[Java]基础入门-Day 3
[Java]基础入门-Day3
学习使用工具
黑马2023新版Java视频教程 https://www.bilibili.com/video/BV1Fv4y1q7ZH?p=8&vd_source=03da0cdb826d78c565cd22a83928f4c2
Java程序员进阶之路 https://tobebetterjavaer.com/overview/java-can-do-what.html
Java泛型 https://www.runoob.com/java/java-generics.html
一、集合框架(容器)
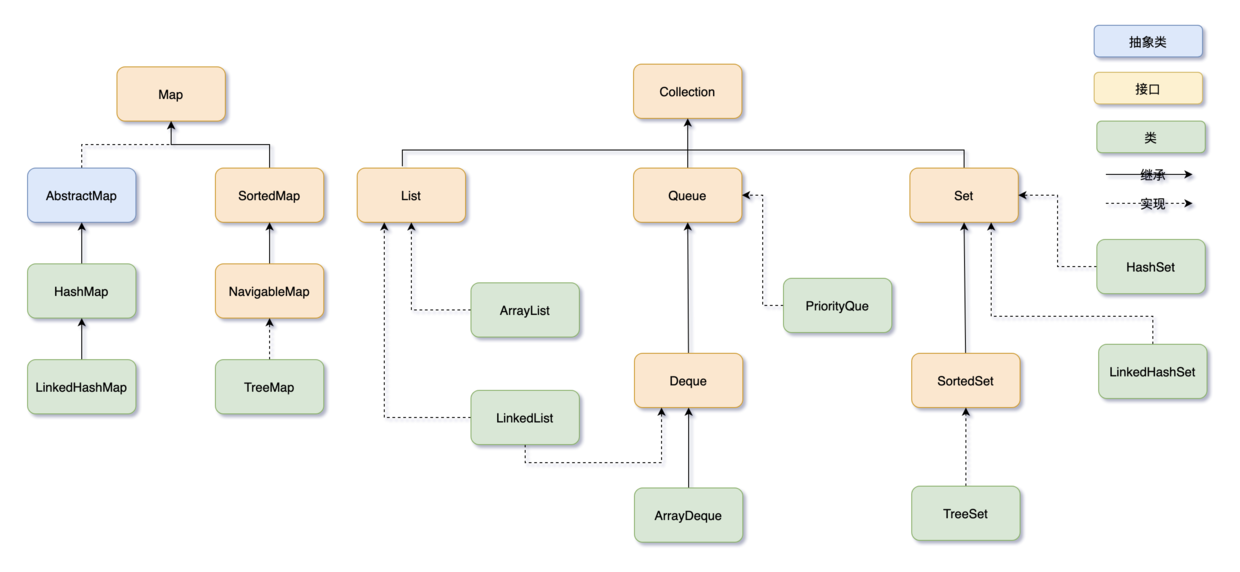
- Collection,主要由 List、Set、Queue 组成,List 代表有序、可重复的集合,典型代表就是封装了动态数组的 ArrayList 和封装了链表的 LinkedList;Set 代表无序、不可重复的集合,典型代表就是 HashSet 和 TreeSet;Queue 代表队列,典型代表就是双端队列 ArrayDeque,以及优先级队列 PriorityQueue。
- Map,代表键值对的集合,典型代表就是 HashMap
二、List
-
ArrayList:数组。支持随机存取,内部数组的容量不足时会自动扩容,当元素非常庞大的时候,效率会比较低。
// 创建一个ArrayList ArrayList<String> list = new ArrayList<String>(); // 添加元素 list.add("王二"); list.add("沉默"); list.add("陈清扬"); // 遍历集合 for 循环 for (int i = 0; i < list.size(); i++) { String s = list.get(i); System.out.println(s); } // 遍历集合 for each for (String s : list) { System.out.println(s); } // 删除元素 list.remove(1); // 修改元素 list.set(1, "王二狗"); -
LinkedList:双端链表,只支持顺序存取。插入和删除元素很方便。每个元素都存储了前一个和后一个节点的引用,所以相对来说,占用的内存空间会比 ArrayList 多一些。
// 创建一个集合 LinkedList<String> list = new LinkedList<String>(); // 添加元素 list.add("王二"); list.add("沉默"); list.add("陈清扬"); // 遍历集合 for 循环 for (int i = 0; i < list.size(); i++) { String s = list.get(i); System.out.println(s); } // 遍历集合 for each for (String s : list) { System.out.println(s); } // 删除元素 list.remove(1); // 修改元素 list.set(1, "王二狗");
三、Set
Set 的特点是存取无序,不可以存放重复的元素,不可以用下标对元素进行操作。Set 集合不是关注的重点,因为底层都是由 Map 实现的。
-
HashSet:其实是由 HashMap 实现的,只不过值由一个固定的 Object 对象填充,而键用于操作。
// 创建一个新的HashSet HashSet<String> set = new HashSet<>(); // 添加元素 set.add("沉默"); set.add("王二"); set.add("陈清扬"); // 输出HashSet的元素个数 System.out.println("HashSet size: " + set.size()); // output: 3 // 判断元素是否存在于HashSet中 boolean containsWanger = set.contains("王二"); System.out.println("Does set contain '王二'? " + containsWanger); // output: true // 删除元素 boolean removeWanger = set.remove("王二"); System.out.println("Removed '王二'? " + removeWanger); // output: true // 修改元素,需要先删除后添加 boolean removeChenmo = set.remove("沉默"); boolean addBuChenmo = set.add("不沉默"); System.out.println("Modified set? " + (removeChenmo && addBuChenmo)); // output: true // 输出修改后的HashSet System.out.println("HashSet after modification: " + set); // output: [陈清扬, 不沉默] -
