关于队头阻塞(Head-of-Line blocking),看这一篇就足够了
(译)Robin Marx: QUIC 和 HTTP/3 队头阻塞的细节
作者:Robin Marx,原文:Head-of-Line Blocking in QUIC and HTTP/3: The Details,GitHub:rmarx/holblocking-blogpost
您可能已经听说,经过4年的工作,新的 HTTP/3 和 QUIC 协议终于接近正式标准化。预览版现在可以在服务器和浏览器中进行测试。
与 HTTP/2 相比,HTTP/3 有很大的性能改进,这主要是因为它将底层传输协议从 TCP 改为基于 UDP 的 QUIC。在这篇文章中,我们将深入了解其中的一项改进,即消除“队头阻塞”(Head-of-Line blocking, 简写:HOL blocking)问题。这很有用,因为我读过很多关于这实际上意味着什么以及它在现实中有多大帮助的误解。解决队头阻塞也是 HTTP/3 和 QUIC 以及 HTTP/2 背后的主要动机之一,因此它也为协议演进的原因提供了一个极好的视角。
我将首先介绍队头阻塞问题,然后在整个 HTTP 历史中跟踪它的不同形式。我们还将研究它如何与其他系统交互,如优先级和拥塞控制。我们的目标是帮助人们对 HTTP/3 的性能改进做出正确的判断,而这(剧透)可能不像营销材料中所说的那样令人惊讶。
目录:
- 什么是队头阻塞?
- HTTP/1.1 的队头阻塞
- HTTP/2(基于 TCP)的队头阻塞
- HTTP/3(基于 QUIC)的队头阻塞
- 总结与结论
彩蛋内容:
- 彩蛋:HTTP/1.1 管道
- 彩蛋:TLS 队头阻塞
- 彩蛋:传输拥堵控制
- 彩蛋:多路复用是否重要?
什么是队头阻塞(Head-of-Line blocking)?
很难给你一个单一的队头阻塞(HOL blocking)的技术定义,因为这篇博客文章单独描述了它的四个不同变体。然而,一个简单的定义是:
当单个(慢)对象阻止其他/后续的对象前进时
现实生活中一个很好的比喻就是只有一个收银台的杂货店。一个顾客买了很多东西,最后会耽误排在他后面的人,因为顾客是以先进先出(First In, First Out)的方式服务的。另一个例子是只有单行道的高速公路。在这条路上发生一起车祸,可能会使整个通道堵塞很长一段时间。因此,即使是在“头部(head)”一个单一的问题可以“阻塞(block)”整条“线(line)”。
这个概念一直是最难解决的 Web 性能问题之一。为了理解这一点,让我们从 HTTP/1.1 开始讲起。
HTTP/1.1 的队头阻塞
HTTP/1.1是一种更简单的协议。一个协议仍然可以基于文本并在网络上可读的时代。如下图1所示:
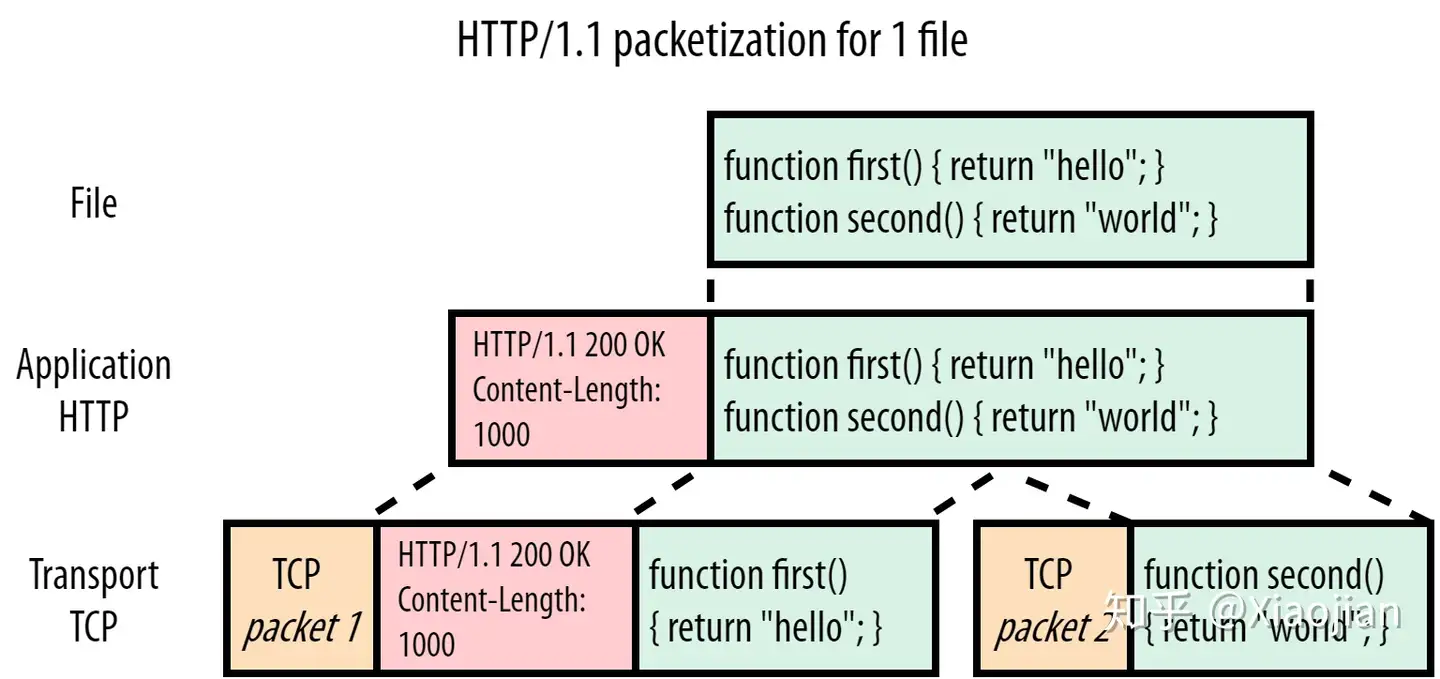
在本例中,浏览器基于 HTTP/1.1上 请求简单的script.js文件(绿色),图1显示了服务器对该请求的响应。我们可以看到 HTTP 方面本身很简单:它只是在明文文件内容或“有效荷载”(payload)前面直接添加一些文本“headers”(红色)。然后,头(Headers)+ 有效荷载(payload)被传递到底层 TCP(橙色),以便真实传输到客户端。对于这个例子,假设我们不能将整个文件放入一个 TCP 包中,并且必须将它分成两部分。
注意:实际上,当使用 HTTPS 时,HTTP 和 TCP 之间有另一个安全层,通常使用 TLS 协议。不过,为了清晰起见,我们在这里省略了这一点。我在结尾加入了一个额外的彩蛋部分,详细说明了 TLS 特定的队头阻塞变体以及 QUIC 如何避免它。阅读完正文后,请随意阅读它(以及其他的彩蛋部分)。
现在让我们看看当浏览器也请求style.css时发生了什么,如图2:
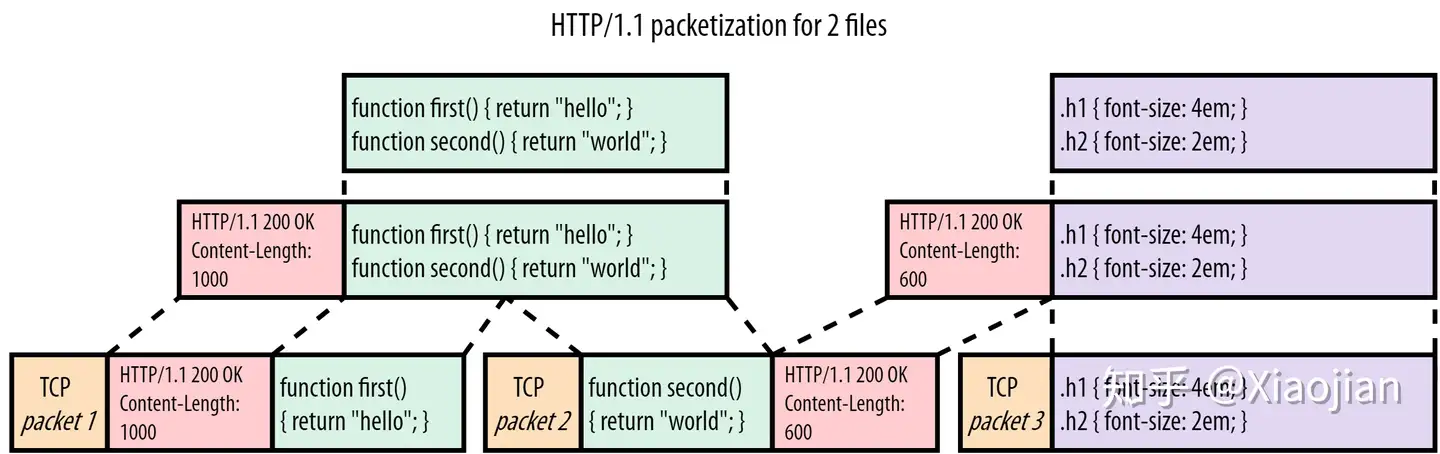
