Java-集合(面试重点)
1.集合类介绍
-
存储一个班学员信息,假定一个班容纳20名学员

-
如何存储每天的新闻信息?
-
为什么出现集合类:
-
面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式
-
-
数组和集合类同是容器,有何不同
-
数组和集合类都是容器。
-
数组长度是固定的;集合长度是可变的。
-
数组中可以存储基本数据类型和引用数据类型,集合只能存储对象。
-
数组中存储数据类型是单一的,集合中可以存储任意类型的对象。
-
-
集合类的特点
-
集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象。
-
2.Collection接口
- Java集合框架图
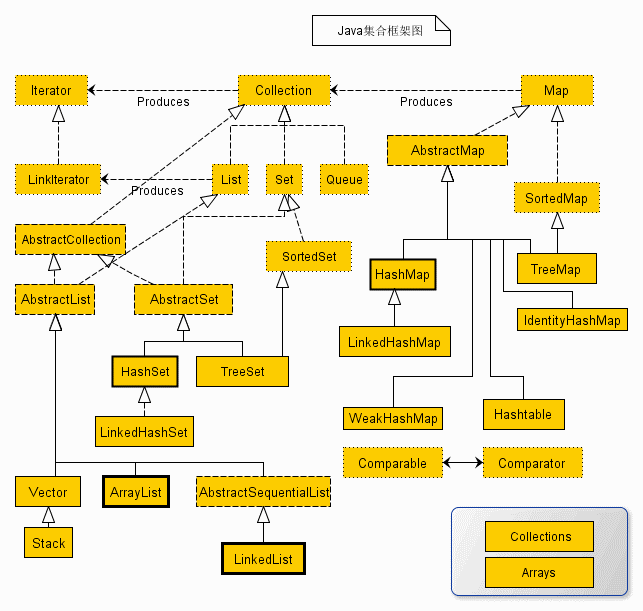
- 简要描述了集合框架的组成:
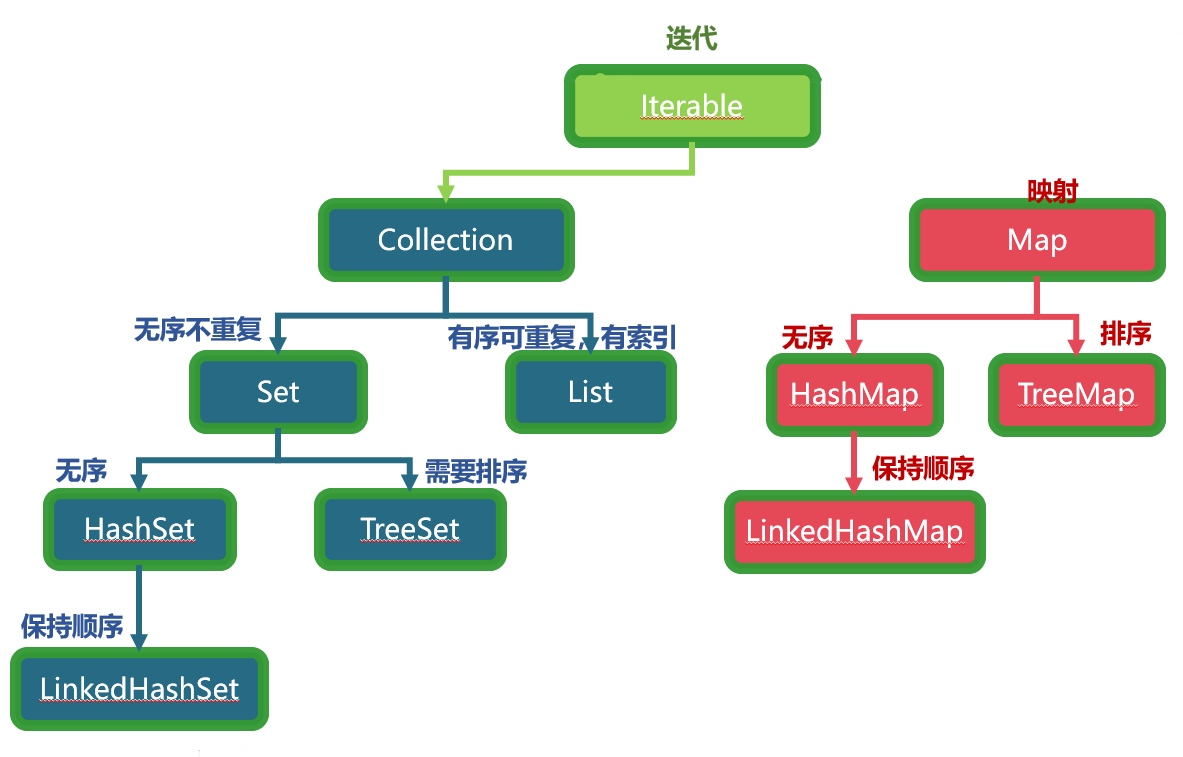
2.1 Collection接口是最基本的集合接口
-
collection接口不提供直接的实现,JavaSDK提供的类都是继承自Collection的“子接口”如List和Set。
-
Collection所代表的是一种规则,它所包含的元素都必须遵循一条或者多条规则。
-
Collection接口为集合提供一些统一的访问接口(泛型接口),覆盖了向集合中添加元素、删除元素、以及协助对集合进行遍历访问的相关方法

2.2 Collection的遍历
-
使用增强型for遍历
-
for(元素类型 循环变量名 : Collection对象){
对循环变量进行处理
} -
增强型 for 循环
-
对数组的遍历一样,循环自动将 Collection 中的每个元素赋值给循环变量,在循环中针对该循环变量进行处理则就保证了对 Collection 中所有的元素进行逐一处理
-
-
使用迭代器遍历
-
因为Collection中有iterator方法,所以每一个子类集合对象都具备迭代器
-
-
Iterator 变量名 = Collection对象.iterator();
while(变量名.hasNext()){
System.out.println(变量名.next());
}
3.List接口
3.1 List接口为Collection子接口。
-
List所代表的是有序的Collection
-
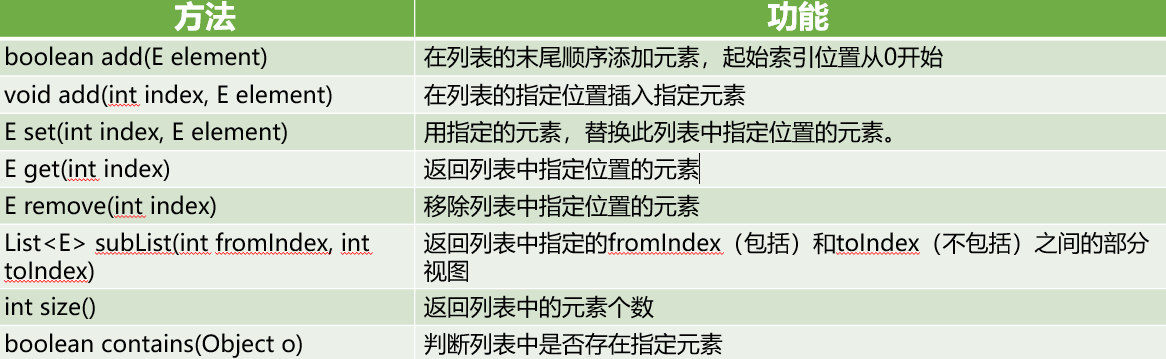
它用某种特定的插入顺序来维护元素顺序,同时可以根据元素的整数索引(在列表中的位置,和数组相似,从0开始,到元素个数-1)访问元素,并检索列表中的元素
-
List由于列表有序并存在索引,因此除了增强for循环进行遍历外,还可以使用普通的for循环进行遍历
2.2 List的常见实现类
3.2.1 List接口实现类-ArrayList
-
构造方法:

-
特点:(注意注意注意)
- 底层实现:数组
- 查找快,添加和删除慢(数组根据索引查找时间复杂度O(1),添加和删除ArrayList需要扩缩容)
- 创建ArrayList对象, 如果使用无参构造,创建的是空列表, 在添加第一个元素的时候,容量才初始化为10
- 存储数据当快溢出时,就会进行扩容操作ArrayList的默认扩容扩展后数组大小为:原数组长度+(原数组长度>>1)
- 可以添加重复元素
- ArrayList是一个非线程安全的列表
- 例子:
3.2.2 LinkedList
-
LinkedList类位置java.util.包,它是List下面的类

-
构造方法

-
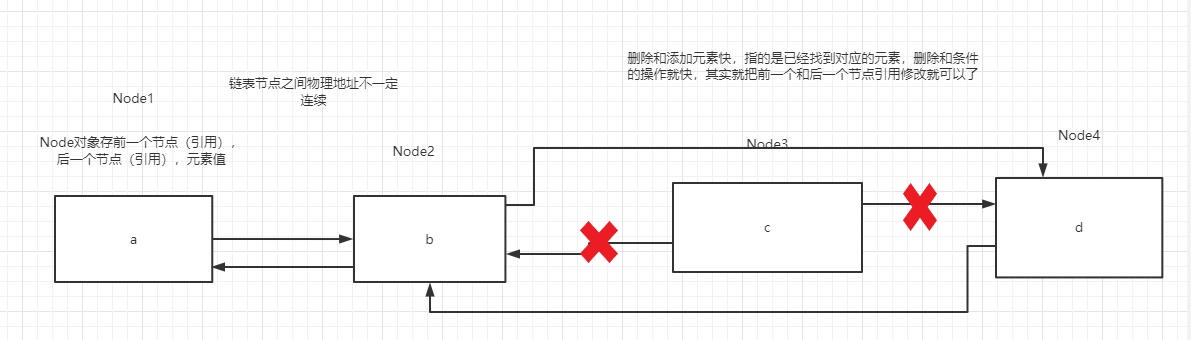
特点(注意注意注意)
(1)有序,可重复
(2)底层使用双链表存储,所以查找慢(LinkedList不能随机访问,从开头或结尾遍历列表),添加和删除快(找到指定位置或者找到指定元素后,添加和删除操作快)
(3)LinkedList也是非同步的
-
案例
public class BookEntity { private String name; private double price; public BookEntity(String name, double price) { this.name = name; this.price = price; } public String getName() { return name; } public void setName(String name) { this.name = name; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } @Override public String toString() { return "BookEntity{" + "name='" + name + '\'' + ", price=" + price + '}'; } } import com.tjetc.BookEntity; import java.util.LinkedList; public class LinkedListTest { public static void main(String[] args) { //创建LinkedList的集合对象,空列表 LinkedList<BookEntity> books = new LinkedList<>(); // 有序 可重复 BookEntity book1 = new BookEntity("红岩", 50); BookEntity book2 = new BookEntity("围城", 60); BookEntity book3 = new BookEntity("长征", 70); BookEntity book4 = book3; books.add(book1); books.add(book2); books.add(book3); //添加重复 