LinkedHashSet:一种基于哈希表实现的Set接口,它继承自HashSet,并且使用链表维护了元素的插入顺序。因此,它既具有HashSet的快速查找、插入和删除操作的优点,又可以维护元素的插入顺序。
LinkedHashSet<String> set = new LinkedHashSet<>(); // 添加元素 set.add("沉默"); set.add("王二"); set.add("陈清扬"); // 删除元素 set.remove("王二"); // 修改元素 set.remove("沉默"); set.add("沉默的力量"); // 查找元素 boolean hasChenQingYang = set.contains("陈清扬"); System.out.println("set包含陈清扬吗?" + hasChenQingYang); -
TreeSet:一种基于红黑树实现的有序集合,它实现了 SortedSet 接口,可以自动对集合中的元素进行排序。按照键的自然顺序或指定的比较器顺序进行排序。
// 创建一个 TreeSet 对象 TreeSet<String> set = new TreeSet<>(); // 添加元素 set.add("沉默"); set.add("王二"); set.add("陈清扬"); System.out.println(set); // 输出 [沉默, 王二, 陈清扬] // 删除元素 set.remove("王二"); System.out.println(set); // 输出 [沉默, 陈清扬] // 修改元素:TreeSet 中的元素不支持直接修改,需要先删除再添加 set.remove("陈清扬"); set.add("陈青阳"); System.out.println(set); // 输出 [沉默, 陈青阳] // 查找元素 System.out.println(set.contains("沉默")); // 输出 true System.out.println(set.contains("王二")); // 输出 false
四、Queue
通常遵循先进先出(FIFO)的原则,新元素插入到队列的尾部,访问元素返回队列的头部。
-
ArrayDeque:一个基于数组实现的双端队列,为了满足可以同时在数组两端插入或删除元素的需求,数组必须是循环的,也就是说数组的任何一点都可以被看作是起点或者终点。
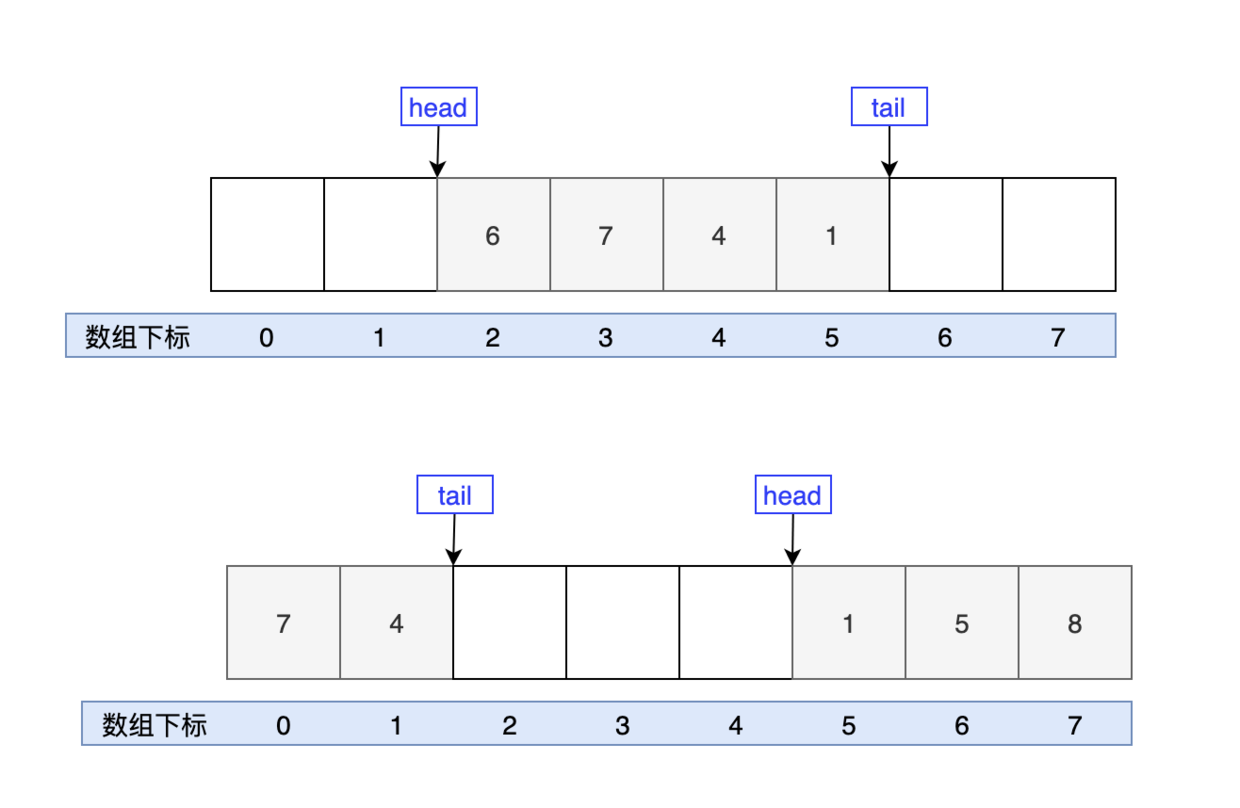
在循环队列中,需要牺牲一个存储空间用于判断队空和队满。
队头指针在队尾指针的下一位置时,队满。 Q.front == (Q.rear + 1) % MAXSIZE 因为队头指针可能又重新从0位置开始,而此时队尾指针是MAXSIZE - 1,所以需要求余。
当队头和队尾指针在同一位置时,队空。 Q.front == Q.rear。ArrayDeque<String> deque = new ArrayDeque<>(); // 添加元素 deque.add("沉默"); deque.add("王二"); deque.add("陈清扬"); // 删除元素 deque.remove("王二"); // 修改元素 deque.remove("沉默"); deque.add("沉默的力量"); // 查找元素 boolean hasChenQingYang = deque.contains("陈清扬"); System.out.println("deque包含陈清扬吗?" + hasChenQingYang); -
LinkedList:一般应该归在 List 下,只不过,它也实现了 Deque 接口,可以作为队列来使用。
