
NVIDIA(Hopper)H100 Tensor Core GPU 架构
NVIDIA(Hopper)H100 Tensor Core GPU 架构

NVIDIA H100 Tensor Core GPU 是 NVIDIA 最新的(2022 年发布)通用可编程流式 GPU,适用于 HPC、AI、科学模拟和数据分析。H100 GPU 主要用于执行 AI、HPC 和数据分析的数据中心和边缘计算工作负载,较少用于图形处理。
H100 是第一款真正异步的 GPU,它扩展了 A100(A100 是 NVIDIA 的上一代 GPU)所有地址空间的全局到共享异步传输,使应用程序能够构建端到端异步管道,将数据移入和移出芯片,完全重叠并隐藏数据移动与计算。
采用 InfiniBand 互连的 H100 可提供比之前的 GPU 型号 A100 高达 30 倍的性能。H100 与 NVIDIA Grace CPU 搭配使用,具有超快的 NVIDIA 芯片间互连,可提供 900GB/s 的总带宽,比 PCIe Gen5 互连快 7 倍,因此与当今最快的服务器相比,可提供高 30 倍的总带宽,并且对于使用 TB 级数据的应用程序,可提供高达 7 倍的性能。

以下是 H100 相对于 A100(上一代 GPU)的改进:
- 与 A100 相比,张量核心速度提高了 6 倍(第 4 代)。这意味着在更广泛的 AI 和 HPC 任务上,矩阵计算速度提高了 6 倍。
- DPX(动态规划 X)指令可将动态规划算法的速度提高到 A100 的 7 倍。DP 通常用于广泛的优化、数据处理和基因组学算法中。
- 每个流式多处理器的时钟性能提高 2 倍,另外还增加了流式多处理器的数量和更高的时钟频率。
- 数据类型 IEEEFP64 和 FP32(64 位和 32 位浮点数)的处理速度提高了 3 倍。
- H100 具有新的线程块集群,可扩大 CUDA 线程组层次结构。集群是一组保证同时调度的线程块,可实现跨多个 SM 的线程高效协作和数据共享。也就是说,集群可使跨多个流式多处理器同时运行的多个线程块同步并协作以获取和交换数据。集群还可以更高效地协同驱动异步单元,如张量内存加速器和张量核心。线程块集群允许以比单个流式多处理器上的单个线程块更大的粒度控制局部性,从而通过添加编程层次结构来扩展 CUDA 编程模型,现在包括线程、线程块、线程块集群和网格。
- NVIDIA 异步事务屏障使集群内的通用 CUDA 线程和片上加速器能够高效同步,即使它们位于单独的 SM 上,也能使每个用户和应用程序始终充分使用其 H100 GPU 的所有单元。
- 用于流式多处理器之间直接通信的分布式共享内存。
- 使用张量内存加速器 (TMA)单元进行异步执行,可以在全局内存和共享内存之间高效传输大块数据。现在只需要少量 CUDA 线程即可使用张量内存加速器管理 H100 的整个内存带宽,而大多数其他 CUDA 线程可以专注于通用计算,例如新一代张量核心的预处理和后处理数据。
- Transformer 引擎可加速转换后的模型训练和推理。它智能地管理 FP8 和 16 位计算并在两者之间动态选择,自动处理每层 FP8 和 16 位之间的重新转换和缩放,与 A100 相比,可提供 9 倍更快的 AI 训练和 30 倍更快的 LLM 推理。
- HBM3 内存子系统的带宽是 A100 的 2 倍。H100 SXM5 GPU 是世界上第一款配备 HBM3 内存的 GPU,可提供 3TB/秒的内存带宽。
- 50 MB L2 缓存架构可缓存大量模型和数据集以供重复访问,从而减少 HBM3 的访问次数。H100 中的 50 MB L2 缓存比 A100 的 40 MB L2 大 1.25 倍。HBM3 或 HBM2e DRAM 和 L2 缓存子系统均支持数据压缩和解压缩技术,以优化内存和缓存的使用率和性能。
- 第二代多实例 GPU (MIG) 技术与 A100 相比,每个 GPU 实例的计算能力提高了 3 倍,内存带宽提高了 2 倍。
