[自然语言处理入门]二、基础语言模型
二、基础语言模型
学习路线参考:
https://blog.51cto.com/u_15298598/3121189
https://github.com/Ailln/nlp-roadmap
https://juejin.cn/post/7113066539053482021
https://zhuanlan.zhihu.com/p/100567371
https://cloud.tencent.com/developer/article/1884740
本节学习使用工具&阅读文章:
https://blog.csdn.net/u012328159/article/details/84719494
https://blog.csdn.net/xixiaoyaoww/article/details/105459590
https://medium.com/programming-with-data/11-詞袋模型-bag-of-words-34f5493902b4
https://zhuanlan.zhihu.com/p/31197209
https://blog.csdn.net/keeppractice/article/details/106177554
https://blog.csdn.net/u014665013/article/details/79642083
1. 词袋模型(BOW)
-
one-hot
词袋模型能够把一个句子转化为向量表示,是比较简单直白的一种方法,它不考虑句子中单词的顺序,只考虑词表中单词在这个句子中的出现次数。设词典的大小为n(词典中有n个词),假如某个词在词典中的位置为k,则设立一个n维向量,第k维置1,其余维全都置0。这个思想就是one-hot编码,中文叫独热编码。
- 优点:直观,容易操作,不需要任何与训练模型
- 缺点:无法表达前后语意关系,无法呈现单字的含义,形成稀疏矩阵,不利于模型训练
-
TF-IDF
\(TF(w)={单词w在文章中出现的次数\over文章的单词总数}\),表示词频,考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。
\(IDF(w)=log({语料库中文档的总数\over包含词w的文档数+1})\),加1是为了防止分母为0。用来模拟语言的使用环境,如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。它的大小与一个词的常见程度成反比。
\(TF-IDF(w)=TF(w)*IDF(w)\)
-
优点:直观,可以凸显单个词的重要性
-
缺点:无法表达前后语义关系,很少见的偏僻词容易被赋予过大的idf权重,idf在文档集合中进行计算,但是文档集合的内部存在不同类分布不均衡的情况
