
降本30%,酷家乐海量数据冷热分离设计与实践
降本30%,酷家乐海量数据冷热分离设计与实践

作者 | 王小波
编辑 | 李忠良
降本增效一直是研发团队追求的目标之一,面对不断上涨的数据量,研发侧开始思考如何在不降低用户体验的情况下进行成本压减,冷热数据分离的架构思想引起了我们的注意。
背 景
定制家具业务是酷家乐最早的业务之一,定制家具的方案数据也同样沉淀了多年的数据;数据库从早期的 MongoDB 到切换到现在的 HBase;存储逻辑也从原来的全量保存演进到现在的分片增量保存。
随着数据量不断增大,带来的是巨大的成本压力与运维难度,目前定制 HBase 集群仅单副本数据量接近 150TB,再考虑到多副本和灾备集群,相关设备成本不是一个小数。近几年来,随着酷家乐的高速发展,每年用户创建的方案数量都在快速增长,单方案的复杂度也在不断提升,但在产品层面,除了回收站功能,暂时没有增加更多的方案生命周期管理能力。
降本增效一直是研发团队追求的目标之一,面对不断上涨的数据量,研发侧开始思考如何在不降低用户体验的情况下进行成本压减,冷热数据分离的架构思想引起了我们的注意。
通过实施数据的冷热分离,可以大幅降低 HBase 相关的使用成本,使得其数据量仅与热数据期限时间内的用户活跃度有关,不会大规模增长,而冷数据成本则可以随着时间的推移线性增长。
一句话概括就是:成本可控,长期可持续。
业务背景 - 增量分片式方案存储架构简要介绍
方案数据是一个非结构化的数据,里面包含了参数化模型的数据,也包含了一些其他有关设计方案的元数据。最早期阶段,我们的做法是将整个方案 JSON 序列化、压缩后,直接扔到存储中。后来随着单方案复杂度的不断提升,一部分巨型方案的数据量很快触及服务端应用的极限,使得接口传输时间变长、接口容易超时、应用 FullGC 频繁等,这种设计无法继续承载大方案的设计。
我们开始尝试拆分,由于方案数据中,参数化模型所占的比例最大,我们对其采用分片保存的处理,将部分模型组成一个 Packet 一同保存。这种方式由于单个模型的复杂度不一,单 Packet 内含有的模型数量不好估计,容易导致部分 Packet 仍然很大,且无法实现修改一个模型时,只修改一部分数据的目的,需要覆写较多的无效数据,最终灰度一段时间后暂停。