- 新的机密计算支持更好地隔离虚拟机,更好地保护数据。
- 第四代 NVIDIA NVLink在所有减少操作上将带宽提高了 3 倍,与上一代 NVLink 相比,总体带宽提高了 50% ,多 GPU IO 的总带宽为900 GB/秒,运行带宽是 PCIe Gen 5 的 7 倍。
- 第三代 NVSwitch技术,在节点内外均配备交换机,用于连接服务器、集群和数据中心环境中的多个 GPU。节点内的每个 NVSwitch 提供 64 个第四代 NVLink 链路端口,以加速多 GPU 连接。总交换机吞吐量从 A100 中的 7.2 Tbits/秒增加到 13.6 Tbits/秒。
- 新的NVLink 交换机系统互连技术和新的二级NVLink 交换机引入了地址空间隔离和保护,最多可连接32 个节点或 256 个 GPU,采用 2:1 锥形胖树拓扑。这些连接的节点可以提供57.6 TB/秒的全对全带宽和1 exaFLOP 的 FP8 稀疏 AI 计算。
- PCIe Gen 5提供128 GB/秒的总带宽(每个方向 64 GB/秒),而 Gen 4 PCIe 提供 64 GB/秒的总带宽(每个方向 32 GB/秒)。
- 安全 MIG 将GPU 划分为独立的、大小合适的实例,以最大限度地提高较小工作负载的服务质量 (QoS)。
- H100 支持新的计算能力 9.0。
GH100 GPU 芯片
为 H100 GPU 提供动力的完整 GH100 GPU 采用台积电 4N 工艺制造。它拥有 800 亿个晶体管,芯片尺寸为 814 平方毫米,并采用更高频率的设计。
与基于台积电 7nm N7 工艺的上一代 GA100 GPU 相比,使用台积电 4N 制造工艺使 H100 能够提高 GPU 核心频率、提高每瓦性能并集成更多的 GPC、TPC 和 SM。
让我们来看看用于制造 H100 GPU 的 GH100 GPU 芯片(硅板)的硬件特性:
为 H100 GPU 供电的 GH100 GPU 芯片由以下部分组成:
- 8 个 GPC(GPU 处理集群),
- 72 个 TPC(纹理处理簇 9 个 TPC/GPC),
- 流式多处理器 (SM)(2 SM/TPC),
- 每个完整 GPU 有 144 个 SM,
- 60 MB 二级缓存和
- 6 个 HBM3 或 HBM2e 堆栈、12 个 512 位内存控制器
- 每个 SM 有 128 个 FP32 CUDA 核心,每个完整 GPU 有 18432 个 FP32 CUDA 核心
- 每个 SM 有 4 个第四代 Tensor Core,每个完整 GPU 有 576 个
- 第四代 NVLink 和 PCIe Gen 5
NVIDIA H100 SXM和NVIDIA H100 NVL是 H100 GPU 的两种变体,专为不同目的而设计,在外形尺寸、内存和用例方面存在关键差异。
采用 SXM5 板外形的 NVIDIA H100 GPU包括以下单元:
- 8 个 GPC、66 个 TPC、2 个 SM/TPC、每个 GPU 132 个 SM
- 每个 SM 有 128 个 FP32 CUDA 核心,每个 GPU 有 16896 个 FP32 CUDA 核心
- 每个 SM 有 4 个第四代 Tensor Core,每个 GPU 有 528 个
- 80 GB HBM3、5 个 HBM3 堆栈、10 个 512 位内存控制器
- 50 MB 二级缓存
- 第四代 NVLink 和 PCIe Gen 5
- 它专为具有 Nvidias NVLink 互连技术的服务器而设计,适用于AI 训练、HPC 和大型企业工作负载,其中多个 GPU 一起使用以实现最大的并行性和性能,并且需要液冷或风冷的服务器环境。
采用 PCIe Gen 5 板型的 NVIDIA H100 GPU包括以下单元:
- 7 或 8 个 GPC、57 个 TPC、2 个 SM/TPC、每个 GPU 114 个 SM