books.add(book4); System.out.println(books.size());//4 for (BookEntity be : books) { System.out.println(be); } System.out.println(); System.out.println(books.get(1)+"\n"); BookEntity book5 = new BookEntity("欧亨利小说", 60); BookEntity book6 = new BookEntity("巴黎圣母院", 70); // 在列表的首部添加元素 books.addFirst(book5); // 在列表的尾部添加元素 books.addLast(book6); System.out.println("获取首部元素:" + books.getFirst()); System.out.println("获取尾部元素:" + books.getLast()+"\n"); // 删除头部元素,并返回列表中的第一个元素 System.out.println(books.removeFirst()); // 删除尾部元素,并返回列表中的最后一个元素 System.out.println(books.removeLast()+"\n"); for (BookEntity be : books) { System.out.println(be); } } }
3.2.3 Vector
-
Vector类位置java.util.Vector

-
Interface Enumeration<E>是接口

-
1.Vector与ArrayList相似,操作几乎一样,但是Vector是同步的。所以说Vector是使用数组实现的线程安全的列表;
2.Vector在进行默认规则扩容时,新数组的长度=原始数组长度*2,也可以指定扩容长度;
3.创建对象的时候初始化长度为10。
-
案例
import java.util.Enumeration; import java.util.Vector; public class VectorTest { public static void main(String[] args) { Vector<String > vector = new Vector<>(); vector.add("Jun"); vector.add("The8"); vector.add("carat"); vector.add("seventeen"); System.out.println(vector.size());/*4*/ //返回集合中所有元素,封装Enumeration对象中 Enumeration<String> elements = vector.elements(); //当前枚举是否包含更多元素 while (elements.hasMoreElements() == true){ String s = elements.nextElement(); System.out.print(s+" ");/*Jun The8 carat seventeen*/ } } } -
说出ArrayList与Vector的区别?(注意注意注意)
相同点:ArrayList与Vector的底层都是由数组实现的。
不同点:1、ArrayList不同步,线程相对不安全,效率相对高;Vector同步的,线程相对安全,效率相对较低。
2、ArrayList是JDK1.2出现的。Vector是jdk1.0的时候出现的。
3、扩容方式:
ArrayList扩容方式:原来数组长度1.5倍 Vector扩容方式: 默认是原来数组长度的2倍4、实现方法不同
3.2.4 Stack
-
Stack继承自Vector,实现一个后进先出的堆栈 ,“一个口进出”
-
Stack提供5个额外的方法使得Vector得以被当作堆栈使用。
基本的push和pop 方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置
-
Stack刚创建后是空栈
-
案例
import java.util.Iterator; import java.util.Stack; public class StackTest { public static void main(String[] args) { // 创建集合对象 先进后出 Stack<Integer> stack = new Stack<>(); stack.add(2); //入栈 stack.push(17); stack.push(526); stack.push(9588); //获取栈顶元素 Integer peek = stack.peek(); System.out.println(peek);/*9588*/ //遍历栈 Iterator<Integer> iterator = stack.iterator(); while(iterator.hasNext()) { Integer next = iterator.next(); System.out.print(next+" ");/*2 17 526 9588 */ } //出栈 Integer pop = stack.pop(); System.out.println("\n"+pop);/*9588*/ while(stack.size()>0) { System.out.print(stack.pop()+" ");/*526 17 2*/ } } }
3.2.5 Queue
-
队列是一种先进先出的数据结构,元素在队列末尾添加,在队列头部删除。“两个口”
-
Queue接口扩展自Collection,并提供插入、提取、检验等操作。
-
接口Deque,是一个扩展自Queue的双端队列,它支持在两端插入和删除元素,因为LinkedList类实现了Deque接口,所以通常我们可以使用LinkedList来创建一个队列。
-
