用图技术搞定附近好友、时空交集等 7 个典型社交网络应用


两个月之前,我的同事拿了一张推特的互动关系图(下图,由 STRRL 授权)来问我能不能搞一篇图技术来探索社交互动关系的文章,看看这些图是如何通过技术实现的。

我想了想,自己玩推特以来也跟随大部队生成了不少的社交关系组图,当中有复杂的社交群体划分:
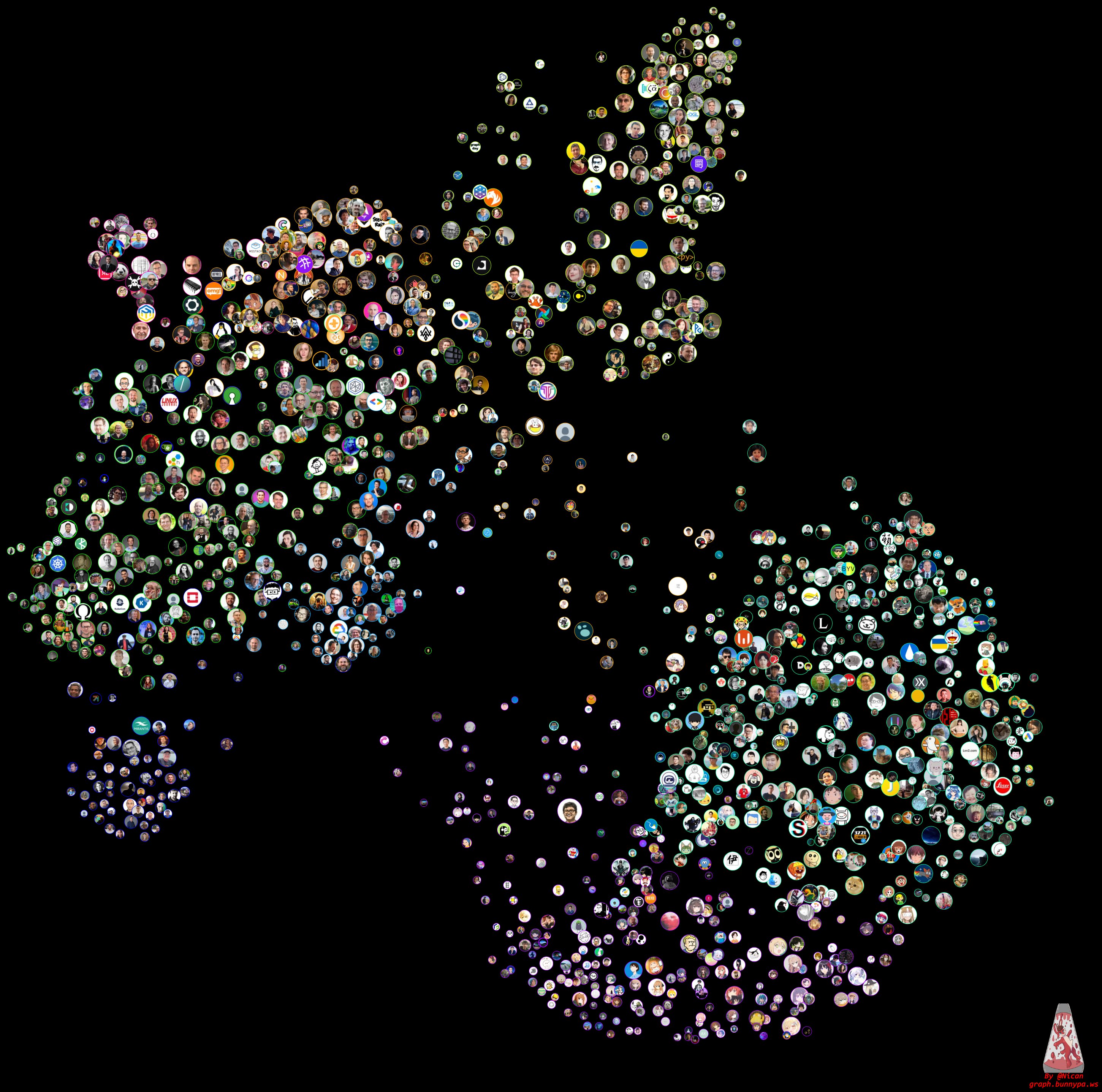
我在技术圈,看在金融、数学圈的大佬在彼岸紧密贴贴。当然也有比较简单的关系图:

看谁和你互动比较多,而他们又和谁关系比较密切。那么问题来了,像上面这种常见的社交关系图,甚至是别的更复杂的基于社交网络的图是如何生成的呢?在本文我将用图数据库 NebulaGraph 来解决社交网络问题,而上面的社交关系组图也被包含在其中。btw,文中介绍的方法提供都了 Playground 供大家学习、玩耍。
简单剖析社交网络的选型
从上面的图我们可以知道,一个典型的社交网络拓扑图便是用户的点和关系的边组成的网状结构。
因此,我们可以用图数据库来表示用户和他们的连接关系,来完成这个社交网络的数据模型。基于图数据库,我们可以对用户间的关系进行查询,让各类基于社交网络连接关系的查找、统计、分析需求变得更便捷、高效。
例如,利用图形数据库来识别网络中的 “有影响力的用户”;根据用户之间的共同点对新的连接(好友关系、感兴趣的信息)进行推荐;更甚者寻找社群中聚集的不同人群、社区,进行用户画像。
以 NebulaGraph 为代表的图数据库不仅能支撑复杂的多跳查询,同时也支持实时写入、更新数据,因此非常适合用来探索用户关系不断变化的社交网络系统。
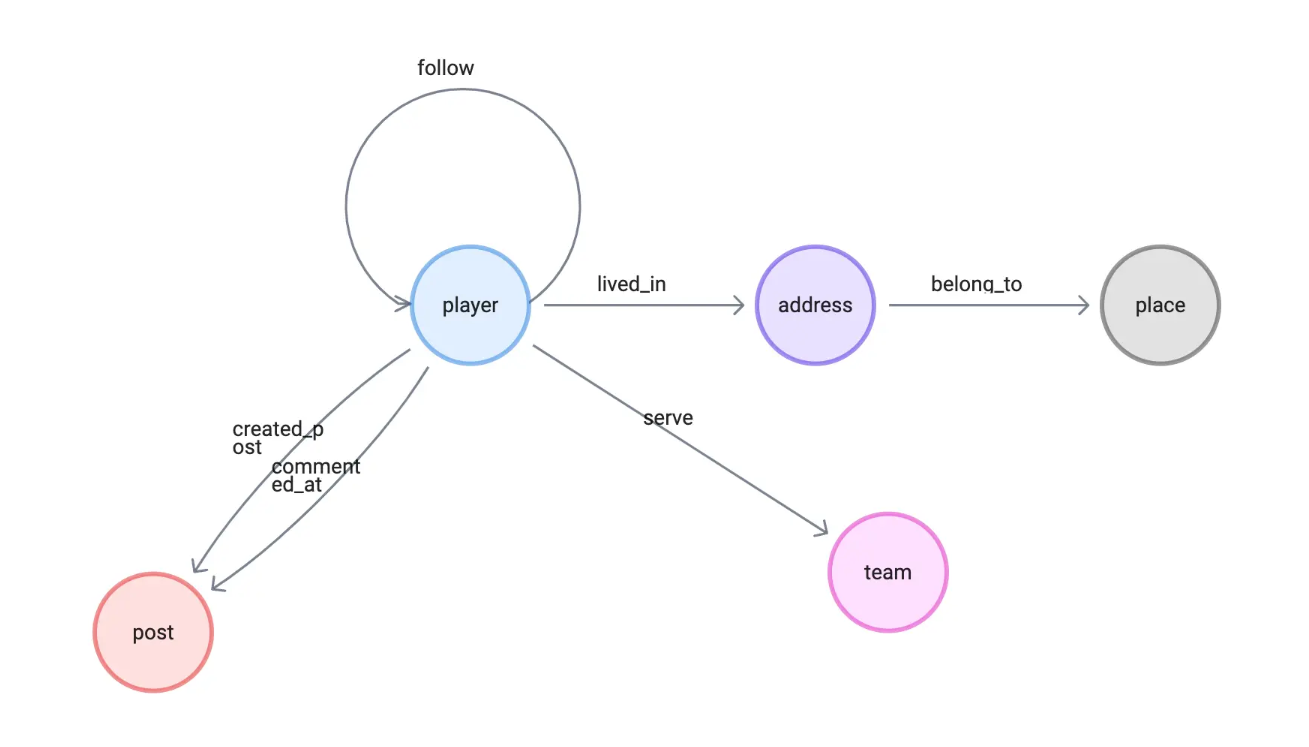
图建模
上文说过社交网络天然就是一种网络、图的结构形态,为了分析常见社交场景的应用示例,本文的例子采用了典型的小型社交网络。因此,我在 NebulaGraph 官方数据集 basketballplayer 之上,增加了:
三种点:
- 地址
- 地点
- 文章
四种边:
- 发文
- 评论
- 住在
- 属于(地点)
它的建模非常自然:
数据导入
导入数据集
首先,我们加载默认的 basketballplayer 数据集,导入对应的 schema 和数据。
如果你使用的是命令行,那你在 console 之中执行 :play basketballplayer 就可以导入数据。如果你使用了可视化图探索工具 NebulaGraph Studio / NebulaGraph Explorer,我们需要在欢迎页点击下载、部署这份基础数据集。
创建社交网络 schema
通过下面语句创建新加入的点、边类型 schema:
CREATE TAG IF NOT EXISTS post(title string NOT NULL);
CREATE EDGE created_post(post_time timestamp);
CREATE EDGE commented_at(post_time timestamp);
CREATE TAG address(address string NOT NULL, `geo_point` geography(point));
CREATE TAG place(name string NOT NULL, `geo_point` geography(point));
CREATE EDGE belong_to();
CREATE EDGE lived_in();
写入新数据
在等待两个心跳(20 秒)以上时间之后,我们可以执行数据插入:
INSERT VERTEX post(title) values \
