C++ in Node.js 业务场景及开发实现

C++ in Node.js 业务场景及开发实现
一、摘要
本文主要对 Node.js V8 引擎进行了介绍,并在了解 Node.js 引擎的基础上分析 Node.js 的优劣势:“擅长I/O密集型计算、不擅长CPU密集型计算”。进而引入对 C++ 编写的 Node.js 插件的介绍。C++ 在高性能、高速和并行计算方面及其强大,很好的弥补了 Node.js 的不足。但在插件编写方面,有着很多细节等待我们去理解。
二、Node.js 及其 V8 引擎
(对 Node.js 底层、机制和特点有初步了解的话可以跳过这一节,讲的很浅,主要是为后一节铺一个基础)
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
Node.js 使用了一个事件驱动、非阻塞式 I/O 的模型,使其轻量又高效。
Node.js 的包管理器 npm,是全球最大的开源库生态系统。
上述引自 Node.js 官网,对 Node.js 的描述。
- 第一句话描述了 Node.js 的本质:V8、JavaScript 运行环境
- 第二句话描述了 Node.js 的特点:事件驱动、非阻塞I/O
- 第三句话描述了 Node.js 的生态:npm
而我们对 Node.js 及其引擎的介绍,就将从前两句话开始。
在介绍之前,先描述一些场景,我们大家在使用 Node.js 的过程中可能都会好奇一些问题:
- 为什么在浏览器中运行的 Javascript 能与操作系统进行如此底层的交互?
- 作为服务端语言,Node.js 比 Java、PHP 等传统语言好在哪里?
- Node.js 的异步非阻塞I/O 相比同步好难理解啊?它好在哪里?是怎么实现的?
用久了以后可能还会想:
- Node.js 这么厉害,难道没有它不适合的事情吗?
看着这些问题,着实有些头大。让我们带着这些问题,来看这一章节。
先介绍一下 V8 引擎:
V8是一个由美国 Google 开发的开源 JavaScript 引擎,用于 Google Chrome 中。
Google 的 V8 引擎 是用 C++ 编写的,它也能够编译并执行 JavaScript 源代码、处理内存分配和垃圾回收。
V8 在运行之前将 JavaScript 编译成了机器码,而非字节码或是解释执行它,以此提升性能。更进一步,使用了如内联缓存(inline caching)等方法来提高性能。有了这些功能, JavaScript 程序与 V8 引擎的速度媲美二进制编译。
我们只需要知道 V8 是 Google 的,用 C++ 编写的,编译执行 JavaScript 代码的引擎就好。而 Node.js 也选取了 V8 作为 Node.js 的引擎。带着这个基础、带着刚刚的问题,一起来探秘 Node.js 底层结构。
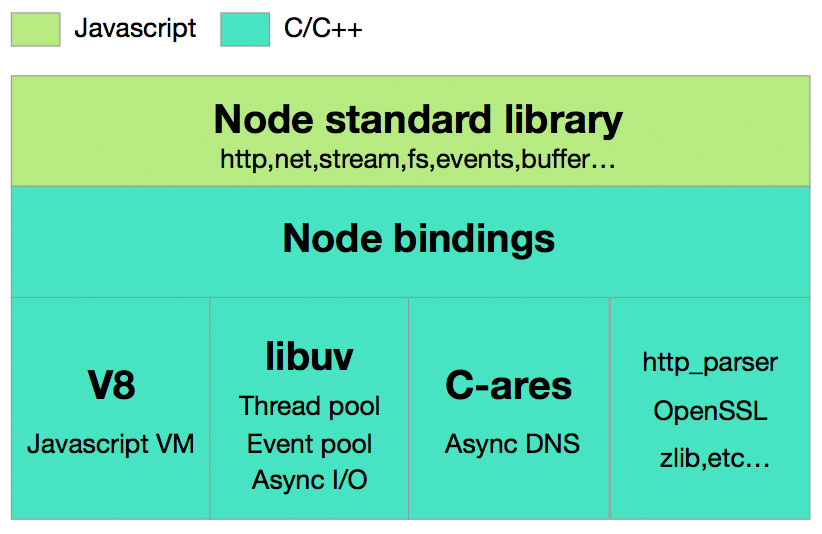
