[自然语言处理入门]五、序列标注基础(2)
五、序列标注基础(2)
学习路线参考:
https://blog.51cto.com/u_15298598/3121189
https://github.com/Ailln/nlp-roadmap
https://juejin.cn/post/7113066539053482021
https://zhuanlan.zhihu.com/p/100567371
https://cloud.tencent.com/developer/article/1884740
本节学习使用工具&阅读文章:
https://zhuanlan.zhihu.com/p/156914795
https://spaces.ac.cn/archives/7213
https://zhuanlan.zhihu.com/p/97829287
https://www.zhihu.com/question/62399257
https://zhuanlan.zhihu.com/p/47802053
https://zhuanlan.zhihu.com/p/150103958?from_voters_page=true
1. 命名实体标注
命名实体识别是指识别中文文本中实体的边界和类别。命名实体识别是文本处理中的基础技术,广泛应用在自然语言处理、推荐系统、知识图谱等领域,比如推荐系统中的基于实体的用户画像、基于实体召回等。
-
命名实体分类
- 3大类:实体类、时间类、数字类
- 7小类:人名、地名、组织机构名、时间、日期、货币量、百分数
-
命名实体识别思想
通常先进行实体标注,然后识别单个实体,最后再识别复合实体。
-
实体标注方法
- IOB标注法:I表示内部,O表示外部,B表示开始
- BIOES标注法:B表示开始,I表示内部,O表示外部,E表示结束,S表示这个词是单独形成一个命名实体
2. 命名实体识别方法
- 基于规则的方法:依赖词典、模板、正则表达式等匹配方法。
- 基于机器学习方法:HMM、MEMM、ME、SVM、CRF,关注概率。
- 基于深度学习方法:BiLSTM-CNN-CRF、BERT-BiLSTM-CRF,关注整体。
基于机器学习方法的主要方法对比如下:
| 模型 | 优点 | 缺点 |
|---|---|---|
| ME最大熵 | 通用性好 | 训练效率低 |
| MEMM最大熵马尔科夫模型 | 充分利用特征 | 局部最优 |
| HMM隐马尔可夫模型 | 训练快 | 局部最优 |
| SVM支持向量机 | 理论完备 | 训练效率低 |
| CRF条件随机场 | 特征灵活、全局最优 | 依赖特征模版 |
3. MEMM
回顾CRF,其对概率分布\(P(Y|X)=P(y_1,y_2,……,y_n|X)\)建模。MEMM同样也是对该概率分布建模,其先对原概率分布进行分解,为:\(P(y_1,y_2,……,y_n|X)=P(y_1|X)P(y_2|X,y_1)……P(y_n|X,y_1,y_2,……,y_{n-1})\)
再假设标签依赖只发生在相邻位置,所以:\(P(y_1,y_2,……,y_n|X)=P(y_1|X)P(y_2|X,y_1)……P(y_n|X,y_{n-1})\)
再仿照线性链CRF的设计,可以设\(P(y_1|X)={1\over Z_1(X)}exp(f(y_1|X))\), \(P(y_k|X,y_{k-1})={1\over Z_k(X)}exp(g(y_{k-1},y_k)+f(y_k;X))\)
至此,这就得到了MEMM了。由于MEMM已经将整体的概率分布分解为逐步的分布之积了,所以算loss只需要把每一步的交叉熵求和。
对比MEMM和CRF,二者的区别仅在于分母(归一化因子\(Z(X)\))的计算方式不同,CRF的我们称之为是全局归一化的,而MEMM的我们称之为是局部归一化的。全局归一化模型效果通常好些,但实现通常相对困难一些;局部归一化模型效果通常不超过全局归一化模型,但胜在易于实现,并与易于拓展。