"post1":("a beautify flower"), "post2":("my first bike"), "post3":("I can swim"), \
"post4":("I love you, Dad"), "post5":("I hate coriander"), "post6":("my best friend, tom"), \
"post7":("my best friend, jerry"), "post8":("Frank, the cat"), "post9":("sushi rocks"), \
"post10":("I love you, Mom"), "post11":("Let's have a party!");
INSERT EDGE created_post(post_time) values \
"player100"->"post1":(timestamp("2019-01-01 00:30:06")), \
"player111"->"post2":(timestamp("2016-11-23 10:04:50")), \
"player101"->"post3":(timestamp("2019-11-11 10:44:06")), \
"player103"->"post4":(timestamp("2014-12-01 20:45:11")), \
"player102"->"post5":(timestamp("2015-03-01 00:30:06")), \
"player104"->"post6":(timestamp("2017-09-21 23:30:06")), \
"player125"->"post7":(timestamp("2018-01-01 00:44:23")), \
"player106"->"post8":(timestamp("2019-01-01 00:30:06")), \
"player117"->"post9":(timestamp("2022-01-01 22:23:30")), \
"player108"->"post10":(timestamp("2011-01-01 10:00:30")), \
"player100"->"post11":(timestamp("2021-11-01 11:10:30"));
INSERT EDGE commented_at(post_time) values \
"player105"->"post1":(timestamp("2019-01-02 00:30:06")), \
"player109"->"post1":(timestamp("2016-11-24 10:04:50")), \
"player113"->"post3":(timestamp("2019-11-13 10:44:06")), \
"player101"->"post4":(timestamp("2014-12-04 20:45:11")), \
"player102"->"post1":(timestamp("2015-03-03 00:30:06")), \
"player103"->"post1":(timestamp("2017-09-23 23:30:06")), \
"player102"->"post7":(timestamp("2018-01-04 00:44:23")), \
"player101"->"post8":(timestamp("2019-01-04 00:30:06")), \