Node.js 的 结构大致分为三个部分:
- Node.js 标准库,这部分是由 Javascript 编写的,即我们使用过程中直接能调用的 API。在源码中的 lib 目录下可以看到。
- Node bindings,这一层是 Javascript 与底层 C/C++ 能够沟通的关键,前者通过 bindings 调用后者,相互交换数据。
- 这一层是支撑 Node.js 运行的关键,由 C/C++ 实现。
在第三层中,我们注意了 V8 以及 libuv:
- V8:Google 推出的 Javascript VM,它为 Javascript 提供了在非浏览器端运行的环境,它的高效是 Node.js 之所以高效的原因之一。
- Libuv:它为 Node.js 提供了跨平台,线程池,事件池,异步 I/O 等能力,是 Node.js 强大的关键。
V8 用于提供 JavaScript 运行环境先不谈,先谈 Libuv。
举一个例子:
const fs = require('fs');
fs.open('./test.txt', "w", function(err, fd) {
//..do something
});
这段很简单的打开文件的代码执行过程如下:
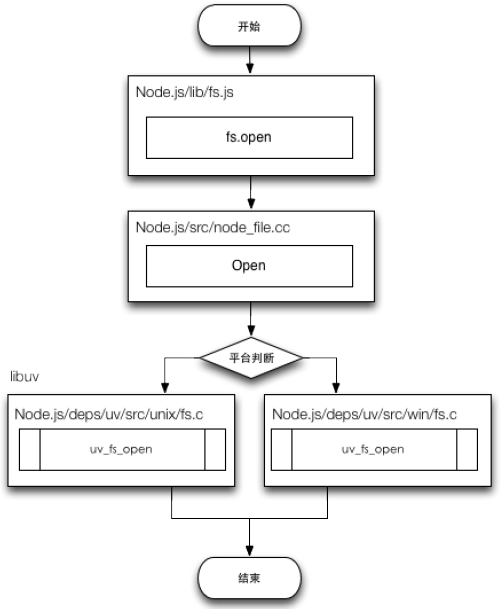
具体来说,当我们调用 fs.open 时,Node.js 通过 process.binding 调用 C/C++ 层面的 Open 函数,然后通过它调用 Libuv 中的具体方法 uv_fs_open 与操作系统进行互动,最后执行的结果通过回调的方式传回,完成流程。在图中,可以看到平台判断的流程,需要说明的是,这一步是在编译的时候(即 Node.js 安装到系统上时)已经决定好的,并不是在运行时中。
通过这个过程,我们可以发现,实际上,Node.js 虽然说是用的 Javascript,但只是在开发时使用 Javascript 的语法来编写程序。真正的执行过程还是由 V8 将 Javascript 解释,然后由 C/C++ 来执行,所以并不需要过分担心 Javascript 执行效率的问题。可以看出,Node.js 并不是一门语言,而是一个将 JavaScript 转为 C++ 来执行系统调用的平台。
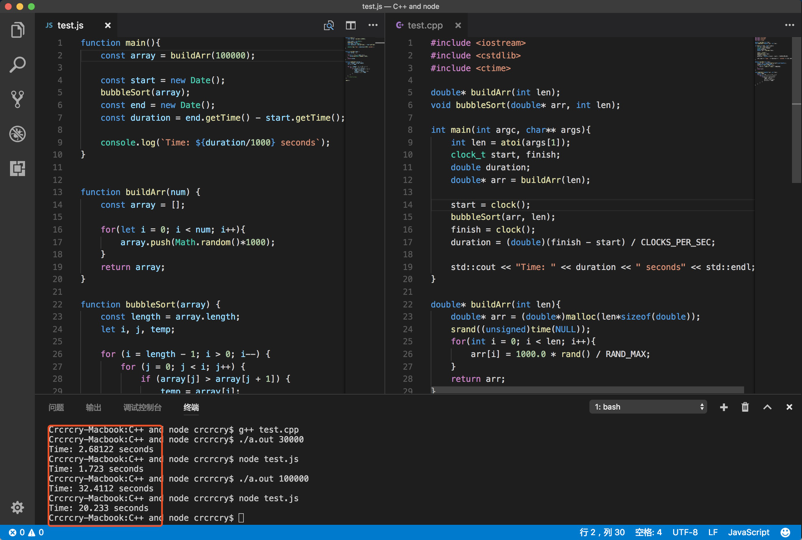
另附上自己写的一个 Node.js 与 C++ 中冒泡排序的耗时比较,简单测试了下 3 万个数和 10 万 个数的耗时。可以看出 Node.js 的性能是很强大的。
简单的讲解了 Node.js 的底层原理后,我们来着重分析 Node.js 的特性:事件驱动和非阻塞I/O。
在服务端,会接收到大量的网络 I/O,进而要完成文件 I/O、查询数据库、分发请求等工作。那 Node.js 在这方面是怎么做的呢?
