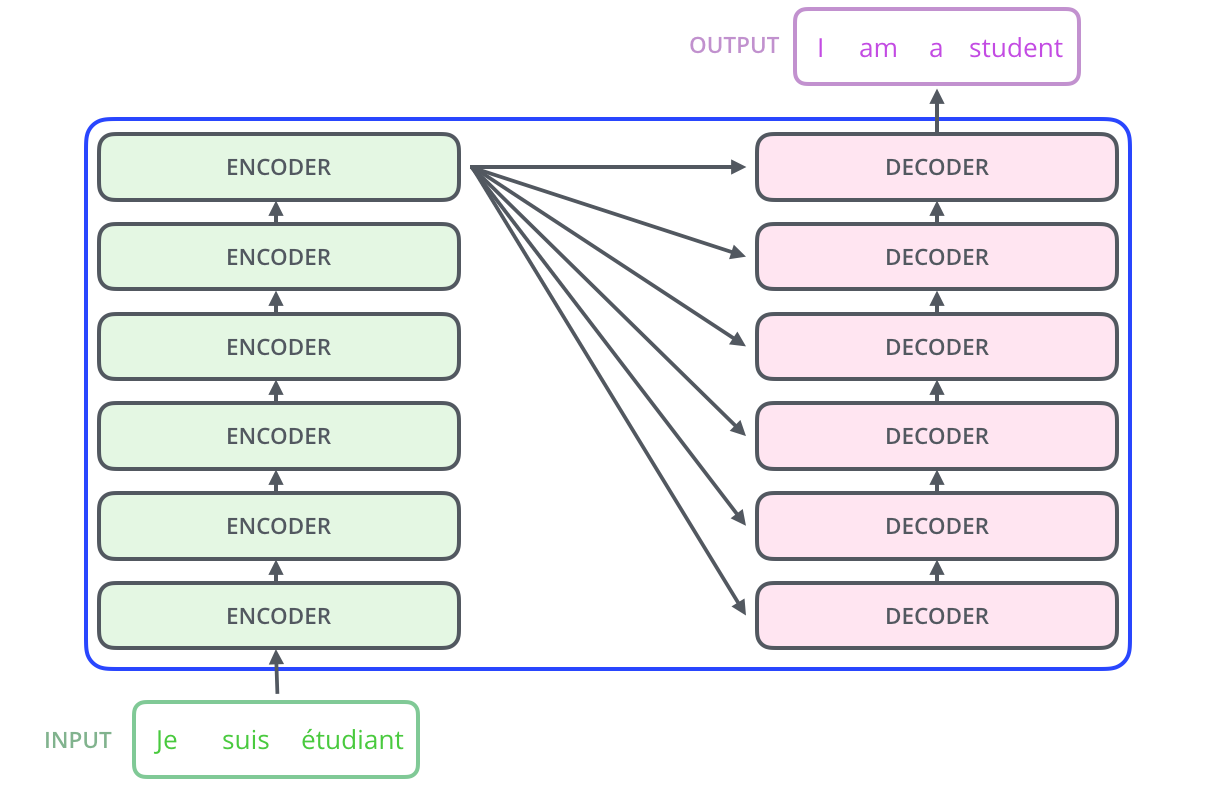
在论文中,编码组件由六个Encoder组成,解码组件由六个Decoder组成。Encoder的输出会和每一层的Decoder进行结合。
3. 输入前的处理
-
Input Embedding
随机初始化词向量,
-
位置编码
经过 word embedding,我们获得了词与词之间关系的表达形式,但是词在句子中的位置关系还无法体现。由于 Transformer 是并行地处理句子中的所有词,因此需要加入词在句子中的位置信息。
Transformer使用了位置编码,利用一定的公式计算词的位置信息,随后与词向量相加就得到了输入。位置编码计算方法如下:
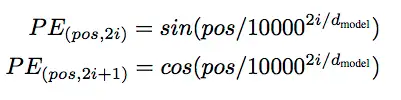
4. Transformer的编码器
![]()
-
Self-Attention
Self-attention是一种attention机制,用来计算一个句子(中的token)的represetation,其包含了这个句子中token不同位置的关系。
第一步:从每个编码器的输入向量(在本例中是每个词的嵌入)创建三个向量。因此,对于每个单词,我们创建一个Q向量、一个K向量和一个V向量。这些向量是通过将嵌入向量乘以我们在\(W^Q, W^K,W^V\)三个矩阵而创建的。这三个矩阵是可学习的。
