
转自:http://gad.qq.com/program/translateview/7160166
译者:赵菁菁(轩语轩缘) 审校:李笑达(DDBC4747)
对于任何追求UE4性能最佳、同时又想保持极高质量视觉效果的人来说,本文有一些可遵循的一般性建议和原则。
局限性
为了性能,你通常受CPU时间(通常和游戏设置相关)和GPU时间限制(渲染场景花费的时间)。CPU创建由GPU渲染的场景会耗费一些时间。
通常情况下,当你发现游戏的运行速度不像你想要的那么快时,第一步是找出你现在受以上哪个环节的约束,然后确定需要修改的资源或设置来修正问题。UE4的一些内置工具就是为了实现这个目标而存在的,我建议好好掌握这些工具,特别是CPU和GPU分析器。
了解可用工具
控制台指令
UE4中有很多可用工具,它们可以用来分析性能和帧率,许多工具采用控制台指令形式,可用在控制台输入这些程序指令,控制台可以在游戏中通过按波浪键显示,也可以在编辑器的显示菜单里找到。这里圈出的是几个特别有用的指令(这些可以按“stat__”也就是“stat unitgraph”或者“stat fps”的形式在控制台输入)。
先是Stat的“Engine”组:

这里让我们仔细看看从“Detailed”Stat组得到的信息(自动选中上面圈出的多数其他stat组):
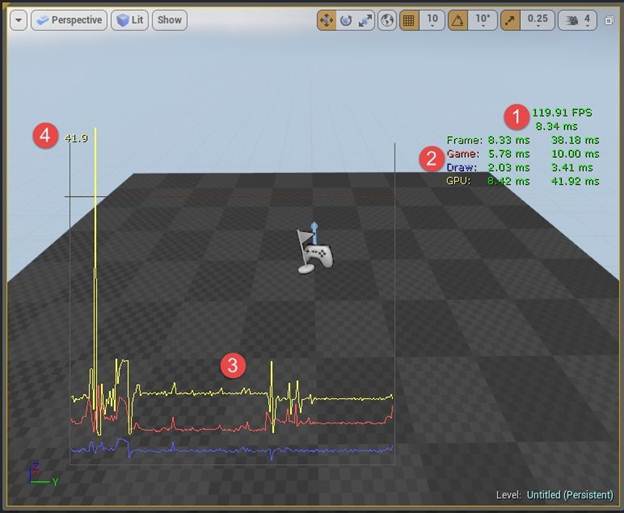
- 这是当前帧率(每秒帧数)和帧时间(每帧毫秒数)。
- 这是帧时间
- 这被分解成两组:
- i. Frame(帧):帧花费的总时间。
- ii. Game(游戏):这是一个任意的CPU逻辑,它不与渲染直接关联。如果该组很慢,通常的情况是程序员有需要修正的内容,但是它可以是与艺术相关的,比如:屏幕上有太多颗粒。内置在CPU分析器中的Frontend工具可以用来研究CPU性能并且观察正运行缓慢代码。特定的、与复杂任务相关的游戏设置只能在CPU上执行,像A.I.和Navigation的设置。
- iii. Draw(绘图):这是一个与GPU上渲染设置相关的CPU逻辑。它包括图形API和绘图调用的设置,或者如果渲染代码已经以非最佳的方式修正了,它就可能与渲染代码相关。
- iv. GPU:GPU渲染帧花费多长时间。它包括:执行图形API调用、绘图调用、着色器和后过程着色器的执行、获取纹理……这里的问题通常与资源相关,它可能是场景中类似着色器这样非常复杂的东西,或者场景中有许多不同的网格,结果就是每帧中发生太多的绘制调用。这可能会让一个专业美工或程序员找到问题根源,但是通常情况下需要一些决策——为了达到预期性能,应该做哪些艺术权衡。这里能帮到您的最棒的工具是GPU分析器和着色器复杂性视图,这些会在之后进行讨论,同时下面还会讨论“Advance”目录中显示的特定stats。
- 这里有两个度量
- i. 第一个是这个帧的当前帧时间(左)
- ii. 第二个是在最后几秒的最差帧时间(右)
- 注意GPU和CPU(游戏&绘制)是同时执行的,所以帧花费的总时间不是它们时间的总和,但是任一项拖了后腿都可能是帧率降低的原因。
- 这被分解成两组:
- 这是游戏、绘图和GPU的几个帧里的帧时间图。
- 这是图中的峰值——当一个特定过程(游戏、绘图或者GPU)的执行花费了很长时间时。它用毫秒标记了那个顶峰的最慢帧的时间。
这也是stats的一个“Advanced”组,它有更详细的内容需要说明。

