
.NET高性能开发-位图索引(一)
.NET高性能开发-位图索引(一)
首先来假设这样一个业务场景,大家对于飞机票应该不陌生,大家在购买机票时,首先是选择您期望的起抵城市和时间,然后选择舱等(公务舱、经济舱),点击查询以后就会出现航班列表,随意的点击一个航班,可以发现有非常多组价格,因为机票和火车票不一样,它的权益、规则更加的复杂,比如有机票中有针对年龄段的优惠票,有针对学生的专享票,有不同的免托运行李额、餐食、有不同的退改签规则,甚至买机票还能送茅台返现等等。
在中国有几十个航司、几百个机场、几千条航线、几万个航班,每个航班有几十上百种产品类型,这是一天的数据,机票可以提前一年购买,总计应该有数十亿,而且它们在实时的变动,没有任何一种数据库能解决这样量级下高并发进行实时搜索的问题。
业内的解决方案都是加载数据到内存进行计算,但是内存计算也是有挑战的,如何在短短的几十毫秒内处理数十亿数据将搜索结果呈现在客户面前呢?
其中有很多可以聊的地方,今天主要聊大规模实时搜索引擎技术的一个小的优化点;通过这个简单的场景,看如何使用.NET构建内存位图索引优化搜索引擎计算速度。
声明:为简化知识和方便理解,本文场景与解决方案均为虚构,如有雷同纯属巧合。
由于篇幅问题,本系列文章一共分为四篇:
-
介绍什么是位图索引,如何在.NET中构建和使用位图索引
-
位图索引的性能,.NET BCL库源码解析,如何通过SIMD加速位图索引的计算
-
CPU SIMD就走到尽头了吗?下一步方向是什么?
-
构建高效的Bitmap内存索引库并实现可观测性(待定,现在没有那么多时间整理)
什么是位图索引#
要回答这样一个问题,我们首先来假设一个案例,我们将航班规则抽象成下面的record类型,然后有如下这样一些航班的规则数据被加载到了内存中:
/// <summary>
/// 舱等
/// </summary>
public enum CabinClass {
// 头等舱
F,
// 经济舱
Y
}
/// <summary>
/// 航班规则
/// </summary>
/// <param name="Airline">航司</param>
/// <param name="Class">舱等</param>
/// <param name="Origin">起飞机场</param>
/// <param name="Destination">抵达机场</param>
/// <param name="DepartureTime">起飞时间</param>
public record FlightRule(string Airline, CabinClass Class, string Origin, string Destination, string FlightNo, DateTime DepartureTime);
var flightRules = new FlightRule[]
{
new ("A6", CabinClass.F, "PEK", "SHA", "A61234", DateTime.Parse("2023-10-11 08:00:00")),
new ("CA", CabinClass.Y, "SHA", "PEK", "CA1234", DateTime.Parse("2023-10-13 08:00:00")),
new ("CA", CabinClass.Y, "SHA", "PEK", "CA1234", DateTime.Parse("2023-10-14 08:00:00")),
new ("CA", CabinClass.Y, "SHA", "PEK", "CA1234", DateTime.Parse("2023-10-15 08:00:00")),
new ("CA", CabinClass.F, "SHA", "PEK", "CA1234", DateTime.Parse("2023-10-15 08:00:00")),
new ("MU", CabinClass.F, "PEK", "CSX", "MU1234", DateTime.Parse("2023-10-16 08:00:00")),
new ("9C", CabinClass.Y, "PEK", "CSX", "9C1234", DateTime.Parse("2023-10-17 08:00:00")),
};
然后有一个搜索表单record类型,如果说要针对这个record编写一个搜索方法,用于过滤得出搜索结果,相信大家很快就能实现一个代码,比如下方就是使用简单的for循环来实现这一切。
// 搜索方法 condition为搜索条件
FlightRule[] SearchRule(FlightRuleSearchCondition condition)
{
