
如何实现大文件上传、断点续传、切片上传
背景
文件上传是个非常普遍的场景,特别是在一些资源管理相关的业务中(比如网盘)。在文件比较大的时候,普通的上传方式可能会遇到以下四个问题。
- 文件上传超时:原因是前端请求框架认限制最大请求时长,或者是 nginx(或其它代理/网关) 限制了最大请求时长。
- 文件大小超限:原因在于后端对单个请求大小做了限制,一般 nginx 和 server 都会做这个限制。
- 上传耗时久。
- 由于各种网络原因上传失败,且失败之后需要从头开始。
对于前两点,虽说可以通过一定的配置来解决,但有时候也不会那么顺利,毕竟调大这些参数会对后台造成一定的压力,需要兼顾实际场景。只是上传慢的话忍一忍是可以接受的,但是失败后重头开始,在网络环境差的时候简直就是灾难。
思路
针对遇到的这些问题,有比较成熟的解决方案。该方案可以简答的概括为切片上传 + 秒传。
切片上传是指将一个大文件切割为若干个小文件,分为多个请求依次上传,后台再将文件碎片拼接为一个完整的文件,即使某个碎片上传失败,也不会影响其它文件碎片,只需要重新上传失败的部分就可以了。而且多个请求一起发送文件,提高了传输速度的上限。
秒传指的是文件在传输之前计算其内容的散列值,也就是 Hash 值,将该值传到后台,如果后台存在 Hash 值一致的文件,认为该文件上传完成。
该方案很巧妙的解决了上述提出的一系列问题,也是目前资源管理类系统的通用解决方案。
本文会梳理大文件上传中的一些知识点,并根据上述方案,实现一个切片上传 + 秒传的前后端,前端我用 react 实现,后台用的 java。相关代码我放在github上。
最终实现的效果如下: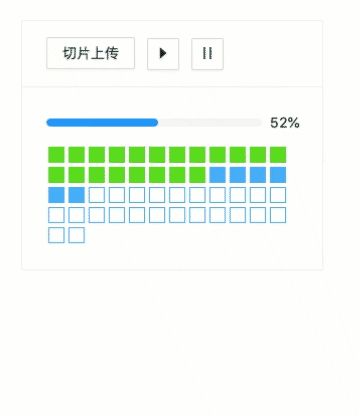
文件上传原理
最开始 XMLHttpRequest 是不支持传输二进制文件的。文件只能使用表单的方式上传,我们需要写一个 Form,然后将 enctype 设置为 multipart/form-data。此时的 Content-Type 为 multipart/form-data,并且会自动跟一个 boundary 字符串,该字符串用于隔离不同的字段。
POST /file/uploadSingle HTTP/1.1 Host: localhost:8080 Connection: keep-alive Content-Length: 9253791 Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryZ6BFzaoozLLGdTBE
所以 multipart/form-data 既可以上传文件,也可以上传键值对,每个元素由 boundary 分隔放在请求的 body 中。
------WebKitFormBoundaryZ6BFzaoozLLGdTBE Content-Disposition: form-data; name="file"; filename="BCompare.zip" Content-Type: application/zip ------WebKitFormBoundaryZ6BFzaoozLLGdTBE--
后来 XMLHttpRequest 升级为 Level 2 之后,新增了 FormData 对象,用于模拟表单数据,并且支持发送和接收二进制数据。我们目前使用的文件上传基本都是基于 XMLHttpRequest Level 2。使用 XMLHttpRequest 后文件上传的报文和上述的一致。写法如下。
let xhr = new XMLHttpRequest(); xhr.upload.onprogress = onProgress; xhr.onload = () => {}; xhr.onabort = () => {}; xhr.onerror = err => {}; xhr.open(method, url, true); xhr.send(data);
需要注意的是,xhr.send(data)中 data 参数的数据类型会影响请求头部 content-type 的值。我们上传文件,data 的类型是 FormData,此时 content-type 默认值为 multipart/form-data; boundary=[xxx]。当然,但如果用 xhr.setRequestHeader() 手动设置了中 content-type 的值,以用户设定的为准。因此,在上传文件场景下,不必设置 content-type 的值,浏览器会根据文件类型自动配置。
文件切片
文件切片和核心是使用 Blob 对象的 slice 方法。
我们使用 的方式获得一个 File 对象。File 继承于 Blob。所以我们也可以使用 slice 方法对文件进行切割。Blob 对象的 slice 方法会返回一个新的 Blob 对象,包含了源 Blob 对象中制定范围内的数据。
