
OCR:使用开源框架Tesseract做文字识别(安装)
Tesseract最初由惠普实验室支持,用于电子版文字识别,1996年被移植到Windows上,1998年进行了C++化,在2005年Tesseract由惠普公司宣布开源。2006年到现在,由Google公司维护开发。
安装

tesseract分为两个版本,tesseract3.0 和 tesseract4.0,建议安装使用最新版本,安装分Ubuntu和mac版本,windows安装直接下载一个压缩包解压即完成安装;
源码安装,可以编译到最新版本tesseract(注意兼容问题),目前tesseract最新版本为 4.1.0--rc4;
1、mac环境安装一些依赖包
brew install automake autoconf
brew install autoconf-archive
brew install pkgconfig
brew install icu4c
brew install leptonica
brew install gcc2、下载tesseract,建议克隆git上的
git clone https://github.com/tesseract-ocr/tesseract.git
cd tesseract
./autogen.sh3、编译
./configure CC=gcc-6 CXX=g++-6 CPPFLAGS=-I/usr/local/opt/icu4c/include LDFLAGS=-L/usr/local/opt/icu4c/lib
./configure CC=gcc-6 CXX=g++-6 CPPFLAGS=-I/usr/local/opt/icu4c/include LDFLAGS=-L/usr/local/opt/icu4c/lib
make -j
sudo make install # if desired
make training注意执行此命令前,键入gcc,然后按多次tab键查看gcc版本或使用brew list gcc查看版本(忽略点后面的数字,即4.6.4为4),然后将数字6替换为本机gcc版本的数组,本机为8.2.0,那么CC=gcc-8 CXX=g++-8,参考点击此处;
完成安装,若未安装成功,需下载插件;
先卸载之前安装
brew uninstall tesseract
然后重新编译;
Ubuntu环境下
建议使用git克隆最新版本,因为本人在测试中发现,版本越新,准确率越高:tesseract 4.0.0-beta.1-262-g555f < tesseract 4.0.0-beta.4-163-ge124 < tesseract 4.0.0-52-ge9866;
1、安装依赖包
sudo apt-get install g++ # or clang++ (presumably)
sudo apt-get install autoconf automake libtool
sudo apt-get install pkg-config
sudo apt-get install libpng-dev
sudo apt-get install libjpeg8-dev
sudo apt-get install libtiff5-dev
sudo apt-get install zlib1g-dev
#如果需要训练模型,则需要额外安装如下库
sudo apt-get install libicu-dev
sudo apt-get install libpango1.0-dev
sudo apt-get install libcairo2-dev
Tesseract与之对应Leptonica最低的版本要求(由于不知道如何设计列表,只能截图了)
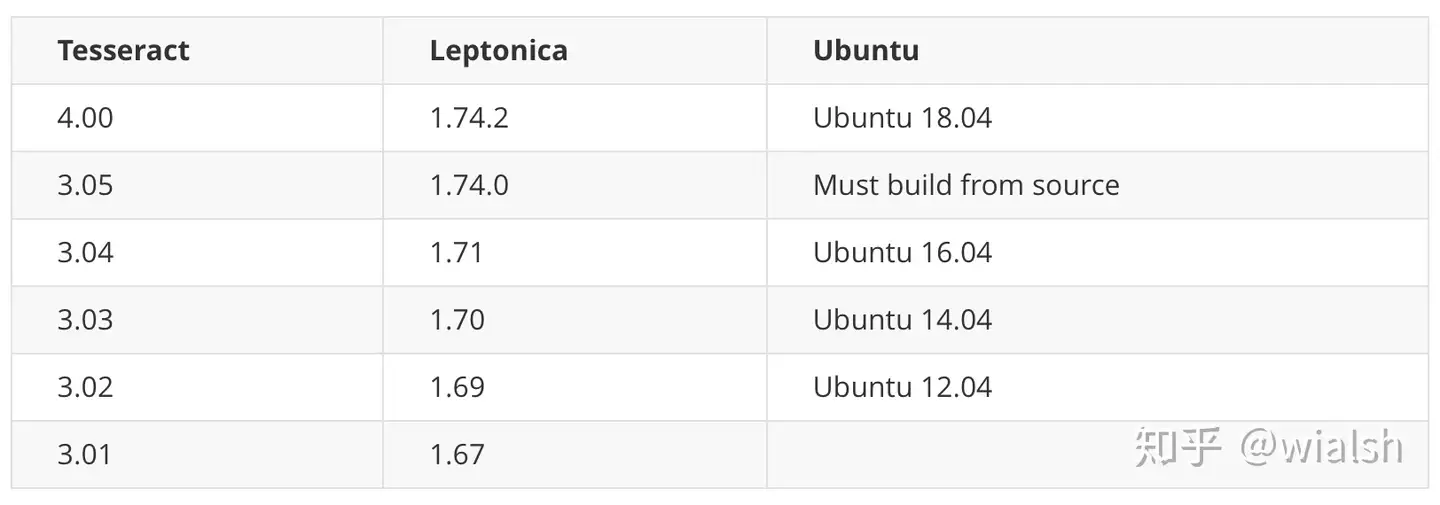
2、安装libleptonica
方法一:编译
若需安装最新的tesseract,建议使用git克隆安装
git clone https://github.com/DanBloomberg/leptonica
cd leptonica/
autoreconf -vi
./configure
make
make install方法二:直接安装(若安装tesseract4.0,可能踩不兼容坑,不建议)