最终我们将分片粒度拆分到最小,实现一个模型保存一条记录,做到了比较极致的增量保存。
整个方案数据由 1 条元数据 + N 条分片数据组成,元数据(MetaData)持有引用分片数据的 ID。方案保存时,仅需保存修改过的模型数据,然后在保存完整的元数据即可。避免了一次性序列化一整个大方案带来的性能问题。
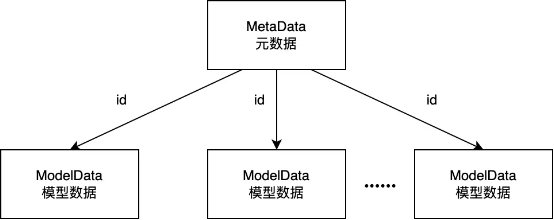
调研分析
冷数据的定义
俗话说的好,“If you can’t measure it, you can’t manage it。“
我们要做冷热分离,首先要了解用户的使用情况,再来做针对性的分析和处理。我们先在接口中添加数据埋点,统计用户获取方案距离上次保存的时间间隔,得到一段时间内的统计数据。
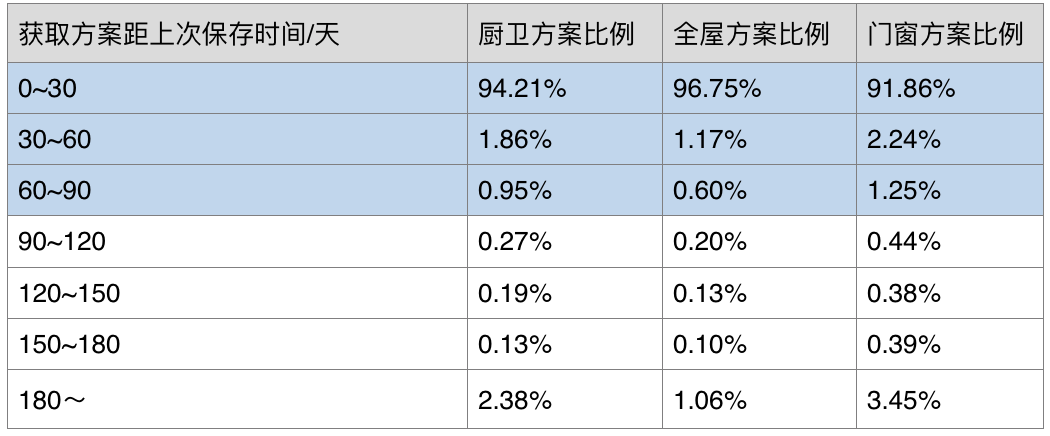
该表格清楚的展示了用户操作方案的使用习惯:大部分方案的使用、获取都会在 2 个月内完成,之后可能只有偶尔的打开。
考虑产品上给用户约定的可恢复历史方案的时限是 90 天,为避免恢复历史方案后历史元数据对当前数据冷热状态的混淆,并综合考虑上述的统计数据,我们把冷热方案的分界线定义为 100 天,100 天以上未修改的方案定义为冷方案。
冷热分离技术调研
- 使用云厂商提供的方案
由于酷家乐的基础设施运行在公有云上,云上解决方案本应是我们优先考虑的。但各家云厂商提供的技术解决方案不尽相同,考虑到兼容性和云中立性,这里不适宜选择云厂商提供的服务,不展开过多,感兴趣的读者可以自行搜索。
- 使用 HBase 社区版的功能
可使用 HDFS Archival Storage + HBase CF-level Storage Policy 技术方案。
该方案是以表为最小粒度,支持将不同的表存储到不同的存储介质中。如果我们同时使用了 SSD 和 HDD,则可以将不同性能要求的表存储到不同的介质中。
该方案也不能满足我们的业务要求,理由如下:当前定制方案各个表对读写性能的需求一致,无法接受一些表性能差,一些表性能好,以表粒度区分冷热数据,粒度太粗。
定制方案 HBase 集群因为数据量大,已经在使用全 HDD 集群,无法在存储介质上进一步降本。