-
2. word2vector
为了解决词袋模型的通病:无法表达上下文关系,可以使用Word2vector模型。Word2Vector的主要作用是将语料中的单词映射到一个固定低维度的稠密向量空间中,使得相近的词(如orange和fruit,就比orange和house要近)在这个空间中的距离较近。由于词之间具有距离相似性,可以用来做聚类,分类,统计分析,可视化,所以word2vector属于一种预训练技术。
-
CBOW & skip-gram
CBOW:将一个词所在的上下文中的词作为输入,而那个词本身作为输出。
skip-gram:将一个词所在的上下文中的词作为输出,而词本身作为输入。
可以看作是一个将高维空间映射到低维空间的过程,用一个单层神经网络就可以实现这种功能。以下主要在Skip-Gram的形式下介绍相关原理。
-
Skip-Gram的具体做法
在语料中任意找到一个词,然后预测其周围词的概率,相邻范围由Window Size设定,下面取Window Size=2为例:
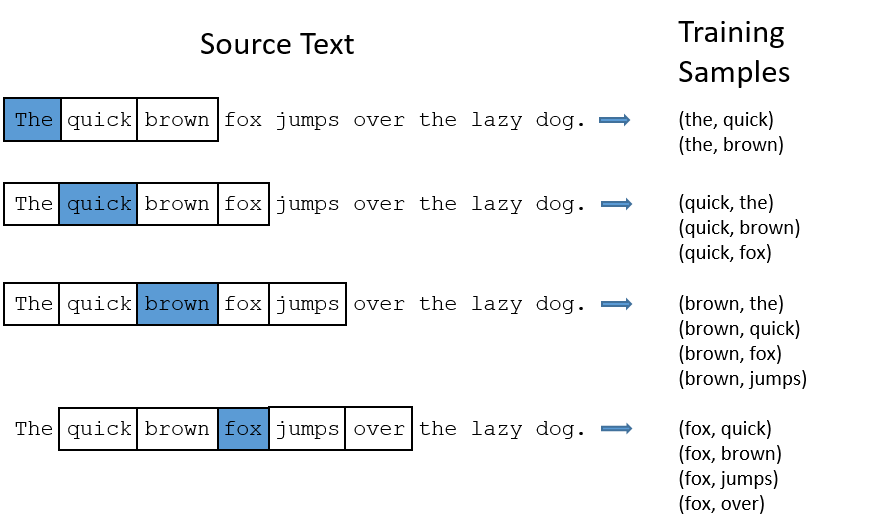
有了这些样本后,需要构建一个函数,接收词的One Hot编码,输出所有的词的概率p,如下:
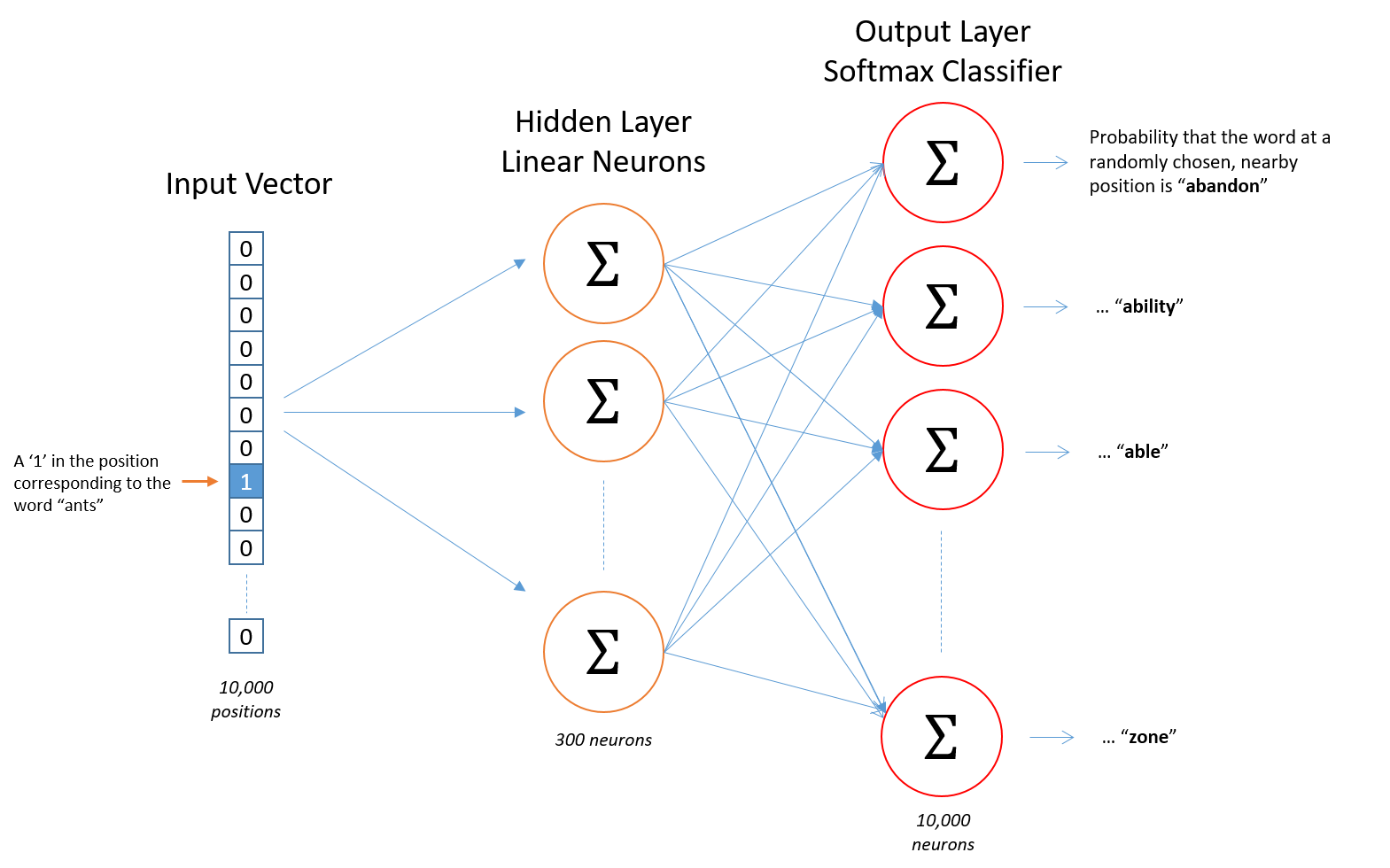
只有一个隐藏层,然后接一个Softmax层,将输出归一化为概率,词向量就是中间这个隐藏层的参数。
-
模型细节
假设从训练文档中抽取出n个唯一不重复的单词组成词汇表。对这n个单词进行one-hot编码,得到的每个单词都是一个n维的向量。此时,输出也是一个n维度(词汇表的大小)的向量,它包含了n个概率,每一个概率代表着当前词是输入样本中output word的概率大小。
我们基于成对的单词来对神经网络进行训练,训练样本是 ( input word, output word ) 这样的单词对,input word和output word都是one-hot编码的向量,最终模型的输出是一个概率分布。
-
隐藏层
如果我们现在想用m个特征来表示一个单词,那么隐层有m个结点,权重矩阵尺寸为n*m。
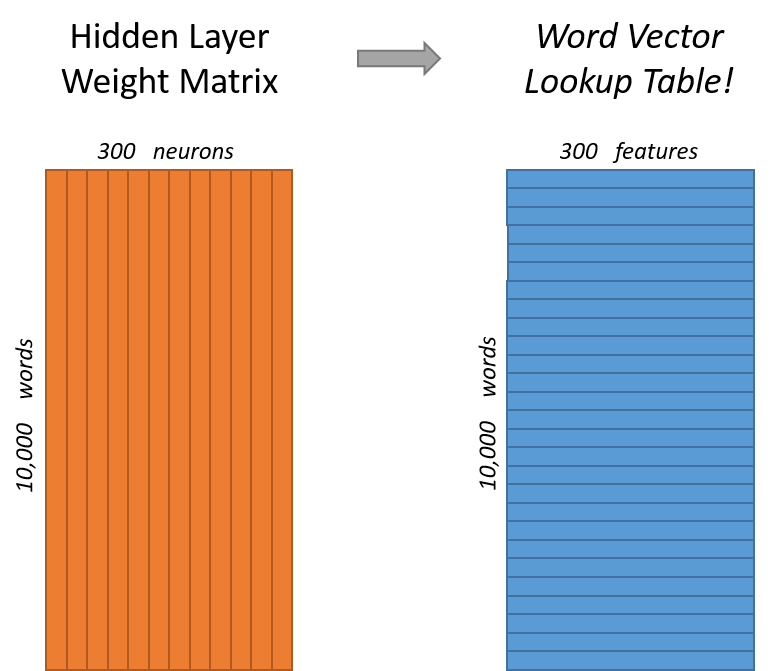
左右两张图分别从不同角度代表了输入层-隐层的权重矩阵。左图中每一列代表一个n维的词向量和隐层单个神经元连接的权重向量。从右边的图来看,每一行实际上代表了每个单词的词向量。
-
-
word2vector的优化
-
词汇表过大导致计算维度过大
使用Hierarchical Softmax方法,构建一棵Huffman树,每个单词都能通过从根节点开始的唯一一条路径进行表示。这棵Huffman树的权重则来源于每个单词出现的频率,根据每个单词的出现频率即可构建出Huffman树。