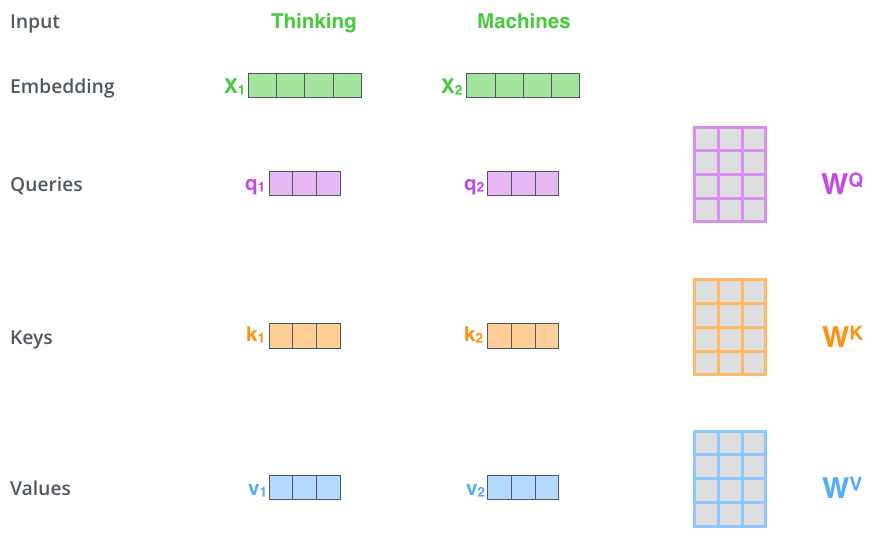
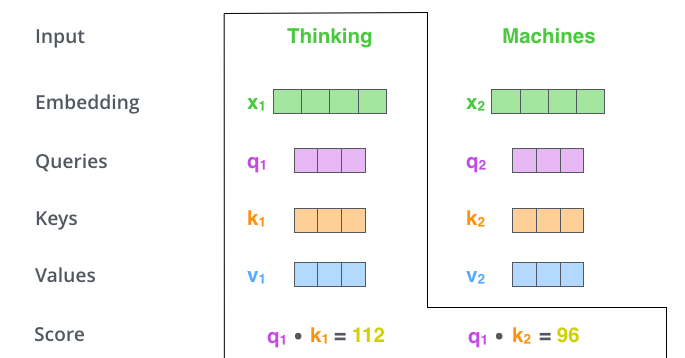
第二步:计算一个score。假设我们正在计算本例中第一个词“Thinking”的自注意力。我们需要根据这个词对输入句子的每个词进行评分。当我们在特定位置对单词进行编码时,分数决定了将多少注意力放在输入句子的其他部分。分数是通过Q与我们正在评分的相应单词的K的点积计算得出的。如图所示:
第三步:将分数除以 8(目的是让梯度更稳定),然后通过 softmax 操作传递结果。Softmax 对分数进行归一化处理,使它们都为正且加起来为 1。
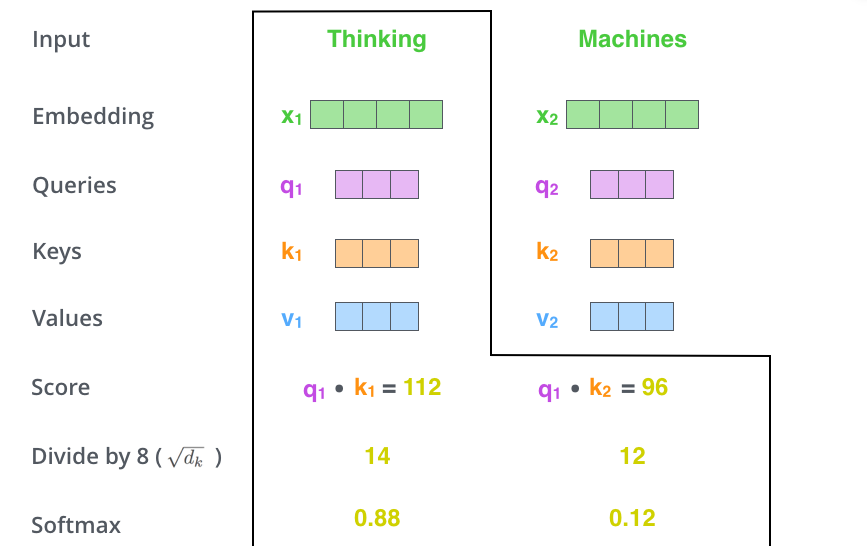
第四步:每个V乘以 softmax 分数(准备将它们相加)。这里的想法是保持我们想要关注的单词的值不变,并忽略不相关的单词。随后对加权值向量求和,产生自注意层的输出。

自注意力计算到此结束,生成的向量是我们可以发送到前馈神经网络的向量。
-
多头自注意力
一组attention的权重参数只能够表达一种词与词之间的关系,在nlp任务中,一种关系可能不足以表达。所以通过配置多组attention权重矩阵,最后通过线性组合,来综合表达。