// 创建一个 LinkedList 对象 LinkedList<String> queue = new LinkedList<>(); // 添加元素 queue.offer("沉默"); queue.offer("王二"); queue.offer("陈清扬"); System.out.println(queue); // 输出 [沉默, 王二, 陈清扬] // 删除元素 queue.poll(); System.out.println(queue); // 输出 [王二, 陈清扬] // 修改元素:LinkedList 中的元素不支持直接修改,需要先删除再添加 String first = queue.poll(); queue.offer("王大二"); System.out.println(queue); // 输出 [陈清扬, 王大二] // 查找元素:LinkedList 中的元素可以使用 get() 方法进行查找 System.out.println(queue.get(0)); // 输出 陈清扬 System.out.println(queue.contains("沉默")); // 输出 false // 查找元素:使用迭代器的方式查找陈清扬 // 使用迭代器依次遍历元素并查找 Iterator<String> iterator = queue.iterator(); while (iterator.hasNext()) { String element = iterator.next(); if (element.equals("陈清扬")) { System.out.println("找到了:" + element); break; } } -
PriorityQueue:一种优先级队列,它的出队顺序与元素的优先级有关,执行 remove 或者 poll 方法,返回的总是优先级最高的元素。想有优先级,元素就需要实现Comparable 接口或者 Comparator 接口。
// 创建一个 PriorityQueue 对象 PriorityQueue<String> queue = new PriorityQueue<>(); // 添加元素 queue.offer("沉默"); queue.offer("王二"); queue.offer("陈清扬"); System.out.println(queue); // 输出 [沉默, 王二, 陈清扬] // 删除元素 queue.poll(); System.out.println(queue); // 输出 [王二, 陈清扬] // 修改元素:PriorityQueue 不支持直接修改元素,需要先删除再添加 String first = queue.poll(); queue.offer("张三"); System.out.println(queue); // 输出 [张三, 陈清扬] // 查找元素:PriorityQueue 不支持随机访问元素,只能访问队首元素 System.out.println(queue.peek()); // 输出 张三 System.out.println(queue.contains("陈清扬")); // 输出 true // 通过 for 循环的方式查找陈清扬 for (String element : queue) { if (element.equals("陈清扬")) { System.out.println("找到了:" + element); break; } }
五、Map
Map 保存的是键值对,键要求保持唯一性,值可以重复。
-
HashMap:实现了 Map 接口,可以根据键快速地查找对应的值——通过哈希函数将键映射到哈希表中的一个索引位置,从而实现快速访问。这里先大致了解一下 HashMap 的特点:
- HashMap 中的键和值都可以为 null。如果键为 null,则将该键映射到哈希表的第一个位置。
- 可以使用迭代器或者 forEach 方法遍历 HashMap 中的键值对。
- HashMap 有一个初始容量和一个负载因子。初始容量是指哈希表的初始大小,负载因子是指哈希表在扩容之前可以存储的键值对数量与哈希表大小的比率。默认的初始容量是 16,负载因子是 0.75。
// 创建一个 HashMap 对象 HashMap<String, String> hashMap = new HashMap<>(); // 添加键值对 hashMap.put("沉默", "cenzhong"); hashMap.put("王二", "wanger"); hashMap.put("陈清扬", "chenqingyang"); // 获取指定键的值 String value1 = hashMap.get("沉默"); System.out.println("沉默对应的值为:" + value1); // 修改键对应的值 hashMap.put("沉默", "chenmo"); String value2 = hashMap.get("沉默"); System.out.println("修改后沉默对应的值为:" + value2); // 删除指定键的键值对 hashMap.remove("王二"); // 遍历 HashMap for (String key : hashMap.keySet()) { String value = hashMap.get(key); System.out.println(key + " 对应的值为:" + value); } -