PriorityQueue类实现了一个优先队列,优先队列中元素被赋予优先级,拥有高优先级的先被删除。
import java.util.LinkedList; import java.util.Queue; public class QueueTest { public static void main(String[] args) { //Deque<E> extends Queue<E> //LinkedList实现了Deque接口 Queue<String> queue = new LinkedList<>(); //入队 queue.offer("aaa"); queue.offer("bbb"); queue.offer("ccc"); //element 获取队头元素 System.out.println(queue.element()); /*aaa*/ //peek 获取队头元素 System.out.println(queue.peek()); /*aaa*/ //poll 削除队头元素,返回削除的队头元素 System.out.println(queue.poll()); /*aaa*/ //remove 删除队头元素,返回削除的队头元素 System.out.println(queue.remove()); /*bbb*/ //数量 System.out.println(queue.size()); /*1*/ } }
4.Set接口
-
Set接口位置java.util.Set
-
特点:一个不包含重复元素的 collection
-
Set接口方法与Collection方法一致。
-
Set接口中常用的子类:
-
HashSet:底层调用HashMap中的方法,集合元素唯一,不保证迭代顺序,线程不安全(不同步),存取速度快。
-
TreeSet: TreeSet中元素不重复,并能按照指定顺序排列。存储的对象必须实现Comparable接口。线程不安全(不同步)。
-
LinkedHashSet: 哈希表和链表实现了Set接口,元素唯一,保证迭代顺序。
-
4.1 Set的常见实现类
4.1.1 EnumSet
-
EnumSet:是枚举的专用Set。所有的元素都是枚举类型
4.1.2 HashSet
-
常用方法:
-
boolean add(E e) 将指定的元素添加到此集合(如果尚未存在)。
-
void clear() 从此集合中删除所有元素。
-
boolean contains(Object o) 如果此集合包含指定的元素,则返回 true 。
-
boolean remove(Object o) 如果存在,则从该集合中删除指定的元素。
-
int size() 返回此集合中的元素个数。
-
-
HashSet特点:(注意注意注意)
-
HashSet:无序不重复,无索引
-
默认不重复的是虚地址,要想内容不重复,就重写hashcode和equals方法。
-
底层是HashMap实现,HashMap底层是由数组+链表+红黑树实现
-
HashSet堪称查询速度最快的集合,因为其内部是以HashCode来实现的。它内部元素的顺序是由哈希码来决定的,所以它不保证set的迭代顺序;特别是它不保证该顺序恒久不变
-
无索引,无法使用for循环来遍历,可以使用增强for循环和迭代器来循环
-
造成存泄露的原因:HashSet的remove方法也依赖于哈希值进行待删除节点定位,如果由于集合元素内容被修改而导致hashCode方法的返回值发生变更,那么,remove方法就无法定位到原来的对象,导致删除不成功,从而导致内存泄露。
-
-
HashSet:HashSet堪称查询速度最快的集合,因为其内部是以 HashCode 来实现的。它内部元素的顺序是由哈希码来决定的,所以它不保证set的迭代顺序
import java.util.HashSet; import java.util.Iterator; import java.util.Set; public class HashSetTest { public static void main(String[] args) { Set<String> set = new HashSet<>(); set.add("s5555"); set.add("1717"); set.add("e2222"); set.add("v6666"); set.add("1717"); //HashSet可去重 System.out.println(set.size());/*4*/ for (String s : set) { System.out.print(s + " ");/*e2222 1717 s5555 v6666*/ } System.out.println(); //添加顺序和遍历的元素顺序不一定一样 Iterator<String> iterator = set.iterator(); while (iterator.hasNext()) { System.out.print(iterator.next() + " ");/*e2222 1717 s5555 v6666*/ } System.out.println(); boolean bl = set.contains("1717"); System.out.println(bl);/*true*/ //清空 set.clear(); System.out.println(set.size());/*0*/ } }
-
HashSet、HashMap怎么判断对象是否相等
-
判断hashcode是否相等
-
如果hashcode相同,就判断equals是否相等
-
- 考虑业务要求