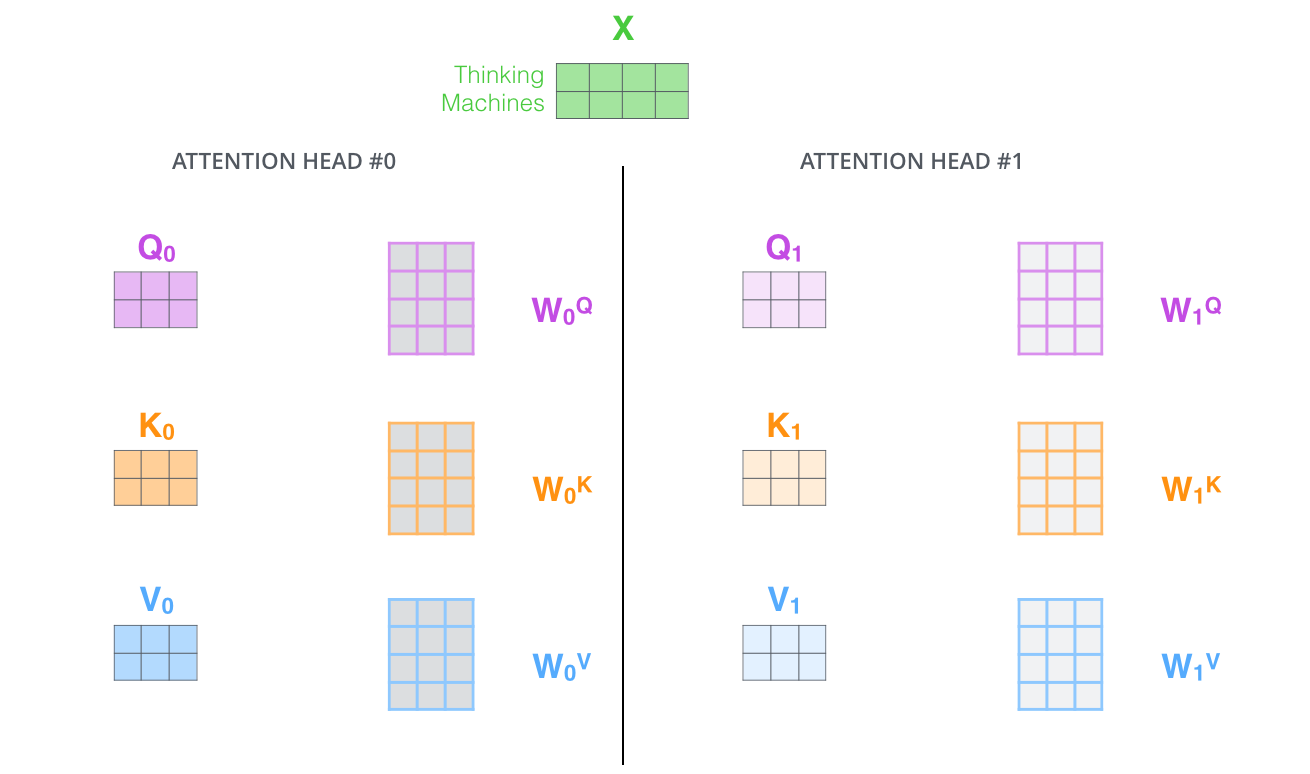
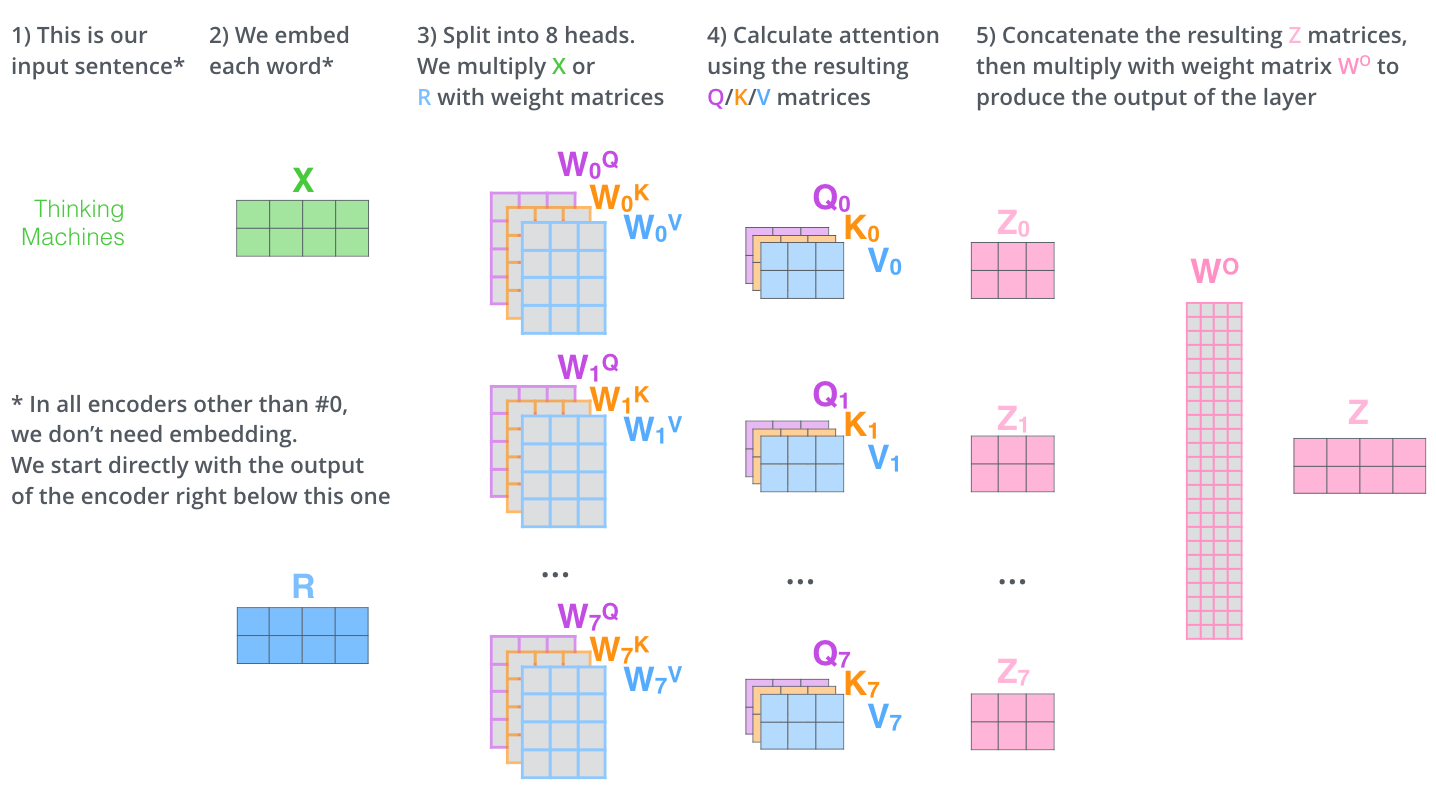
对于多头注意力,我们为每个头维护单独的 \(Q/K/V\) 权重矩阵,从而产生不同的 \(Q/K/V\) 矩阵。我们最终会得到八个不同的 Z 矩阵,随后连接这些矩阵,然后将它们乘以一个额外的权重矩阵 \(W^O\),得到最终的Z矩阵。
整个Self-Attention层可以描述为下图:
-
-
Feed Forward Neural Network
在进行了Attention操作之后,对向量先使用一个线性变换,再针对该线性变换的输出使用RELU函数,最后再针对RELU函数的输出使用一个线性变换。其效果与加上一层卷积核大小为1*1的CNN是一样的。
5. Add&Normalize
每个编码器中的每个子层周围都有一个残差连接,然后是LayerNormalize步骤。
![]()
Layer Normalization是作用于每个时序样本的归一化方法,其作用主要体现在:
- 作用于非线性激活函数前,能够将输入拉离激活函数非饱(防止梯度消失)和非线性区域(保证非线性);
- 保证样本输入的同分布。