LinkedHashMap:HashMap 是无序的,LinkedHashMap 是有序的。LinkedHashMap 可以看作是 HashMap + LinkedList 的合体,它使用了哈希表来存储数据,又用了双向链表来维持顺序,会维持键值对的插入顺序。
-
TreeMap:实现了 SortedMap 接口,可以自动将键按照自然顺序或指定的比较器顺序排序,并保证其元素的顺序。内部使用红黑树来实现键的排序和查找。
六、泛型
泛型方法:该方法在调用时可以接收不同类型的参数。根据传递给泛型方法的参数类型,编译器适当地处理每一个方法调用。
下面是定义泛型方法的规则:
- 所有泛型方法声明都有一个类型参数声明部分(由尖括号分隔),该类型参数声明部分在方法返回类型之前(在下面例子中的
)。 - 每一个类型参数声明部分包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。
- 类型参数能被用来声明返回值类型,并且能作为泛型方法得到的实际参数类型的占位符。
- 泛型方法体的声明和其他方法一样。注意类型参数只能代表引用型类型,不能是原始类型(像 int、double、char 等)。
java 中泛型标记符:
- E - Element (在集合中使用,因为集合中存放的是元素)
- T - Type(Java 类)
- K - Key(键)
- V - Value(值)
- N - Number(数值类型)
- ? - 表示不确定的 java 类型
public class GenericMethodTest
{
// 泛型方法 printArray
public static < E > void printArray( E[] inputArray )
{
// 输出数组元素
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}
public static void main( String args[] )
{
// 创建不同类型数组: Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3, 4, 5 };
Double[] doubleArray = { 1.1, 2.2, 3.3, 4.4 };
Character[] charArray = { 'H', 'E', 'L', 'L', 'O' };
System.out.println( "整型数组元素为:" );
printArray( intArray ); // 传递一个整型数组
System.out.println( "\n双精度型数组元素为:" );
printArray( doubleArray ); // 传递一个双精度型数组
System.out.println( "\n字符型数组元素为:" );
printArray( charArray ); // 传递一个字符型数组
}
}
泛型类:泛型类的声明和非泛型类的声明类似,除了在类名后面添加了类型参数声明部分。
和泛型方法一样,泛型类的类型参数声明部分也包含一个或多个类型参数,参数间用逗号隔开。一个泛型参数,也被称为一个类型变量,是用于指定一个泛型类型名称的标识符。因为他们接受一个或多个参数,这些类被称为参数化的类或参数化的类型。
public class Box<T> {
private T t;
public void add(T t) {
this.t = t;
}
public T get() {
return t;
}
public static void main(String[] args) {
Box<Integer> integerBox = new Box<Integer>();
Box<String> stringBox = new Box<String>();
integerBox.add(new Integer(10));
stringBox.add(new String("菜鸟教程"));
System.out.printf("整型值为 :%d\n\n", integerBox.get());
System.out.printf("字符串为 :%s\n", stringBox.get());
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号