在“Advanced”组中的大多数项是特别针对像Lighting或者AI Behavior这样特定系统的,所以这样的系统也包含专门针对“Advanced”组的stats。这里让我们看一些特殊兴趣点的例子:
场景渲染指令和绘制调用
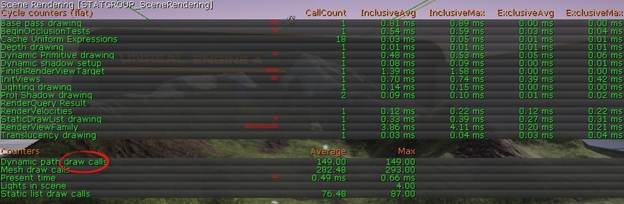
场景渲染是特别方便的,因为它显示了你的场景中绘制调用发生的次数,取决于你的绘图API,这可能是一个极其重要的数字(例如:在手机OpenGL平台上,绘制调用代价太高了以至于开发者经常将大多数的环境并入一个静态网格中来让它作为一个单一的绘制调用)。
初始视图指令和选择
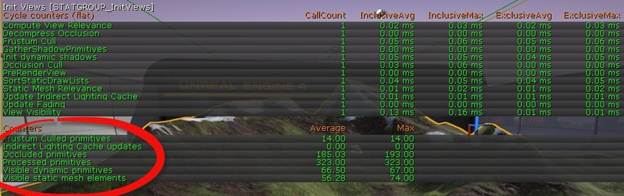
在验证场景剔除时这个stats组很有用。“剔除”就是当你选择性地不运行或渲染部分场景,这些场景当前视图中不会使运行加速。通过参考Frustum Culled初始量值,你可以查看渲染系统决定不绘制的初始量的数量,因为这些量是不可见的。相反,可见的动态初始量部分显示了被定义为可见初始量的数量。
另一个可视化的方式就是使用调试摄像头,你可以在玩游戏的时候通过控制台命令“ToggleDebugCamera ”转至调试摄像头。在那里,如果你点击“F”键来停止渲染并且把调试摄像头移到另一个角度,你可以清晰地看到哪个初始量被渲染了、哪些被修改了。

在上面的屏幕截图中你可以看到预览窗口中的角色摄像的原始视图,该视图是在Play模式中通过在场景大纲中选择摄像头呈现的。ToggleDebugCamera用来停止渲染,在移动摄像头到另一边查看剔除的初始量时,要保证摄像位置的剔除是稳定的。
性能可视化工具
线框视图模式可以告诉你场景和独立网格中有多少顶点和三角形,要实现这个模式,你可以在编辑器等级视口的可视化模式菜单中找到,或者在游戏运行期间按F1键,或者在控制台输入“viewmode wireframe”命令:

如果你的网格有三角形/顶点的富余,而且远比摄像头的充足时,线框就会变成实线。如果你的网格不总是实线的,这意味着你有可能需要比渲染更高的复杂性,你就应该减少网格中的多边形数量。
着色器复杂性可视化
当你的场景中存在很多材质时,可能很难确定哪些是复杂的。幸运的是,UE4中有一个内置视图:着色器复杂性。通过编辑器关卡视窗中的可视化模式菜单可以找到它,还可以在游戏运行时通过按F5找到它,或者进入“viewmode shadercomplexity”控制台指令:

这里的暗绿色区域比浅绿色区域含有更复杂的着色程序逻辑,红色和白色区域也仍有更加复杂的着色逻辑。着色复杂性最大的原因通常是:当多重透明材质重叠时,需要为所有重叠区域计算着色。
当你已经确定了一个红色区域,你可以右击对象来编辑那个角色,在这种情况下——一个静态网格:

从这个静态网格编辑器中,你可以在Details面板中看到网格正使用的材质:

单击放大镜就可以在内容浏览器中选择材质资源,你可以双击它来打开材质编辑器:

在材质编辑器中,你可以推动stats按钮来打开stats的材质标签。在这里你可以看到材质对应的着色器的说明数量。但是说明数量不是与性能的影响一一对应的(因为一些说明比其它更昂贵)了,于一个材质的复杂度来说,说明的总数是一个很好的表征,总体来讲,减少说明的数量可以产生更好的性能。
着色器在其它领域的性能也可以是受约束的——如纹理缓存。如果你在你的材质中用了许多纹理,那么就可能没有足够的空间来立刻将它们写入缓存,所以它们最终会被调入、调出内存,这样是非常慢的。因为这个原因,有可能的话最好减少每个材质的纹理取样器。在材质编辑器的stats窗口和说明数量中,你可以看到材质目前正使用的纹理取样器的数量。
另一方面,着色器在纹理检查中性能也受约束。比如说如果你正在使用一个大型纹理,但是它距离摄像头很远,相对只有一小部分纹理是会被取样的,但是为了给它取样,要读比实际用到的多得多的纹理。这里锥形纹理技术(mip map)就起作用了,因为锥形纹理在纹理的连续区域内包含的纹理更小,所以只有纹理的小得多的部分需要被读入来得到采样。这样一来,保证在所有纹理中充分利用锥形纹理技术是很重要的。
光线复杂度视图模式
光线复杂度视图模式 显示了影响你的几何图形的非静态光线的数量,它可以通过编辑器等级视口的可视化模式菜单得到,或者在游戏运行中按F9键:

这对于追踪光线代价是很有用的——光影响外观越多,它产生阴影的代价就越大。
一个光线可以被剔除的方式有很多,包括半径削减、z型交叉、摄像头背对光源、光函数是0等等,所以光会在不同阴影中出现是非常有可能的。光线复杂度视图模式在将代价与颜色亮度联系起来的方面是做得最好的。
减少半径削减或者光线的锥形角度可能会有帮助。打光性能是非常依赖角度的,所以它极大程度上取决于玩家的摄像头在哪里,由于这个原因,最好在不同角度研究光复杂度。
静止光线重叠视图模式
静止光线重叠视图模式用红色显示了哪些静止光线正被迫移动。

静止光线一次最多只允许4次重叠。一旦你有了大于等于5个的静止光线重叠,拥有最小半径的那个静止光线会开始投射动态阴影,这会产生很高的性能代价。
其他Stats视图
在Window>Statistics菜单中有一些其他统计数据视图:

纹理Stats
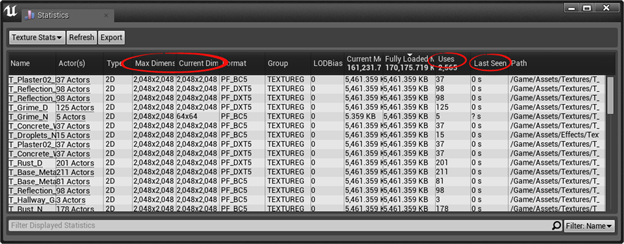
这个工具显示了在当前关卡下使用的所有纹理,它们的分辨率、使用次数和游戏中出现的时间。如果你的场景中有高分辨率的纹理并且没有被很多使用次或者不常见,它们不仅会占据很多不必要的内存,而且也会造成GPU处理缓慢,增加GPU渲染场景花费的时间。
初始量Stats
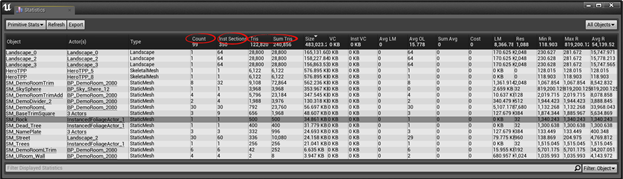
这里你可以看到许多有用信息,开始是在你的骨骼网格、静态网格和场景中有多少三角形初始量。如果你在你的场景中定义了一个对象,它的三角形数量很多,试着在线框层次上观察这个角色。
可视化用来观察线框在一个正常的观察距离外是否保持着实线(或接近实线),这意味着在你的网格中你有比你需要的更多的细节,你可以使用DCC工具或者UE4支持的网格简化工具来减少网格中的顶点数量。
初始量Stats视图也包括数量,这个数量是在当前关卡上使用的数量;还包括实例部分,就是网格中类似着色器和绘制调用这样的元素的数量,主要就是绘制这个对象实例复杂度的度量。如果两个值数量值很高(在你的关卡设置了许多相同对象),实例部分值也很高(对象渲染复杂),那么这可能导致渲染时大量的绘制调用或者图形API状态发生变化,这会显著增加GPU渲染场景的时间。基本上,如果数量×实例部分与场景中其他对象相比是一个相对大的数,这个对象就是应该优化的区域。达到这个目标的一个潜在方法是把单一角色用高多边形数量分解成多个角色,允许他们被单独选择,因此你就有机会一次性绘制比整个多边形数量少的图像了。但是这主要只对CPU加载有影响,所以如果你的游戏不是CPU受限的,那么最好把你的优化时间集中在其它任务上。
只有一种不适用的情况:当使用实例化的静态网格特征时,你可以使用这个特征在你的关卡周围设置许多相同静态网格的拷贝,但是在渲染时应把它们合并为一个单独的绘制调用。这可以提升性能,但也意味着那些网格不能被单独选择,所以如果它们中的任何一个在屏幕上可见,它们都会被渲染。
分析器
也许在优化性能时应该熟悉的两个最重要的工具是CPU分析器和GPU分析器。
CPU分析器
CPU分析器作为一个独立应用运行,可以从Session前端或者Unreal前端获取到,Session前端可以在Unreal编辑器的窗口菜单中找到。这里我将会讨论如何使用Unreal前端,因为两者的界面几乎是完全相同的。
首先你应该启动你的游戏,最好是作为一个独立应用程序运行,但是你也可以在Unreal编辑器中分析运行(在编辑器中分析意味着会有很多的编辑器菜单逻辑和其他代码在你的分析记录中出现,所以最好把它作为一个独立游戏来分析)。
分析的最好配置就是测试建立,因为所有不必要的调试输出都可以被省略,而且它含有全部的代码优化,并且使用烘焙的优化内容。你可以读到更多关于不同建立配置的信息。你也会需要烘焙来让你的内容作为独立游戏来运行,这可以通过Unreal编辑器的File Menu > Cook Content for*Platform*完成,或者你可以为其他平台给你的内容打包。
无论是何种原因,如果你不能完成测试建立或者烘焙你的内容,你可以完成一个开发编辑器建立,带着游戏选项运行,这会为很好地为你显示不同特征的相对性能代价,但是一个含有烘焙内容的测试建立对于得到最终数据是最佳选择。
当启动你的游戏时,启用游戏和Unreal前端之间的内部过程通信,通过使用命令行上的messaging选项是很必要的。Unreal前端不仅支持在相同机器上运行的UE4应用分析,也支持在网络中分析。
在你完成启动游戏之后,你可以运行UnrealFrontend.exe,这可以在UE4/Engine/Binaries 文件夹中找到。你可以看到如下的界面,先在导航找到Session前端标签,之后找到分析器标签。
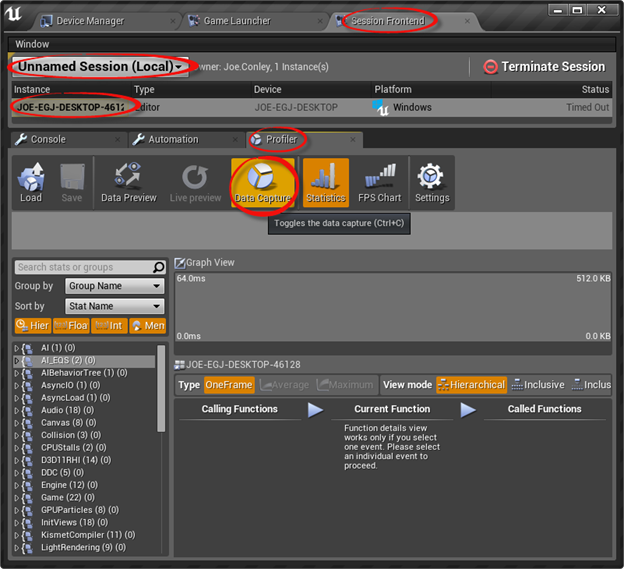
一旦你选择了一个session和一个实例,数据抓取按钮就会变得可用,你可以立即点击它开始数据抓取,再点击一次停止。当你停止的时候,你可以看到一个对话框询问你是否想要把抓取结果传递到这台机器上:

在这里,它会把文件传到你的机器上(如果你不是在网上分析的话就本地拷贝),你会看到这个弹出框:

当完成时,会询问你是否想要加载:

当分析器已经加载了,它长成这样:

我会详细解释各个部分:
- 这是一个渲染线程vs游戏线程的简图,根据CPU逻辑与渲染的关系,一眼你就会知道你是否是CPU受限的,或者它是否是与游戏相关的且花费最多性能的逻辑。
- 这个区域显示了抓取期间的整个CPU加载的简图。在这里,你可以沿着时间线单击任何部分来观察对应帧的CPU分析,或者你可以单击、拖拽来选择帧的范围并且查看均值。根据你这里的选择,函数时间(3)的层级列表中的分析数据会改变。
- 这是调用的不同函数和所花时间的层级列表,花费时间最长的函数排在顶端。花费最多时间的函数以红色显示,其它用黑色显示。你可以通过单击左侧三角来展开对应层,你可以看到这个函数调用过程的分解以及执行花费的时间。
a.
b. 注意这里的CPU停转是CPU闲置等待其它线程结束的时间。
- 如果你在函数时间(3)的层级列表中选择了特定的函数,你可以看到这里的显示变化,这里显示了什么函数调用了这个函数,以及该函数调用了哪些函数,同时可以看到这些调用和被调用函数执行时间的比例。
- 左侧面板展示了stats和stat组。顶层是stat组,你可以展开它查看内部的独立stat。这些stat可以是整型、浮点型数字或者内存,你可以控制哪些显示在stat过滤器面板(6)中。如果你鼠标停留在一个stat上,会弹出该stat的分析信息(8)。
- 在这里你可以通过搜索想要的stat、改变分组和排序、隐藏/显示不同类型的stat(浮点/整型/内存)以及启用/禁用层级视图控制stat面板的显示(5)。
- 这些控件用于显示函数时间的层级列表和所选函数的分解信息(4)
a. 类型——如果在图像视图中你只选择了一帧(2),你唯一的选择就是显示信息那帧,但是如果你选择了一系列帧,你可以选择是否显示平均时间或者花费的最长时间。

b. 视图模式——这会改变函数时间分层的层级列表视图(3),或者改变单纯的函数列表,里面包括这些函数的子程序包括的或排除的时间。

c. 向前、向后按钮可以让你在图像视图的不同部分之间跳转(2)。所有你可以看到一系列信息,之后缩小你的选择范围直到一个帧,然后用这些按钮来在两者之间切换。下拉箭头显示了之前的选择。

d. 这里的火焰按钮是用来展开你当前选择函数的时间层级列表的(3),用来查找花费最多时间的路径,它也会用一个小火焰图标来标识该路径。

8. 鼠标在stat面板(5)的一个stat上面停留时,会显示关于该stat的分析信息,最重要的是最小值、平均值和最大值:

GPU分析器
有一个与研究GPU性能的类似工具。
首先,如果你想要启动你的游戏,最好先作为一个独立应用来启动,但是你也可以在Unreal编辑器中分析它的运行(因为编辑器UI渲染等也会在你的分析文件中显示,所以最好单独分析游戏)。
分析的最好配置就是测试建立,它含有全部的代码优化,并且使用烘焙的优化内容。你可以读到更多关于不同建立配置的信息。你也会需要烘焙来让你的内容作为独立游戏来运行,这可以通过Unreal编辑器的File Menu > Cook Content for*Platform*完成,或者你可以为其他平台给你的内容打包。
如果因为无论任何原因你不能完成测试建立或者烘焙你的内容,你可以完成一个开发编辑器建立,带着游戏选项运行,这会为很好地你显示不同特征的相对性能代价,但是一个含有烘焙内容的测试建立对于得到最终数据是最佳选择。
在这个游戏中,你可以在控制台输入profilegpu来启动GPU分析器,或者按Ctrl+Shift+,来启动,这会打开GPU观察器:

这里你可以看到一张形象图,里面有渲染场景的步骤,在顶部可以看到它们在GPU上花费多少时间,在底部你可以在文本列表中看到相同的信息。在图或者列表中任选一个入口都会在两地方同时选定选中对象,如果鼠标在图上停留,会显示GPU的任务名称。
这个命令不仅打开了观察器,同时也向日志文件和输出日志输出了相同信息(也有一些额外信息)。你可以从窗口菜单中打开输出日志:
输出日志标签中的输出内容如下:
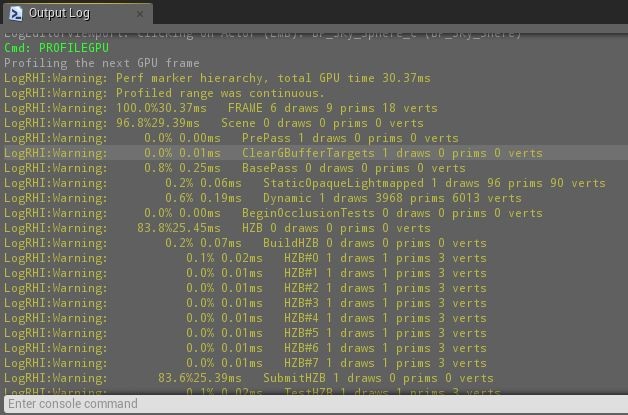
你可以在输出日志中看到这里也有百分比信息,还有绘制、初始量和顶点的数量。
为你的内容做计划和预算
优化的最初阶段之一应该是为你的内容计划性能预算。为制作内容制定指导方针是必要的,所以当美工为游戏制作不同角色和环境时,它们的性能和内存特征变化不大,一些内容的合并会以一个不好的帧率运行,因为一些合并未充分利用潜在可用的CPU和图形性能。
特殊的性能提升建议
合并网格
如之前在线框可视化解释中提到的,减少三角形和顶点的数量永远都是提高性能的方法,但是很多时候,一个单独网格比多个网格刻画集合图形的性能要好得多(一个有1000个顶点的网格可能比10个有100个顶点的网格的更新和渲染都快)。这是因为不仅这些网格可能会分别单独调用GPU来绘制,也因为UE4会为每个网格单独保存和更新变换信息,而且可能检查这些独立网格间的碰撞。所以,如果没有功能性的原因来设置单独网格的话,你应该考虑在把它们引入UE4之前在DCC工具中选择合并它们。
关于合并网格反对的说法是:一个单独的网格可能不能被部分剔除,所以如果它的任何一部分是可见的,整个网格都会渲染。由于这个原因,可能把你的整个关卡都合并成一个单独网格可能不是一个好主意,但是让每一个三角形都成为一个单独网格同样也不是最理想的,所以在两种极端中取得平衡至关重要。
由大量网格组成的单一对象
使用由很多独立网格组成的对象(比如说一辆车的每个独立部分由成百成千的单独网格组成)对于引擎来说可能任务非常繁重,如果引擎在仿真时把每个网格当做独立对象,而且为每个网格单独运行引擎系统(例如:在你的对象中为几千个网格进行单独的挽歌物理仿真)。
像这样对许多网格组件进行父处理并且把它们作为一个对象处理比较好,但是我们有一些建议提供给你,来避免在这些事情上浪费不必要的CPU和GPU的周期。
首先,如果你的对象中有许多网格并且经常不可见,试着不要在移动场景中建立这些网格直到它们可见。即使网格没被渲染,每当一个父级网格组件的变换改变时,每个子网格组件的变换都会被更新,而且在网格需要可见前不要调用Components.Add()方法,这样可以节省许多处理器周期。
同样道理也适用于在游戏系统中注册不可见的网格,如果网格不可见,它的物理形态等可能不需要每帧都更新,所以,在网格需要变为可见之前不要在不可见网格组件上调用RegisterComponent()方法。
避免在由相同对象组成的、或不需要相互碰撞的网格间运行碰撞检测。
对于那些不需要碰撞的子网格组件,把它们的碰撞情况设置为无:
ChildMeshComponent>SetCollisionProfileName(UCollisionProfile::NoCollision_ProfileName);
如果你的角色一点也不需要碰撞,那么就在你的父级网格组件上设置相同的内容,否则就在父级上启用碰撞,但是给它一些能表示它和它的孩子的碰撞说明。
如果包含你的角色的网格组件是接触的或重叠的,它们就会产生重叠时间。如果你不在意这些事件,禁用它们会提升性能:MeshComponent>bGenerateOverlapEvents = false;
屏幕剔除系统用网格组件的边界来确定该网格是否应该在这一帧中渲染。对于那些含有许多网格组件的对象来说,即使对象部分在屏幕外,为每个独立子对象检查边界的代价也可能比单纯渲染所有网格组件的代价要大。试着设置子网格组件使用它们父级组件的边界,来测试观察性能是否没有提升。
ChildMeshComponent>bUseAttachParentBound = true;
给所有这些网格单独打光是不必要的繁重任务——在CPU配置文件中渲染线程部分中“更新间接照明缓存”的毫秒数值很高。通过在你对象的根组件中设置bLightAttachmentsAsGroup为true,你可以选择在你的对象的每个网格中使用相同的间接照明缓存信息,这会节省独立更新网格的时间。