3. 自研冷热数据分离方案
使用定时任务将冷方案数据逐步迁移到对象存储,同时在业务层与数据层之间增加分层,用于隔离冷热数据获取的细节。这个方案的优点是:基于对业务数据的理解,自研方案可以更好的做到数据一致性。细节可控,进度可控。方案存取已经作为一个单独的微服务应用,改造对业务方的透明;缺点是需要代码改造,有开发成本。迁移需要避开业务高峰期,无法持续高负载迁移,需要较长时间才能完成。考虑到以上种种条件及限制,我们最终采用自研冷热数据分离的方案。
方案设计
基本原则、目标
- 用户体验无感知。
- 保证数据安全与数据一致性。
- 支持重跑。
- 尽可能减少脏数据。
- 可灵活控制迁移速度。
架构图
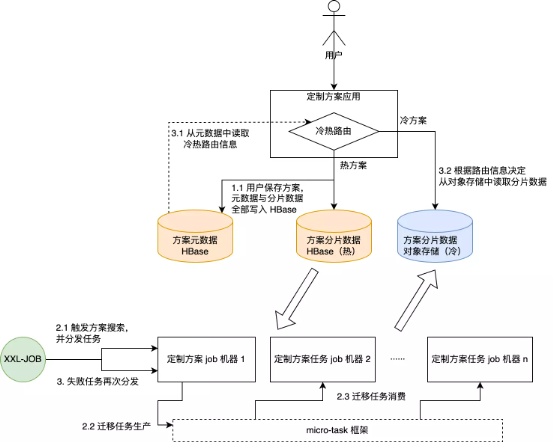
结合公司当前已有的基础设施与中间件,设计的整体架构如下(micro-task 是酷家乐内部开发的一款分布式任务框架):
- 用户保存方案时,元数据直接保存进 HBase;
- 分片数据保存时,根据元数据保存的路由信息,决定保存至 HBase 或对象存储;
- 取数据时,元数据直接从 HBase 中获取,同时提供冷热的路由信息决定如何获取分片数据;
- 每日低峰期由定时任务触发处理最后修改时间为 100 天前的方案,将其分片数据迁移到对象存储中;
- 迁移任务完成后,触发失败任务重试,减少人工关注;
数据操作原则
在总体架构的设计下,拆分出每日 3 个定时任务:
- 冷方案迁移任务
- 失败任务重试任务
- 检查失败任务并报警任务
下面逐一来看各个任务流程细节:
【冷方案迁移的任务】:
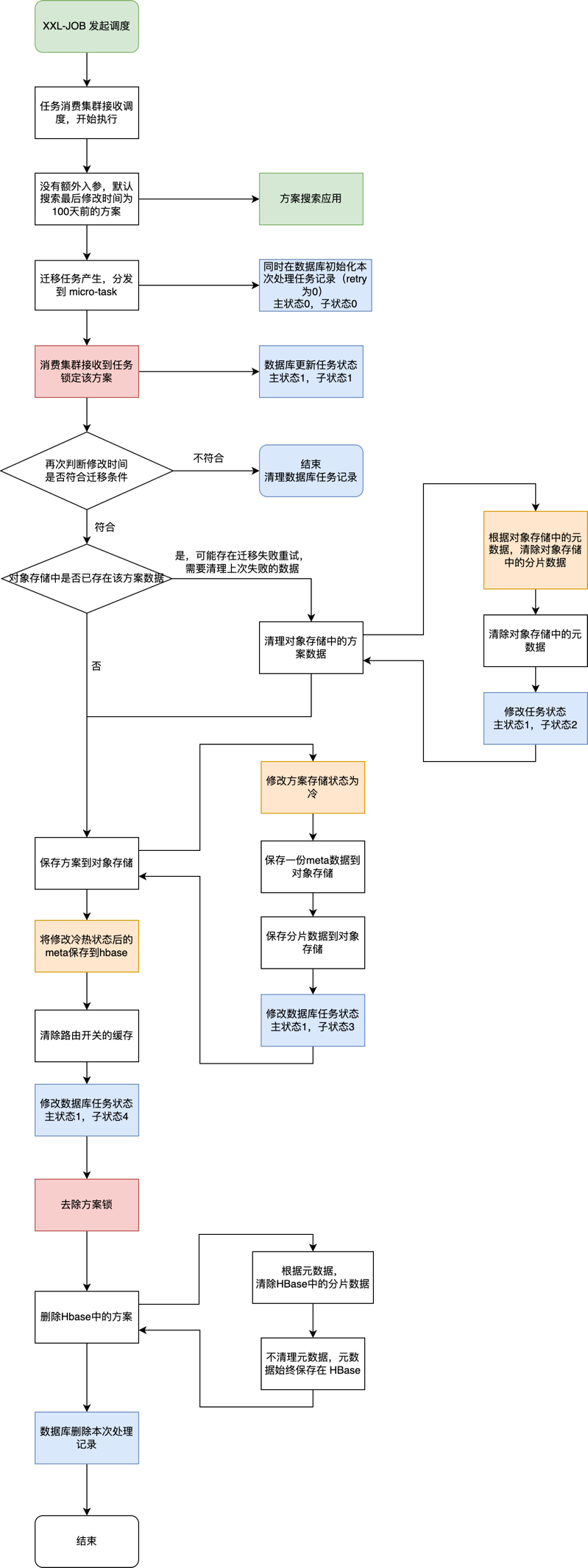
主要分为 5 大流程,分别是:
- 任务预处理,校验方案状态,初始化迁移记录;
- 清理之前可能的失败任务留下的异常数据;
- 查询 HBase 的数据并保存到对象存储中;
- 元数据冷热状态的修改及迁移记录的修改;
- 删除 HBase 中的数据,完成迁移记录;
下面的流程图更加细致的展示了整个过程。其中主状态 0 表示任务初始化未开始,主状态 1 表示任务迁移中,自状态的 1,2,3,4 分别表示了迁移中的各个关键状态。
【失败任务重试的任务】:
考虑到线上可能出现的各种异常状况,对于失败的任务需要重试机制,来减少人工介入。以下重试任务会在当日全部迁移任务完成后触发,用于重试失败的任务。
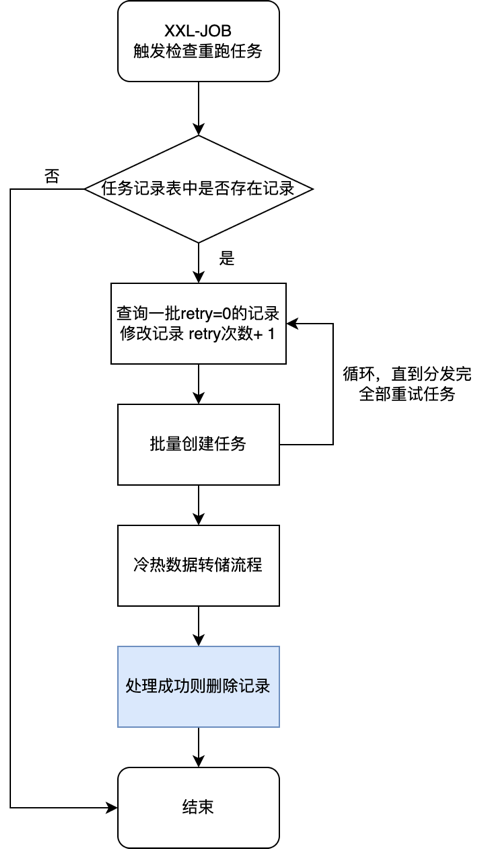
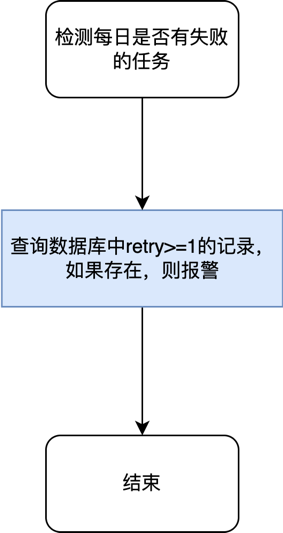
【检查失败任务并报警的任务】:
失败的任务不能无限次的重试,对于重试一次仍然失败的任务,需要提醒研发人员介入处理,人工判断异常原因,并决定忽略该失败任务,还是手动再次触发处理,亦或是修复 bug。
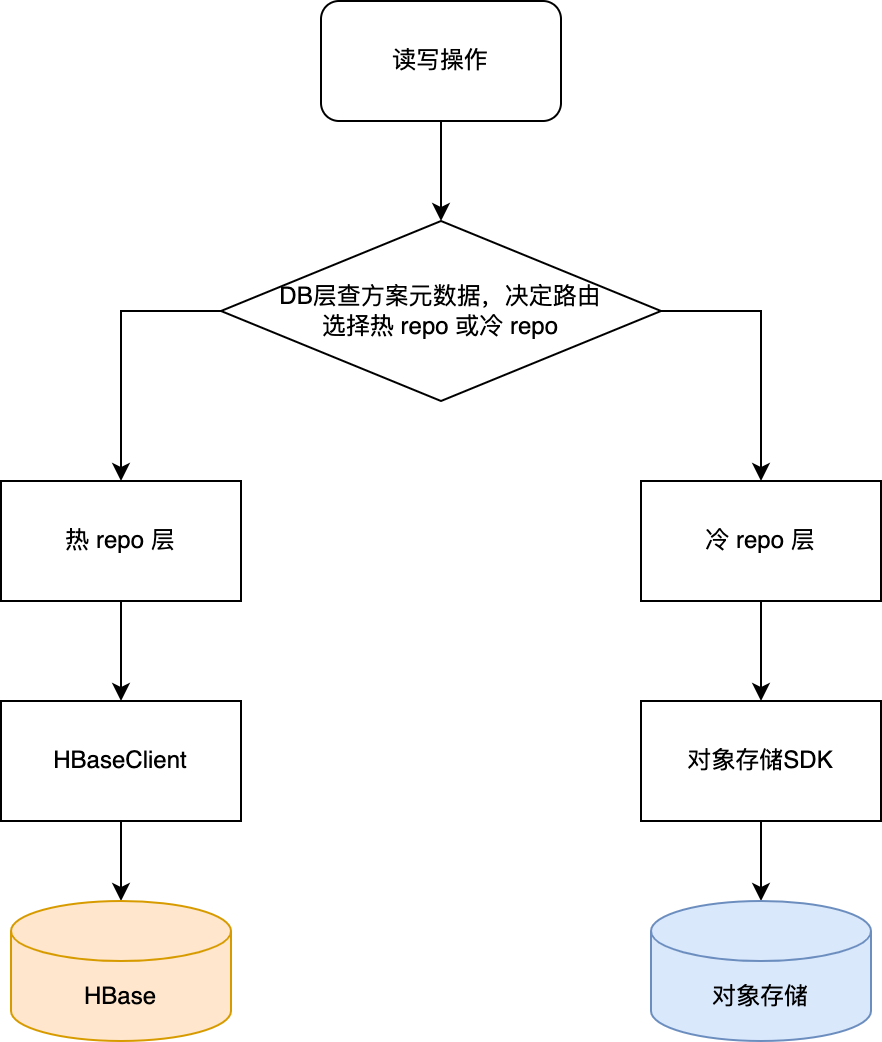
读写逻辑改造
方案应用代码结构原来大致分为 4 层, 从 Controller 层到 Service 层到 DB 层再到 HBaseClient 层。
为了避免对上层逻辑的侵入,使得冷热方案的细节对上层透明,在 DB 层与 HBaseClinet 层中间抽象出一层 Repository 层,用于表示冷热存储的读写逻辑,实现同一套接口(主要包括读、写、删、Exist 及其对应的批量操作),由 DB 层查询冷热路由,并决定调用不同的 Repository 实现,然后由 Repository 层调用更加底层的 HBaseClient 或对象存储 SDK。
大致结构如下:
设计细节分析
如何设计迁移细节才能保证我们定下的原则和目标呢?
下面针对一些问题做重点分析:
- 用户操作与迁移同时发生时,如何保证数据安全与一致性?
场景 1:搜索满足迁移条件的冷方案时,判定某方案为冷方案并分发了迁移任务,此时用户发生了保存操作,然后执行器接收到了任务准备迁移。
解决:需要使用分布式锁,锁级别为单方案,在保存方案分片数据及元数据时,亦或是迁移时,均需要获取锁,保存锁和迁移锁互斥,保存锁可重入。迁移任务开始时,需要锁定方案,锁定后,再次检查方案最后修改时间是否满足时间条件。
场景 2:迁移任务开始后,用户发生方案保存。
解决:同样需要靠锁定方案,用户保存会等待获取锁或超时失败。迁移成功后,用户可保存,此时方案元数据中的冷热路由已切换到冷,分片数据会直接保存对象存储。
场景 3:迁移过程中,发生用户读取方案的操作。