router.get('/users', (req, res) => {
// ... 省略一些数据库连接的代码
connection.query('SELECT something FROM sometable', function (error, results, fields) {
connection.release();
if (error) throw error;
res.json({
code: 1,
result: results
});
});
})
// ... 干点其他的
这是一个很常见的 Node.js 框架 Express.js 中处理网络请求、查询数据库的案例。执行流程实际为:
- 用户通过 Javascript 代码调用 Node 核心模块,将参数(查询语句)和回调函数(对查询结果的处理)传入到核心模块;
- Node 核心模块会将传入的参数和回调函数封装成一个请求对象;
- 将这个请求对象推入到 I/O 线程池等待执行;
- Javascript 发起的异步调用结束,Javascript 线程继续执行后续操作(干点其他的)。
也就是说,将参数和函数封装并推入线程池,Node.js 就可以干别的了,而不用傻等着处理结果什么也干不了。傻等着结果的过程,其实是对计算机资源的浪费,也是性能的瓶颈。
当数据库查询完成时:
- 将结果存储到请求对象的 results 对象上,并发出操作完成的通知。
- Node.js 有一个类似 while(true) 的事件循环,每次事件循环时会检查是否有完成的 I/O 操作,如果有就将请求对象加入到 I/O 观察者队列中,之后当做事件处理。
- 处理 I/O 观察者事件时,会取出之前封装在请求对象中的回调函数,执行这个回调函数。在本段代码中是将查询结果处理成一个 JSON 返回给客户端。
这就是 Node.js 事件驱动及非阻塞 I/O 的流程,它将各种复杂的 I/O 都(甩锅?)丢了出去,并且告诉它“你做完了告诉我一声,我再来处理你。”
这样一种策略和 Java 等的策略是完全不同的。Java 采取的是阻塞型 I/O,为每个客户端请求分配一个线程/进程,当 I/O 时,这个线程/进程阻塞,等待 I/O 的完成。因为阻塞的过程,Java 的这种策略很难实现高性能。
事实上,大多数网站的服务器端都不会做太多的计算,它们只是接收请求,交给其它服务(比如文件系统或数据库),然后等着结果返回再发给客户端。所以聪明的 Node.js 针对这一事实采用非阻塞 I/O 策略。单线程也避开了创建、销毁线程以及在线程间切换所需的开销和复杂性。主线程只接收请求,把需要长时间处理的操作交出去,然后继续接收新的请求,服务其他用户。
当然,Node.js 的策略也有自己的缺陷,因为不是所有的服务端服务都不需要做太多计算的。I/O 操作可以尽可能的扔出去等别人做完,但 JavaScript 代码总得自己运行吧,如果这部分代码运行耗时很长,就会导致事件循环被阻塞,其他的回调、事件监听器等都得不到运行的机会。这样下去,轻则效率降低,重则运行停滞。
虽然 Node.js 也有 process 全局对象来实现多进程。但它仍然难以充分利用服务器多核CPU资源。
因此,我们常见的模板渲染,压缩,解压缩,加/解密等涉及大量代码计算运行的操作,都是 Node.js 的软肋。这一类操作,通常叫做 CPU 密集型任务。而 Node.js 擅长的那一类操作,叫做 I/O 密集型任务。
所以,我们需要点什么办法,让 Node.js 也可以高效的处理 CPU 密集型任务。
三、C++ Addon in Node.js