"player106"->"post9":(timestamp("2022-01-02 22:23:30")), \
"player105"->"post10":(timestamp("2011-01-11 10:00:30")), \
"player130"->"post1":(timestamp("2019-01-02 00:30:06")), \
"player131"->"post2":(timestamp("2016-11-24 10:04:50")), \
"player131"->"post3":(timestamp("2019-11-13 10:44:06")), \
"player133"->"post4":(timestamp("2014-12-04 20:45:11")), \
"player132"->"post5":(timestamp("2015-03-03 00:30:06")), \
"player134"->"post6":(timestamp("2017-09-23 23:30:06")), \
"player135"->"post7":(timestamp("2018-01-04 00:44:23")), \
"player136"->"post8":(timestamp("2019-01-04 00:30:06")), \
"player137"->"post9":(timestamp("2022-01-02 22:23:30")), \
"player138"->"post10":(timestamp("2011-01-11 10:00:30")), \
"player141"->"post1":(timestamp("2019-01-03 00:30:06")), \
"player142"->"post2":(timestamp("2016-11-25 10:04:50")), \
"player143"->"post3":(timestamp("2019-11-14 10:44:06")), \
"player144"->"post4":(timestamp("2014-12-05 20:45:11")), \
"player145"->"post5":(timestamp("2015-03-04 00:30:06")), \
"player146"->"post6":(timestamp("2017-09-24 23:30:06")), \
"player147"->"post7":(timestamp("2018-01-05 00:44:23")), \
"player148"->"post8":(timestamp("2019-01-05 00:30:06")), \
"player139"->"post9":(timestamp("2022-01-03 22:23:30")), \
"player140"->"post10":(timestamp("2011-01-12 10:01:30")), \
"player141"->"post1":(timestamp("2019-01-04 00:34:06")), \
"player102"->"post2":(timestamp("2016-11-26 10:06:50")), \
"player103"->"post3":(timestamp("2019-11-15 10:45:06")), \
"player104"->"post4":(timestamp("2014-12-06 20:47:11")), \
"player105"->"post5":(timestamp("2015-03-05 00:32:06")), \
