

多线程异步日志系统,高效、强悍的实现方式:双缓冲!

作 者:道哥,10+年嵌入式开发老兵,专注于:C/C++、嵌入式、Linux。
关注下方公众号,回复【书籍】,获取 Linux、嵌入式领域经典书籍;回复【PDF】,获取所有原创文章( PDF 格式)。
别人的经验,我们的阶梯!
大家好,我是道哥,今天我为大伙儿解说的技术知识点是:【在多线程环境下,如何实现一个高效的日志系统】。
在很久之前,曾经写过一篇文章《【最佳实践】生产者和消费者模式中的双缓冲技术》,讨论了:在一个产品级的日志系统中,如何利用双缓冲机制来解决生产者-消费者相关的问题。
前段时间,有位小伙伴私信给我,希望可以具体聊一下这个实现方案。
本来答应在国庆期间完成的,但是我的拖延症一犯再犯,一直拖到今天,终于把这个作业给补上了。
双缓冲这个思路并不是我原创的,而是参考了大神陈硕老师的一本书《Linux 多线程服务端编程》。
从书名就可以看出,讨论的是服务器端的相关编程内容,而且是多线程场景下的,因此可以隐约看出,书中给出的参考代码的质量是很高的。
如果您的主力开发语言是 C++,强烈推荐您去研究下这本书。
很多 C++ 语言的细节问题,作者都给出了自己专业、严谨的思考和解决方案。
言归正传!
在上一篇文章中,我主要从思路、概念的角度,来描述如何利用双缓冲机制。
这篇文章,我们就忠于书中原文,一起来学习一下作者的思考过程,并给出一些对性能起决定作用的关键代码。
先来看一下书中的性能测试结果:

单片机中常用的环形缓冲区
一说到缓冲区,相信各位小伙伴一定看过很多关于缓冲缓冲区的文章和代码,在单片机中的使用率很高。
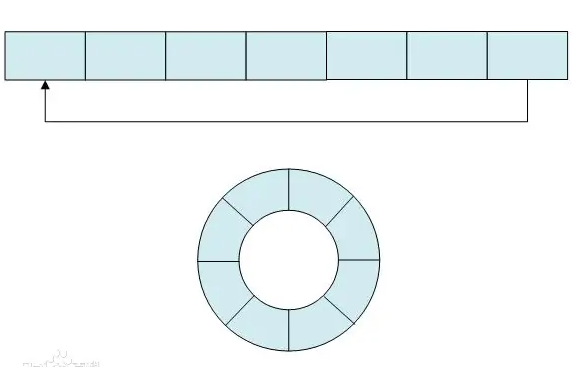
所谓的环形缓冲区,就是一块平整的内存区域,让它的尾部连接到首部即可。
另一个类似的结构:环形队列,本质上都是一样的。
维护环形缓冲区的数据结构中,有head和tail指针。
当写入的时候,把输入写入到tail指针的位置,写完之后,递增tail的指针值;
当读取的时候,从head指针的位置开始读取,读完之后,也递增head的指针值。
这样的操作方式,比较适合那种简单的单输入、单输出场景。
只要处理好:当 head 和 tail 这两个指针交汇的时候如何处理即可。
但是在x86的操作系统中,在多核 + 多线程的工作环境下,无论是从功能上、还是从性能上来考虑,这样的环形缓冲区就满足不了需求了。
还是拿日志系统来举例:在一个应用程序中,可能会有多个线程同时调用日志系统的写入API接口函数,这就需要保证线程安全。
这样的线程称作 前台/前端 线程。
日志数据存储在内存中之后,最终是要输出的,比如:写入到文件系统、通过网络上传到服务端、输出到其他的监控系统等等。
实现输出操作的也是一个线程,假如需要写入到文件系统,那么在写入期间,这个线程就需要一直持有缓冲区中的日志数据。
这样的线程称作 后台/后端 线程。
但是,文件系统的写入速度是很慢的(毕竟要操作硬盘啊),如果这个时候又有前台线程需要写日志信息了,该如何处理?
总不能暴力的说:后台线程正在把现有的日志数据存储到硬盘上,已经持有了内存缓冲区,前台线程你是后来的,先等着!
多线程异步日志:双缓冲机制
在这本书中,作者对这样的日志系统规定了几个关键的要求,都是与实际的业务需求相关的:
线程安全:多个线程可以并发写日志,不造成竞争,两个线程的日志信息不会交叉出现;
吞吐量大;
日志消息有多种级别,格式可配置等等;
为了达到这个目的,作者提出了“双缓冲”思路(Double Buffering)。
基本思路是:
准备两块 buffer: A 和 B;
前端负责往 buffer A 填数据(日志信息);
后端负责把 buffer B 的数据写入文件。
当 buffer A 写满之后,交换 A 和 B,让后端将 buffer A 的数据写入文件,而前端则往 buffer B 填入新的日志信息,如此反复。
其实还是蛮好理解的哈,我们还是来画图描述一下:
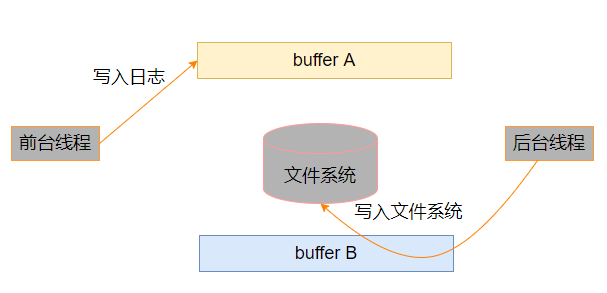
当 buffer A 写满之后,交换两个缓冲区:

双缓冲机制为什么高效
使用两个buffer缓冲区的好处是:
在大部分的时间中,前台线程和后台线程不会操作同一个缓冲区,这也就意味着前台线程的操作,不需要等待后台线程缓慢的写文件操作(因为不需要锁定临界区)。
还有一点就是:后台线程把缓冲区中的日志信息,写入到文件系统中的频率,完全由自己的写入策略来决定,避免了每条新日志信息都触发(唤醒)后端日志线程。
例如:可以根据实际使用场景,定义一个刷新频率,例如:3秒。
只要刷新时间到了,即使缓冲区中的日志信息很少,也要把它们存储到文件系统中。
换言之,前端线程不是将一条条日志信息分别传送给后端线程,而是将多条信息拼成一个大的 buffer 传送给后端,相当于是批量处理,减少了线程唤醒的频率,降低开销。
尽可能的降低 Lock 的时间
在刚才的描述中,有这么一句话:在[大部分的时间中],前台线程和后台线程不会操作同一个缓冲区。
也就是是说,在小部分时间内,它们还是有可能操作同一个缓冲区的。
那就是:当前台的写入缓冲区 buffer A 被写满了,需要与 buffer B 进行交换的时候。
交换的操作,是由后台线程来执行的,具体流程是:
后台线程被唤醒,此时 buffer B 缓冲区是空的,因为在上一次进入睡眠之前,buffer B 中数据已经被写入到文件系统中了;
把 buffer A 与 buffer B 进行交换;
把 buffer B 中的数据写入到文件系统;
开始休眠;
在第2个步骤中:交换缓冲区,就是把两个指针变量的值交换一下而已,利用C++语言中的swap操作,效率很高。
在执行交换缓冲区的时候,可能会有前台线程写入日志,因此这个步骤需要在 Lock 的状态下执行。
可以看出:这个双缓冲机制的前后台日志系统,需要锁定的代码仅仅是交换两个缓冲区这个动作,Lock 的时间是极其短暂的!这就是它提高吞吐量的关键所在!
参考代码
在示例代码中,作者对双缓冲机制进行了扩展,采用4个缓冲区,这样可以进一步减少或避免前端线程的等待时间。
数据结构如下:

这里的 nextBuffer_ 相当有是currentBuffer_的“备胎”。
当前台线程发现currentBuffer_不可用时(空间已满,或者正在被后台线程操作),可以立刻写入到这个"备胎"缓冲区中,从而降低了前台线程的等待时间。
下面是前台线程的写入代码:

前端线程在生成一条日志消息的时候,会调用append()函数。
在这个函数中,如果当前缓冲区(currentBuffer_)剩余的空间足够大,直接把消息消息拷贝(追加)进去,这是最常见的情况。
如果当前缓冲区的剩余空间,小于这次日志信息的写入长度,就把它移动到 buffer_ 集合中(一个Vector),此时会发送唤醒信号给后端线程,然后把 nextBuffer_ 这个备胎 move 为 currentBuffer_。
move 是 C++ 中的操作,意思是移动,而不是拷贝/复制。
当然了,如果前端的写入速度太快,一下子就把两块缓冲区都用完了,那么只好分配一块新的 buffer 作为当前缓冲区,这是极少发生的情况。
再来看看后端的代码实现,这里只贴出了最关键的临界区内的代码,也就是前文所说的“小部分时间”的情况:

这段代码中最重要的就是 swap 函数,它把前后台使用的缓冲区进行了交换。
当前后台缓冲区交换之后,就离开了临界区,此时后台线程就可以慢慢的往文件系统中写入数据了。
另外,这段代码中还有一个地方比较有意思,就是对备胎 nextBuffer_ 的操作:
当前台中使用的备胎 nextBuffer_ 已经被消耗掉时,后台线程及时地为它补充一个新的备胎。
可以继续优化的地方
在本章的最后部分,作者提出了一个更加严苛的情况:
异步日志系统中,使用了一个全局锁,尽管临界区很小,但是如果线程数目较多,锁争用也可能影响性能。
一种解决方法是像 Java 的 ConCurrentHashMap 那样使用多个桶子(bucket),前端线程写日志的时候根据线程id哈希到不同的 bucket 中,以减少竞争。
这种解决方案本质上就是提供更多的缓冲区,并且把不同的缓冲区分配给不同的线程(根据线程 id 的哈希值)。
那些哈希到相同缓冲区的线程,同样是存在争用的情况的,只不过争用的概率被降低了很多。
推荐阅读
【2】C语言指针-从底层原理到花式技巧,用图文和代码帮你讲解透彻