import java.util.HashSet; import java.util.Set; /*HashSet怎么判断 1、判断hashcode是否相等 2、如果hashcode相同,就判断equals是否相等 */ public class StudentHashSet { public static void main(String[] args) { Student s1 = new Student("001", "Yi", 21); Student s2 = new Student("004", "Jun", 25); Student s3 = new Student("008", "The8", 24); Student s5 = new Student("001", "Carat", 6); Student s4 = s1; //没有业务要求,s1 s2 s3 是三个不相等对象(内存地址不相等) Set<Student> sets = new HashSet<>(); s1.setAge(100); System.out.println(s1.hashCode());/*47665*/ System.out.println(s2.hashCode());/*47668*/ System.out.println(s3.hashCode());/*47672*/ System.out.println(s4.equals(s1));/*true*/ //如果业务要求:学生学号相同认为是同一个学生 sets.add(s1); sets.add(s2); sets.add(s3); //在业务看来,s1,s4,s5,是同一个学生 sets.add(s4); sets.add(s5); s1.setNo("004"); System.out.println(sets.size());/*3*/ sets.remove(s1); System.out.println(sets.size());/*2*/ } }
4.1.3 LinkedHashSet
-
LinkedHashSet继承自HashSet,它主要是用链表实现来扩展HashSet类,HashSet中条目是没有顺序的,但是在LinkedHashSet中元素既可以按照它们插入的顺序排序,也可以按它们最后一次被访问的顺序排序
-
保持Set中元素的插入顺序或者访问顺序,就使用LinkedHashSet
-
案例
import java.util.ArrayList; import java.util.LinkedHashSet; public class LinkedHashSetTest { public static void main(String[] args) { ArrayList<String> list = new ArrayList<>(); list.add("a"); list.add("b"); list.add("b"); list.add("c"); list.add("c"); list.add("c"); list.add("d"); list.add("d"); list.add("d"); list.add("d"); /*1、2步 LinkedHashSet<String> lhs = new LinkedHashSet<>(list); */ //1,创建一个LinkedHashSet集合 LinkedHashSet<String> lhs = new LinkedHashSet<>(); //2,将List集合中所以的元素添加到LinkedHashSet集合中 lhs.addAll(list); //增强for循环遍历,迭代顺序与添加顺序一致,并且去重复 for (String s : lhs) { System.out.print(s + " ");/*a b c d*/ } } }public class Student { private String no; private String name; private int age; public Student(String no, String name, int age) { this.no = no; this.name = name; this.age = age; } public String getNo() { return no; } public void setNo(String no) {this.no = no; } public String getName() { return name; } public void setName(String name) {this.name = name; } public int getAge() {return age; } public void setAge(int age) {this.age = age; } @Override public String toString() { return "Student{" + "no='" + no + '\'' + ", name='" + name + '\'' + ", age=" + age + '}'; } //如果业务要求:学生学号相同认为是同一个学生 //在业务判断中,使用equals判断对象是否相等 @Override public boolean equals(Object o) { Student otherStu = (Student) o; if (this.getNo() == null || otherStu.getNo() == null) { return false; } return this.getNo().equals(otherStu.getNo()); } /* 重写hashCode 适应HashSet和HashMap equals相等,hashcode必相同 ; hashcode相同,equals不一定相等 */ @Override public int hashCode() { return this.getNo().hashCode(); } } /* 1、相同的学号字符串,hashcode也相同 2、不同的字符串,hashcode有可能相同 不影响,因为HashSet和HashMap 判断hashcode相等之后还要判断equals */