既然 V8 是用 C++ 编写的,那我们写 C++ 来处理高计算任务不就好了?C++ 在高速度、高性能和并行计算领域可是一把好手。OpenMP、MPI、TBB,各种并行计算开发工具,很好的支持了 C++ 在高性能计算领域的发展。
那该怎么做呢?见 Node 官方文档
文档比较难读,我举个栗子。
如下 C++ 代码:

核心部分主要在两个红框,第一个红框编写了计算逻辑(传入两个参数相加)并返回值,第二个红框描述了将编写的 C++ 函数转化为 JavaScript 下的 add 函数并导出。
于是我们就可以编译这个模块并调用啦:

噢,当然没有这么简单。我们刚刚只是大概描述了过程
- 编写基于 V8 的 C++ 函数,并编写转化和导出函数(图中第二个红框)
- 编译 C++ 文件为 node 模块。
- 在 Node.js 中引用、调用。
而实际上,如何基于 V8 编写 C++ 接口,以及编译过程。都有一堆坑要踩。
先简单介绍下代码中两个一直出现的保留字:Isolate、Local
- Isolate:V8 工具类,代表一个 V8 引擎实例。
- Local:V8 存储对象的结构,代表了内存分配释放管理的对象引用。
进入正题,如何基于 V8 编写 C++ 接口:
编写 C++ 接口的难点在于,数据类型转化。你总不能指望 JavaScript 中的 number 可以直接在 C++ 里面当 int/double 用吧?
这二者当然不能直接转换,属于 V8 的数据和普通 C++ 内存分配的有着巨大的差别。属于 V8 的数据特指的是持有 JavaScript 数据的存储单元。即上方示例中的 addon.add(3, 5) 中的 3 和 5。这两个数字在 C++ 中不能直接访问,而需要通过调用接口,即 args[0]->NumberValue() 和 args[1]->NumberValue() 来访问。
想要具体了解 V8 数据和 C++ 数据转换 API,可以读这篇。
在 JavaScript 中,基本类型(数字,字符串,布尔值等)是不可变的,基本类型变量的重新赋值实质是,变量重新指向另一个存储了数据的地址。一个 C++ 扩展自然也不能够改变与基本类型相连的存储单元,而只能通过 API 去访问它们。但这些基本类型的 JavaScript 变量可以被重新分配到 C++ 创建的新存储单元中,供我们操作。
double args0 = args[0]->NumberValue();
但是这意味着改变数据将会导致新内存的分配。
在少量数据传递时,这没什么。但当你设计了一个需要频繁交换数据的 C++ Addon in Node.js,分配和拷贝的开销是巨大的。
但复制数据是不可避免的,毕竟我们需要 C++ 处理计算任务。而且频繁调用接口获取 V8 数据值的开销也不容小嘘。
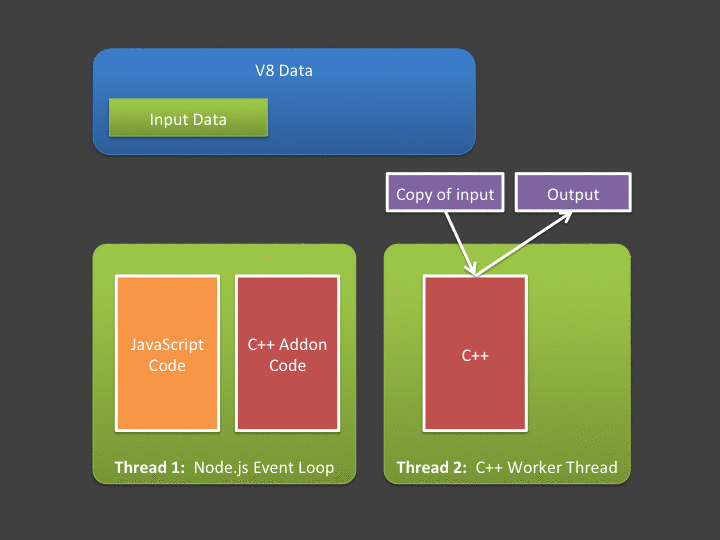
当我们写下 var a = 3 并将其传入 C++ addon 使用,最后得到返回数据过程中,我们实际经历了以下步骤:
- var a = 3; 将一个变量 a 指向为数据 3 分配的 V8 空间。
- addon.add(a, 2); 将 a 这一数据传入 C++ Addon。
- C++ Addon 中分配一块普通 C++ 内存,存储该 V8 数据的值(通过调用接口)。
- C++ 进行运算工作。
- C++ 算出应返回的数据。
- C++ Addon 创建一块 V8 内存,存入该数据值。
- 将该 V8 数据返回给 JavaScript。
- JavaScript 获取数据,进行接下来的运算。
很麻烦对不对?我们在 Node.js 中用 C++ 的需求是什么?高性能计算、CPU密集型任务?