var blob = instanceOfBlob.slice([start [, end [, contentType]]]};
start 和 end 代表 Blob 里的下标,表示被拷贝进新的 Blob 的字节的起始位置和结束位置。contentType 会给新的 Blob 赋予一个新的文档类型,很少使用。
在分片上传场景中,我们一般会规定一个切边大小,根据这个大小对文件进行分割。除了这种固定大小的方案外,还有的文章中会根据当前的网络情况动态的调整切片的大小,类似于 TCP 的拥塞控制。本文为了简单,实用固定大小的切片。代码如下。我定义了 FileChunk 对象,这个对象中除了包含切片本身外,还额外存放了一些数据,比如切边在源文件中的起止位置,这么做是为了方便后台拿到切片数据后做文件合并的。
const CHUNK_SIZE = 10 * 1024 * 1024; // 生成文件切片 function createFileChunk(file, blockSize = CHUNK_SIZE) { const fileChunkList = []; const { name, size } = file; let cur = 0; while (cur < size) { let end = cur + blockSize; if (end > size) { end = size; } // 调用 slice 方法进行文件切割 fileChunkList.push( new FileChunk(file.slice(cur, end), name, cur, end, size), ); cur += blockSize; } ... return fileChunkList; } class FileChunk { constructor(chunk, fileName, start, end, total) { // 切片对象 this.chunk = chunk; // 文件名称 this.fileName = fileName; // 切片起始位置 this.start = start; // 切片结束位置 this.end = end; // 文件总大小 this.total = total; // 切片名称 this.chunkName = ''; // 整体文件Hash this.fileHash = ''; // 索引 this.index = 0; // 文件切片总数 this.chunkNum = 0; // 文件状态 'READY', 'UPLOADING', 'SUCCESS', 'ERROR' this.status = 'READY'; } }
文件合并文件合并方案有这么几种。
- 前端发送切片完成后,发送一个合并请求,后端收到请求后,将之前上传的切片文件合并。
- 后台记录切片文件上传数据,当后台检测到切片上传完成后,自动完成合并。
- 创建一个和源文件大小相同的文件,根据切片文件的起止位置直接将切片写入对应位置。
这三种方案中,前两种都是比较通用的方案,且都是可行的,方案一的代价在于多发了一次请求,极小的概率会出现文件上传成功,但是合并请求发送失败的情况,好处就是流程比较清晰。方案二比方案一少了一次请求,代价是每次上传结束后需要判断当前切片是否是最后一个切片,需要在数据库中维护切片的状态。
方案三比较好的,相当于直接省略了文件合并的步骤,速度比较快。但是不用语言的实现难度不同。如果没有合适的 API 的话,自己实现的难度很大。由于我后台是用 java 编写的。我们可以充分利用 java 中的 RandomAccessFile 这个类。
RandomAccessFile 既可以读取文件内容,也可以向文件输出数据。它最大的特点就是支持 “随机访问” 的方式,程序快可以直接跳转到文件的任意地方来读写数据。在切片上传场景下,由于请求是并行发送的,后台会一次性收到大量的切片文件。每个切片文件都携带了当前切片在总文件中的位置信息,我们使用 RandomAccessFile 的 seek 方法定位到切片的起始位置,然后将切片从这个位置开始写入。这也是 RandomAccessFile 的一个重要使用场景。
* 上传切片文件 * @param chunk 切片文件 * @param fileChunk 切片文件的信息 * @return true | false */ @PostMapping("/uploadChunk") @ResponseBody public Boolean upload(@RequestParam("chunk") MultipartFile chunk, FileChunk fileChunk) throws IOException { String fullPath = filePath + fileChunk.getFileName(); // 模块写入对应的位置 try(RandomAccessFile rf = new RandomAccessFile(fullPath, "rw")) { rf.seek(fileChunk.getStart()); rf.write(chunk.getBytes()); } catch (Exception e) { LOGGER.error(e.getMessage()); return false; } ... return true; }