4.1.4 TreeSet
-
TreeSet特点:无序不重复,但是排序。 线程不安全(不同步)。底层基于TreeMap实现。
-
使用元素的自然顺序(字典顺序)进行排序:
-
存储非自定义对象(必须本身已经实现Comparable的接口),默认进行排序。
-
存储自定义对象(需要实现Comparable接口,重写compareTo方法)进行排序。
-
接口Comparable<T>
-

-
使用比较器进行排序:
-
可以使用外部比较器Comparator,灵活为类定义多种比较器,此时类本身不需要实现Comparable接口;
-

- 例子
public class Teacher implements Comparable<Teacher> { private String name; private int age; private int level; public Teacher(String name, int age, int level) { this.name = name; this.age = age; this.level = level; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public int getLevel() { return level; } public void setLevel(int level) { this.level = level; } @Override public String toString() { return "Teacher{" + "name='" + name + '\'' + ", age=" + age + ", level=" + level + '}'; } /** * 比较两个对象大小(通过年龄比大小) * * @param o * @return 大于0 当前对象大于传入的对象o */ @Override public int compareTo(Teacher o) { if (this.age - o.age == 0) { return this.level - o.level; } else { return this.age - o.age; } } }
5.Map接口
-
Map是由一系列键值对组成的集合,提供了key到Value的映射。同时它也没有继承 Collection。
-
Map是一个key对应一个value,所以它不能存在相同的 key 值,当然value值可以相同
-
Map接口提供了重要的针对键、值进行操作的接口方法
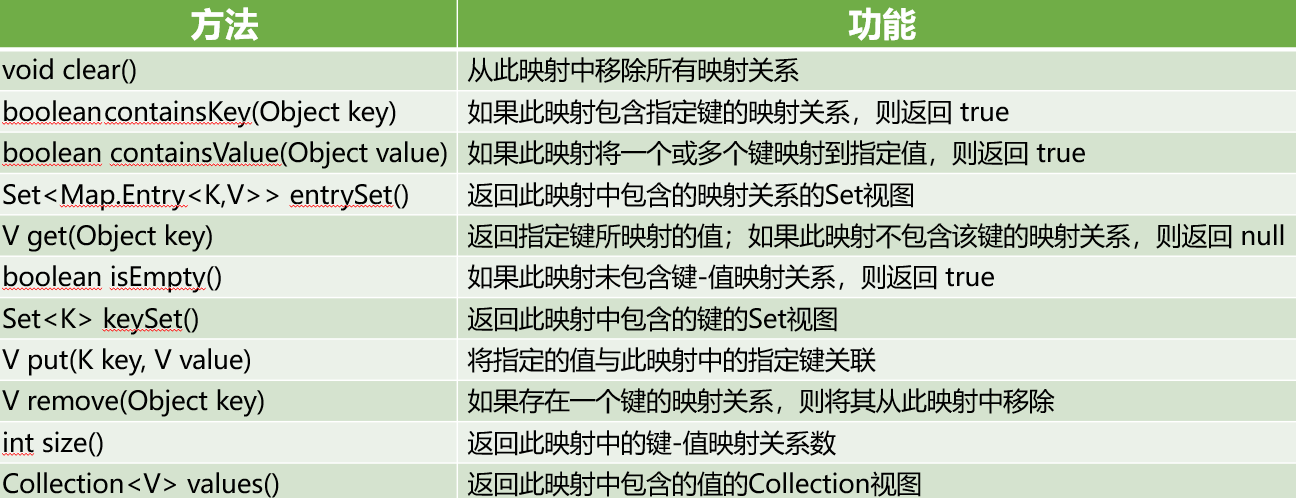
5.1 HashMap(注意注意注意)
-
特点:
-
1.底层实现1.7之前:数组+链表 1.8以后:数组+链表+红黑树
-
2.key不允许重复,如果key的值相同,后添加的数据会覆盖之前的数据
-
3.HashMap是非线程安全的,允许存放null键,null值。
-
- 例子:
import com.tjetc.set.Teacher; import java.util.Collection; import java.util.HashMap; import java.util.Map; //public interface Map<K,V>{} import java.util.Set; public class HashMapTest { public static void main(String[] args) { Map<String, Teacher> maps = new HashMap<>(); Teacher t1 = new Teacher("Yi", 21, 17); Teacher t2 = new Teacher("Jun", 25, 4); Teacher t3 = new Teacher("The8", 24, 8); Teacher t4 = new Teacher("HoShi", 25, 5); Teacher t5 = new Teacher("HoShi", 255, 5); //V put(K key, V value); maps.put("Yi",t1); maps.put("Jun",t2); maps.put("The8",t3); maps.put("HoShi",t4); //put一个重复的 maps.put("HoShi",t5); //int size(); System.out.println(maps.size()); //boolean containsKey(Object key); System.out.println(maps.containsKey("Jun")); //boolean containsValue(Object value); System.out.println(maps.containsValue(t2)); //V get(Object key); System.out.println("根据key值获取value:"+maps.get("The8")); System.out.println("========遍历key========"); Set<String> keys = maps.keySet(); for (String key: keys) { System.out.print(key+" "); } System.out.println(); //V remove(Object key); System.out.println("根据key值删除元素:"+maps.remove("Yi")); System.out.println("========遍历value========"); Collection<Teacher> values = maps.values(); for (Teacher value: values) { System.out.println(value); } System.out.println("========interface Entry<K,V>{}========"); Set<Map.Entry<String,Teacher>> entries = maps.entrySet(); for (Map.Entry<String,Teacher> entry : entries) { //System.out.println(entry); String key = entry.getKey(); Teacher value = entry.getValue(); System.out.println("key值为:"+key+"\n"+"value为:"+value); } } } -