var matchRules = new List<FlightRule>();
foreach (var rule in flightRules)
{
if (rule.Airline == condition.Airline &&
rule.Class == condition.Class &&
rule.Origin == condition.Origin &&
rule.Destination == condition.Destination &&
rule.DepartureTime.Date == condition.DepartureTime.Date)
{
matchRules.Add(rule);
}
}
return matchRules.ToArray();
}
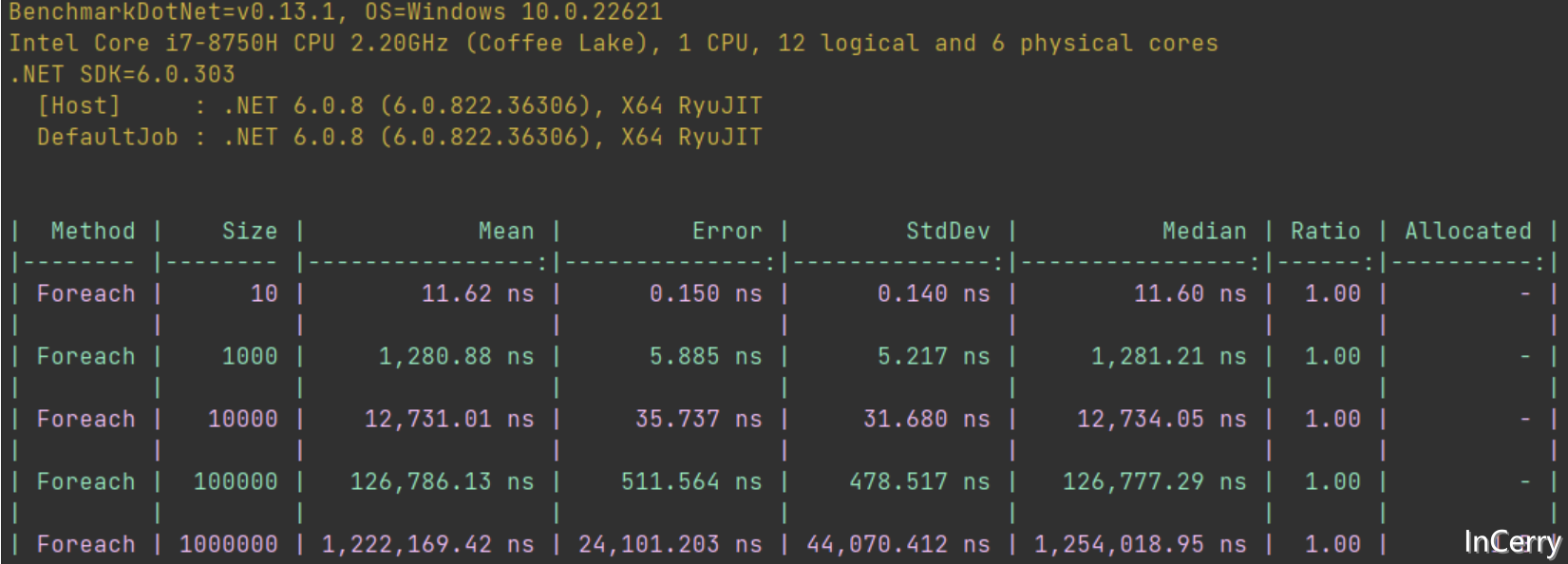
这个解决方案的话再数据量小的时候非常完美,不过它的时间复杂度是O(N),大家可以回忆之前文章如何快速遍历List集合的结论,我们知道就算是空循环,面对动辄十几万、上百万的数据量时,也需要几秒钟的时间。
数据库引擎在面对这个问题的时候,就通过各种各样的索引算法来解决这个问题,比如B+树、哈希、倒排、跳表等等,当然还有我们今天要提到的位图索引。
我们先来看一下位图索引的定义:位图索引是一种数据库索引方式,针对每个可能的列值,建立一个位向量。每个位代表一行,如果该行的列值等于位向量的值,位为1,否则为0。特别适用于处理具有少量可能值的列。听起来比较抽象是嘛?没有关系,我们通过后面的例子大家就能知道它是一个什么了。
构建位图索引#
还是上面提到的航班规则数据,比如第一个Bit数组就是航司为CA的行,那么第0位就代表航班规则数组中的第0个元素,它的航司是CA,所以这个Bit位就为True,赋值为1;同样的,第1位就代表航班规则数据中的第1个元素,它航司不是CA,所以就赋值为0。
new ("A6", CabinClass.F, "PEK", "SHA", "A61234", DateTime.Parse("2023-10-11 08:00:00")),
new ("CA", CabinClass.Y, "SHA", "PEK", "CA1234", DateTime.Parse("2023-10-13 08:00:00")),
new ("CA", CabinClass.Y, "SHA", "PEK", "CA1234", DateTime.Parse("2023-10-14 08:00:00")),
new ("CA", CabinClass.Y, "SHA", "PEK", "CA1234", DateTime.Parse("2023-10-15 08:00:00")),
new ("CA", CabinClass.F, "SHA", "PEK", "CA1234", DateTime.Parse("2023-10-15 08:00:00")),
new ("MU", CabinClass.F, "PEK", "CSX", "MU1234", DateTime.Parse("2023-10-16 08:00:00")),
new ("9C", CabinClass.Y, "PEK", "CSX", "9C1234", DateTime.Parse("2023-10-17 08:00:00")),
| 特征 | 规则0 | 规则1 | 规则2 | 规则3 | 规则4 | 规则5 | 规则6 |
|---|---|---|---|---|---|---|---|
| 航司CA | 0 | 1 | 1 | 1 | 1 | 0 | 0 |
根据这个规则,我们可以根据它的不同维度,构建出好几个不同维度如下几个Bit数组,这些数组组合到一起,就是一个Bitmap。
| 规则序号 | 航司CA | 航司A6 | 航司MU | 航司9C | 经济舱 | 起飞机场PEK | 起飞机场SHA | 起飞机场CSX | 抵达机场PEK | 抵达机场SHA | 抵达机场CSX |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| 3 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| 5 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 6 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
现代CPU的字长都是64bit,它能在一次循环中处理64bit的数据,按照一个不严谨的算法,它比直接for搜索要快64倍(当然这并不是极限,在后面的文章中会解释原因)。
位图索引逻辑运算#
位图索引已经构建出来了,那么如何进行搜索操作呢?