显示进度
旧版的 XMLHttpRequest 是不支持显示进度的,升级为 Level 2 之后,有一个 progress 事件,用来返回进度信息。这也是为什么该场景下推荐使用 xhr ,而不使用 fetch 的原因。fetch 不提供相关的接口,我们无法获得文件的上传进度。
我们可以通过 onprogress 事件来实时显示进度,默认情况下这个事件每 50ms 触发一次。需要注意的是,上传过程和下载过程触发的是不同对象的 onprogress 事件:上传触发的是 xhr.upload 对象的 onprogress 事件,下载触发的是 xhr对象的 onprogress 事件。
xhr.onprogress = updateProgress;
xhr.upload.onprogress = updateProgress;
这个事件有一些属性。event.total 是需要传输的总字节,event.loaded 是已经传输的字节
function updateProgress(event) { if (event.lengthComputable) { var completedPercent = event.loaded / event.total; } }
由于在切片上传场景下,我们获得的是单个切片的上传进度,所以一般需要将单个的进度进行累加,用于计算总的进度,具体代码就不贴了。当然,我们也可以兼顾两种方式。我在大圣老师的文章中找到一种很好的显示进度的方式。将每个切片算作是一个小方块,通过颜色表示进度,非常直观。
断点续传
切片上传有一个很好的特性就是上传过程可以中断,不论是人为的暂停还是由于网络环境导致的链接的中断,都只会影响到当前的切片,而不会导致整体文件的失败,下次开始上传的时候可以从失败的切片继续上传。
我们为当前的上传操作增加一个停止按钮,用于模拟网络错误导致的上传失败。一个请求能被取消的前提是,我们需要将未收到响应的请求保存在一个列表中,然后依次调用每个 xhr 对象的 abort 方法。调用这个方法后,xhr 对象会停止触发事件,将请求的 status 置为 0,并且无法访问任何与响应有关的属性。
// 取消上传操作 pause = () => { this.requestList.forEach(xhr => xhr?.abort()); this.requestList = []; };
从后端的角度看,一个上传请求被取消,意味着当前浏览器不会再向后端传输数据流,后端此时会报错,如下,错误信息也很清楚,就是文件还没到末尾就被客户端中断。当前文件切片写入失败。
java.io.EOFException: Unexpected EOF read on the socket
接下来就是如何实现断点续传,关键点是后端需要记录文件文件切片的信息。用户在上传一个文件之前,先询问服务器,当前文件是否存在已经上传完毕的切片,如果存在的话,需要返回切片信息。前端根据返回的信息,调整当前的进度,上传未完成的切片。
具体的做法是,切片上传完成后,后端记录当前切片的详细信息。
@PostMapping("/uploadChunk") @ResponseBody public Boolean upload(@RequestParam("chunk") MultipartFile chunk, FileChunk fileChunk) { String fullPath = filePath + fileChunk.getFileName(); // 存储文件 ... // chunk 记录到数据库 uploadService.addChunk(fileChunk); ... }
前端在文件上传之前,多加一个步骤,那就是从后端获得已经存在的切片文件。这里我们先用文件名来查询,这只是临时方案,文件名并不能作为文件的唯一标志,后续我们会改为使用文件 Hash 的方式来查询。
upload = file => { // 1. 文件切片 const chunkList = createFileChunk(file); // 2. 判断后端是或已经存在该文件 this.getExistFileChunk(file.name).then(res => { // 标记已经完成上传的 this.chunkList.forEach(chunk => { uploadedChunkList.forEach(uploadedChunk => { if (uploadedChunk.chunkName === chunk.chunkName) { this.markAsSuccess(chunk); } }); }); // 上传切片 this.uploadChunks(chunkList); } }); return this; };