如果致力于创建高吞吐量的 Node.js 应用,这样一个流程将过多经历花费在了数据拷贝上,不利于性能的提升。
我们希望的流程应该是这样的:
- JavaScript 分配一个空间传入 C++。
- 该空间数据直接参与 C++ 运算。
- 将数据直接返回给 JavaScript。
如果需要做到这样,我们需要 Node.js Buffer 的帮助。
Buffer 类被引入作为 Node.js API 的一部分,使其可以在 TCP 流或文件系统操作等场景中处理二进制数据流。
Buffer 类的实例类似于整数数组,但 Buffer 的大小是固定的、且在 V8 堆外分配物理内存。
这不就是我们想要的吗?Buffer 的数据不存储在 V8 存储单元,不受限于 V8 的规则。
我们先来了解如何操作 Buffer 进行 I/O,看 Node.js 文档上的例子。
// 创建一个长度为 10、且用 0 填充的 Buffer。
const buf1 = Buffer.alloc(10);
// 创建一个长度为 10、且用 0x1 填充的 Buffer。
const buf2 = Buffer.alloc(10, 1);
// 创建一个长度为 10、且未初始化的 Buffer。
// 这个方法比调用 Buffer.alloc() 更快,
// 但返回的 Buffer 实例可能包含旧数据,
// 因此需要使用 fill() 或 write() 重写。
const buf3 = Buffer.allocUnsafe(10);
// 创建一个包含 [0x1, 0x2, 0x3] 的 Buffer。
const buf4 = Buffer.from([1, 2, 3]);
// 创建一个包含 UTF-8 字节 [0x74, 0x73, 0x74] 的 Buffer。
const buf5 = Buffer.from('tst');
我们在 Node.js 调用函数中传入 Buffer,再在 C++ 中用一个指针指向 Buffer 即可,可以用 char * 的指针强制类型转化一下,更便于数据读取。而计算过程中直接操作该指针,Buffer 的关联内存就已经被修改了。
不过此处需要安装一个额外的 NPM 包 NAN 用于处理 Buffer,在 binding.gyp 中配置(具体配置后面会讲)。
下附一个简单代码,将 Buffer 中每个值的 ASCII 码都加一,如果看懂意思就没有必要看代码了。输出“BCD”。
Node.js:
const addon = require('./build/Release/buffer_example');
// 在 V8 之外分配内存,预设值为 ASCII 码的 "ABC"
const buffer = Buffer.from("ABC");
addon.add(buffer, buffer.length, 1);
console.log(buffer.toString('ascii'));
C++:
#include <nan.h>
using namespace Nan;
using namespace v8;
NAN_METHOD(add) {
char* buffer = (char*) node::Buffer::Data(info[0]->ToObject());
unsigned int size = info[1]->Uint32Value();
unsigned int rot = info[2]->Uint32Value();
for(unsigned int i = 0; i < size; i++ ) {
buffer[i] += rot;
}
}
NAN_MODULE_INIT(Init) {
Nan::Set(target, New<String>("add").ToLocalChecked(),
GetFunction(New<FunctionTemplate>(add)).ToLocalChecked());
}
NODE_MODULE(buffer_example, Init)
通过 Buffer 和 NAN 模块还可以构建 C++ Addon 的异步处理,也能较好的提高性能。限于篇幅简单介绍一下。
通过写一个继承于 NAN::AsyncWorker 的子类,使得在一个 C++ 线程中执行计算。通过 NAN API,重写 Execute 方法,将该 C++ 计算线程推入线程池,而当计算结束时,libuv(前面介绍 Node.js 时那个重要模块)调用 Node.js 事件轮询线程的 HandleOKCallback 的方法(这个方法也需要在子类中重写),创建一个 Buffer 并调用 JavaScript 回调函数。
上面一直在讲 Node.js 与 C++ 之间的数据传递和返回,那中间的计算怎么办呢?