数据结构:
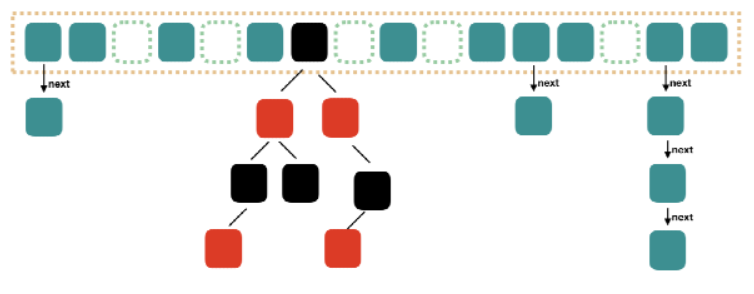
java1.7 HashMap结构
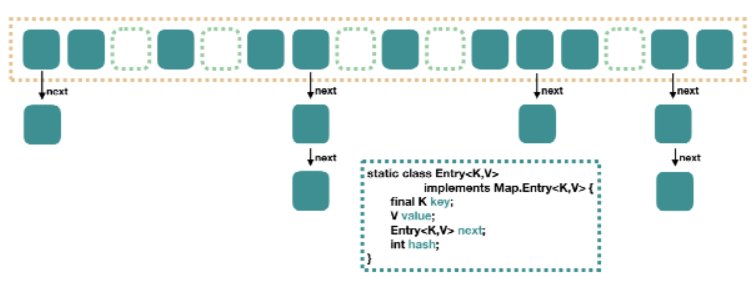
大方向上,HashMap 里面是一个数组,然后数组中每个元素是一个单向链表。上图中,每个绿色
的实体是嵌套类 Entry 的实例,Entry 包含四个属性:key, value, hash 值和用于单向链表的 next
-
capacity:当前数组容量,始终保持 2^n,可以扩容,扩容后数组大小为当前的 2 倍。
-
loadFactor:负载因子,默认为 0.75。
-
threshold:扩容的阈值,等于 capacity * loadFactor
-
-
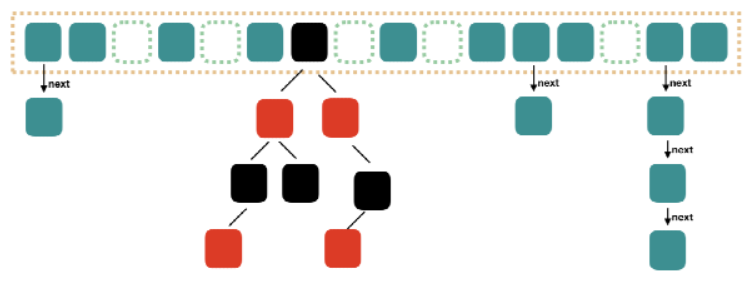
java1.8 HashMap结构:
Java1.8 对 HashMap 进行了一些修改,最大的不同就是利用了红黑树,所以其由 数组+链表+红黑 树 组成。
根据 Java1.7 HashMap 的介绍,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。为了降低这部分的开销,在 Java1.8 中,当链表中的元素超过了 8 个以后, 会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
-
如何判断key是否相同
-
第一步计算key的hashcode是否想相同,如果不同,就认为key不相同,
-
如果相同进行第二步判断,判断key的equals是否为true,如果为false就是认为key不相同,如果为true就认为key相同
-
-
重写hashcode和equals的原则
-
hashcode相同,equals不一定相等,但是equals相等,hashcode必须相同
-
5.2 HashTable
-
Hashtable,它的操作接口和HashMap相同。
-
HashMap和HashMap的区别在于:
-
Hashtable是线程安全的,而HashMap是非线程安全的
-
Hashtable不允许空的键值对,而HashMap可以
-
Hashtable与HashMap都实现Map接口,但二个类的继承的父类不是同一个
-
- HashMap<K,V>
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {}
- HashTable<K,V>
public class Hashtable<K,V>extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
-
HashTable底层实现:数组+链表+红黑树
-
案例
import java.util.HashMap; import java.util.Hashtable; import java.util.Map; public class HashTableTest { public static void main(String[] args) { Hashtable<String, Integer> hashtable = new Hashtable<>(); //hashtable.put(null,1); //运行报错,java.lang.NullPointerException ,key不能是null //hashtable.put("a",null); //运行报错,java.lang.NullPointerException ,value不能是null //hashtable.put(null,null); //运行报错,java.lang.NullPointerException HashMap<String, Integer> hashMap = new HashMap<>(); hashMap.put(null, 1); hashMap.put("jack", null); hashMap.put(null, null); //HashMap的key和value都能为null,但key不能重复,无论存储key为null多少次,最终就有一个key为null,value会被覆盖 for (Map.Entry<String, Integer> entry : hashMap.entrySet()) { System.out.println(entry); } } } /* null=null jack=null */
5.3 ConcurrentHashMap
-
特点:ConcurrentHashMap是线程安全并且高效的HashMap
-
常用方法:同HashMap
-
数据结构:JDK8 数组+链表+红黑树,数组的结构可能是链表,也可能是红黑树,红黑树是为了提高查找效率。
-
采用CAS+Synchronized保证线程安全。CAS表示原子操作,例如:i++不是原子操作。
-
Synchronized:表示锁,多线程能够保证只有一个线程操作。
-
-
ConcurrentHashMap比HashTable效率要高
-
案例:
import java.util.Map; import java.util.Set; import java.util.concurrent.ConcurrentHashMap; public class ConcurrentHashMapTest { public static void main(String[] args) { ConcurrentHashMap<String, Integer> concurrentHashMap = new ConcurrentHashMap<>(); //添加键值对 concurrentHashMap.put("Jun", 4); concurrentHashMap.put("The", 8); //java.lang.NullPointerException /*concurrentHashMap.put(null, 1);*/ System.out.println(concurrentHashMap.size());/*1*/ Set<Map.Entry<String, Integer>> entries = concurrentHashMap.entrySet(); for (Map.Entry<String, Integer> entry : entries) { System.out.print(entry + " "); /*The=8 Jun=4*/ } } }
5.4 LinkedHashMap
-
LinkedHashMap继承自HashMap,它主要是用链表实现来扩展HashMap类,HashMap中条目是没有顺序的,但是在LinkedHashMap中元素既可以按照它们插入的顺序排序,也可以按它们最后一次被访问的顺序排序
-
保持Map中元素的插入顺序或者访问顺序,就使用LinkedHashMap
-
案例
import java.util.Iterator; import java.util.LinkedHashMap; import java.util.Set; public class LinkedHashMapTest { public static void main(String[] args) { LinkedHashMap<String, Integer> lhm = new LinkedHashMap<>(); lhm.put("Yi", 21); lhm.put("Jun", 25); lhm.put("The8", 24); lhm.put("HoShi", 25); System.out.println(lhm.size());/*4*/ Set<String> keys = lhm.keySet(); Iterator<String> it = keys.iterator(); //快捷键itit while (it.hasNext()) { String key = it.next(); Integer value = lhm.get(key); System.out.print(key + "," + value + "; "); /*Yi,21; Jun,25; The8,24; HoShi,25; */ } } }
5.5 TreeMap
-
TreeMap特点: 可以对Map集合中的元素进行排序。
-
1.TreeMap基于红黑树数据结构的实现
-
2.键可以使用Comparable或Comparator接口, 重写compareTo方法来排序。
-
3.自定义的类必须实现接口和重写方法,否则抛异
-
4.Key值不允许重复,如果重复会把原有的value值覆盖。
-
-
使用元素的自然顺序(字典顺序)进行排序:
-
对象(本身具有比较功能的元素)进行排序。
-
自定义对象(本身没有比较功能的素)进行排序(要进行比较那就让元素具有比较功能,
那就要实现Comparable这个接口里compareTo的方法)
-
-
使用比较器进行排序:
-
定义一个类实现Comparator接口,覆盖compare方法,将类对象作为参数传递给TreeSet集合的构造方法
-
- 举例
public class Product { private String name; private double price; public Product(String name, double price) { this.name = name; this.price = price; } public String getName() { return name; } public void setName(String name) { this.name = name; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } @Override public String toString() { return "Product{" + "name='" + name + '\'' + ", price=" + price + '}'; } }import java.util.Comparator; public class ProductComparator implements Comparator<Product> { /** * 判断o1和o2对象大小的规则 * @param o1 * @param o2 * @return 正数 表示 o1大于 负数 表示o1小于o2 0表示o1等于o2 */ @Override public int compare(Product o1, Product o2) { if (o1.getPrice() < o2.getPrice()) { return 1; } else if (o1.getPrice() > o2.getPrice()) { return -1; } else { return 0; } } }//测试类 import java.util.Map; import java.util.Set; import java.util.TreeMap; import