在本例中,当script.js的响应传输之后,我们发送style.css(紫色)。style.css的头部(headers)和内容只是附加在 JavaScript(JS)文件之后。接收者使用Content-Length header 来知道每个响应的结束位置和另一个响应的开始位置(在我们的简化示例中,script.js是1000字节,而style.css只有600字节)。
在这个包含两个小文件的简单示例中,所有这些似乎都很合理。但是,假设 JS 文件比 CSS 大得多(比如说 1MB 而不是 1KB)。这种情况下,在下载整个JS文件之前,CSS 必须等待,尽管它要小得多,其实可以更早地解析/使用。更直接地将其可视化,使用数字 1 表示large_script.js和 2 表示`style.css`,我们会得到这样的结果:
11111111111111111111111111111111111111122你可以看到这是一个队头阻塞问题的例子!现在你可能会想:这很容易解决!只需让浏览器在JS文件之前请求CSS文件!然而,至关重要的是,浏览器无法预先知道这两个文件中的哪一个在请求时会成为更大的文件。这是因为没有办法在HTML中指明文件有多大(类似这样的东西很不错,HTML工作组:<img src="thisisfine.jpg" size="15000" />)。
这个问题的“真正”解决方案是采用多路复用(multiplexing)。如果我们可以将每个文件的有效荷载(header)分成更小的片(pieces)或“块”(chunks),我们就可以在网络上混合或“交错”(interleave)这些块:为 JS 发送一个块,为 CSS 发送一个块,然后再发送另一个用于 JS,等等,直到文件被下载为止。使用这种方法,较小的CSS文件将更早地下载(并且可用),同时只将较大的JS文件延迟一点。用数字形象化我们会得到:
12121111111111111111111111111111111111111然而不幸的是,由于协议存在一些基础的限制,这种多路复用在 HTTP/1.1 中是不可能的。为了理解这一点,我们甚至不需要继续查看大资源对小资源(large-vs-small)场景,因为它已经在我们的示例中显示了两个较小的文件。如图3,我们只为两个资源交错4个块:
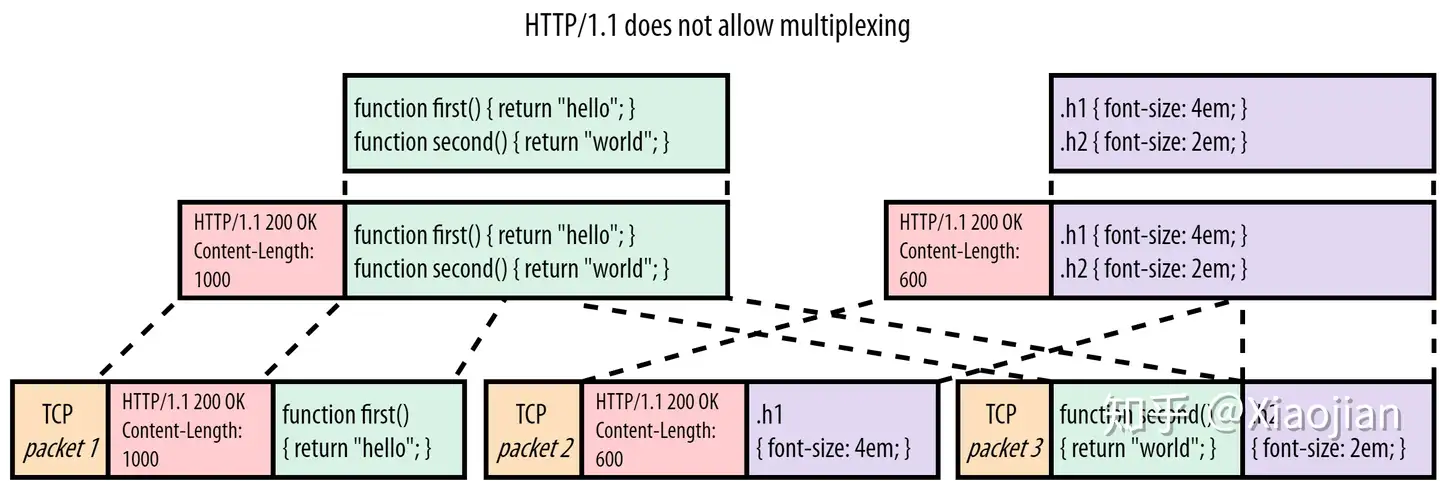
这里的主要问题是 HTTP/1.1 是一个纯文本协议,它只在有效荷载(payload)的前面附加头(headers)。它不会进一步区分单个(大块)资源与其他资源。让我们用一个例子来说明这一点,如果我们尝试了它会发生什么。在图3中,浏览器开始分析script.js并期望后面有1000个字节(Content-Length)的有效荷载。但是,它只接收450个 JS 字节(第一个块),然后开始读取sytle.css的头部。它最终将 CSS 头部和第一个 CSS 块解释为JS的一部分,因为这两个文件的有效荷载和头都是纯文本。更糟糕的是,它在读取1000个字节后停止,直到第二个script.js块的一半。此时,它看不到有效的新报头,必须删除 TCP 数据包3(packet 3)的其余部分。然后浏览器传递它认为的内容script.js到JS解析器,它失败了因为不是有效的 JavaScript:
function first() { return "hello"; }
HTTP/1.1 200 OK
Content-Length: 600
.h1 { font-size: 4em; }
func
同样,您可以说有一个简单的解决方案:让浏览器查找HTTP/1.1 {statusCode} {statusString}\n模式来查看新的头块何时开始。这可能适用于 TCP 数据包2(packet 2),但在数据包3(packet 3)中会失败:浏览器如何知道绿色的script.js块在哪里结束和紫色style.css块从哪里开始?