与运算#
比如我们需要查询航司为CA,起飞机机场为SHA到PEK的航班,就可以通过AND运算符,分别对它们进行AND操作。
就能得出如下的Bit数组,而这个Bit数组中为1的位对应的位下标就是符合条件的规则,可以看到下标1~4都是符合条件的规则。
| 规则序号 | 航司CA | 起飞机场SHA | 抵达机场PEK | AND结果 |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 | 1 |
| 2 | 1 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 | 1 |
| 5 | 0 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 | 0 |
或运算#
如果想搜索10月13号和10月15号起飞的航班,那应该怎么做呢?其实也很简单,就是通过OR运算符,先得出在10月13号和10月15号的规则(请注意,在实际项目中对于时间这种高基数的数据不会对每一天创建索引,而是会使用BSI、REBSI等方式创建;或者使用B+ Tree这种更高效的索引算法):
| 规则序号 | 起飞日期10月13日 | 起飞日期10月15日 | OR结果 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 |
| 2 | 0 | 0 | 0 |
| 3 | 0 | 1 | 1 |
| 4 | 0 | 1 | 1 |
| 5 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 |
然后再AND上文中的出的结果数组即可,可以看到只有规则1、3和4符合要求了。
| 规则序号 | 上次运算结果 | OR结果 | 本次结果 |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 1 |
| 2 | 1 | 0 | 0 |
| 3 | 1 | 1 | 1 |
| 4 | 1 | 1 | 1 |
| 5 | 0 | 0 | 0 |
| 6 | 0 | 0 | 0 |
非运算#
那么用户不想坐经济舱应该怎么办?我们这里没有构建非经济舱的Bit数组;解决其实很简单,我们对经济舱进行NOT操作:
| 规则序号 | 经济舱 | NOT结果 |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 1 | 0 |
| 2 | 1 | 0 |
| 3 | 1 | 0 |
| 4 | 0 | 1 |
| 5 | 0 | 1 |
| 6 | 1 | 0 |
然后AND上文中的结果即可,就可以得出符合上面条件,但不是经济舱的航班列表,可以发现仅剩下规则4可以满足需求:
| 规则序号 | 上次运算结果 | NOT结果 | 本次结果 |
|---|---|---|---|
| 0 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 |
| 2 | 0 | 0 | 0 |
| 3 | 1 | 0 | 0 |
| 4 | 1 | 1 | 1 |
| 5 | 0 | 1 | 0 |
| 6 | 0 | 0 | 0 |
代码实现#
请注意,本文中代码为AI生成,仅供演示和参考,不可用于实际生产环境,请使用其它更成熟实现(如:BitArray)。
那么如何实现一个Bitmap索引呢?其实非常的简单,在.NET中已经自带了BitArray类,将多个BitArray使用Dictionary组合在一起就可以实现Bitmap索引。
在这里为了详细的讲述原理,我们不使用官方提供的BitArray,自己实现一个简单的,其实就是一个存放的数组和简单的位运算。
public class MyBitArray
{
private long[] _data;
// 每个long类型有64位
private const int BitsPerLong = 64;
public int Length { get; }
public MyBitArray(int length)
{
Length = length;
// 计算存储所有位需要多少个long
_data = new long[(length + BitsPerLong - 1) / BitsPerLong];
}
public bool this[int index]
{
// 获取指定位的值
get => (_data[index / BitsPerLong] & (1L << (index % BitsPerLong))) != 0;
set
{
// 设置指定位的值
if (value)
_data[index / BitsPerLong] |= (1L << (index % BitsPerLong));
else
_data[index / BitsPerLong] &= ~(1L << (index % BitsPerLong));
}
}
public void And(MyBitArray other, MyBitArray result)
{
// 对两个MyBitArray进行AND操作
for (int i = 0; i < _data.Length; i++)
result._data[i] = _data[i] & other._data[i];
}
public void Or(MyBitArray other, MyBitArray result)
{
// 对两个MyBitArray进行OR操作
for (int i = 0; i < _data.Length; i++)
result._data[i] = _data[i] | other._data[i];
}
public void Xor(MyBitArray other, MyBitArray result)
{
// 对两个MyBitArray进行XOR操作
for (int i = 0; i < _data.Length; i++)
result._data[i] = _data[i] ^ other._data[i];
}
public void Not(MyBitArray result)
{
// 对MyBitArray进行NOT操作
for (int i = 0; i < _data.Length; i++)
result._data[i] =