这就是 C++ 的事啦,各种并行计算、高性能计算库,用起来,接口的数据输入和输出都搞定了,中间的算法和逻辑就与本文无关了。
写好了接口,还需要编译 C++ 为 node 模块,才能在 Node.js 中进行 require 引入和调用。
编译 C++ 为 node 模块,需要使用 node-gyp,该工具是 Node.js 官方原生插件构建工具。
上手很简单:npm install -g node-gyp。
而我们在要编译模块的地方,需要手动写一个 binding.gyp 文件,就类似于 JavaScript 项目下需要一个 package.json 一样,在该文件位置输入一系列命令可以进行编译操作:
node-gyp configure // 根据平台,生成项目构建文件,如:MakeFile
node-gyp build // 根据构建文件,生成原生 Node.js 插件文件,这一步之后就可以将生成的插件复制出来到处用啦,但是注意:不能跨平台。
node-gyp clean // 清除 configure 和 build 生成的文件
node-gyp rebuild // 按顺序运行 clean、configure、build 命令
// 其他的可以用到的时候查文档 ...
列一个我写过的 binding.gyp 配置文件:
{
"targets": [
{
"target_name": "reach",
"sources": [
"./Reachability/ReachCLI.cpp",
"./TrajectoryGraph/TrajectoryGraph.cpp",
],
"include_dirs": [
"/usr/share/boost/include",
"/usr/include",
"<!(node -e \"require('nan')\")"
],
"libraries": [
"/usr/share/boost/lib/libboost_serialization.so",
"/usr/lib64/libtbb.so",
],
'cflags_cc!': [
'-fno-rtti',
],
}
]
}- binding.gyp 文件的配置在 node-gyp 上没有详细介绍,需要额外去查阅资料了解。
- target_name 是生成的 Node.js 模块名。
- sources 是涉及的 cpp 文件。
- include_dirs 是 C++ 中引入的库文件的搜索路径(当然环境变量中的路径自动会搜索的),这里我引入了经典 C++ 库 Boost 和 TBB,用于进行高性能计算,前两行即这两个库的 .h 文件位置。第三行代表引入之前介绍的 NAN 包。
- libraries 是涉及的静态/动态链接库,需要手动写进来。此处我引入了 Boost 和 TBB 中的动态链接库(引入了头文件当然还需要引入库,不太了解的看这篇,复习一下 C++)。
- cflags_cc! 下的 ‘-fno-rtti’ 是动态转换发生 error 时,由于 RTTI 未打开,加入的 option。
构建文件编写的过程还是有蛮多的坑的,不过 node-gyp 编译时都会有效报错,解决不了时在 Stack Overflow 或者 Google 上查一下就比较容易找到原因了。
直接去阅读 gyp user document 也是可以的,但是那个写的比较粗略,而且不太易读。
四、总结
- 基于 V8 的 Node.js 擅长处理 I/O 密集型任务,不擅长处理 CPU 密集型任务。
- 作为服务端总有需要处理的 CPU 密集型任务,这时需要引入 C++ Addon in Node.js
- 不能忽视 V8 存储单元和 C++ 变量之间的数据拷贝消耗。可以通过 Buffer 解决这一问题,如果对性能的要求更高,可以编写异步的 Node.js 模块,操作 Buffer 执行回调。
- binding.gyp 的配置介绍。
- 提取文中一些干货引用:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号