这是 HTTP/1.1 协议设计方式的一个基础限制。如果您只有一个 HTTP/1.1 连接,那么在您切换到发送新资源之前,必须完整地传输资源响应。如果前面的资源创建缓慢(例如,从数据库查询动态生成的index.html)或者,如上所述,如果前面的资源很大。这些问题可能会引起队头阻塞问题。
这就是为什么浏览器开始为 HTTP/1.1 上的每个页面加载打开多个并行 TCP 连接(通常为6个)。这样,请求可以分布在这些单独的连接上,并且不再有队头阻塞。也就是说,除非每页有超过6个资源…这当然是很常见的。这就是在多个域名上“分片”(sharding)资源的实践(img.mysite.com, static.mysite.com, 等)和 CDN 的由来。由于每个单独的域名有6个连接,浏览器将为每个页面加载总共打开 30-ish 个 TCP 连接。这是可行的,但有相当大的开销:建立一个新的 TCP 连接可能是昂贵的(例如在服务器上的状态和内存方面,以及设置 TLS 加密的计算),并且需要消耗一些时间(特别是对于 HTTPS 连接,因为 TLS 需要自己的握手)。
由于这个问题不能用 HTTP/1.1 解决,而且并行 TCP 连接的补丁解决方案也不能随着时间的推移扩展得太好,很明显需要一种全新的方法,这就是后来的 HTTP/2。
注意:阅读本文的老哥可能会表示想知道 HTTP/1.1 管道(pipelining)。我决定不在这里讨论这一点,以保持整个故事的流畅性,但对更深入的技术感兴趣的人可以阅读结尾的彩蛋部分。
HTTP/2(基于 TCP)的队头阻塞
那么,让我们回顾一下。HTTP/1.1 有一个队头阻塞问题,一个大的或慢的响应会延迟后面的其他响应。这主要是因为协议本质上是纯文本的,在资源块(resource chunks)之间不使用分隔符。作为一种解决办法,浏览器打开许多并行TCP连接,这既不高效,也不可扩展。
因此,HTTP/2 的目标非常明确:我们能够回到单个 TCP 连接,解决队头阻塞问题。换一种说法:我们希望能够正确地复用资源块(resource chunks)。这在 HTTP/1.1 中是不可能的,因为没有办法分辨一个块属于哪个资源,或者它在哪里结束,另一个块从哪里开始。HTTP/2 非常优雅地解决了这一问题,它在资源块之前添加了帧(frames)。如图4所示:
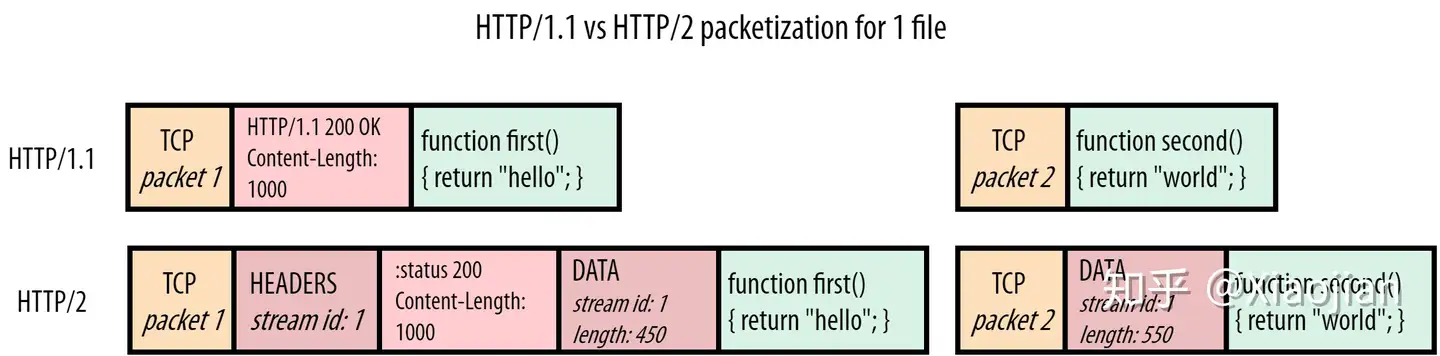
HTTP/2 在每个块前面放置一个所谓的数据帧(DATA frame)。这些数据帧主要包含两个关键的元数据。首先:下面的块属于哪个资源。每个资源的“字节流(bytestream)”都被分配了一个唯一的数字,即流id(stream id)。第二:块的大小是多少。协议还有许多其他帧类型,图5也显示了头部帧(HEADERS frame)。这再次使用流id(stream id)来指出这些头(headers)属于哪个响应,这样甚至可以将头(headers)从它们的实际响应数据中分离出来。
使用这些帧,HTTP/2 确实允许在一个连接上正确地复用多个资源,参见图5:
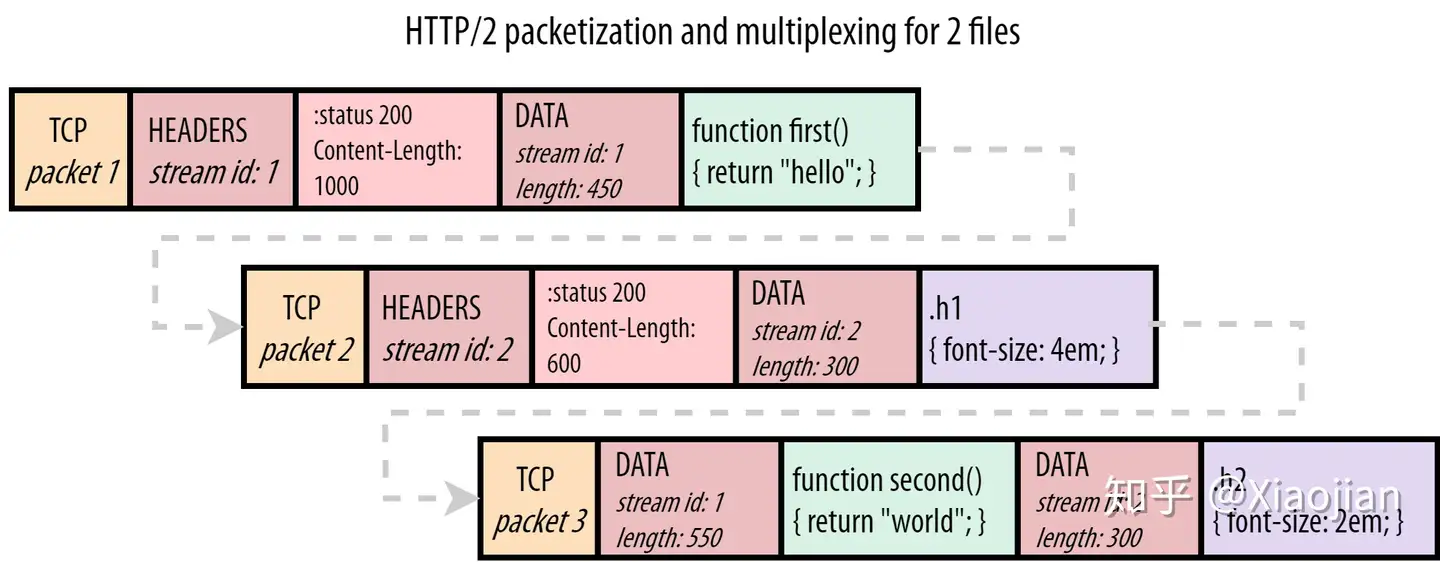
与图3中的示例不同,浏览器现在可以完美地处理这种情况。它首先处理script.js的头部帧(HEADERS frame),然后是第一个JS块的数据帧(DATA frame)。从数据帧(DATA frame)中包含的块长度来看,浏览器知道它只延伸到 TCP 数据包1的末尾,并且需要从 TCP 数据包2开始寻找一个全新的帧。在那里它确实找到了style.css的头(HEADERS), 下一个数据帧(DATA frame)含有与第一个数据帧(1)不同的流 id(2),因此浏览器知道这属于不同的资源。同样的情况也适用于 TCP 数据包3,其中数据帧(DATA frame)流 id 用于将响应块“解复用”(de-multiplex)到正确的资源“流”(streams)。
因此,通过“framing”单个消息,HTTP/2 比 HTTP/1.1 更加灵活。它允许在单个 TCP 连接上通过交错排列块来多路传输多个资源。它还解决了第一个资源缓慢时的队头阻塞问题:而不必等待查询数据库生成的index.html,服务器可以在等待index.html时开始发送其他资源。
HTTP/2 的方式一个重要结果是,我们突然需要一种方法让浏览器与服务器通信,单个连接的带宽如何跨资源分布(distributed)。换一种说法:资源块应该如何“调度(scheduled)”或交错(interleaved)。如果我们再次用 1 和 2 来表示,我们会发现对于 HTTP/1.1,唯一的选项是11112222(我们称之为顺序的(sequential))。然而, HTTP/2 有更多的自由:
- 公平多路复用(例如两个渐进的 JPEGs):12121212
- 加权多路复用(2是1的两倍):22122122121
- 反向顺序调度(例如2是密钥服务器推送的资源):22221111
- 部分调度(流1被中止且未完整发送):112222
使用哪种方法是由 HTTP/2 中所谓的“优先级(prioritization)”系统驱动的,所选择的方法对Web 性能有很大的影响。然而,这本身就是一个非常复杂的话题,你不需要在接下来的博客文章中理解它,所以我不把它放在这里讲了(尽管我在YouTube上有一个关于这个的讲座)。
我想您会同意,通过 HTTP/2 的帧(frames)及其优先级设置,它确实解决了 HTTP/1.1 的队头阻塞问题。这意味着我在这里的工作完成了,我们都可以回家了。对吗?好吧,没那么简单。我们已经解决了 HTTP/1.1 的队头阻塞,是的,但是 TCP 的队头阻塞呢?