解决:在元数据中增加冷热方案标识,作为读写分片数据的路由,然后决定从 HBase 读还是从 COS 读。迁移过程中,会先把数据保存到对象存储,然后再修改路由开关,最后删除 HBase 中的热数据。如果切换路由开关后才发生数据读取,则直接根据路由去读对象存储;如果读取到一半发生路由切换,用户实际上还在继续读取 HBase,这里需要再删除前等待一小段时间(如 500 毫秒)保证用户读取完剩余数据。
- 是否考虑设计冷数据上浮为热数据
暂不考虑,有如下问题:当前判断冷方案的依据是方案最后修改时间。如果发生读取就将冷数据上浮为热数据,那么该方案再次被认定为冷方案的依据将缺失,该方案永远无法被再次迁移,除非额外使用其他标识作为冷方案判断的依据。
目前看对象存储的读写性能比 HBase 略弱,但是也能基本满足使用需要,如果后期有性能提升需求,再考虑将修改过的冷方案上浮为热方案。
- 如何保证任务成功
当前方案服务还没有引入消息中间件,考虑到已使用的微任务框架,使用 MySQL 来记录迁移任务及中间状态,保证任务一定被消费并正确处理完全部流程。当每日迁移任务完成后,可触发重试子任务,将迁移状态表中异常的迁移任务重试。最后还可以创建定时任务,每日早上检查前一日是否有失败任务,并做人工处理。
- 如何支持重跑
时间维度看,可以对一个时间段内的冷方案反复迁移,因为迁移任务的流程中,会检查方案的冷热标识,以及热方案数据是否存在,不满足条件的,迁移任务会直接结束。
方案维度看,可以重复指定同一方案进行迁移,可重试的理由同上。
单个任务维度看,每次任务开始时,都会检查对象存储中因为上次任务失败而残留的垃圾数据并清理,所以如果在切换路由开关前任意时刻失败,迁移任务可从头开始跑;而如果已切换路由开关到冷存储,那么下次重跑前,可能会发生用户保存,导致最新版的数据落在对象存储上,那此时重跑只能从切换后的流程开始跑。
- 是否考虑做数据的深度压缩
可以考虑,冷方案获取频率较低,在不损失较多解压缩性能的情况下,可以考虑更高压缩比的算法,如 ZSTD。
实践与总结
在写下本文时,该系统已经上线运行了一个多月了,其中经历了灰度阶段、提速阶段、增加处理存量数据功能的阶段。目前每日处理新增冷方案(即 100 天前那天保存后没有再次修改的方案)大致需要花费 2 个小时。然后触发存量冷方案迁移,直到第二天高峰期开始前结束。