- 128 个 FP32 CUDA 核心/SM,每个 GPU 有 14592 个 FP32 CUDA 核心
- 每个 SM 有 4 个第四代 Tensor Core,每个 GPU 有 456 个
- 80 GB HBM2e、5 个 HBM2e 堆栈、10 个 512 位内存控制器
- 50 MB 二级缓存
- 第四代 NVLink 和 PCIe Gen 5。虽然它仍然提供 GPU 到 GPU 的通信,但与 SXM 外形尺寸(具有更高的 NVLink 带宽)相比,它通常仅限于较少的 GPU。
- 通常使用风冷系统,但这取决于服务器或工作站环境。
NVIDIA H100 NVL包括以下单元:
- 双 GPU 板将两个 H100 GPU组合成一张卡。它专为非常特定的高内存、大规模 AI 工作负载而设计。
- NVL 卡上的两个 H100 GPU 均配备94 GB HBM3 内存,总计188 GB。这种巨大的内存容量对于大型语言模型 (LLM)和需要大量内存来存储参数的 AI 模型的推理至关重要。
- H100 NVL 使用NVLink 直接连接卡上的两个 GPU,从而实现它们之间的高带宽通信。这对于处理需要在 GPU 之间高效传递数据的大型 AI 模型至关重要。
- H100 NVL 高度专业化,适用于AI 推理,尤其是用于服务大型语言模型(例如 GPT 模型),其中双 GPU 设计和大内存容量用于大规模部署大量模型。它在 AI 训练或通用计算任务方面不如 PCIe 变体那么通用。
- 主要用于以AI 推理为重点的数据中心或高性能环境,特别是处理大量 AI 工作负载的企业级部署。
- 由于双 GPU 设计的功耗和散热要求较高,NVL 通常需要液体冷却。
H100 GPU 主要用于执行 AI、HPC 和数据分析的数据中心和边缘计算工作负载,但不用于图形处理。SXM5 和 PCIe H100 GPU 中只有两个 TPC 具有图形功能(即它们可以运行顶点、几何和像素着色器)。
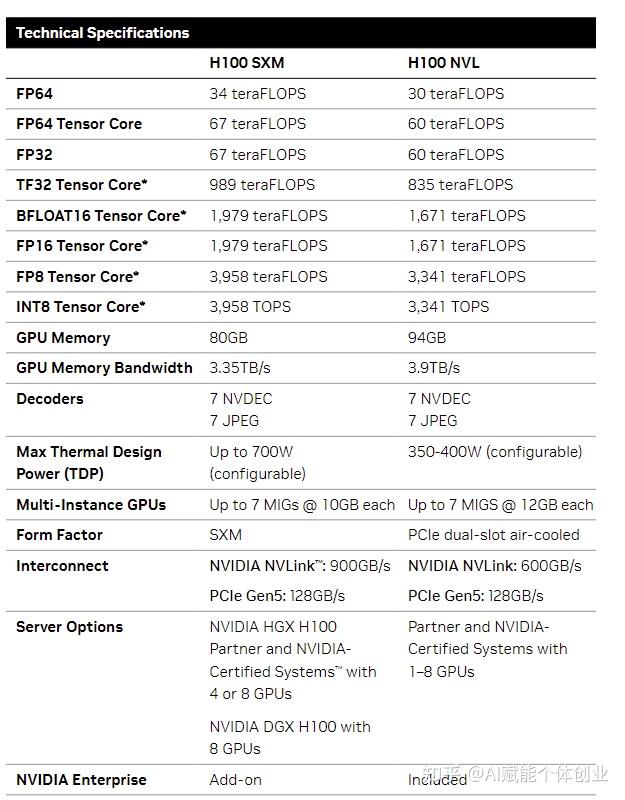
GH100 流式多处理器的架构
H100 Tensor Core 架构
Tensor Core 是用于矩阵乘法和累加 (MMA) 数学运算的高性能处理元素。与标准浮点 (FP)、整数 (INT) 和融合乘法累加 (FMA) 运算相比,在一个 NVIDIA GPU 中跨 SM 并行运行的 Tensor Core 可大幅提高吞吐量和效率。
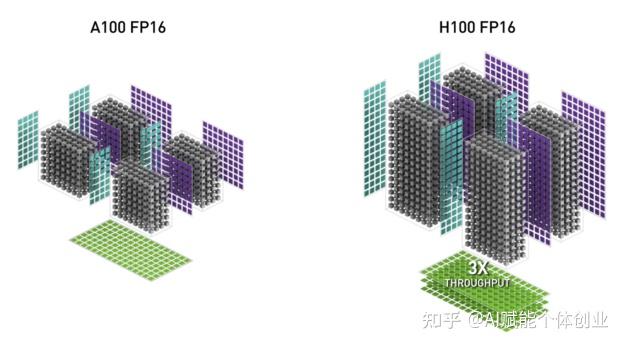
与 A100 相比,H100 中的 Tensor Core 架构使每个 SM 的原始密集和稀疏矩阵数学吞吐量提高了 2 倍。它支持 FP8、FP16、BF16、TF32、FP64 和 INT8 MMA 数据类型。
H100 中的 FP8 Tensor Cores 支持 FP32 和 FP16 累加器以及两种新的 FP8 输入数据类型 -具有 4 个指数位、3 个尾数位和 1 个符号位的E4M3和具有 5 个指数位、2 个尾数位和 1 个符号位的E5M2。
E4M3 支持需要较小动态范围和更高精度的计算,而 E5M2 则提供更宽的动态范围和更低的精度。新的 Transformer 引擎同时使用 FP8 和 FP16 精度来减少内存使用量并提高性能,同时仍保持大型语言和其他模型的准确性。
NVIDIA H100 可以提供比 A100 大约 6 倍的计算性能提升,因为它拥有 132 个流式多处理器 (SM),比 A100 中的 SM 数量多 22%(108 个),由于其新的第四代 Tensor Core,每个 H100 SM 的速度都提高了 2 倍。在每个 Tensor Core 中,新的 FP8 格式和相关的变压器引擎又提供了 2 倍的改进。随着时钟频率的提高,H100 的性能又提高了 1.3 倍。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号