推荐的光线性能设置
动态对象的每个对象阴影可以通过不选关卡平行光中的bUseInsetShadowsForMovableObjects 的flag来禁用,这会提升性能。
在你的关卡的平行光属性中,经常减少动态阴影级联的数量不会对阴影外观产生非常大的影响,但是会提升性能,我认为默认的是5,但是减少至大约3的样子就会产生大致差不多的效果。
动态阴影
动态阴影的代价可能很大,尤其是全局动态阴影。这是因为三角形必须得为动态阴影映射重新渲染。如果你在移动光源上需要许多动态阴影来使多边形尽可能少,如果你想要更多多边形,那就试着少用带有动态阴影的可移动光线。
记住,设置了4个以上的重叠固定光线会迫使半径最小的那个变成可移动的,这样就会开始投射动态阴影。本文他处讨论的固定光重叠可视化是确保没有过多重叠的好方法。
限制后过程效果
后过程效果同样是代价很大的,禁用你不需要的效果也可以很大地提升性能。一些可以考虑禁用的后过程效果包括镜头闪光、土地深度和屏幕空间反射。为了提升性能,你可能也想要以低质量运行屏幕空间抗混叠,以更小的散景尺寸运行散景DOF,因为这里的尺寸与性能是负相关的(更大的散景意味着更差的性能)。
如果最终你可以在其它系统中取得足够的性能提升,你可以之后选择性地把这些效果重新启用。
高存储低质量影响
● 在后过程设置中禁用scene color fringe
● 禁用 ambient cubemap,用 LightmassEnvironmentColor代替
● 通过设置强度在后过程设置中禁用imagebased lens flares 。
在单一镜头中限制贴花数量
如果在摄像头中同时有许多彼此接近的贴花,有时这样的代价是很大的。如果你有比如说50个贴花正同时被渲染,这对于性能可能有消极影响。试着稀释或扩散这些贴花,那么就不会有那么多贴花同时被渲染了。
以更低分辨率和更少变形渲染
如果你想要试着以稍低的分辨率和稍少的变形进行渲染来节省性能,试着做、看看它看起来和运行起来效果如何是非常简单的。
当游戏运行时,你可以打开控制台输入“r.screenpercentage 90”,其中90是全凭尺寸和渲染的百分比。
更永久的设置方法是:选中你的后步骤列表里的“覆写屏幕百分比”框,之后将屏幕百分比设置成想要的百分比(小于等于100)。
场景捕捉对象
场景捕捉对象(如场景捕捉立方体)的默认设置是捕捉每帧。捕捉这些基本涉及到从不同视角渲染整个场景(对于一个场景捕捉立方体来说,会这做6次,每次渲染立方体的一个面),还有从玩家的视角来渲染。这样的代价明显是很大的(如果一个场景中有许多这样的对象尤其如此),所以,除非每帧都抓取它们是你的游戏的一个重要特点,抓取应该被禁用。
总体来讲,同样的原因,限制场景抓取物件的总数量是有道理的。
其它涉及事项:
设置最大和最小帧率
可以在DefaultConfig.ini.文件中设置来控制这个变量,默认如下:
[/Script/Engine.Engine]bSmoothFrameRate=true MinSmoothedFrameRate=22
MaxSmoothedFrameRate=62
禁用遮挡剔除
对于一些特定类型的游戏,遮挡剔除可能会花费比它本身所节省的时间更多。比如:在打斗游戏中,通常场景中的所有内容都应该是被渲染的,不常见的情况是许多几何图形被其他对象遮挡,在这些情况下,使用全局预计算可见复选框也许有帮助?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· [AI/GPT/综述] AI Agent的设计模式综述
2013-07-17 cocos2d-x CCArray
2013-07-17 利用AssetsManager实现在线更新脚本文件lua、js、图片等资源(免去平台审核周期)
2013-07-17 cocos2d-x 纹理源码分析
2013-07-17 cocos2d-x 让精灵按照自己设定的运动轨迹行动
2013-07-17 cocos2d-x 仿真树叶飘落效果的实现
2013-07-17 cocos2d-x 1970毫秒数转时间
2013-07-17 cocos2d-x CCScale9Sprite