TCP 队头阻塞
事实证明,HTTP/2 只解决了 HTTP 级别的队头阻塞,我们可以称之为“应用层”队头阻塞。然而,在典型的网络模型中,还需要考虑下面的其他层。您可以在图6中清楚地看到这一点:
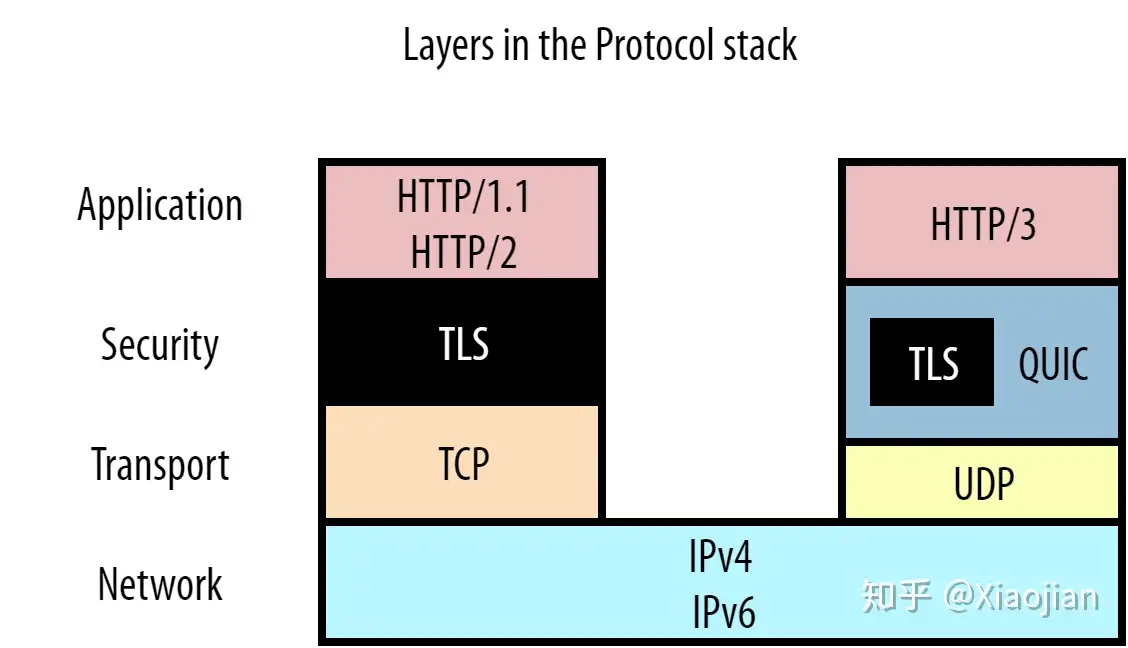
HTTP 位于顶层,但首先由安全层的 TLS 支持(请参阅“彩蛋 TLS”部分),然后接着再由传输层的 TCP 传输。这些协议中的每一层都用一些元数据包装来自其上一层的数据。例如,在我们的 HTTP(S) 数据中预先加上 TCP 包头(packet header),然后将其放入 IP 包等,这样就可以在协议之间实现相对简洁的分离。这反过来又有利于它们的可重用性:像 TCP 这样的传输层协议不必关心它正在传输什么类型的数据(可以是 HTTP,也可以是 FTP,也可以是 SSH,谁知道呢),而且 IP 对于 TCP 和 UDP 都能很好地工作。
然而,如果我们想将多个 HTTP/2 资源多路传输到一个 TCP 连接上,这确实会产生重要的后果。如图7:
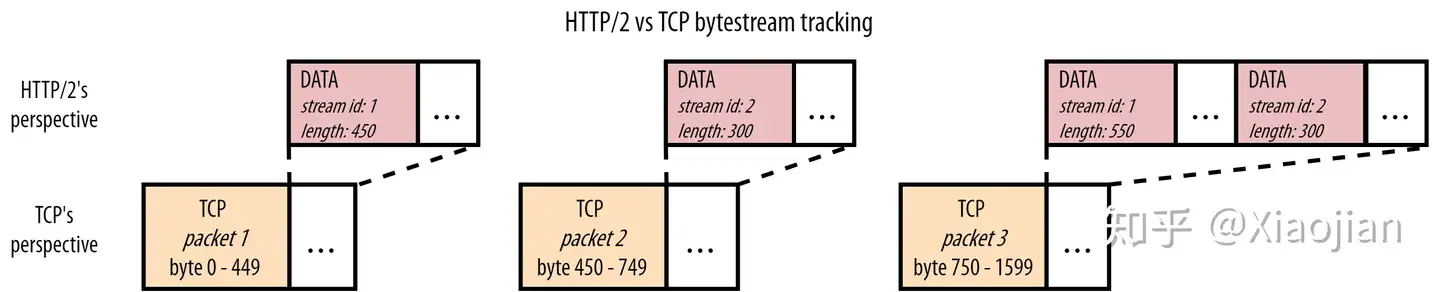
虽然我们和浏览器都知道我们正在获取 JavaScript 和 CSS 文件,但 HTTP/2 不需要知道这一点。它只知道它在使用来自不同资源流 id (stream id)的块。然而,TCP 甚至不知道它在传输 HTTP!TCP 所知道的就是它被赋予了一系列字节,它必须从一台计算机传输另一台计算机。为此,它使用特定最大大小(maximum size)的数据包,通常大约为1450字节。每个数据包只跟踪它携带的数据的那一部分(字节范围),这样原始数据就可以按照正确的顺序重建。
换言之,这两个层之间的透视图是不匹配的:HTTP/2 可以看到多个独立的资源字节流(bytestream),而 TCP 只看到一个不透明的字节流(bytestreams)。图7的TCP数据包3就是一个例子:TCP 只知道它正在传输的任何内容的字节 750 到字节1 599。另一方面,HTTP/2 知道数据包3中实际上有两个独立资源的两个块。(注意:实际上,每个 HTTP/2 帧(如 DATA 和 HEADERS)的大小也有几个字节。为了简单起见,我没有计算额外的开销或这里的 HEADERS 帧,以使数字更直观。)
所有这些看起来都是不必要的细节,直到你意识到互联网是一个根本不可靠的网络。在从一个端点到另一个端点的传输过程中,数据包会丢失和延迟。TCP 的可靠性正是其最受欢迎的原因之一。它只需重新传输丢失数据包的副本就可以做到这一点。
我们现在可以理解传输层是如何导致队头阻塞的。再次思考下图7并问自己:如果 TCP 数据包2在网络中丢失,但数据包1和数据包3已经到达,会发生什么情况?请记住,TCP并不知道它正在承载 HTTP/2,只知道它需要按顺序传递数据。因此,它知道数据包1的内容可以安全使用,并将这些内容传递给浏览器。然而,它发现数据包1中的字节和数据包3中的字节(放数据包2 的地方)之间存在间隙,因此还不能将数据包3传递给浏览器。TCP 将数据包3保存在其接收缓冲区(receive buffer)中,直到它接收到数据包2的重传副本(这至少需要往返服务器一次),之后它可以按照正确的顺序将这两个数据包都传递给浏览器。换个说法:丢失的数据包2 队头阻塞(HOL blocking)数据包3!
您可能不清楚为什么这是个问题,所以让我们更深入地研究图7中 HTTP 层的 TCP 包中的实际内容。我们可以看到,TCP 数据包2只携带流id 2(CSS文件)的数据,数据包3同时携带流1(JS文件)和流2的数据。在 HTTP 级别,我们知道这两个流是独立的,并且由数据帧(DATA frame)清楚地描述出来。因此,理论上我们可以完美地将数据包3传递给浏览器,而不必等待数据包2到达。浏览器将看到流id为1的数据帧,并且能够直接使用它。只有流2必须被挂起,等待数据包2的重新传输。这将比我们从 TCP 的方式中得到的效率更高,TCP 的方式最终会阻塞流1和流2。
另一个例子是数据包1丢失,但是接收到2和3的情况。TCP将再次阻止数据包2和3,等待1。但是,我们可以看到,在HTTP/2级别,流2的数据(CSS文件)完全存在于数据包2和3中,不必等待数据包1的重新传输。浏览器本可以完美地解析/处理/使用 CSS 文件,但却被困在等待 JS 文件的重新传输。
总之,TCP 不知道 HTTP/2 的独立流(streams)这一事实意味着 TCP 层队头阻塞(由于丢失或延迟的数据包)也最终导致 HTTP 队头阻塞!
现在,您可能会问自己:那重点是什么?如果我们仍然有 TCP 队头阻塞,为什么还要使用HTTP/2 呢?好吧,主要原因是虽然数据包丢失确实发生在网络上,但还是比较少见的。特别是在有线网络中,包丢失率只有 0.01%。即使是在最差的蜂窝网络上,在现实中,您也很少看到丢包率高于2%。这与数据包丢失和抖动(网络中的延迟变化)通常是突发性的这一事实结合在一起的。包丢失率为2%并不意味着每100个包中总是有2个包丢失(例如数据包 42 和 96)。实际上,可能更像是在总共500个包中丢失10个连续的包(例如数据包255到265)。这是因为数据包丢失通常是由网络路径中的路由器内存缓冲区暂时溢出引起的,这些缓冲区开始丢弃无法存储的数据包。不过,细节在这里并不重要(如果你想知道更多,可以在其他地方找到)。重要的是:是的,TCP 队头阻塞是真实存在的,但是它对 Web 性能的影响要比HTTP/1.1 队头阻塞小得多,HTTP/1.1 队头阻塞几乎可以保证每次都会遇到它,而且它也会受到 TCP 队头阻塞的影响!