在CNN类模型中,常用的归一化方法是Batch Normalization,即统计和学习跨样本各通道内的归一化方法;RNN类模型中,或者更一般的讲,在序列问题中,由于序列的天然时序性以及序列长度的不一致性,采用Layer Normalization更为合理。
Transformer在各层的MultiHead-Attention和FFN中均采用了Layer Normalization的技术,同时配以skip-connection,以提高信息的流通通道,提高模型的可训练性。
6. Transformer的解码器
![]()
解码器的组件与编码器基本完全相同,但有一定的区别:
- Self-Attention:也是计算输入的Self-Attention,但是因为是生成过程,因此在时刻 i 的时候,大于 i 的时刻都没有结果,只有小于 i 的时刻有结果,因此需要做Mask。因此这里实际上是Masked multi-head Self-Attention。
- 增加了一个Encoder-Decoder Attention。该层同样因为只能获取到当前时刻之前的输入,因此只对时刻 t 之前的时刻输入进行Attention计算,需要做Mask。同时该层的K和V是由Encoder提供的,而非点积得来的。
![]()
![]()
7. Linear + Softmax
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出,同时将Decoder的堆栈输出作为输入,从底部开始,最终进行单词预测。
8. Transformer的优势
- 长距离的信息捕捉。虽然RNN通过gate的引入,能在一定上改善长距离依赖,但自回归模型的梯度消失/爆炸仍限制了RNN模型的使用。而CNN模型的专场在于捕捉local特征,虽然可以通过空洞卷积和层次化的结构扩大感受野,但对于长距离的信息捕捉仍然较弱。而self-attention直接摆脱了距离的限制,能够很好的捕捉远距离的文本信息关系。
- 计算上的优势。RNN的另外一大缺点在于自回归模型无法实现并行计算,而self-attention的自交互式计算则没有这个问题,可以非常方便的进行并行计算。此外,一般embedding的维度是大于文本长度的,所以transformre的计算量更小。
- 性能上的优势。由于Transformer的self-attention对每两个token间的信息进行了交互,同时multi-head的方式也能够从各sub-space捕获更多的特征细节,所以用Transformer作为特征抽取器的模型在各种下游任务上的表现均明显优于传统的CNN和RNN模型。所以,Transformer在后续GPT、Bert、XLNet等预训练模型上的大火也就不难理解了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号