如果存在已经上传好的切片,将这些切片的状态更新为成功,修改进度为 100,后续发送请求的时候会过滤掉状态为成功的切片。
// 标记为上传完成 markAsSuccess = fileChunk => { fileChunk.status = 'SUCCESS'; const chunkSize = fileChunk.chunk.size; fileChunk.progress = { percentage: 100, loaded: chunkSize, total: chunkSize, }; };
如此,就完成了一个文件的断点续传工作,演示如下。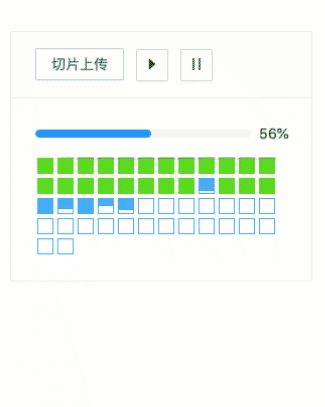
限制请求个数
我在尝试将一个 5G 大小的文件上传的时候,发现前端浏览器出现卡死现象,原因是切片文件过多,浏览器一次性创建了太多了 xhr 请求。这是没有必要的,拿 chrome 浏览器来说,默认的并发数量只有 6,过多的请求并不会提升上传速度,反而是给浏览器带来了巨大的负担。因此,我们有必要限制前端请求个数。
思路比较简单,先创建最大并发数的请求,然后在请求的回调函数中再次创建请求,直到全部请求都发出为止。
const MAX_REQUEST_NUM = 4; // 限制请求并发数 requestWithLimit = ( fileChunkList, max = MAX_REQUEST_NUM, ) => { return new Promise((resolve, reject) => { // 切片数量 const requestNum = fileChunkList.filter(fileChunk => { return fileChunk.status === 'READY'; }).length; // 发送成功数量 let counter = 0; const request = () => { // max 限制了最大并发数 while (counter < requestNum && max > 0) { max--; // 等待发送的切片 const fileChunk = fileChunkList.find(chunk => { return chunk.status === 'READY'; }); const formData = fileChunk.toFormData(); fileChunk.status = 'UPLOADING'; ajax4Upload({ method: 'POST', url: this.uploadUrl, data: formData }) .then(() => { fileChunk.status = 'SUCCESS'; // 释放通道 max++; counter++; if (counter === requestNum) { resolve(); } else { request(); } }) .catch(e => { reject(e); }); } }; request(); }); };
并发重试
切片上传的过程中,我们有可能因为各种原因导致某个切片上传失败,比如网络抖动、后端文件进程占用等等。对于这种情况,最好的方案就是为切片上传增加一个失败重试机制。由于切片不大,重试的代价很小,我们设定一个最大重试次数,如果在次数内依然没有上传成功,认为上传失败。
具体的做法就是改造 requestWithLimit 方法。
定义一个 retryArr 数组,用于记录文件上传失败的次数。改造 catch 方法,一个文件切片上传报错时候,先判断 retryArr 中给切片的错误次数是否达到最大值,如果没有的话,清空当前切片上传进度,重新请求。相应的,我们之前只上传处于 READY 状态的切片,现在要稍微调整下,处于 ERROR 状态的切片也获得上传资格。
const MAX_RETRY_NUM = 3; requestWithLimit = ( fileChunkList, max = MAX_REQUEST_NUM, retry = MAX_RETRY_NUM, ) => { return new Promise((resolve, reject) => { ... // 记录文件上传失败的次数 const retryArr = []; const request = () => { while (counter < requestNum && max > 0) { max--; // READY 或者 ERROR const fileChunk = fileChunkList.find(chunk => { return chunk.status === 'ERROR' || chunk.status === 'READY'; }); ... ajax4Upload({ method: 'POST', url: this.uploadUrl, data: formData, onProgress: this.onProgressHandler.bind(this, fileChunk), requestList: this.requestList, }) .then(() => { ... }) .catch(e => { fileChunk.status = 'ERROR'; // 触发重试机制 if (typeof retryArr[fileChunk.index] !