然而,当比较单个连接上的 HTTP/2 和单个连接上的 HTTP/1.1 时,这个基本上是真的。正如我们之前所看到的,实际上它并不是这样工作的,因为 HTTP/1.1 通常会打开多个连接。这使得 HTTP/1.1 不仅在一定程度上减轻了 HTTP 级别,而且减轻了 TCP 级别的队头阻塞。因此,在某些情况下,单个连接上的 HTTP/2 很难比6个连接上的 HTTP/1.1 快,甚至与 HTTP/1.1 一样快。这主要是由于 TCP 的“拥塞控制”(congestion control)机制。然而,这是另一个非常深入的话题,并不是我们讨论队头阻塞(HOL blocking)的核心,所以我把它移到了末尾的另一个彩蛋部分。
总之,事实上,我们看到(也许出乎意料),HTTP/2 目前部署在浏览器和服务器中,在大多数情况下通常与 HTTP/1.1 一样快或略快。在我看来,这部分是因为网站在优化 HTTP/2 方面做得更好,部分原因是浏览器仍然经常打开多个并行 HTTP/2 连接(要么是因为站点仍然在不同的服务器上共享资源,要么是因为与安全相关的副作用),从而使两者兼得。
然而,也有一些情况(特别是在数据包丢失率较高的低速网络上),6个连接的 HTTP/1.1 仍然比一个连接的 HTTP/2 更为出色,这通常是由于 TCP 级别的队头阻塞问题造成的。正是这个事实极大地推动了新的 QUIC 传输协议的开发,以取代 TCP。
HTTP/3(基于 QUIC)的队头阻塞
在那之后,我们终于可以开始谈论新的东西了!但首先,让我们总结一下我们目前所学到的:
- HTTP/1.1 有队头阻塞,因为它需要完整地发送响应,并且不能多路复用它们
- HTTP/2 通过引入“帧”(frames)标识每个资源块属于哪个“流”(stream)来解决这个问题
- 然而,TCP 不知道这些单独的“流”(streams),只是把所有的东西看作一个大流(1 big stream)
- 如果一个 TCP 包丢失,所有后续的包都需要等待它的重传,即使它们包含来自不同流的无关联数据。TCP 具有传输层队头阻塞。
我敢肯定你现在可以预测我们如何解决 TCP 的问题,对吧?毕竟,解决方案很简单:我们“只是”需要让传输层知道不同的、独立的流!这样,如果一个流的数据丢失,传输层本身就知道它不需要阻塞其他流。
尽管这个解决方案概念简单,但在现实中却很难实现。由于各种原因,不可能改变 TCP 本身使其具有流意识(stream-aware)。选择的替代方法是以 QUIC 的形式实现一个全新的传输层协议。为了使 QUIC 现实中可以部署在因特网上,它运行在不可靠的 UDP 协议之上。然而,非常重要的是,这并不意味着 QUIC 本身也是不可靠的!在许多方面,QUIC 应该被看作是一个 TCP 2.0。它包括 TCP 的所有特性(可靠性、拥塞控制、流量控制、排序等)的最佳版本,以及更多其他特性。QUIC还完全集成了TLS(参见图6),并且不允许未加密的连接。因为 QUIC 与 TCP 如此不同,这也意味着我们不能仅仅在其上运行 HTTP/2,这就是为什么创建了 HTTP/3(稍后我们将详细讨论这个问题)。这篇博文已经足够长了,不需要更详细地讨论QUIC(请参阅其他来源),因此我将只关注我们需要了解当前队头阻塞讨论的几个部分。如图8所示:
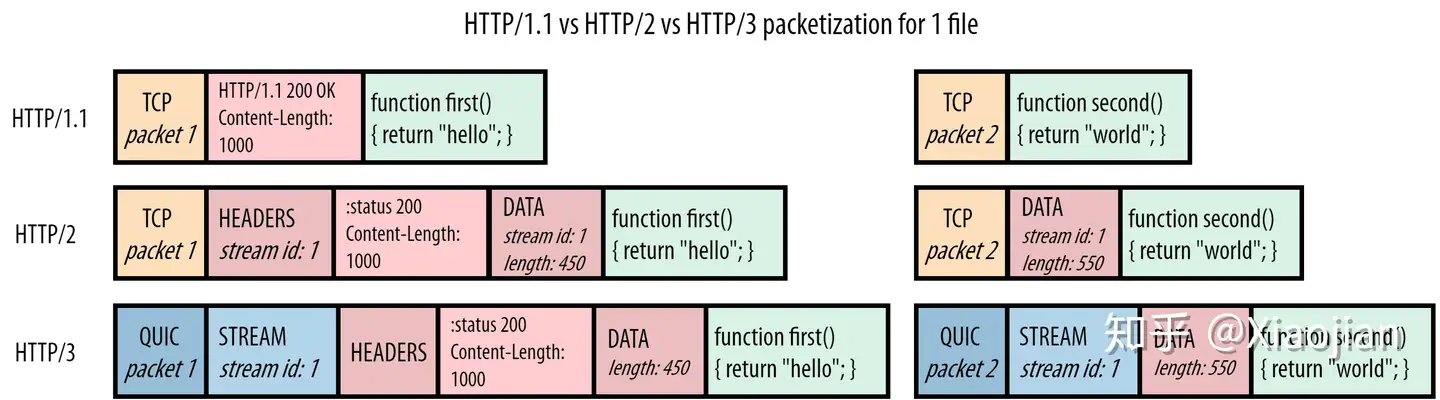
我们观察到,让 QUIC 知道不同的流(streams)是非常简单的。QUIC 受到 HTTP/2 帧方式(framing-approach)的启发,还添加了自己的帧(frames);在本例中是流帧(STREAM frame)。流id(stream id)以前在 HTTP/2 的数据帧(DATA frame)中,现在被下移到传输层的 QUIC 流帧(STREAM frame)中。这也说明了如果我们想使用 QUIC,我们需要一个新版本的 HTTP 的原因之一:如果我们只在 QUIC 之上运行 HTTP/2,那么我们将有两个(可能冲突的)“流层”(stream layers)。相反,HTTP/3 从 HTTP 层删除了流的概念(它的数据帧(DATA frames)没有流id),而是重新使用底层的 QUIC 流。
注意:这并不意味着 QUIC 突然知道 JS 或 CSS 文件,甚至知道它正在传输 HTTP;和 TCP 一样,QUIC 应该是一个通用的、可重用的协议。它只知道有独立的流(streams),它可以单独处理,而不必知道它们到底是什么。
现在我们了解了QUIC的流帧(STREAM frames),也很容易看出它们如何帮助解决图9中的传输层队头阻塞:
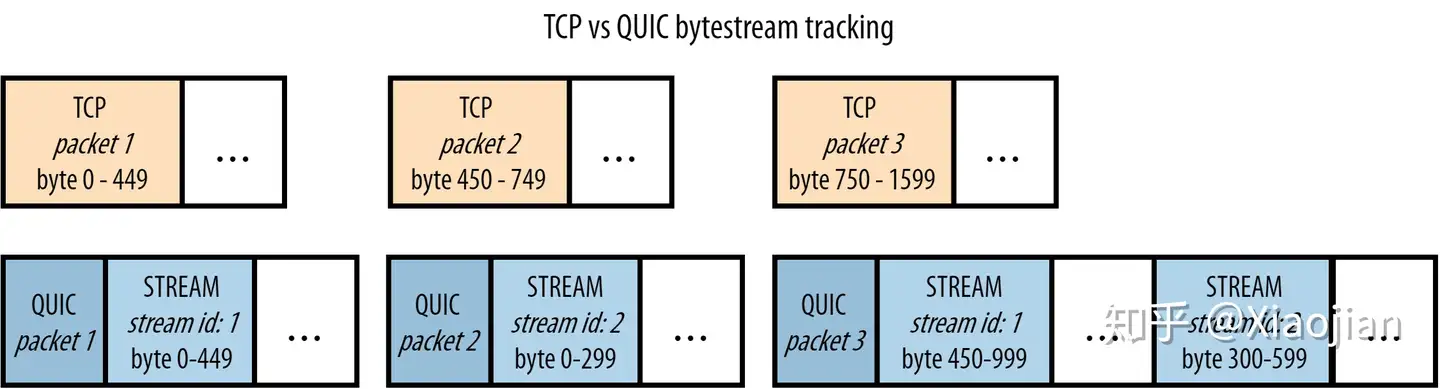
与 HTTP/2 的数据帧(DATA frames)非常相似,QUIC 的流帧(STREAM frames)分别跟踪每个流的字节范围。这与 TCP 不同,TCP 只是将所有流数据附加到一个大 blob 中。像以前一样,让我们考虑一下如果 QUIC 数据包2丢失,而 1 和 3 到达会发生什么。与 TCP 类似,数据包1中流1(stream 1)的数据可以直接传递到浏览器。然而,对于数据包3,QUIC 可以比 TCP 更聪明。它查看流1的字节范围,发现这个流帧(STREAM frame)完全遵循流id 1的第一个流帧 STREAM frame(字节 450 跟在字节 449 之后,因此数据中没有字节间隙)。它可以立即将这些数据提供给浏览器进行处理。然而,对于流id 2,QUIC确实看到了一个缺口(它还没有接收到字节0-299,这些字节在丢失的 QUIC 数据包2中)。它将保存该流帧(STREAM frame),直到 QUIC 数据包2的重传(retransmission)到达。再次将其与 TCP 进行对比,后者也将数据流1的数据保留在数据包3中!