上线初期还是碰到了一些问题,如:
- 单个方案任务运行时间较长。由于方案是分片保存的,一个任务需要多次读写 HBase,部分大方案任务耗时较长。
- HBase 压力较大,偶现 HBase fullGC。
- 任务分发慢,处理瓶颈多,分发速度不可控,整体速率只能靠调节机器数量来控制。
- 整个迁移任务在夜间运行时,会经历多个不同的工况,需要能在不同时刻控制不同的运行速率,如:
- 运行初期,线上业务处于次低峰期,需要限速运行。
- 运行中后期,线上业务处于低峰期,可以全速运行。
- 凌晨 0 点到 3 点是 HBase compaction 不限速时段,需要限速避开。
优化方案:
- 把处理流程中的全部 HBase 操作全部改为批量处理,优化后,单任务耗时有所下降,超时任务减少。
- 通过修改 HBase client 参数,使得 HBase 在读操作时,不缓存 BlockCache,降低 HBase fullGC 风险。
- 根据各个系统的指标监控,逐一升级依赖的 Redis、MySQL 等中间件,并适当提高单机 worker 数量配置。
- 根据速率控制的实际需求,通过以下多种手段,形成一套控制任务速率的准闭环控制系统,控制系统框图如下。
- 提高任务分发线程池的线程数,使其不再是分发速度的限制。
- 引入 Guava 包的 RateLimiter,通过分时段速率配置表,控制不同时段的分发速度。
- 引入排队控制机制,读取任务框架的排队数量,当排队数达到一定值时,停止搜索分发任务。
- 配置机器的自动扩缩容,扩容条件包括 CPU 使用率、任务排队数量等。

下图展示了一个典型夜间周期的任务执行情况:
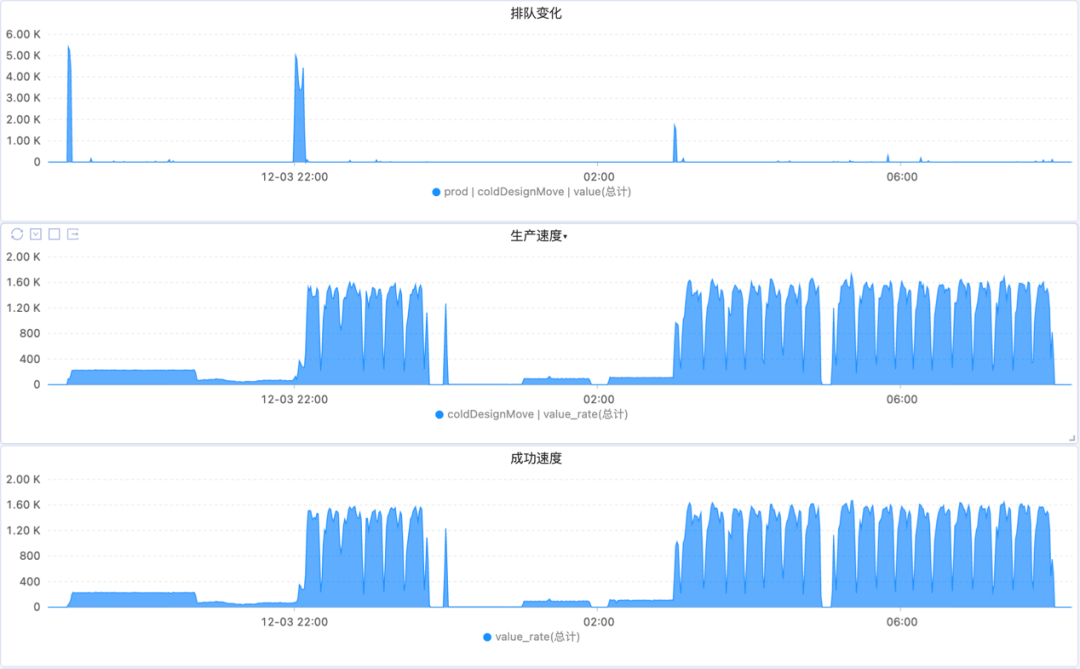
- 19:00, xxl-job 触发任务,执行器只有 1 台,消费速度赶不上生产速度,任务开始堆积,触发 HPA 扩容,随后消费速度赶上生产速度。该阶段是业务次低峰期,用户使用量仍不算太低,限速执行。
- 大约 1 个半小时后,增量方案处理完毕,处理回收站里的增量方案,由于部分方案是无效的,任务生产速度下降。
- 22:00 左右,低峰期限速放开,同时增量方案处理完毕,开始处理存量方案。由于限速放开,生产速度再次提高,产生了一波任务堆积,执行器再次扩容,使得消费速度赶上生产速度。