MEMM除了训练速度快之外,性能并不优于CRF。
4. LSTM-CRF
序列标注问题本质上是分类问题,因为其具有序列特征,所以LSTM就很合适进行序列标注。
我们可以直接利用LSTM进行序列标注。但是这样的做法有一个问题:每个时刻的输出没有考虑上一时刻的输出。我们在利用LSTM进行序列建模的时候只考虑了输入序列的信息,即单词信息,但是没有考虑标签信息,即输出标签信息。
这样会导致一个问题,以“我 喜欢 跑步”为例,LSTM输出“喜欢”的标签是“动词”,而“跑步”的标签可能也是“动词”。但是实际上,“名词”标签更为合适,因为“跑步”这里是一项运动。也就是“动词”+“名词”这个规则并没有被LSTM模型捕捉到。也就是说这样使用LSTM无法对标签转移关系进行建模。
而标签转移关系对序列标注任务来说是很重要的,所以就在LSTM的基础上引入一个标签转移矩阵对标签转移关系进行建模。
CRF有两类特征函数,一类是针对观测序列与状态的对应关系,一类是针对状态间关系。在LSTM+CRF模型中,前一类特征函数的输出由LSTM的输出替代,后一类特征函数就变成了标签转移矩阵。
可以将LSTM的输出矩阵看作是一个打分矩阵,将其输出作为CRF的发射概率;再由CRF自己学习转移概率,即构成了LSTM-CRF体系。
5. BiLSTM
利用LSTM对句子进行建模存在一个问题:无法编码从后到前的信息。在更细粒度的分类时,如对于强程度的褒义、弱程度的褒义、中性、弱程度的贬义、强程度的贬义的五分类任务需要注意情感词、程度词、否定词之间的交互。举一个例子,“这个餐厅脏得不行,没有隔壁好”,这里的“不行”是对“脏”的程度的一种修饰,通过BiLSTM可以更好的捕捉双向的语义依赖。
BiLSTM就是双向的LSTM,同时具备前向的LSTM和后向的LSTM。
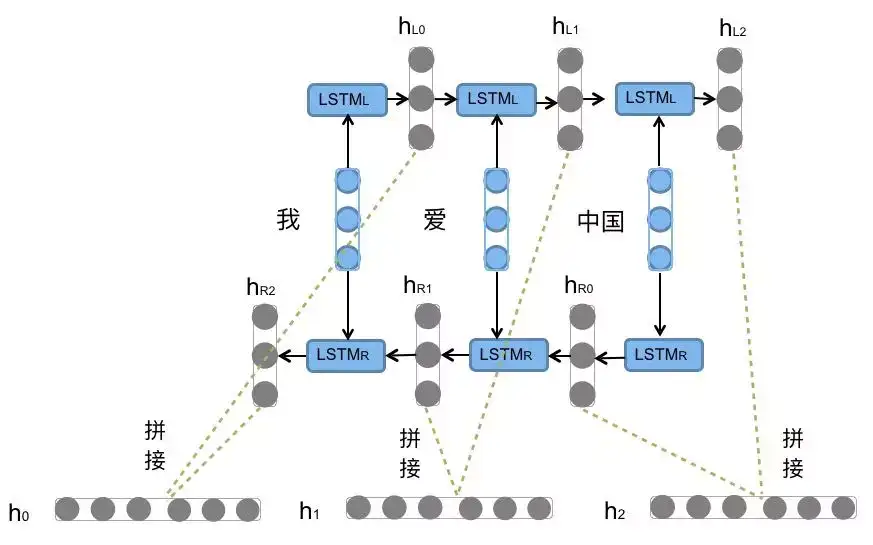
例如“我爱中国”这句话,前向LSTM依次输入我 爱 中国得到三个向量\(\{h_{L0},h_{L1},h_{L2}\}\),后向LSTM依次输入中国 爱 我得到三个向量\(\{h_{R0},h_{R1},h_{R2}\}\)。最后将前向和后向对应的隐向量进行拼接即可得到最终的结果。
6. BiLSTM-CRF
同LSTM-CRF一样,相比LSTM-CRF,BiLSTM更能识别上下文信息。
7. BiLSTM-CNNS-CRF
出自ACL2016《End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF》特点是END2END,不需要手工进行特征设计,不需要任何特征工程,这说明不需要手工的特征也能有好的性能。
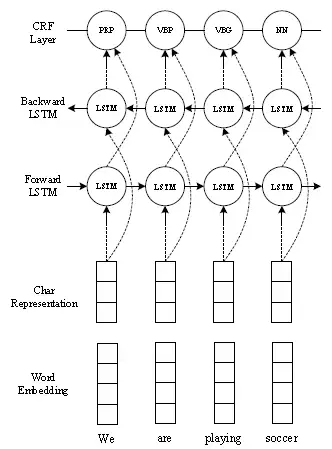
流程:
- 卷积神经网络:提取单词字符级表示
- BiLSTM:单向LSTM只能获取过去信息,无法获取未来信息,所以双向LSTM的基本思想是将每个序列向前和向后呈现到两个单独的隐藏状态,以分别捕获过去和未来的信息。 然后将两个隐藏状态连接起来形成最终的输出。
- CRF:使用条件随机场 (CRF)联合建模标签序列,而不是独立解码每个标签。
后面部分与BiLSTM-CRF是相同的,只是在前面加上了一个CNN。在先前的研究工作中发现,CNN可以有效抽取单词字符的形态学特征(如单词的前缀、后缀等)形成字符级别的表示特征。网络结构如下图所示,需要注意的是虚线表示Dropout操作。
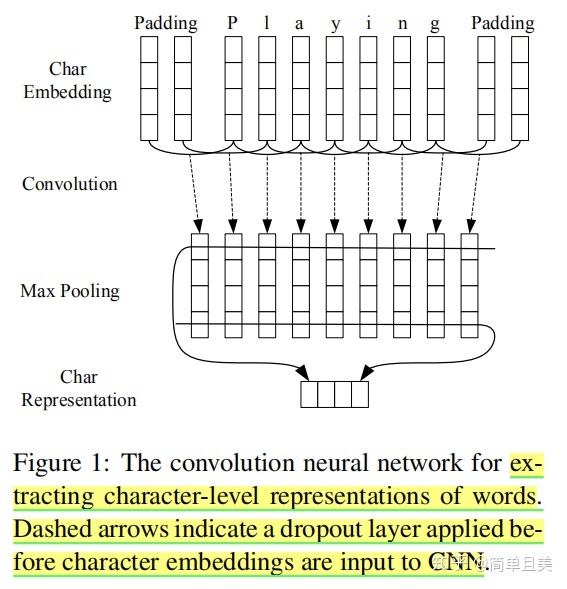
这里的Word Embedding分别使用了GloVe、Senna-50、Google's Word2Vec-300,实验表明GloVe的效果最好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号