类似的情况发生在另一种情形下,数据包1丢失,但2和3到达。QUIC 知道它已经接收到流2(stream 2)的所有预期数据,并将其传递给浏览器,只保留流1(stream 1)。我们可以看到,对于这个例子,QUIC 确实解决了 TCP 的队头阻塞!
不过,这种方式有几个重要的后果。最有影响的是 QUIC 数据可能不再以与发送时完全相同的顺序发送到浏览器。对于 TCP,如果您发送数据包1、2和3,它们的内容将以完全相同的顺序发送到浏览器(这就是导致队头阻塞的第一个原因)。然而,对于 QUIC,在上面的第二个示例中,在数据包1丢失的情况下,浏览器首先看到数据包2的内容,然后是数据包3的最后一部分,然后是数据包1的(重传),然后是数据包3的第一部分。换言之:QUIC 在单个资源流中保留了顺序,但不再跨单个流(individual streams)进行排序。
这是需要 HTTP/3 的第二个也是最重要的原因,因为事实证明,HTTP/2 中的几个系统非常严重地依赖于 TCP 跨流(across streams)的完全确定性排序。例如,HTTP/2 的优先级系统通过传输更改树数据结构(tree data structure )布局的操作(例如,将资源5添加为资源6的子级)工作的。如果这些操作应用的顺序与发送顺序不同(现在通过 QUIC 是可能出现的),客户端和服务端的优先级状态可能不同。HTTP/2 的头压缩系统 HPACK 也会发生类似的情况。理解这里的细节并不重要,只需要得出结论:要让这些 HTTP/2 系统直接应用 QUIC 是非常困难的。因此,对于 HTTP/3,有些系统使用完全不同的方法。例如,QPACK 是 HTTP/3 的 HPACK 版本,它允许在潜在的队头阻塞和压缩性能之间进行自我选择的权衡。HTTP/2 的优先级系统甚至被完全删除,很可能会被 HTTP/3 的简化版本所取代。所有这些都是因为,与 TCP 不同,QUIC 不能完全保证首先发送的数据也会首先被接收。
所以,所有 QUIC 和重新设想 HTTP 版本的这些工作都是为了消除传输层队头阻塞。我当然希望这是值得的…
QUIC 和 HTTP/3 真的完全消除了队头阻塞?
如果你允许我说一点不好的话,我想引用自己几个段落前的话:
QUIC在单个资源流中保留排序
你想想,这很符合逻辑。它基本上是这样说的:如果你有一个 JavaScript 文件,该文件需要重新组装(re-assembled),就像它是由开发人员创建的一样(或者,老实说,通过 webpack),否则代码将无法工作。任何类型的文件都是一样的:把图片随机地放在一起意味着你阿姨寄来的一些奇怪的电子圣诞卡(甚至更奇怪的)。这意味着,即使在QUIC中,我们仍然有一种队头阻塞的形式:如果在单个流中有一个字节间隙,那么流的后面部分仍然会被阻塞,直到这个间隙被填满。
这有一个关键的含义:QUIC 的队头阻塞移除只有在多个资源流同时活动时才有效。这样,如果其中一个流上有包丢失,其他流仍然可以继续。这就是我们在上面图9的例子中看到的。然而,如果在某一时刻只有一个流在活动,任何丢包都会影响到这条孤独的流,我们仍然会被阻塞,即使在 QUIC。所以,真正的问题是:我们会经常有多个并发流(simultaneous streams)吗?
正如对 HTTP/2 所解释的,这是可以通过使用适当的资源调度器/多路复用方法来配置的。流1和流2可以被发送 1122、2121、1221 等,并且浏览器可以使用优先级系统指定它希望服务器遵循的方案(对于 HTTP/3 仍然如此)。所以浏览器可以说:嘿!我注意到这个连接有严重的数据包丢失。我将让服务器以 121212 模式而不是 111222 向我发送资源。这样,如果1的一个数据包丢失,2仍然可以继续工作。然而,这种模式的问题是,121212 模式(或者类似的)对资源加载性能通常不是最优的。
这是另一个复杂的话题,我现在不想太深入(我在 YouTube 上有一个关于这个的讨论,供感兴趣的人了解)。但是,通过我们的 JS 和 CSS 文件的简单示例,基本概念很容易理解。正如您可能知道的那样,浏览器需要接收整个 JS 或 CSS 文件,然后才能实际执行/应用它(虽然有些浏览器已经可以开始编译/解析部分下载的文件,但它们仍然需要等待它们完整后才能实际使用它们)。但是,大量多路复用这些文件的资源块最终会延迟它们:
使用多路复用(较慢):
---------------------------
流1(Stream 1)只有到这里才能使用
▼
12121212121212121212121212121212
▲
流2(Stream 2)在这里下载完毕
未使用多路复用/顺序(流1(Stream 1)更快):
------------------------------------------------------
流1(Stream 1)在这里下载完毕,可以更早地使用
▼
11111111111111111122222222222222
▲
流2(Stream 2)还是在这里下载完毕现在,这个话题有很多细微差别,当然也存在多路复用方法更快的情况(例如,如果其中一个文件比另一个文件小得多,正如本文前面讨论的那样)。然而,一般来说,对于大多数页面和大多数资源类型,我们可以说顺序方法最有效(再次,请参阅上面的YouTube链接以获取更多信息)。
现在,这是什么意思?对于最佳性能,我们有两个相互冲突的性能优化建议:
- 从 QUIC 的队头阻塞移除中获利:多路复用发送资源(12121212)
- 为了确保浏览器能够尽快处理核心资源:按顺序发送资源(11112222)
那么,哪一个是正确的?或者至少:哪一个应该优先于另一个?可悲的是,目前我还不能给你一个明确的答案,因为这是我正在研究的一个主题。这之所以困难,主要是因为数据包丢失模式很难预测。
正如我们在上面讨论过的,包丢失通常是突发性的和分组的。这意味着我们上面 12121212 的例子已经过于简化了。图10给出了一个更真实的概述。在这里,我们假设在下载2个流(绿色和紫色)时,我们有一个8个丢失包的突发事件:
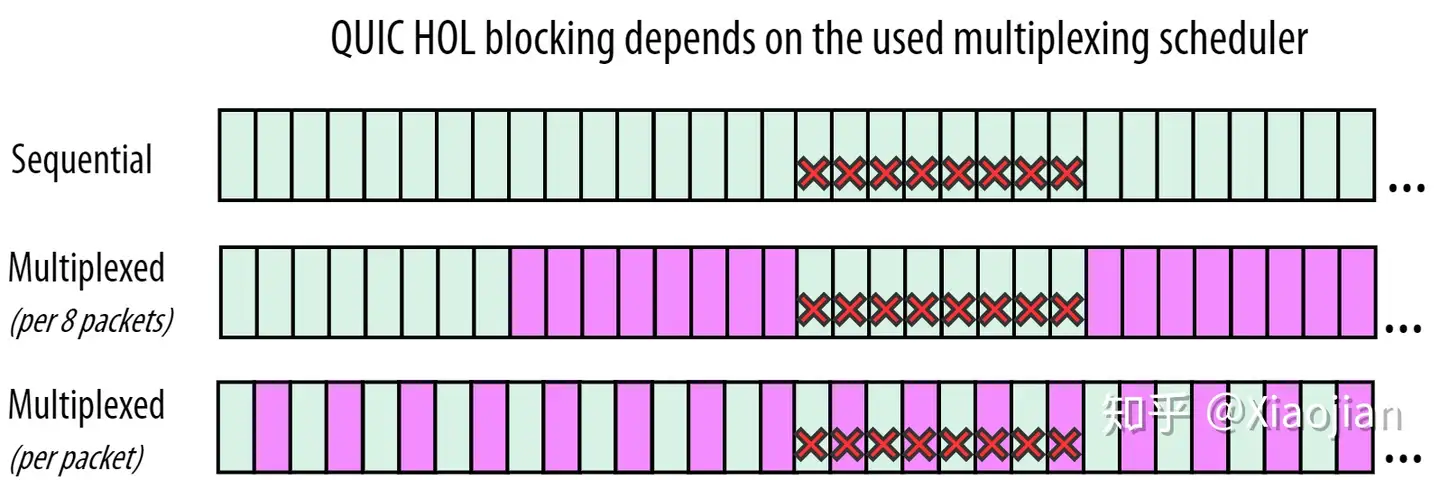
在图10的顶部第一行中,我们可以看到(通常)对资源加载性能更好的顺序情况。在这里,我们看到 QUIC 对消除队头阻塞确实没有那么大的帮助:在丢包之后收到的绿包不能被浏览器处理,因为它们属于经历丢包的同一个流。第二个(紫色)流的数据尚未收到,因此无法处理。
这与中间一行不同,中间一行(偶然!)丢失的8个数据包都来自绿色流。这意味着浏览器可以处理最后收到的紫色数据包。然而,正如前面所讨论的,如果浏览器是 JS 或 CSS 文件,如果有更多的紫色数据出现,浏览器可能不会从中受益太多。因此,在这里,我们从 QUIC 的队头阻塞移除中获得了一些好处(因为紫色没有被绿色阻止),但是可能会牺牲整体资源加载性能(因为多路复用会导致文件稍后完成)。
最下面一行几乎是最糟糕的情况。8个丢失的数据包分布在两个流中。这意味着这两个流现在都被队头阻塞了:不是因为它们像TCP那样在等待对方,而是因为每个流仍然需要自己排序。
注意:这也是为什么大多数 QUIC 实现很少同时创建包含来自多个流(streams)的数据包(packets)的原因。如果其中一个数据包丢失,则会立即导致单个数据包中所有流的队头阻塞!