- 00:00,HBase compaction 开始不限速执行,此时,为了不给 HBase 造成过大压力,任务生产速度再次限速。
- 01:00,任务限速适当提高。
- 03:00,HBase compaction 开始限速,任务分发限速放开,此时任务分发的速度受限于方案搜索的速度和方案查询的速度。
- 08:00,业务低峰期结束,迁移任务停止分发,执行期逐渐缩容回 1 台。
一整晚迁移数据量在 0.3TB~0.4TB 之间。存量冷方案每晚大致处理 20 天的数据量,需要花费 4~5 个月的时间处理完所有的存量冷方案。
最终,HBase 中的热方案数据量会降至一个可控的范围内,预计数据量可降低 30% 以上,且不会随着时间的增长而增长,同时搭建生产集群和热备集群的成本也更加可以接受;大量的冷方案数据被沉淀到对象存储中,对象存储的使用量会随着时间的推移而线性增长。总体来看存储成本将得到较好的控制。
嘉宾介绍:
王小波,酷家乐几何中间件组后端研发工程师,当前主要参与公司参数化模型的能力体系建设,以及负责参数化模型的存储服务等。
活动推荐:
在 3 月 17 日 -18 日,ArchSummit 全球架构师峰会(北京站)即将落地,届时群核科技(酷家乐)的资深专家王栋年讲师也会莅临现场与大家分享《酷家乐多云架构演进和落地》(演讲详情:https://archsummit.infoq.cn/202303/beijing/presentation/5118),欢迎大家到线下交流。
除此之外,来自百度、京东、华为、腾讯、斗鱼、中国信通院等企业与学术界的技术专家,将就数字化业务架构、低代码实践、国产化替代方案、分布式架构等主题展开分享讨论。
目前已上线数字化场景下的业务架构、低代码实践与应用、国产软件优化迭代之路、多数据中心的分布式架构实践、软件质量保障、技术 - 产品 - 业务、高并发架构实现、架构师成长与团队搭建落地实践、大数据和人工智能融合、大规模微服务架构演进、可观测技术落地、云原生大数据实践等多个专题,点击阅读原文去官网查看大会日程。
会期临近,门票即将售罄,购票或咨询其他问题请联系票务同学:15600537884(微信同电话)