java.util.TreeSet; public class TreeMapTest { public static void main(String[] args) { Product p1 = new Product("苹果", 20); Product p2 = new Product("巧克力", 18); Product p3 = new Product("香蕉", 25); //创建外部比较器对象 ProductComparator comparator = new ProductComparator(); //TreeMap TreeMap<Product, String> treeMap = new TreeMap<>(comparator); treeMap.put(p1, "我是苹果"); treeMap.put(p2, "我是巧克力"); treeMap.put(p3, "我是香蕉"); Set<Map.Entry<Product, String>> entries = treeMap.entrySet(); for (Map.Entry<Product, String> entry : entries) { System.out.println(entry); } System.out.println("======================================="); //TreeSet TreeSet<Product> treeSet = new TreeSet<>(comparator); treeSet.add(p1); treeSet.add(p2); treeSet.add(p3); for (Product p : treeSet) { System.out.println(p); } } } /* Product{name='香蕉', price=25.0}=我是香蕉 Product{name='苹果', price=20.0}=我是苹果 Product{name='巧克力', price=18.0}=我是巧克力 ======================================= Product{name='香蕉', price=25.0} Product{name='苹果', price=20.0} Product{name='巧克力', price=18.0} */
5.6HashMap和Hashtable区别
-
1、两者父类不同
- HashMap是继承自AbstractMap类,
- Hashtable是继承自Dictionary类。
- 都实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口。
-
2、对外提供的接口不同
- Hashtable比HashMap多提供了elments() 和contains() 两个方法。
- elments() 方法继承自Hashtable的父类Dictionnary。elements() 方法用于返回此Hashtable中的value的枚举。
- contains()方法判断该Hashtable是否包含传入的value。它的作用与containsValue()一致。事实上,contansValue() 就只是调用了一下contains() 方法。
-
3、对null的支持不同
- Hashtable:key和value都不能为null。
- HashMap:key可以为null,但是这样的key只能有一个,因为必须保证key的唯一性;可以有多个key值对应的value为null。
-
4、安全性不同
- HashMap是线程不安全的,在多线程并发的环境下,可能会产生死锁等问题,因此需要开发人员自己处理多线程的安全问题。
- Hashtable是线程安全的,它的每个方法上都有synchronized 关键字,因此可直接用于多线程中。
- 虽然HashMap是线程不安全的,但是它的效率远远高于Hashtable,这样设计是合理的,因为大部分的使用场景都是单线程。
- 当需要多线程操作的时候可以使用线程安全的ConcurrentHashMap。
- ConcurrentHashMap虽然也是线程安全的,但是它的效率比Hashtable要高好多倍。因为ConcurrentHashMap使用了分段锁,并不对整个数据进行锁定。
-
5、初始容量大小和每次扩充容量大小不同
- Hashtable默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。
- HashMap默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。
-
6、计算hash值的方法不同
- 为了得到元素的位置,首先需要根据元素的 KEY计算出一个hash值,然后再用这个hash值来计算得到最终的位置。
- Hashtable直接使用对象的hashCode。hashCode是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值。然后再使用除留余数发来获得最终的位置。
- Hashtable在计算元素的位置时需要进行一次除法运算,而除法运算是比较耗时的。
- HashMap为了提高计算效率,将哈希表的大小固定为了2的幂,这样在取模预算时,不需要做除法,只需要做位运算。位运算比除法的效率要高很多。
- HashMap的效率虽然提高了,但是hash冲突却也增加了。因为它得出的hash值的低位相同的概率比较高,而计算位运算
- 为了解决这个问题,HashMap重新根据hashcode计算hash值后,又对hash值做了一些运算来打散数据。使得取得的位置更加分散,从而减少了hash冲突。当然了,为了高效,HashMap只做了一些简单的位处理。从而不至于把使用2 的幂次方带来的效率提升给抵消掉。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话