因此,我们看到可能存在某种最佳位置(中间一行),在这里,队头阻塞预防和资源加载性能之间的权衡可能是值得的。然而,正如我们所说,丢包模式很难预测。不会总是8个数据包。它们不会总是一样的8个数据包。如果我们搞错了,丢失的数据包只向左移动了一个,我们突然也少了一个紫色的包,这基本上使我们降级到与最下面一行相似的位置…
我想你会同意我的观点,那听起来很复杂,甚至可能太复杂了。即便如此,问题是这会有多大帮助。如前所述,包丢失在许多网络类型中通常比较少见,可能(也许?)太罕见了,看不到 QUIC 移除队头阻塞的影响。另一方面,已经有很好的文档证明,无论您使用的是 HTTP/2 还是 HTTP/3,每个资源的数据包(图10的最后一行)对资源加载性能都是相当不利的。
因此,有人可能会说,虽然 QUIC 和 HTTP/3 不再受到应用层或传输层队头阻塞的影响,但这在现实中可能并不重要。我不能确定这一点,因为我们还没有完全完成 QUIC 和 HTTP/3 的实现,所以我也没有最后的度量(measurements)。然而,我个人的直觉(这是由我的几个早期实验的结果支持的)说,QUIC 消除队头阻塞可能实际上对 Web 性能没有太大帮助,因为理想情况下,您不希望为了资源加载性能而对许多流进行多路复用。而且,如果你真的想让它工作得很好,你就必须非常巧妙地调整你的多路复用方式来适应连接类型,因为你绝对不想在包丢失非常低的快速网络上进行大量的多路复用(因为它们无论如何都不会遭受太多的队头阻塞)。就我个人而言,我不认为会发生这种事。
注意:在这里,在结尾,你可能已经注意到我的故事有点不一致。一开始,我说 HTTP/1.1 的问题是它不允许多路复用。最后,我说多路复用在现实中并不那么重要。为了帮助解决这个明显的矛盾,我添加了另一个额外的彩蛋部分
总结与结论
在这篇(很长,我知道)的文章中,我们一直在追踪队头阻塞。我们首先讨论了为什么 HTTP/1.1 会受到应用层队头阻塞的影响。这主要是因为 HTTP/1.1 没有识别单个资源块的方法。HTTP/2 使用帧来标记这些块并启用多路复用。这解决了 HTTP/1.1 的问题,但遗憾的是HTTP/2 仍然受到底层 TCP 的限制。由于 TCP 将 HTTP/2 数据抽象为一个单一的、有序的、但不透明的流,因此如果数据包在网络上丢失或严重延迟,它将遭受队头阻塞。QUIC 通过将 HTTP/2 的一些概念引入传输层来解决这个问题。这反过来会产生严重的影响,因为跨流的数据不再是完全有序的。这最终导致需要一个全新的版本 HTTP/3,它只运行在 QUIC 之上(而 HTTP/2 只运行在 TCP 之上,请参见图6)。
我们需要所有这些上下文来批判性地思考 QUIC(以及 HTTP/3)中的队头阻塞移除在现实中对 Web 性能的实际帮助有多大。我们看到它可能只会对有大量数据包丢失的网络产生很大的影响。我们还讨论了为什么即使这样,您仍然需要多路复用资源,并看运气丢包对多路复用的影响怎么样。我们看到了为什么这样做实际上弊大于利,因为资源多路复用通常不是 Web 性能的最佳方案。我们得出的结论是,虽然现在确定这一点还为时过早,但在大多数情况下,QUIC 和 HTTP/3 的队头阻塞移除可能不会对 Web 性能起到多大作用。
那么…这又给我们留下什么样的 Web 性能评价呢?忽略 QUIC 和 HTTP/3,坚持 HTTP/2 + TCP?我当然不希望!我仍然相信 HTTP/3 总体上将比 HTTP/2 快,因为 QUIC 还包括其他性能改进。例如,它比 TCP 在网络上的开销更小,在拥塞控制方面更加灵活,而且最重要的是,它具有 0-RTT 连接建立特性。我觉得特别是 0-RTT 将提供最多的Web性能好处,尽管也有很多挑战。以后我会写另一篇关于 0-RTT 的博客文章,但是如果你迫不及待想知道更多关于放大攻击预防、重放攻击、初始拥塞窗口大小等的信息,请看我的另一篇 YouTube 讲座或阅读我最近的论文。
如果你喜欢所有这些,并希望在未来有更多的交流,请关注我的 twitter @programmingart。
这篇文章的“在线文档”版本可以在 github 上找到。如果您有关于如何改进它的建议,请让我知道!
感谢您的阅读!
彩蛋:HTTP/1.1 管道(pipelining)
HTTP/1.1 包含了一个名为“管道“(pipelining)的特性,在我看来这是经常被误解的。我看过很多文章,甚至书籍中都有人声称 HTTP/1.1 管道解决了队头阻塞问题。我甚至见过一些人说管道和正确的多路复用是一样的。两种说法都是错误的。
我发现用类似彩蛋图1中的插图来解释 HTTP/1.1 管道是最简单的:

如果没有管道(pipelining)(彩蛋图1的左侧),浏览器必须等待发送第二个资源请求,直到第一个请求的响应被完全接收(同样使用 Content-Length)。这会为每个请求增加一个往返时间(RTT)延迟,这对Web性能不利。
有了管道(彩蛋图1的中间部分),浏览器不必等待任何响应数据,现在可以背靠背地发送请求。这样,我们在连接过程中节省了一些 RTTs,使得加载过程更快。另请注意,请回顾图2:您会看到实际上也在使用管道,因为服务器在 TCP 数据包2中打包 script.js 以及 style.css 的响应数据。当然,只有在服务器同时接收到这两个请求时,这才是可能的。
然而,最重要的是,这种管道只适用于来自浏览器的请求。正如[HTTP/1.1 规范][h1spec]所说:
服务器必须按照接收请求的顺序发送对这些[管道化]请求的响应。
因此,我们看到,实际的响应块(response chunks)多路复用(如彩蛋图1右侧所示)在 HTTP/1.1 管道中仍然是不可能的。换一种说法:管道解决了请求的队头阻塞,而不是响应的队头阻塞。可悲的是,响应队头阻塞是导致 Web 性能问题最多的原因。
更糟糕的是,大多数浏览器实际上并没有在现实中使用 HTTP/1.1 管道,因为这会使队头阻塞在多个并行 TCP 连接的设置中变得更加不可预测。为了理解这一点,让我们设想一个设置,其中通过两个 TCP 连接从服务器请求三个文件 A(大)、B(小)和 C(小)。A 和 B 在不同的连接上被请求。现在,浏览器应该在哪个连接上传输对 C 的请求?正如我们之前所说,它不知道 A 还是 B 将成为最大/最慢的资源。
如果它猜对了(B),它就可以在传输 A 所需的时间内同时下载 B 和 C,从而获得了很好的加速效果。但是,如果猜测是错误的(A),B 的连接将长时间处于空闲状态,而 C 则在 A 后面被阻塞。这是因为 HTTP/1.1 也没有提供一种在请求被发送后“中止”的方法(HTTP/2 和 HTTP/3 允许这样做)。因此,浏览器不能简单地通过 B 的连接请求 C,因为它最终会请求两次 C。
为了解决所有这些问题,现代浏览器不使用管道,甚至会主动延迟对某些已发现资源(例如图像)的请求一段时间,以查看是否找到更重要的文件(例如 JS 和 CSS),以确保高优先级资源不会被阻塞。
很明显,HTTP/1.1 管道的失败是 HTTP/2 使用截然不同方法的另一个动机。然而,由于 HTTP/2 的优先级系统指导多路复用在现实中常常无法执行,一些浏览器甚至采取了延迟 HTTP/2 资源请求的方式来获得最佳性能。
彩蛋:TLS 队头阻塞
如上所述,TLS 协议为应用层协议(如 HTTP)提供加密(和其他功能)。它通过将从 HTTP 获取的数据包装到 TLS 记录中,TLS 记录在概念上类似于 HTTP/2 帧(frames)或 TCP 数据包(packets)。例如,它们在开始时包含一些元数据,以标识记录的长度。然后,对该记录及其 HTTP 内容进行加密并传递给 TCP 进行传输。