== 'number') { retryArr[fileChunk.index] = 0; } // 次数累加 retryArr[fileChunk.index]++; // 一个请求报错超过最大重试次数 if (retryArr[fileChunk.index] >= retry) { return reject(); } // 清空进度条 fileChunk.progress = {}; // 释放当前占用的通道,但是counter不累加 max++; request(); }); } }; request(); }); };
后台坐下设置,每个切片第一次上传一定失败,会触发重传机制,如下所示。每个切片都会上传两次,发现进度显示的有点魔性,抽空优化吧。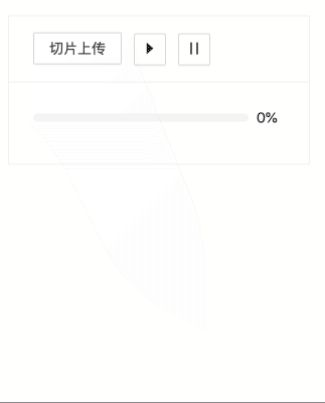
秒传
秒传指的是文件如果在后台已经存了一份,就没必要再次上传了,直接返回上传成功。在体量比较大的应用场景下,秒传是个必要的功能,既能提高用户上传体验,又能节约自己的硬盘资源。
秒传的关键在于计算文件的唯一性标识。
文件的不同不是命名的差异,而是内容的差异,所以我们将整个文件的二进制码作为入参,计算 Hash 值,将其作为文件的唯一性标识。一般而言,这样做就够了,但是摘要算法是存在碰撞概率的,我们如果想要再严谨点的话,可以将文件大小也作为衡量指标,只有文件摘要和文件大小同时相等,才认为是相同的文件。
文件 Hash 值的计算是 CPU 密集型任务,线程在计算 Hash 值的过程中,页面处于假死状态。所以,该任务一定不能在当前线程进行,我们使用 Web Worker 执行计算任务。
Web Worker 是 HTML5 标准的一部分,它允许一段 JavaScript 程序运行在主线程之外的另外一个线程中。这样计算任务就不会影响到当前线程的渲染任务。
目前网上有很多 Web Worker 使用方案,我使用的前端框架是 umi,直接配置下就好了。
export default defineConfig({ workerLoader: { worker: 'Worker', esModule: true, }, });
Web Worker 是一段单独的 JS 程序,它和当前线程间使用 postMessage 的方式进行通讯。
import Worker from './hash.worker.js'; // 生成文件 hash(web-worker) function calculateFileHash(fileChunkList) { return new Promise(resolve => { const worker = new Worker(); worker.postMessage({ fileChunkList, type: 'HASH' }); worker.onmessage = e => { const { hash } = e.data; if (hash) { resolve(hash); } }; }); }
如何快速计算文件的 md5 值呢? 我们使用 js-spark-md5 这个库
js-spark-md5 是号称全宇宙最快的前端类包。我在本机测下来,计算 1G 文件大概 15 秒,确实很快。由于是在 Web Worker 中计算,需要将 spark-md5.min.js 放到静态资源目录下,方便引用。
self.importScripts('spark-md5.min.js'); // 导入脚本 // 全量 Hash postHashMsg = fileChunkList => { const spark = new self.SparkMD5.ArrayBuffer(); let count = 0; const loadNext = index => { const reader = new FileReader(); reader.readAsArrayBuffer(fileChunkList[index].chunk); reader.onload = e => { count++; spark.append(e.target.result); if (count === fileChunkList.length) { self.postMessage({ hash: spark.end(), }); self.close(); } else { // 递归计算下一个切片 loadNext(count); } }; }; loadNext(0); }; self.onmessage = e => { const { fileChunkList, type } = e.data; if (type === 'HASH') { postHashMsg(fileChunkList); } };