此时在word2vec中就转化为分层二分类逻辑斯蒂回归,从根节点出发,分为负类则向左子树走,分为正类则向右子树走,分类的依据来源于每个非叶子节点上所带有的内部节点向量。
训练依然使用基于梯度的方式,如SGD进行更新。
-
每次迭代的过程中都需要更新大量向量
使用负采样(Negative Sampling)方法。训练需要正负样本输入的,正样本(输出的上下文单词)当然需要保留下来,而负样本(不对的样本)同样需要采集,但是肯定不能是词库里面的所有其他词,因此我们需要采样,这个采样被就是所谓的Negative Sampling。
-
频繁词欠采样
包含部分频繁词(例如the)这类样本意义不是特别大,所以需要将这类样本从整体的训练样本中剔除。Word2Vector通过给每个词设定一个概率来随机剔除这个词,这个词的概率与词的频率有关:\(P(w_i)=1-\sqrt{t\over f(w_i)}\)。
其中\(f(w_i)\)表示词\(w_i\)的频率,\(t\)是词频的阈值,大于这个阈值的词需要欠采样,原始论文中给的值是\(10^{-5}\)。
-
随机窗口尺寸
通过随机减少上下文窗口长度来实现:对较近的词给予较高权重,同时减少训练样量,提升计算效率。比如上下文窗口window_size=5,那么每次计算样本时,随机在window_size=1到5之前选取,通过这种方法,较近词被选取的权重高,较远词被选取的权重低,示意图如下:

-
3. LSA
该方法对term-document矩阵(矩阵的每个元素为tf-idf)进行奇异值分解,从而得到term的向量表示和document的向量表示。此处使用的tf-idf主要还是term的全局统计特征。
4. Glove(Global Vector for Word)
GloVe模型结合了word2vec和LSA的特点,同时使用了语料库的全局统计特征,也使用了局部的上下文特征。首先基于语料库构建词的共现矩阵,然后基于共现矩阵和GloVe模型学习词向量。
-
统计共现矩阵
设共现矩阵为\(X\),其元素为\(X_{i , j}\) 的意义为:在整个语料库中,单词\(i\)和单词\(j\)共同出现在一个窗口中的次数。
-
GloVe模型
使用的代价函数:\(J=\sum^N_{i,j}f(X_{i,j})(v_i^Tv_j+b_i+b_j-log(X_{i,j}))^2\)
- \(v_i,v_j\):单词i和单词j的词向量
- \(b_i,b_j\):偏差项
- \(f\):权重项,\(f(x)=\begin{cases}(x/xmax)^{0.75}, if~x<xmax\\1,if~x>=xmax\end{cases}\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号