就 CPU 使用率而言,加密可能是一项昂贵的操作,因此一次加密一个好数据块通常是一个好主意,因为这通常更有效。实际上,TLS 可以以高达 16KB 的块加密资源,这足以填充大约 11 个典型的 TCP 包(give 或 take)。
然而,至关重要的是,TLS 只能对整个记录进行解密,这就是为什么会出现 TLS 队头阻塞的情况。假设 TLS 记录分散在 11 个 TCP 包上,最后一个 TCP 包丢失。由于 TLS 记录是不完整的,它不能被解密,因此被卡在等待最后一个 TCP 包的重传。注意,在这个特定的情况下,没有 TCP 队头阻塞:在编号11之后没有数据包被卡住等待重新传输。换言之,如果我们在本例中使用纯 HTTP 而不是 HTTPS,那么前10个包中的 HTTP 数据可能已经被移动到浏览器中进行处理。然而,因为我们需要整个11包的 TLS 记录才能解密它,所以我们有了一种新形式的队头阻塞。
虽然这是一个非常具体的情况,在现实中可能不会经常发生,但在设计 QUIC 协议时,它仍然被考虑在内。因为那里的目标是彻底消除所有形式的队头阻塞(或至少尽可能多地消除),甚至这种边缘情况也必须被移除。这就是为什么 QUIC 集成了 TLS,它总是以每个包为基础加密数据,并且不直接使用 TLS 记录。正如我们所看到的,与使用更大的块相比,这效率更低,需要更多的 CPU,这也是为什么 QUIC 在当前实现中仍然比 TCP 慢的主要原因之一。
彩蛋:传输拥塞控制
传输层协议如 TCP 和 QUIC 包括一种称为拥塞控制(Congestion Control)的机制。拥塞控制器的主要工作是确保网络不会同时被过多的数据过载。如果没有缓冲区的话,数据包就会溢出。所以,它通常只发送一点数据(通常是 14KB),看看是否能通过。如果数据到达,接收方将确认发送回发送方。只要所有发送的数据都得到确认,发送方就在每次 RTT 时将其发送速率加倍,直到观察到丢包事件(这意味着网络过载(1 位),它需要后退(1 位))。这就是 TCP 连接如何“探测”其可用带宽。
注:以上描述只是拥塞控制的一种方法。目前,其他方法也越来越流行,其中主要是 BBR 算法。BBR 并没有直接观察数据包丢失,而是大量考虑 RTT 波动来确定网络是否过载,这意味着它通常通过探测带宽来减少数据包丢失。
关键是:拥塞控制机制对每个 TCP(和 QUIC)连接都是独立的!这反过来也会影响到 HTTP层 的 Web 性能。首先,这意味着 HTTP/2 的单个连接最初只发送 14KB。然而,HTTP/1.1 的6个连接在它们的第一次传输中发送 14KB,大约是 84KB!随着时间的推移,这将变得复杂,因为每个 HTTP/1.1 连接使用每个 RTT 将其数据加倍。第二,只有在数据包丢失的情况下,连接才会降低其发送速率。对于 HTTP/2 的单个连接,即使是一个包丢失也意味着它将减慢速度(除了导致 TCP 队头阻塞之外!)。然而,对于 HTTP/1.1,只有一个连接上的一个包丢失只会减慢这一个连接的速度:其他5个连接可以保持正常的发送和增长。
这一切使一件事变得非常清楚:HTTP/2 的多路复用与 HTTP/1.1 的同时下载资源是不一样的(我还看到一些人声称这一点)。单个 HTTP/2 连接的可用带宽只是在不同文件之间分布/共享,但是块仍然是按顺序发送的。这与 HTTP/1.1 不同,后者以真正的并行方式发送内容。
现在,您可能会想知道:那么,HTTP/2 怎么可能比 HTTP/1.1 快呢?这是一个很好的问题,也是我断断续续问自己很久的问题。一个明显的答案是,如果你有超过6个文件。这就是 HTTP/2 在当时的市场营销方式:将一个图像分割成小正方形,然后通过 HTTP/1.1 vs HTTP/2 加载它们。这主要展示了 HTTP/2 的队头阻塞移除。然而,对于普通/真实的网站来说,事情很快就会变得更加微妙。这取决于资源的数量、大小、使用的优先级/多路复用方案、到服务器的 RTT、实际有多少丢包以及何时发生、同时链路上有多少其他流量、使用的拥塞控制器逻辑,等等。HTTP/1.1 可能会丢失的一个例子是在可用带宽有限的网络上:6个 HTTP/1.1 连接各自增加其发送速率,导致它们很快使网络过载,之后它们都必须后退,必须通过反复试验找到它们共存的带宽限制(在 HTTP/2 之前,人们认为 HTTP/1.1 的并行连接可能是因特网上数据包丢失的主要原因)。单个 HTTP/2 连接增长较慢,但在包丢失事件后恢复速度更快,并且更快地找到最佳带宽。另一个带有注释的拥塞窗口的更详细的,HTTP/2 更快的示例可以看这张图片(不适用于胆小的人)。
QUIC 和 HTTP/3 将面临类似的挑战,就像 HTTP/2 一样,HTTP/3 将使用单一的底层 QUIC 连接。然后,您可能会说 QUIC 连接在概念上有点像多个 TCP 连接,因为每个 QUIC 流都可以看作一个TCP连接,因为丢失检测是在每个流的基础上完成的。然而,关键的是,QUIC 的拥塞控制仍然是在连接级别完成的,而不是针对每个流。这意味着,即使流在概念上是独立的,它们仍然会影响 QUIC 的单连接拥塞控制器,如果流中有任何一个丢失,就会导致速度减慢。换句话说:单个 HTTP/3+QUIC 连接仍然不会像 6 个 HTTP/1.1 连接那样快速增长,类似于一个连接上的 HTTP/2+TCP 增长速度并不快。
彩蛋:多路复用是否重要?
如上所述,并在本演示文稿中进行了深入解释,通常建议以顺序方式而不是多路传输方式发送大多数网页资源。换一种说法,如果你有两个文件,你通常最好发送 11112222 而不是 12121212。对于需要在应用之前完全接收的资源,如 JS、CSS 和字体,尤其如此。
如果是这样的话,我们可能会想为什么我们需要多路复用?通过扩展:HTTP/2 甚至 HTTP/3,因为多路复用是 HTTP/1.1 没有的主要特性之一。首先,一些可以增量处理/呈现的文件确实从多路复用中获益。例如,渐进式图像就是这样。第二,如上所述,如果其中一个文件比其他文件小得多,那么它可能会很有用,因为它将更早地下载,而不会对其他文件造成太多的延迟。第三,多路复用允许改变响应的顺序,并为高优先级的响应中断低优先级的响应。
现实中出现的一个很好的例子是在源服务器前面使用 CDN 缓存。假设浏览器从 CDN 请求两个文件。第一个(1)没有被缓存,需要从源文件中获取,这需要一段时间。第二个资源(2)缓存在 CDN 中,因此可以直接传输回浏览器。
在一个连接上使用 HTTP/1.1,由于队头阻塞,我们必须等待队头完全发送(1),然后才能开始发送(2)。这将给我们带来 11112222,但需要很长的前期等待时间。然而,使用HTTP/2,我们可以立即开始发送(2),利用 CDN 和源节点之间的“思考时间”,并“预热”连接的拥塞控制器。重要的是,如果(1)在(2)完成之前开始到达,我们现在可以简单地开始将(1)的数据注入到响应流中。这样我们就可以得到 22111122,等待的时间要短得多。甚至可以在连接开始时使用服务器推送(Server Push)或103早期提示(103 early hints)等功能。
因此,虽然像 12121212 这样的完全“轮询”多路复用很少是您想要的 Web 性能,但是多路复用在总体上绝对是一个有用的特性。
感谢
我要感谢所有提前审阅过这篇文章的人,包括:Andy Davies, Dirkjan Ochtman, Paul Reilly, Alexander Yu, Lucas Pardue, Joris Herbots, 和 neko-suki。
所有图片都是用 https://www.diagrams.net 制作的。使用的字体是“Myriad Pro Condensed”。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号