此时前端上传文件的流程是这样的。
- 文件切片。
- 计算全量 Hash。
- 判断文件是否符合秒传条件,如果不满足,判断是否满足断点续传条件。
- 文件上传。
后端也做下调整,上传文件的接口,需要在文件全部上传完毕后,记录下文件的详细信息,包括 md5 值,作为后续文件秒传的依据。
/** * 上传切片文件 * @param chunk 切片文件 * @param fileChunk 切片文件的源数据 * @return true | false */ @PostMapping("/uploadChunk") @ResponseBody public Boolean upload(@RequestParam("chunk") MultipartFile chunk, FileChunk fileChunk) { ... // 文件全部上传完成 Integer chunkSize = uploadService.getChunkNumByContentHash(fileChunk.getFileHash()); if (chunkSize.equals(fileChunk.getChunkNum())) { // 删除 chunk 记录 uploadService.removeChunkRecord(fileChunk.getFileHash()); // 增加 file 记录 FileModel fileModel = new FileModel(fileChunk.getFileName(), fileChunk.getFullPath(), fileChunk.getFileHash(), fileChunk.getTotal(), "SUCCESS"); uploadService.addFile(fileModel); } }
判断秒传和断点续传的代码可以合并为一个接口,作为文件上传的前置接口。
秒传功能由于需要计算 Hash 值,会导致整体上传速度变慢,但是和大文件上传需要的耗时以及消耗的流量比起来,是一种性价比很高的选择。
如果觉得文件计算全量 Hash 比较慢的话,还有一种方式就是计算抽样 Hash,减少计算的字节数可以大幅度减少耗时,但是抽样 Hash 的结果不能作为文件的唯一性标识,抽样 Hash 的值如果和后端一致,前端再计算全量 Hash,如果和后端不一致,那么这个文件一定无法秒传,此时可以直接将文件上传,当然,上传之后还是需要计算全量 Hash 值的。这种方案在文件重复率较少的场景下是很好的,它能极大减少了前端的计算量,提高了速度,相当于转移了一部分工作到后端,也是不错的选择。
总结
断点续传的重点是文件的切割与合并,整个上传流程需要前后端配合好,细节较多。秒传的关键是如何快速计算大文件的摘要信息。我们最后再梳理下文件上传的完整流程。
- 获得文件后,使用 Blob 对象的 slice 方法对其进行切割,并封装一些上传需要的数据,文件切割的速度很快,不影响主线程渲染。
- 计算整个文件的 MD5 值,大文件比较耗时,我们将这部分任务放在 Web Worker 中执行。
- 获得文件的 MD5 值之后,我们将 MD5 值以及文件大小发送到后端,后端查询是否存在该文件,如果不存在的话,查询是否存在该文件的切片文件,如果存在,返回切片文件的详细信息。
- 根据后端返回结果,依次判断是否满足“秒传” 或是 “断点续传” 的条件。如果满足,更新文件切片的状态与文件进度。
- 根据文件切片的状态,发送上传请求,由于存在并发限制,我们限制 request 创建个数,避免页面卡死。
- 对于上传失败的文件,设置最大重试次数,将其继续加入到上传任务中,超过最大重试次数的才认为上传失败。
- 后端收到文件后,首先保存文件,保存成功后记录切片信息,判断当前切片是否是最后一个切片,如果是最后一个切片,记录文件信息,认为文件上传成功,清空切片记录。
目前还有一些可以优化的点。
- 多人上传同一个文件,只要其中一人上传成功即可认为其他人上传成功。
- 拥塞控制,动态计算文件切片大小,大圣老师文章中已经实现。
- 进度条优化,进度条在断点续传和失败重传会出现倒退的情形,
文章和代码都参考了如下几位大神的项目,建议大家看看。
1. 字节跳面试官,我也实现了大文件上传和断点续传
2. 写给新手前端的各种文件上传攻略,从小图片到大文件断点续传
如果您觉得有所收获,就点个赞吧!
完整的代码放在了GitHub上。分别是用 java 实现的 server 端,以及用 react 实现的前端。对着代码看文章,理解会深一些。