$ sudo apt-get install libleptonica-dev
3、安装tesseract
或直接在 源码 链接中下载(建议,因为可以下载到最新版本)
若当前最新的 tesseract 版本是 4.0.0-RC4
git clone https://github.com/tesseract-ocr/tesseract.git
cd tesseract/
./autogen.sh
./configure --enable-debug #加上参数 –prefix=xxx 来指定安装路径,以后卸载方便,但安装完成需要做额外的配置(本人默认)编译
LDFLAGS="-L/usr/local/lib" CFLAGS="-I/usr/local/include" make
make installldconfig #安装完成,安装目录在/usr/include或/usr/local/include
tessdata目录/usr/share/tesseract-ocr/tessdata或/usr/local/share/tessdata/
查看版本
$ tesseract
Usage:
tesseract --help | --help-extra | --version
tesseract --list-langs
tesseract imagename outputbase [options...] [configfile...]
OCR options:
-l LANG[+LANG] Specify language(s) used for OCR.
NOTE: These options must occur before any configfile.
Single options:
--help Show this help message.
--help-extra Show extra help for advanced users.
--version Show version information.
--list-langs List available languages for tesseract engine.
$ tesseract --version
tesseract 4.0.0-52-ge9866
leptonica-1.77.0
libjpeg 9c : libpng 1.6.36 : libtiff 4.0.10 : zlib 1.2.11 : libwebp 1.0.2 : libopenjp2 2.3.0
Found AVX2
Found AVX
Found SSE
$ tesseract --list-langs
List of available languages (131):
afr
amh
ara
...需存在AVX/SSE,否则返回速度慢,详情请看
https://mail.google.com/mail/#inbox/FMfcgxvzLDzqgnlLcHVJkMLcrdWWvbCR
https://github.com/tesseract-ocr/tesseract/issues/1278
安装训练模型
在3.03版本后,在安装附加库后,可编译训练模型
make
make training
sudo make training-install结束!!!!
OCR例子请点击此处
编译中的一些错误
问题一:
.ibtoolize: error: AC_CONFIG_MACRO_DIRS([m4]) conflicts with ACLOCAL_AMFLAGS=-I m4a. 可能是因为configure.ac和http://Makefile.am文件是dos格式导致的
b. 使用dos2unix转换一下后再执行,问题可能就解决(若在windows使用git,设置不转换文件可避免,参考)
问题二:
bash: ./autogen.sh: /bin/sh^M: bad interpreter: No such file or directory也是因为文件格式问题(如docs格式,在windows下编辑后,上传至linux编译)
解决方法同上,或如下
vim autogen.sh
:set ff #查看文件格式,若是fileformat=dos,则在linux编译中汇出错
:set fileformat=unix #修改文件格式
wq!