"player106"->"post6":(timestamp("2017-09-25 23:31:06")), \
"player107"->"post7":(timestamp("2018-01-06 00:46:23")), \
"player118"->"post8":(timestamp("2019-01-06 00:35:06")), \
"player119"->"post9":(timestamp("2022-01-04 22:26:30")), \
"player110"->"post10":(timestamp("2011-01-15 10:00:30")), \
"player111"->"post1":(timestamp("2019-01-06 00:30:06")), \
"player104"->"post11":(timestamp("2022-01-15 10:00:30")), \
"player125"->"post11":(timestamp("2022-02-15 10:00:30")), \
"player113"->"post11":(timestamp("2022-03-15 10:00:30")), \
"player102"->"post11":(timestamp("2022-04-15 10:00:30")), \
"player108"->"post11":(timestamp("2022-05-15 10:00:30"));
INSERT VERTEX `address` (`address`, `geo_point`) VALUES \
"addr_0":("Brittany Forge Apt. 718 East Eric WV 97881", ST_Point(1,2)),\
"addr_1":("Richard Curve Kingstad AZ 05660", ST_Point(3,4)),\
"addr_2":("Schmidt Key Lake Charles AL 36174", ST_Point(13.13,-87.65)),\
"addr_3":("5 Joanna Key Suite 704 Frankshire OK 03035", ST_Point(5,6)),\
"addr_4":("1 Payne Circle Mitchellfort LA 73053", ST_Point(7,8)),\
"addr_5":("2 Klein Mission New Annetteton HI 05775", ST_Point(9,10)),\
"addr_6":("1 Vanessa Stravenue Suite 184 Baileyville NY 46381", ST_Point(11,12)),\
"addr_7":("John Garden Port John LA 54602", ST_Point(13,14)),\
"addr_8":("11 Webb Groves Tiffanyside MN 14566", ST_Point(15,16)),\
"addr_9":("70 Robinson Locks Suite 113 East Veronica ND 87845", ST_Point(17,18)),\
"addr_10":("24 Mcknight Port Apt. 028 Sarahborough MD 38195", ST_Point(19,20)),\
"addr_11":("0337 Mason Corner Apt. 900 Toddmouth FL 61464", ST_Point(21,